SimCLR
- 이미지 데이터의 정답 label이 없는 상황에서 visual representation 추출
- unsupervised learning
- data augmentation을 통해 얻을 수 있는 positive/negative sample
- contrastive learning (대조 학습
- supervised learning으로 학습한 모델에 준하는 모습을 보여줌
Contrastive Learning Framework
- pretext task -> 동일 이미지에 각도를 변환하거나 이미지를 잘라 퍼즐을 만들어 풀게하는 등의 학습 방식
- Contrastive Learning
- positive pair 끼리는 같게
- negative pair 끼리는 다르게
- 예시
- query: 노랑
- key: 사과/바나나/딸기
- 노랑 - 바나나만 연결되게 학습
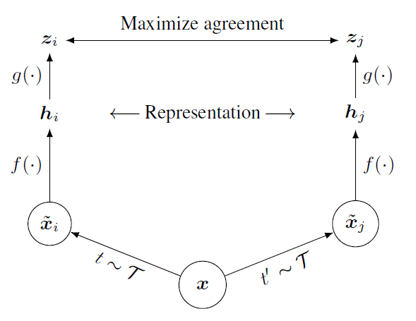
SimCLR은 각 이미지에서 서로 다른 두 data augmentation들을 적용하여, 같은 이미지로부터 나온 결과들은 positive pair로 정의하고, 서로 다른 image로부터 나온 결과들은 negative pair로 정의하는 형태로 contrastive learning 방식을 적용하였음.
- 하나의 이미지 x
- 다른 두개의 augmentation을 거침 -> xi, xj로 나뉨
- 이 둘은 positive pair임
- 또 다른 이미지 y 로부터 yi, yj 얻음,
- xi, yi은 negative pair
- 변환된 xi, xj는 CNN 네트워크를 통과하여 visual representation embedding vector(hi, hj)로 변환됨.
- 이 CNN을 base encoder, ResNet 사용했음
- visual representation vector는 MLP 기반의 네트워크 g를 통과하여 한번 더 변환됨
- MLP 네트워크를 projection head라고 하고, 두 개의 linear layer 사이에 ReLU act 넣음
- Encoder, projection head는 batch 단위로 학습됨.
- N개의 batch size -> 2N개 sample
- sample 별로 1 쌍의 positive pair, 2N-2 쌍의 negative pair 구성 가능함
- pisitive 간의 similiary 높이고 negative 간의 similarity 최소화 하는 형태의 loss function 제안
- loss function 이름: NT-Xent
- 학습을 진행할 때 필요한 것
- 좋은 quality, 많은 양의 negative pair
- 이렇게 하려면 큰 batch size를 이용해야 함, 기본적으로 4096의 batch size(8192 samples)
- batch가 클 때는 LARS optimizer, multi-device 이용
- batch normalization 적용 시에는 device 별로 평균과 표준 편라를 계산하여 적용하느 것이 아니라 모든 device에서 평균/표준편하를 통합하여 적용, -> positive sample이 포함된 device와 negative sample 만으로 구성된 device 들 간의 분포를 같게 normalize 하게 되어 batch normalization 과정에서 발생하는 정보 손실을 최소화할 수 있다.
- ImageNet ILSVRC-2012 dataset으로 진행, encoder freeze 하고 linear classifier를 얹어서 정확도를 측정하는 linear evaluation 방식으로 모델 평가함
Data Augmentation for Contrastive Representation Learning
-
Data Augmentation 기법 이용하기 전에는 두 CNN을 이용하여 하나는 local 정보 위주, 다른 하나는 global 정보 위주로 추출하여 contrastive loss를 적용하였음. -> 이는 random crop하는 것과 같은 효과를 보임.
-
적용 Augmentation
- Geo
- Crop
- Resize
- Rotate
- Cutout
- Color
- color drop
- jitter
- blur
- sobel filter
- Geo
-
여러 augmentation을 이용했을 때 representation quality 증가.
-
color aug를 안넣으면 색 배합으로 모델이 추정함. 이를 방지하기 위해 넣어야함.
-
color distortion을 강하게 가할수록 contrastive prediction task의 난이도가 증가함.
-
모델이 커질수록 성능 증가
-
linear projection head와 projection head 를 넣으면 성능이 더 좋아졌음
Loss Function and Batch Size
- NT-Xent loss는 cross entropy loss를 기반으로 함.
Comparison with SOTA
1. 학습된 모델을 freeze하고 위에 linear classifier를 얹어서 성능을 평가하는 linear evaluation
2. 학습된 모델과 linear classifier를 모두 learnable한 상태로 학습하는 fine-tuning
3. 학습된 모델을 다른 종류의 dataset에 대하여 learnable한 상태로 학습하는 transfer learning의 세 가지 방법으로 평가
4. 성능 좋아짐
