MaskFormer, Mask2Former
Preliminary knowledge
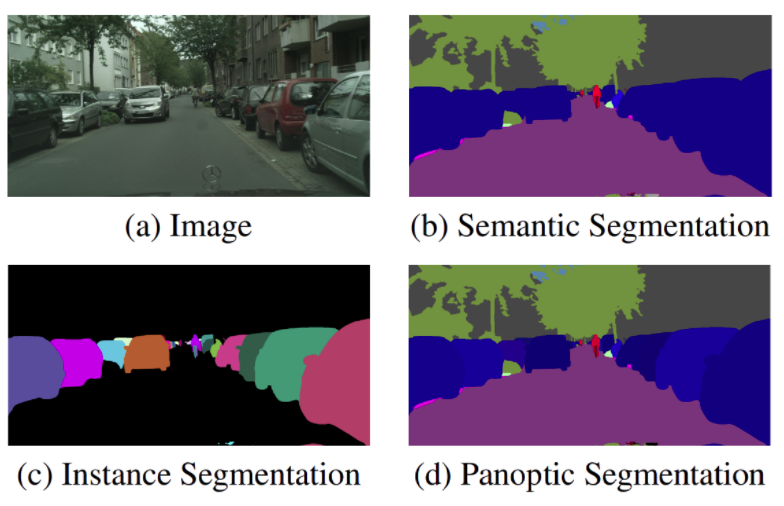
1. Image segmentation task
- definition: category 혹은 instance membership으로 pixel을 group하는 것
- image segmentation task 종류는 대표적으로 3가지가 있음
- semantic segmentation
- panoptic segmentation
- instance segmentation
2. Per-pixel vs mask classification
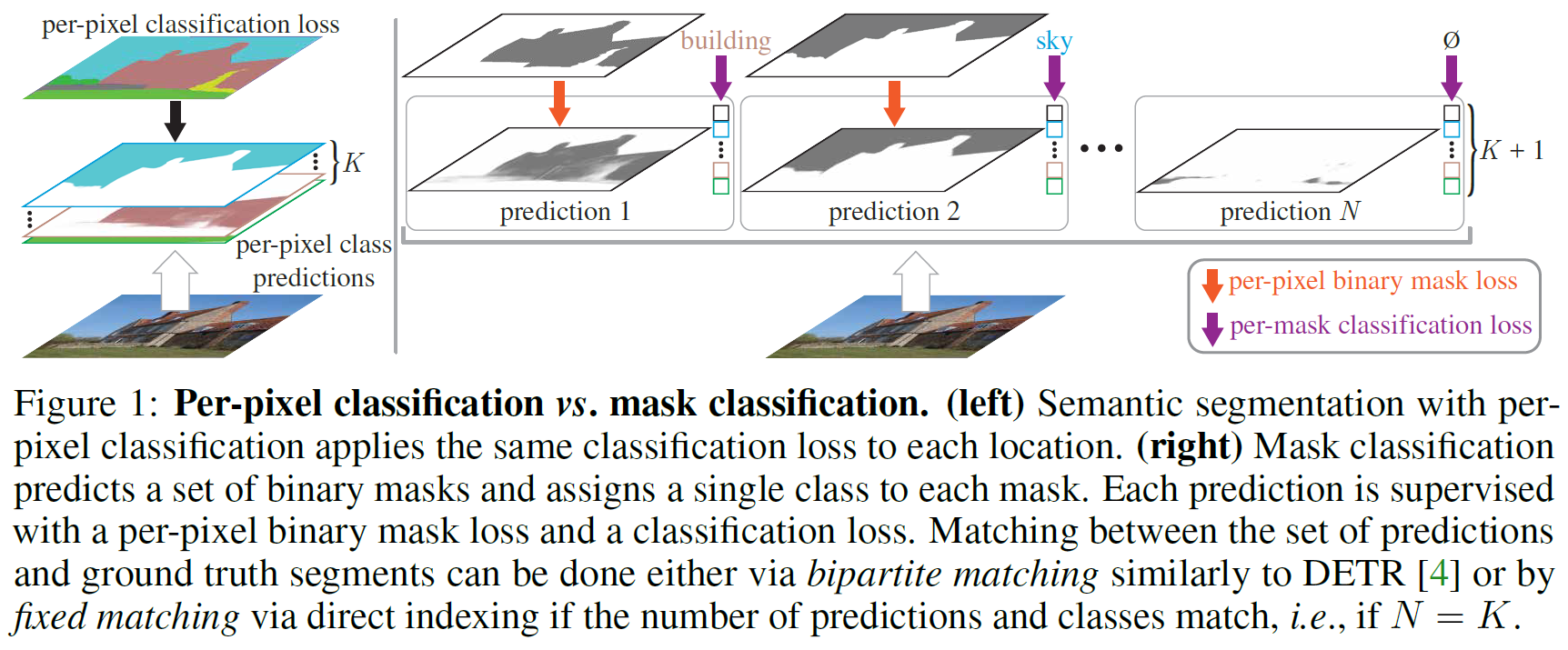
- image segmentation task를 위한 분류 방법으로 두 가지가 있음
- per-pixel classification
- mask classification
- 각 task 별 주요 분류 방법
- semantic segmentation
- FCN 이전 → mask classification 우세
- FCN → per-pixel classification 우세
- panoptic segmenation, instance segmentation은 mask classification 사용
- semantic segmentation
- MaskFormer 이전에는 3가지 task 각각 개별적으로 특화된 architecture들이 개발되어 왔음
- MaskFormer, Mask2Former는 3가지 task를 모두 해결하는 universal architecture이며, mask classification을 사용함
MaskFormer
1. Key insight
- mask classification은 semantic- instance-level segmentation 둘 다 해결할 수 있을 만큼 충분히 general 하므로 둘 다 동일한 model, loss, training procedure로 해결할 수 있는 방법을 찾아보자
- Per-pixel classification → Mask classification
