🐼 목 차 🐼
📖 웹 크롤링 (Web Crawling)
📖 정적 크롤링과 동적 크롤링
📖 BeautifulSoup와 Selenium 사용 예시 (프로젝트)
웹 크롤링 (Web Crawling)
- 웹 사이트를 자동으로 탐색해 정보를 수집하는 프로세스
- 웹 페이지의 HTML 코드를 분석하고 필요한 데이터를 추출해 데이터베이스나 파일에 저장하는 과정
- 크롤러(봇), 또는 스파이더라고 하는 프로그램이 인터넷을 탐색해 링크를 따라가고 정보를 수집함
- 주로 검색 엔진이나 가격 비교 웹 사이트 등에서 사용되며, 정보 수집, 분석, 모니터링, 예측 등 다양한 분야에서 활용됨
※ 웹 스크래핑(Web Scraping)?
스크래핑은 크롤링의 일부분으로 볼 수 있음.
즉, 크롤러가 웹 페이지를 찾아다니는 것은 크롤링이고, 그 중에서 웹 페이지의 데이터를 추출하는 과정이 스크래핑임.
정적 크롤링과 동적 크롤링
⭐ 정적 크롤링 (Static Crawling)
- 웹 페이지가 서버로부터 정적으로 제공되는 경우에 데이터를 수집하는 방법 (정적인 HTML 문서 기반)
- HTML 문서가 서버로부터 한 번에 전송되고, 클라이언트 측에서는 추가적인 자바 스크립트 실행이 없거나 제한적인 경우에 사용됨
- 사용법이 간단하고 직관적이며, 속도가 빠르지만 동적인 웹 페이지에서는 사용할 수 없음
- 주로 뉴스 기사, 블로그 포스트 등 수집에 사용
- 대표적으로, BeautifulSoup와 같은 라이브러리를 사용해 웹 페이지의 HTML을 파싱하고 데이터를 추출할 수 있음
- 그 외로는 requests, urllib 등이 있음
⭐ 동적 크롤링 (Dynamic Crawling)
- 웹 페이지가 클라이언트 측에서 자바 스크립트와 같은 스크립트를 사용해 동적으로 생성되는 경우에 데이터를 수집하는 방법
- 웹 페이지가 로드된 후에도 사용자 인터랙션에 따라 데이터가 동적으로 업데이트되는 경우에 사용됨
- 브라우저를 실제로 제어하기 때문에 JavaScript로 렌더링된 동적인 웹 페이지에서도 데이터를 추출할 수 있음. 그러나 브라우저를 제어한다는 이유로 실행 속도가 느림
- 주로 실시간 주식 가격, 소셜 미디어의 실시간 피드, 웹 어플리케이션의 동적 컨텐츠 등 수집에 사용
- 대표적으로, Selenium과 같은 웹 자동화 도구를 사용해 브라우저를 제어하고 JavaScript를 실행해 동적으로 생성되는 데이터를 수집할 수 있음
- 그 외로 chromedriver도 사용함
- 그 외로 chromedriver도 사용함
BeautifulSoup와 Selenium 사용 예시
🤔B 카페는 일부러 A 카페 근처에 입점하는 가?🤔
A 카페 근처에 B 카페가 있는 광경을 자주 볼 수 있음 서울에 있는 A, B 카페 지점들 정보를 BeautifulSoup와 Selenium을 사용해 긁어와, 진짜 그런지 Folium을 통한 지도 시각화로 확인해보자✔️ 사용할 라이브러리 임포트
from urllib.request import urlopen # 사이트에 http 요청을 보내고 응답 받는 기능 from bs4 import BeautifulSoup from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException #from tqdm import tqdm from tqdm import tqdm_notebook # 주피터 노트북에서는 위에 걸 써야하는데, 위에 거 맘에 안들어서 이거 씀 import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from bs4 import BeautifulSoup import time import pandas as pd
1. 서울시 A 카페 지점별 정보 크롤링
✔️ 구 리스트 받아오기
1 홈페이지 접속 → 2 매장 위치 찾기 페이지로 접속 → 3 '서울' 선택 → 4 여러 구 선택 → 5 지점 정보 스크래핑
프로세스 1부터 4까지는 Selenium을, 프로세스 5는 BeautifulSoup를 이용
# 프로세스 1 및 2 driver = webdriver.Chrome("../driver/chromedriver.exe") driver.get("A 카페 홈페이지") # A 카페 홈페이지(매장 찾기 페이지) wait = WebDriverWait(driver, 3) # 프로세스 3 seoul_button = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'))) seoul_button.click() # A 카페 홈페이지의 '매장 찾기'에서 서울 카테고리 선택 # 프로세스 4 gus = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#mCSB_2_container > ul > li'))) gu_list = [] for idx, gu in enumerate(gus): gu_list.append(gu.text) print(idx, end='') print(' ', gu.text) # 왜 '은평구', '종로구', '중구', '중랑구'는 안 나올까? 우선 이 구들 제외하고 크롤링해보자
프린트 결과)
