1. 자연어 처리 개요
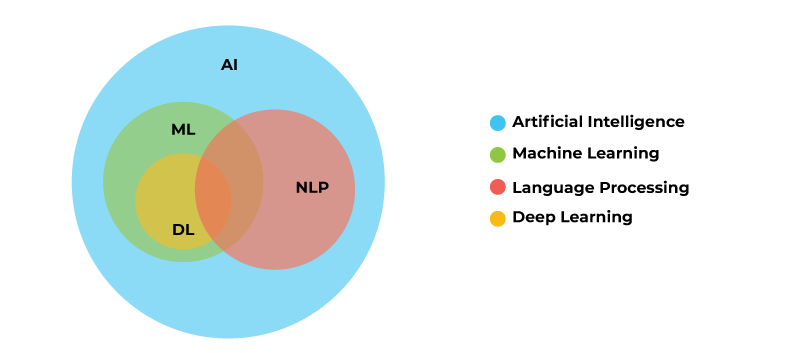
- 자연어 (Natural language) : 일상 생활에서 사용하는 보편적인 언어
- 자연어 처리 (Natural language processing, NLP) : 컴퓨터가 자연어를 처리하는 일 (예, 음성 인식, 번역, 요약, 분류 등)
(예) Chatbot의 여러 가지 기능
- Sentiment Analysis (텍스트에 녹아 있는 감정 또는 의견을 파악)
- Tokenization (단어의 최소한의 의미를 파악하는 쪼개기)
- Named Entity Recognition (텍스트로부터 주제 파악하기)
- Normalization (의도된 오타 파악하기)
- Dependency Parsing (문장 구성 성분의 분석)
Siri의 여러 가지 기능
- Feature Analysis (음성 데이터로부터 특징을 추출)
- Language Model (언어별로 갖고 있는 특성을 반영)
- Deep Learning (이미 학습된 데이터로부터 음성 신호 처리)
- HMM: Hidden Markov Model (앞으로 나올 단어 또는 주제의 예측)
- Similarity Analysis (음성 신호가 어떤 기준에 부합하는가?)
Papago의 여러 가지 기능
- Encoding (유사도 기반 자연어의 특징 추출)
- Time Series Modeling (문장을 시간에 따른 데이터로 처리)
- Attention Mechanism (번역에 필요한 부분에만 집중하기)
- Self-Attention (문장 사이의 상관관계 분석하기)
- Transformer (Attention 구조를 이용한 번역 원리) - 바로 위 두 개의 조합
2. 텍스트 전처리 과정
컴퓨터 및 컴퓨터 언어에서 자연어를 효과적으로 처리할 수 있도록 아래의 세 가지 "전처리" 과정을 거쳐야 함
토큰화, 정제 및 추출, 인코딩
1) 토큰화 (Tokenization)
문장을 형태소 단위(의미 부여가 가능한 단위)로 자르는 것
예) I / love / you / for / always / Do / n't / be / afraid
- 단어의 형태소에 따라 토큰화하는 거라 한국어의 토큰화는 매우 복잡함
- 단어 처리 방식이 패키지마다 다르므로 사용시 잘 유의해야 함
- 표준 토큰화: Treebank Tokenization
⌨️ Input
from nltk.tokenize import TreebankWordTokenizer tokenizer = TreebankWordTokenizer() text = "Model-based RL don't need a value function for the policy." print(tokenizer.tokenize(text))
⌨️ Output
['Model-based', 'RL', 'do', "n't", 'need', 'a', 'value', 'function', 'for', 'the', 'policy', '.']
- 문장 토큰화: 문장 단위로 의미를 나누기 (글이 매우 길 때)
- 잘 사용하지는 않음
- 잘 사용하지는 않음
2) 정제 및 추출 (Cleaning, stemming)
시간 및 메모리의 효율화를 위해 중요한 단어만 추출하는 것
예) I was wondering if you can help me on this problem.