2. From Per-Pixel to Mask Classification
2.1 Per-pixel classification formulation
- image에서 각 pixel이 가질 수 있는 개의 category에 대한 확률 분포를 예측하는 것
- probability distribution
- : K-dimensional probability simplex
- ground truth category labels
- cross-entropy (negative log-likelihood)
2.2 Mask classification formulation
- binary masks
- set of probability-mask pairs
- (No object도 포함해야 하므로 K+1)
- ground truth
- 일반적으로 set 과 set 가 다르므로, 로 가정하고 ground truth에 padding을 "no object" token 으로 채움
- semantic segmentation의 경우 (fixed matching) 가능
- bipartite matching-based assigment를 사용하여 , matching함
- : binary mask loss
2.3 MaskFormer
- 3가지 부분으로 구성되어 있음
- Transformer module
- Pixel-level module
- Segmentation module
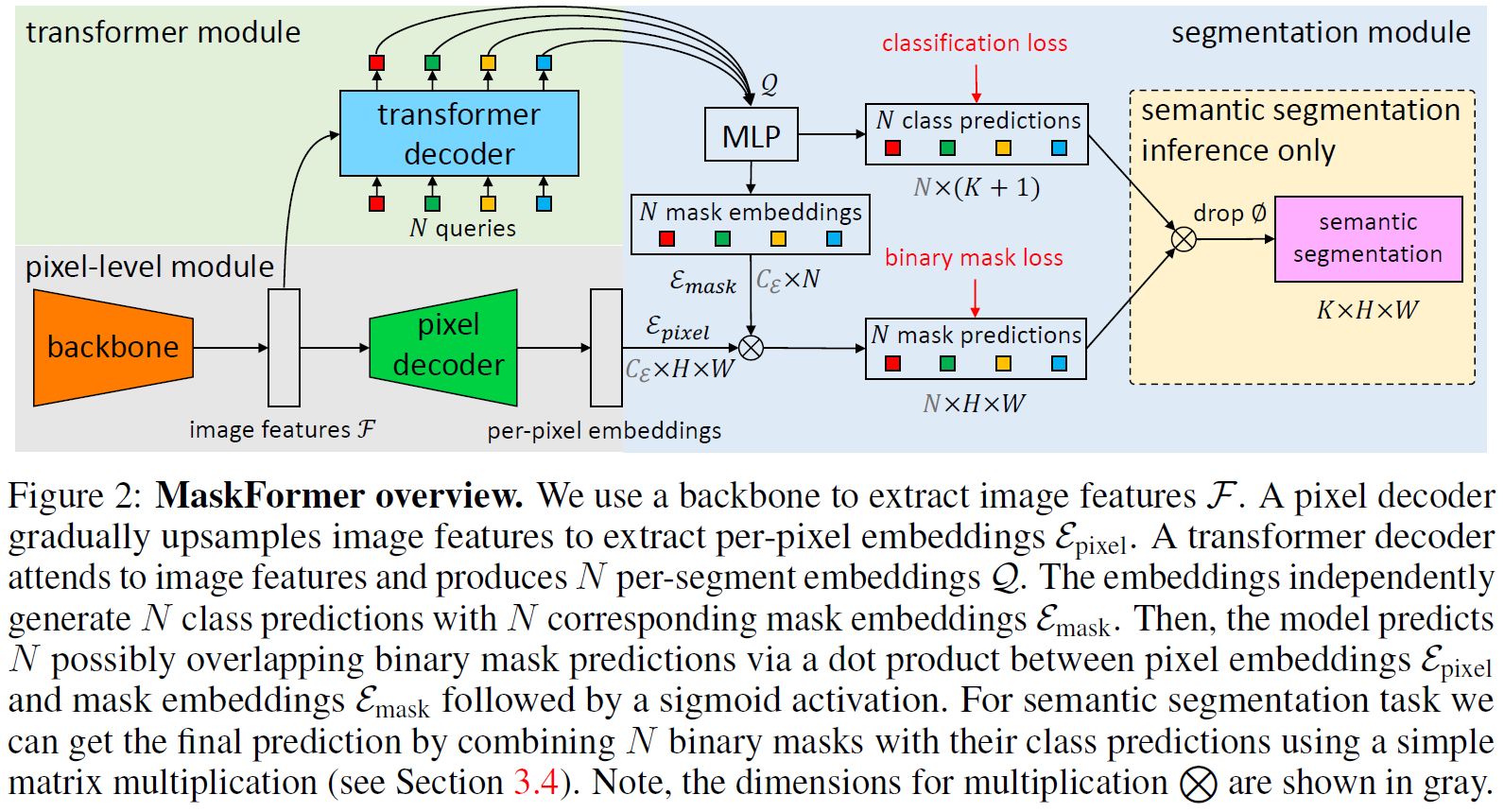
Pixel-level module
- low-resolution의 image feature map 생성
- : 채널 수
- : stride 수
- pixel decoder에서 upsample 하여 per-pixel embedding 생성
- : embedding dimension
- cross entropy 적용
Transformer module
- standard Transformer decoder 사용
- 입력: image features , learnable positional embeddings (즉, query)
- 출력: 개의 per-segment embeddings
- global information을 encode함
Segmentation module
- N class predictions: 에 대해 softmax activation과 함께, linear classifier 적용
- N mask embeddings: MLP 적용,
- N mask prediction: 과 를 dot product하여 구함
2.4 Mask-classification inference
- General inference는 panoptic 혹은 semantic output format
- Semantic inference는 semantic 전용
General inference
- most likely class label
- 직관적으로 각 pixel에서 가장 확률 높은 class로 할당
- semantic segmentation의 경우 동일 class에 대해 merge 됨
- instance-level segmentation task의 경우 index 가 다르면 구분됨
- panoptic segmentation에서 false positive rate를 줄이기 위해서, previous inference strategy를 사용 ?
- low-confidence prediction을 사전에 제거함
- 많이 occluded 된 부분도 처리함
Semantic inference
- "no object" category()이 없는 경우 사용
- 경험적으로 general inference보다 성능이 좋음
- However, we observe that directly maximizing per-pixel class likelihood leads to poor performance. We hypothesize, that gradients are evenly distributed to every query, which complicates training.??
3. Experiments
Datasets
- ADE20K
- COCO
- Mapillary Vistas
- ...