0 전체
1 강남구
2 강동구
3 강북구
4 강서구
5 관악구
6 광진구
7 구로구
8 금천구
9 노원구
10 도봉구
11 동대문구
12 동작구
13 마포구
14 서대문구
15 서초구
16 성동구
17 성북구
18 송파구
19 양천구
20 영등포구
21 용산구
22
23
24
25 스크롤 위치에 따라 22-25번의 구가 나타나지 않거나, 0-3번 구가 나타나지 않음;;
Selenium을 통해 스크롤바 위치를 설정해도 같은 문제 계속 발생한다..
매장은 다른 구에도 충분히 많으니 어쨌든 무시하고 진행해보자
✔️ 구 별 지점 정보 스크래핑
# 각 구별로 들어가 정보 긁어오기 a_all_info = [] # 데이터 받아올 빈 리스트 생성 for i in tqdm_notebook(range(1, len(gus)-4)): # 구 선택 gu = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, f'#mCSB_2_container > ul > li:nth-child({i+1})'))) gu.click() time.sleep(5) # 페이지 갱신 대기 # 페이지 소스 가져오기 gu_html = driver.page_source a_store = BeautifulSoup(gu_html, 'html.parser') # 선택한 구의 a 카페 매장 목록 추출 stores = a_store.find_all('li', class_='quickResultLstCon') for store in stores: name = store['data-name'] lat = store['data-lat'] lon = store['data-long'] address = store.find('p', class_='result_details').get_text(strip=True) store_info = { 'name': name, 'lat': lat, 'lng': lon, 'address': address } a_all_info.append(store_info) print(f'{gu_list[i]} 크롤링 완료') # '지역 검색' 버튼을 클릭하여 상위 페이지로 돌아가기 region_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a'))) region_search_button.click() time.sleep(3) # 페이지 갱신 대기 0 seoul_button = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'))) seoul_button.click()
프린트 결과)
100% 21/21 [03:11<00:00, 9.14s/it]
강남구 크롤링 완료
강동구 크롤링 완료
강북구 크롤링 완료
강서구 크롤링 완료
관악구 크롤링 완료
광진구 크롤링 완료
구로구 크롤링 완료
금천구 크롤링 완료
노원구 크롤링 완료
도봉구 크롤링 완료
동대문구 크롤링 완료
동작구 크롤링 완료
마포구 크롤링 완료
서대문구 크롤링 완료
서초구 크롤링 완료
성동구 크롤링 완료
성북구 크롤링 완료
송파구 크롤링 완료
양천구 크롤링 완료
영등포구 크롤링 완료
용산구 크롤링 완료print(a_all_info)
프린트 결과)
[{'name': '매장명1',
'lat': '37.어쩌고',
'lng': '127.어쩌고',
'address': '서울특별시 강남구 어쩌고'},
{'name': '매장명2',
'lat': '37.어쩌고',
'lng': '127.어쩌고',
'address': '서울특별시 강남구 어쩌고'},
{'name': '매장명3',
'lat': '37.어쩌고',
'lng': '127.어쩌고',
'address': '서울특별시 강남구 어쩌고'},....✔️ 데이터프레임화 및 기타 처리
df_sb = pd.DataFrame(a_all_info) import re df_a['address'] = df_a['address'].apply(lambda x: re.sub(r"\s*\([^)]*\)\s*\d+-\d+", "", x)) df_a['strict'] = df_a['address'].apply(lambda x: re.search(r'(\w+구)', x).group(1) if re.search(r'(\w+구)', x) else '') df_a = df_a[['name', 'strict', 'address', 'lat', 'lng']] df_a.to_csv('./서울_구별_a카페_정보.csv') driver.quit()
2. 서울시 B 카페 지점별 정보 크롤링
1 홈페이지 접속 → 2 매장 위치 찾기 페이지로 접속 → 3 검색창에 '구이름' 검색 → 4 구별 지점 정보 스크래핑
프로세스 1부터 3까지는 Selenium을, 프로세스 4는 BeautifulSoup를 이용
✔️ 홈페이지 접속
# 프로세스 1 및 2 driver = webdriver.Chrome("../driver/chromedriver.exe") driver.get("B 카페 홈페이지") # B 카페 홈페이지(매장 찾기 페이지) wait = WebDriverWait(driver, 3) gu_list = gu_list [1:22] gu_list.extend(['용산구', '은평구', '중구', '중랑구']) # A 카페 구 리스트 스크래핑에 실패한 구 추가
✔️ 구 리스트 정리 및 검색 엔진 접근