✔️ 정제 (Cleaning)
데이터 사용 목적에 맞춰 노이즈를 제거 (예, 대문자→소문자, 출현 횟수가 적은 단어의 제거, 길이가 짧은 단어(관사, 지시대명사 등) 제거)
✔️ 추출 (Stemming)
어간(Stem) : 단어의 의미를 담은 핵심
접사(Affix) : 단어에 추가 용법을 부여 (복수 -s, 진행형 -ing, 명사형 -ness 등)
- Porter Algorithm (대표적인 Stemming 방법)
- 어간 추출 : 단어 품사 정보 포함 X
- 표제어 추출 (Lemmatization) : 단어 품사 정보 포함 O (is, are → be 동사)
- 불용어 (Stopword)
- 문장에서 대세로 작용하지 않는, 중요도가 낮은 단어
- 지워줄 수 있으면 지우는 게 좋음
⌨️ 불용어 제거 과정
from nltk nltk.download('stopwords') nltk.download('punkt') from nltk.corpus import stopwords from nltk.tokenize import word_tokenize input_sentence = "We should all study hard for the exam." stop_words = set(stopwords.words('english')) word_tokens = word_tokenize(input_sentence) result = [] for w in word_tokens: if w not in stop_words: result.append(w) print(word_tokens) print(result)
3) 인코딩 (Encoding)
남겨진 단어들을 숫자로 바꾸는 것
- 정수 인코딩 (1, 2, 3, ...)
- 자주 등장하는 단어면 작은 정수 할당하는 방식도 있음 (계산 효율적)
- 과정 : 딕셔너리 생성 → 빈도순 정렬 (Sorting)

-
원-핫 인코딩 (0, 1)
- 분류 문제에서는 원핫 인코딩을 사용하는 게 좋음 (cross entropy 계산을 위해서)
- 메모리를 많이 잡아먹기 때문에, 평상시에는 정수 인코딩을 사용하고 필요할 때 원핫 인코딩을 사용하는 걸 추천함
-
Word2vec 인코딩
- 단어의 유사성을 인코딩에 반영
- 인코딩 벡터가 비슷하다 = 단어가 유사하다
-
TF-IDF (Term Frequency - Inverse Document Frequency)
-
단어들의 중요한 정도를 가중치로 매기는 방법 ( : 특정 문서 번호, : 특정 단어 번호)
-
-
Padding (Zero-padding)
- 인코딩된 단어의 길이가 다르면 처리가 힘듦 (RNN은 처리 가능)
- 단어의 길이를 맞추기 위해 0을 넣어줌
3. 언어 모델 (Language Model)
1) 통계(확률) 기반 언어 모델(&Markov Chain)
-
Count-based Approximation
- Sparsity Problem : 보통 사용하는 문장은 상당히 희소성이 있음 (많은 단어의 조합으로 인해)
-
N-gram Language Model
- Sparsity problem을 위해 나온 대안
p(core | Deep Learning has become a),n=2: 뒤에서 n 번째 자리 단어까지만 참조함
-
한국어 언어 모델은 단어의 순서가 바껴도 문장의 의미는 동일한 경우가 많음
- Markov chain 참조
2) 인공 신경망 기반 언어 모델
4. 유사도 분석
1) 벡터 유사도: Cosine Metric
벡터 노름(np.linalg.norm())에 코사인을 곱한 것
얼마나 유사한지의 척도 (정반대의 경우 -1, 유사성이 없을 경우 0, 동일할 경우 1)
예시) [1, 1, 0] & [1, 0 -1]
→
2) 문장 유사도 분석
- Bag-of-Words (BoW) 개념 이용
- 단어별 출현 빈도수를 벡터화시켜 문장 간 유사도 계산
- 벡터 유사도: Euclidean Metric
- Levenshtein Distance
- 단어 사이의 거리를 나타내는 대표적인 척도 (단어 A를 단어 B로 수정하기 위한 최소 횟수 - 삽입, 삭제, 변경)
- Tabular method를 통해 직접 구할 수 있음