Evaluation metrics
- mIoU
Baseline models
- PerPixelBaseline
- PerPixelBaseline+
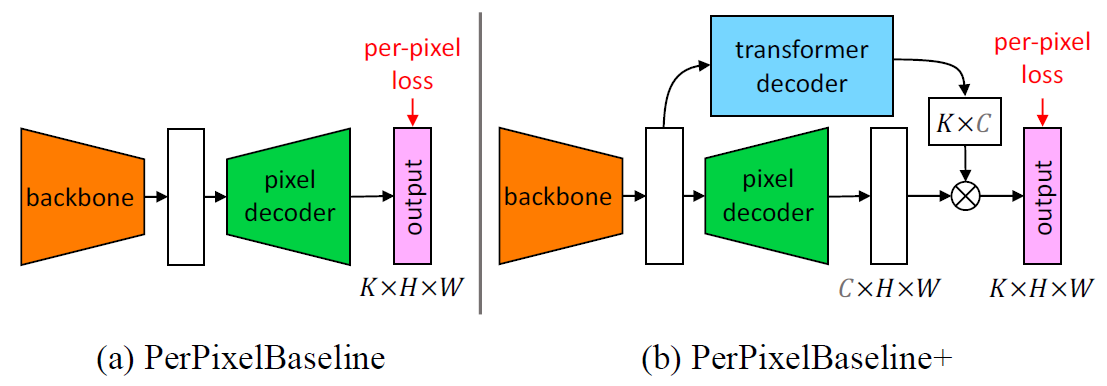
3.1 Implementation details
Backbone
- ResNet
- Swin-Transformer
Pixel decoder
- ASPP
- PSP
Transformer decoder
- DETR과 같음
Segmentation module
- MLP
- 2 hidden layers
- 256 channels
Loss weights
- mask loss에 focal loss, mask loss 사용
Mask2Former
1. MaskFormer, Mask2Former 성능 비교
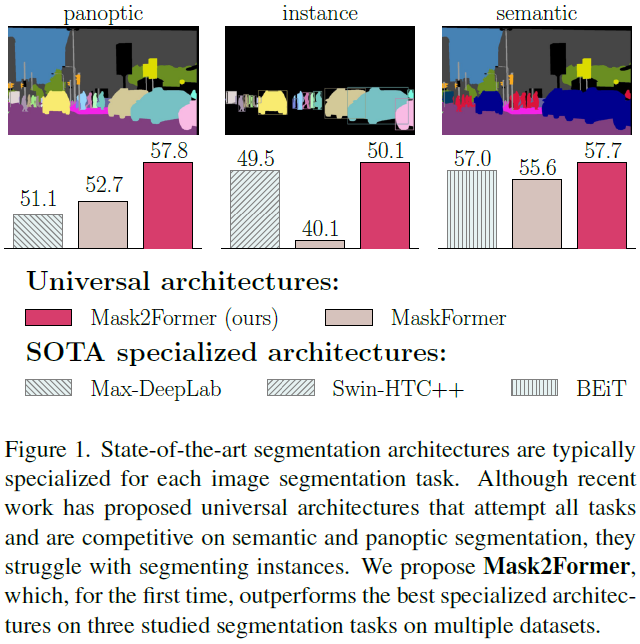
- MaskFormer는 specialized architecture의 성능을 능가하지 못했음
- Mask2Former는 능가함
2. MaskFormer, Mask2Former 구조 차이
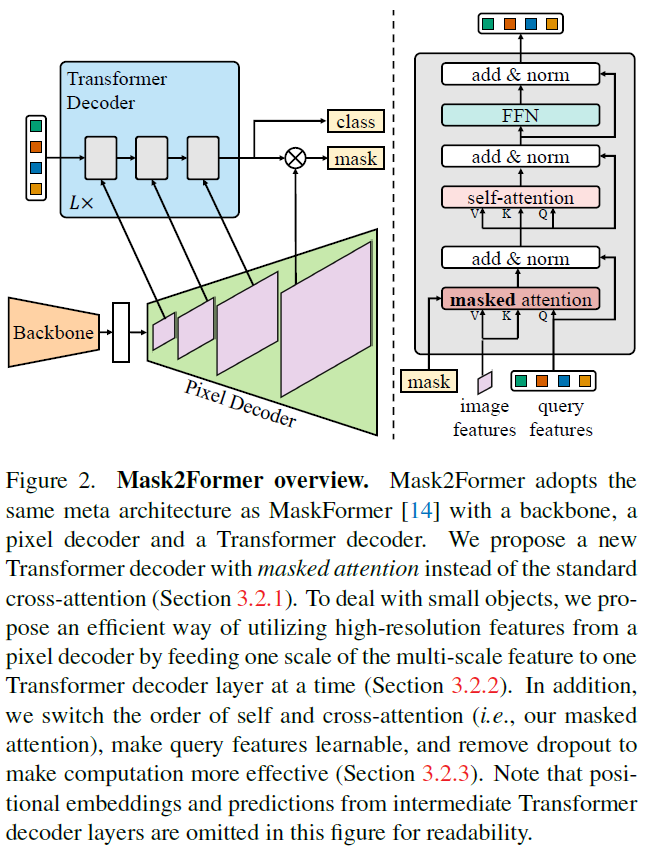
2.1 Transformer decoder with masked attention
- Transformer decoder 제안
- cross-attention을 foreground region 내부로 제한함
- multi-scale
2.1.1 Masked attention
- Standard cross-attention
- 변형
2.1.2 High-resolution features
- feature pyramid 사용
2.2.3 Optimization improvements
- masked attention, self-attention 순서를 변경하여 최적화
2.2 Improving training efficiency
- loss 계산 시 mask 대신에 sampled point 사용하여 훈련 효율 상승

sshinohs