Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
Neural Network의 두 가지 부담
- computationally intensive
- memory intensive
본 논문(Deep Compression)에서 부담을 경감시킬 3가지 방법 제안함
- pruning
- trained quantization
- Huffman coding
Compression 방법 설명
(방법) Overview
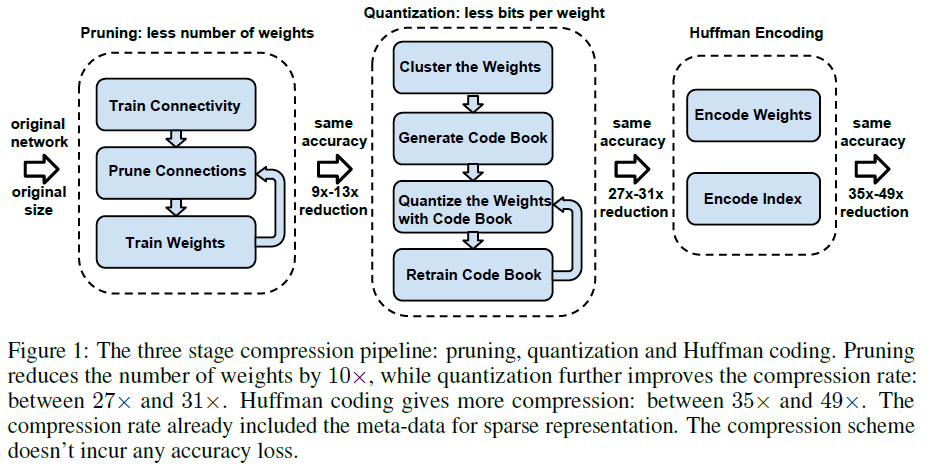
(방법) Pruning
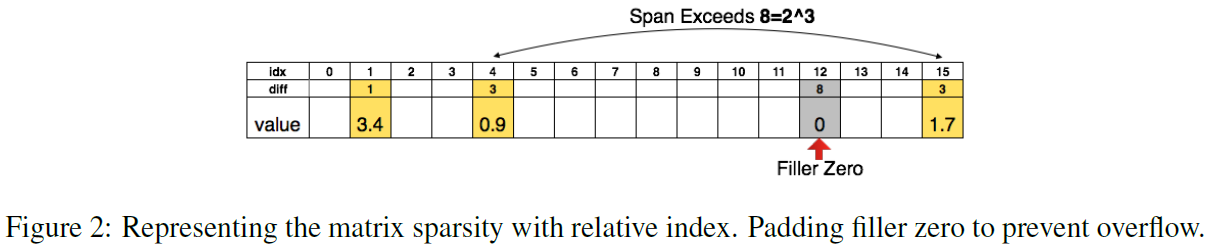
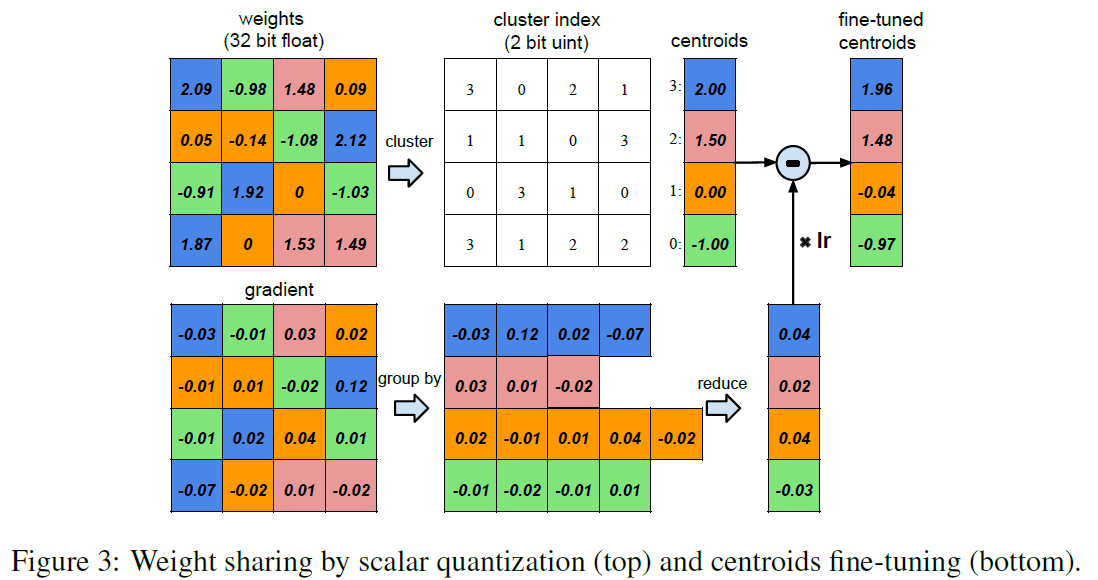
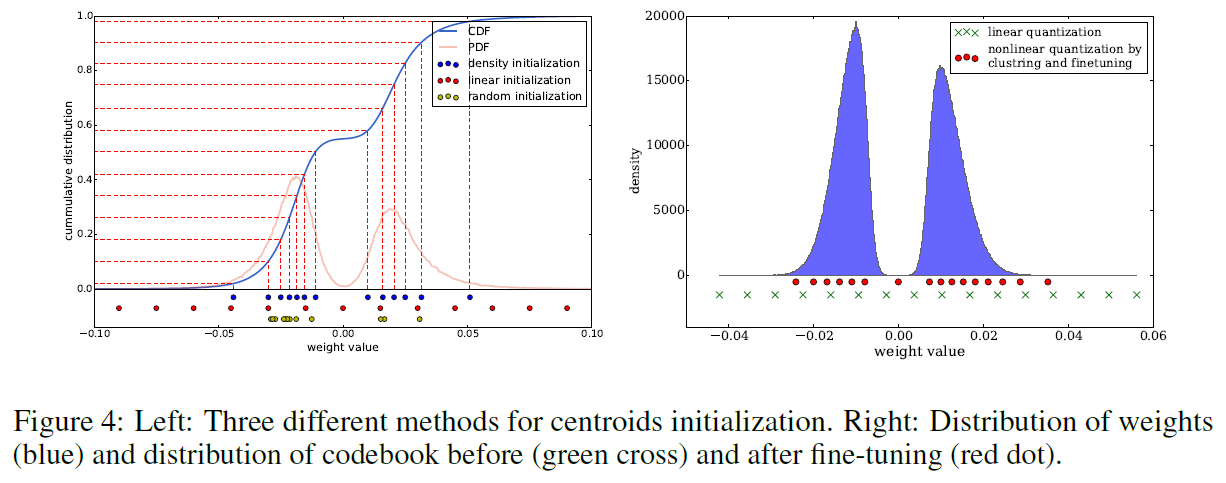
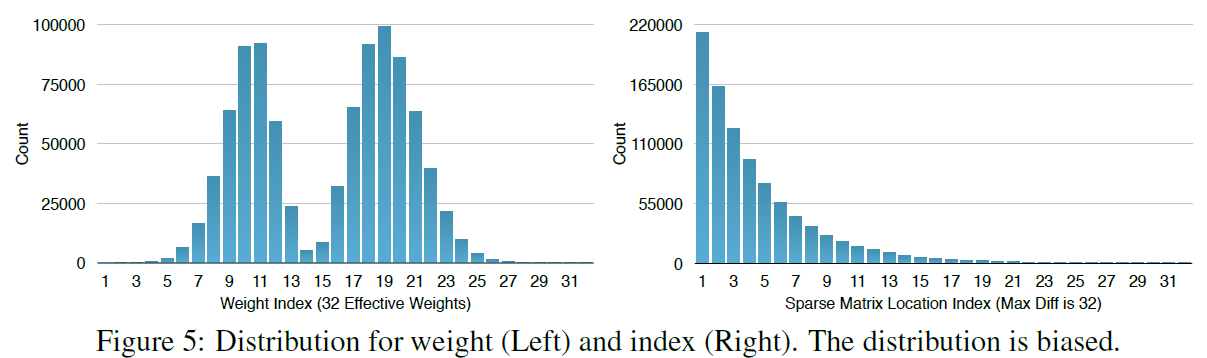
(방법) Quantization & Sharing
(방법) Huffman Coding
compression 방법 적용 시 효과
- 모델 압축을 통해, off-chip DRAM memory을 사용하던 모델을, on-chip SRAM cache에서 사용하기에 적합하도록 만들어 줌
- SRAM cache (5 pJ/access)
- DRAM memory (640 pJ/access)
- 속도, 에너지 효율 개선
compression 적용 순서
pruning -> quantization -> Huffman coding
얼마나 개선하는지?
(개선) Overview
- Storage requirements를 35x ~ 49x 감소
- AlexNet: 240MB -> 6.9MB (35x)
- VGG-16: 552MB -> 11.3MB (49x)
- 3x ~ 4x의 layerwise speedup
- 3x ~ 7x의 energy efficiency
(개선) Pruning
- number of connections를 9x ~ 13x 감소
(개선) Quantization
- number of bits를 32에서 5로 감소
적용 유의 사항
- pruning, quantization은 재학습(retraining)이 요구됨

sshinohs