MLDL 101
1.[NLP] 자연어처리 개요 (수정 중)
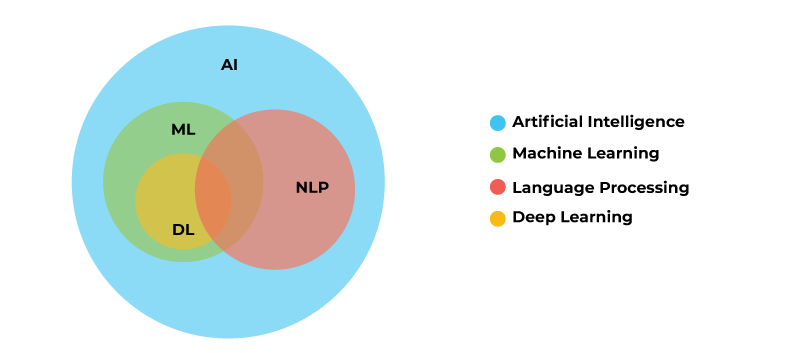
1. 자연어 처리 개요 자연어 (Natural language) : 일상 생활에서 사용하는 보편적인 언어 자연어 처리 (Natural language processing, NLP) : 컴퓨터가 자연어를 처리하는 일 (예, 음성 인식, 번역, 요약, 분류 등) > (예) Chatbot의 여러 가지 기능 Sentiment Analysis (텍스트에...
2.엔트로피와 지니 계수

머신러닝에서의 엔트로피와 지니 계수
3.ML 데이터 스케일링 정리
LabelEncoder, MinMaxScaler, StandardScaler , RobustScaler
4.파이프라인을 사용해보자
데이터 전처리와 모델 학습을 하나의 워크플로우로 결합하고, 하이퍼 파라미터 튜닝을 더 간편하게 수행할 수 있게하는 pipeline
5.교차 검증과 하이퍼 파라미터 튜닝에 있어서의 내 오해
K-fold CV와 하이퍼 파라미터 튜닝
6.파이프라인을 사용하면서 그리드 서치를 적용하기
제목 그대로
7.SVM은 국경 나누기
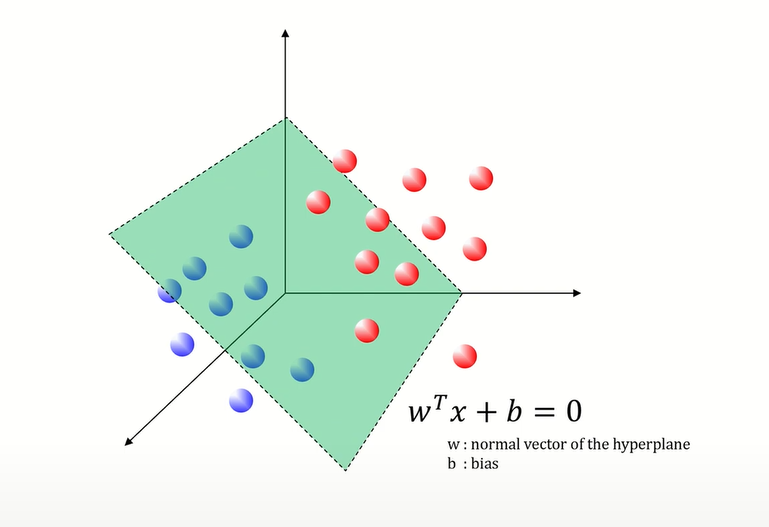
서포트 벡터 머신 (분류)
8.Mini-batch vs Fold