# 프로세스 3 res = driver.find_element_by_css_selector('#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a') res.click() driver.implicitly_wait(5) # 입력 필드를 찾아 키 입력 input_field = driver.find_element(By.ID, "keyword") input_field.clear() # 검색창 클리어 b_all_info = [] # 서울시 구를 세 리스트로 나누고, 강서구와 중구는 여러 동으로 나눔 # 검색 결과가 너무 많아 에러가 발생하는 것을 방지하기 위해 구 리스트를 나눈 것 (롤백 용도) gu_list1 = ['강남구', '강동구', '강북구', '공항동', '방화동', '가양동', '발산동', '등촌동', '염창동', '화곡동', '관악구', '광진구', '구로구', '금천구'] gu_list2 = ['노원구', '도봉구', '동대문구', '동작구', '마포구', '서대문구', '서초구', '성동구', '성북구', '송파구', '양천구', '영등포구', '용산구', '은평구'] gu_list3 = ['중림동', '회현동', '명동', '광희동', '필동', '신당동', '다산동', '황학동', '중랑구']
✔️ 구별 지점 정보 스크래핑
# gu_list2에 대한 크롤링 (예시) try: current_info = list(b_all_info) # 에러 발생시 기존으로 롤백 for i in tqdm_notebook(range(len(gu_list2))): try: input_field.send_keys(gu_list2[i]) # 검색어 입력 driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click() # 검색 버튼 클릭 time.sleep(1.2) # 페이지 소스 가져오기 gu_html = driver.page_source b_store = BeautifulSoup(gu_html, 'html.parser') places_list = b_store.find_all('ul', id='placesList') # 페이지 소스 가져오기 gu_html = driver.page_source b_store = BeautifulSoup(gu_html, 'html.parser') # 현재 구의 b 카페 목록 추출 stores = b_store.find_all('li', class_='item') for j in tqdm_notebook(range(len(stores))): time.sleep(1.2) onclick = stores[j].find('a')['onclick'] lng = onclick.split("'")[1] lat = onclick.split("'")[3] store_name = stores[j].find('dt').get_text().strip() store_address = stores[j].find('dd').get_text().strip() store_info = { 'name': store_name, 'lat': lat, 'lng': lng, 'address': store_address } b_all_info.append(store_info) print(f'{gu_list2[i]} 크롤링 완료') except UnexpectedAlertPresentException: # 에러 발생해도 다음 프로세스로 넘어가게 하기 alert = driver.switch_to.alert alert.accept() print(f'알림 처리됨: {alert.text}') continue # 다음 구로 넘어감 finally: # 입력 필드 클리어 및 다음 검색 준비 input_field.clear() time.sleep(1.2) input_field.clear() time.sleep(1.2) except Exception as e: # 에러가 발생한 경우 이전 상태로 롤백 print(f"에러 발생: {e}") ed_all_info = current_info print("롤백") finally: # 입력 필드 클리어 및 다음 검색 준비 input_field.clear() time.sleep(1.2)
✔️ 데이터프레임화 및 기타 처리
df_b = pd.DataFrame(b_all_info) df_b['strict'] = df_b['address'].apply(lambda x: re.search(r'(\w+구)', x).group(1) if re.search(r'(\w+구)', x) else '') df_b = df_b[['name', 'strict', 'address', 'lat', 'lng']] df_b.to_csv('./서울_구별_b카페_정보.csv') driver.quit()
3. Folium을 통한 지도 시각화 및 가설 검증