미니 배치(Mini-batch)와 데이터의 폴드(Fold)는 머신러닝의 학습 과정에서 다루는 데이터의 서브셋(subset)을 의미하지만, 사용 목적과 맥락이 다릅니다. 미니 배치 (Mini-batch): 미니 배치는 경사하강법을 사용할 때 전체 훈련 데이터셋을 더 작은 배치로 나누어 각 반복(iteration)에서 사용하는 데이터의 양을 의미합니다. ...
9.OOF vs k-fold cv
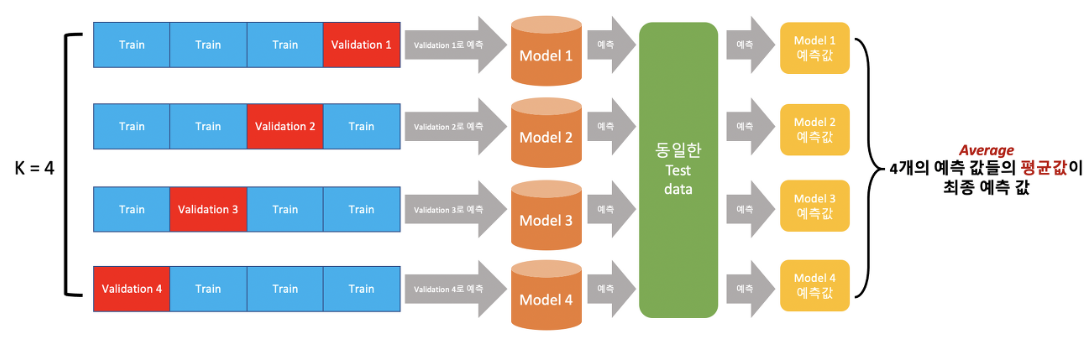
cross validation : 데이터 수가 적을 때 모델의 overfitting을 예방하기 위해 사용됨 ex) K-fold cross validation 의문 : 'Out-Of-Fold'와 'K-fold CV'에서의 'fold'는 같은 것? 답 : 비슷하다. 그러나 OOF 예측은 K-fold cv의 일부로서, 각 fold가 validati...
10.Loss function vs 성능 평가 지표 (loss function과 cost function의 차이)

Loss Function과 성능 평가 지표는 ML 모델의 오차를 측정하는 평가지만, 목적과 사용 방법에는 차이가 있다. Loss Function 모델의 학습(fit) 도중에 사용됨 train set에 사용 모델의 예측값과 실제값 사이의 차이 측정 이 차이(loss function)를 최소화하도록(=최적화되는 함수) 모델의 파라미터(가중치, 잔차)를...
11.여러가지 Metric(성능 평가 지표) 정리

1. 이진 분류(Binary Classification) 정확도(Accuracy) : 전체 샘플 중 올바르게 예측한 샘플의 비율 정밀도(Precision) : 양성 클래스(1)로 예측된 샘플 중 실제로 양성 클래스인 샘플의 비율 재현율(Recall, 민감도) : 실제 양성 클래스인 샘플 중 양성 클래스로 예측된 샘플의 비율 F1 점수(F1 Score) : ...
12.MLE vs Gradient Descent 그리고 log likelihood

MLE(Maximum Likelihood Estimation, 최대 우도 추정법)과 Gradient Descent는 모두 파라미터 추정법임 1. MLE 목표 : 주어진 데이터를 가장 잘 설명하는 파라미터(웨이트, 편차)를 찾는 것 주어진 데이터가 관찰될 확률(우도)을 최대화하는 파라미터는 무엇인가? 그러면 로그 우도(log likelihood)는 뭐지...
13.Transfer Learning, Fine Tuning

전이학습 (Transfer Learning) 사전학습된 모델(pretrained model)의 지식을 활용해 새로운 문제를 해결하는 방법 사전학습된 모델은 대규모 데이터셋(예, ImageNet, Wikipedia 등)을 기반으로 학습해, 일반적인 패턴을 잘 인식할 수 있는 능력을 갖고 있음 모델이 이미 학습한 일반적인 지식을 이용해 빠르게 적응하고 효율적...
14.Transfer Learning, Fine Tuning (with Keras)

VGG, ResNet, MobileNet
15.CNN(Convolutional Neural Network) basic

1. MLP의 한계 구조적 한계 MLP(fully-connected)는 층이 깊어지고 뉴런의 수가 많아지면 가중치 수가 급격히 늘어남 이는 학습해야 할 매개변수의 수가 많아져 오버피팅의 위험이 커지고, 계산 복잡도가 증가하는 한계가 됨 위치 민감성 MLP는 이미지의 특정 패턴의 위치에 민감함 즉, 인풋 이미지의 모든 정보를 일차원 벡터...
16.Bias, Variance
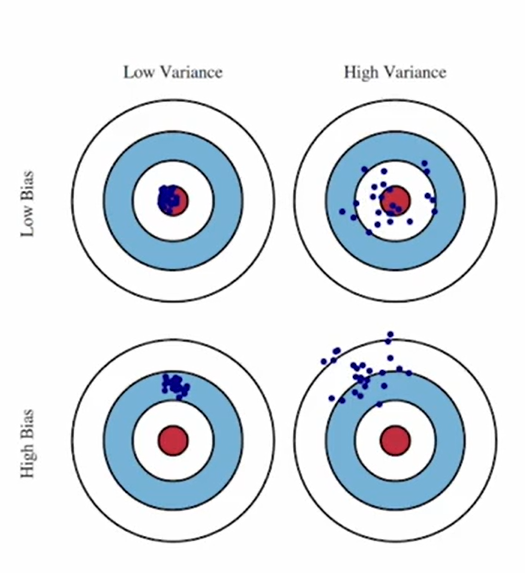
1. Bias $E(\hat{h} - f)$ Estimation(Trained model)과 True data distribution 차이의 평균치 모델의 가정 자체가 실제 데이터 분포가 다른 정도 Bias가 큰 모델은 아무리 잘 학습하더라도 true distribution을 정확하게 추정할 수 없음 모델 파라미터 수가 적을수록 bias는 커짐 ...
17.Learning Rate와 Hyperparameter
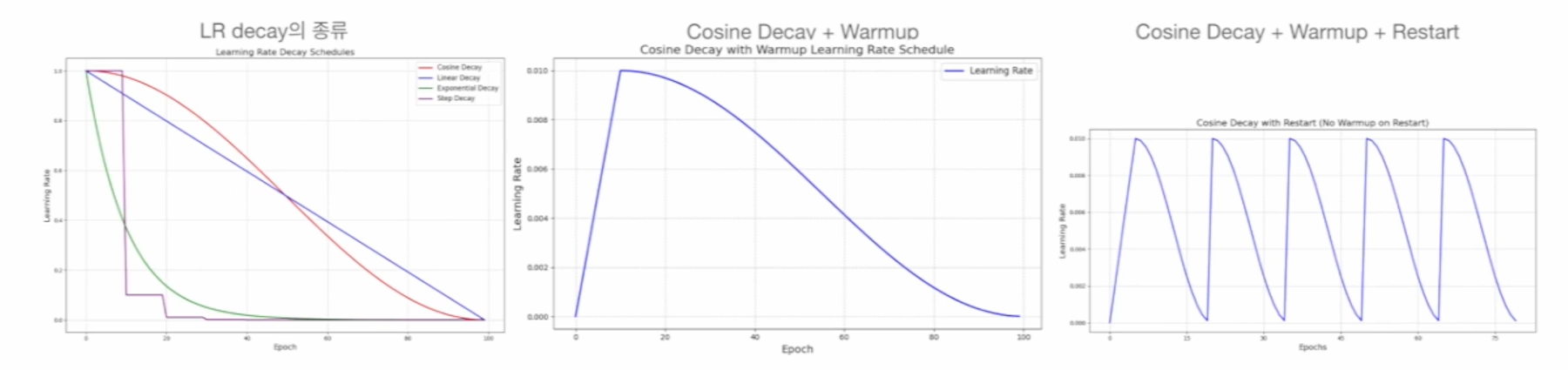
Learning Rate Scheduling Decay : 모델의 학습이 진행될수록 learning rate $\alpha$ (lr)를 작게 함 Cosine decay, Linear decay, Exponential decay, Step decay etc Warmup : 초기 학습 안정성을 위해 lr을 작은 값부터 시작해 서서히 증가시키는 것 Rest...