내 가설을 검증하는 방식은 다양하지만 (물리적 거리 측정, 주소로 단순 유추 등)
나는 Folium을 통해 지도에 카페 위치를 점찍어놓고 단순히 육안으로 검증해보려고 함
✔️ 위, 경도 데이터 결측치 처리
print(df_a['lat'].min()), print(df_a['lat'].max()) print(df_a['lng'].min()), print(df_a['lng'].max()) print(df_b['lat'].min()), print(df_b['lat'].max()) print(df_b['lng'].min()), print(df_b['lng'].max())
프린트 결과)
(lat 37.어쩌고
dtype: object,
lat 37.어쩌고
dtype: object)
(lng 126.어쩌고
dtype: object,
lng 127.어쩌고
dtype: object)
('0', '9')
('0', '해당 지점 주소가 나음')B 카페 위치정보 데이터 결측치를 Google Maps API를 통해 새로운 정보로 대체
import googlemaps gmaps_key = "내api" gmaps = googlemaps.Client(key=gmaps_key) # 주소로부터 위도와 경도를 검색하고 데이터프레임 업데이트 def update_lat_lng(df): # 위도와 경도를 저장할 빈 리스트 latitudes = [] longitudes = [] # 각 주소에 대해 geocode 수행 for address in df['address']: result = gmaps.geocode(address, language="ko") if result: geometry = result[0].get('geometry') lat, lng = geometry['location']['lat'], geometry['location']['lng'] latitudes.append(lat) longitudes.append(lng) else: # Geocode가 결과를 반환하지 않을 경우, NaN 처리 latitudes.append(np.nan) longitudes.append(np.nan) # 데이터프레임에 새로운 위도와 경도 정보 업데이트 df['lat'] = latitudes df['lng'] = longitudes update_lat_lng(df_b)
결측치 대체 여부 확인
df_b['lat'].min(), df_b['lat'].max() df_b['lng'].min(), df_b['lng'].max()
프린트 결과)
(35.어쩌고, 38.어쩌고)
(126.어쩌고, 129.어쩌고정상화됨!!
✔️ Folium을 통한 시각화
A 카페 위치를 전부 찍고 A 카페로부터 반경 150m의 원을 그림
그리고 B 카페 위치를 전부 찍음
그런데 그 A 카페 150m 반경 안에 드는 B 카페는 색을 파란색 포인트로,
들지 않는 카페는 빨간색 포인트로 찍어봤음
import folium import json from geopy.distance import geodesic # 기본 맵 객체 생성 m = folium.Map( location=[37.544564958079896, 127.05582307754338], # 중심 좌표 설정 zoom_start=12, # 초기 확대 수준 tiles="OpenStreetMap" # 타일 스타일 ) # a 카페 모든 지점에 대해 마커 추가 for a in range(len(df_a)): tooltip_a = folium.Tooltip(f'<span style="color: black;"><i>{df_a["name"].iloc[a].values[0]}</i></span>') folium.CircleMarker( location=[ed_row['lat'], ed_row['lng']], radius=3, tooltip=f'<span style="color: black;"><i>{ed_row["name"]}</i></span>', color="lightgray", fill=True, fill_color=color, fill_opacity=1.0 ).add_to(m) # 각 지점을 중심으로 하는 원 추가 folium.Circle( location=[df_a['lat'].iloc[a], df_a['lng'].iloc[a]], radius=500, # 반경 500미터 color='gray', # 원의 선 색상 fill=True, # 원 내부를 채움 fill_color='lightblue', # 원 내부 색상 fill_opacity=0.4 # 원 내부 채우기의 불투명도 ).add_to(m) # b 카페 모든 지점에 대해 CircleMarker 추가 for b_index, b_row in df_b.iterrows(): in_radius = False for a_index, a_row in df_a.iterrows(): distance = geodesic((a_row['lat'], a_row['lng']), (b_row['lat'], b_row['lng'])).meters if distance <= 150: # a 매장으로부터 반경 150m 짜리 원 그리기 in_radius = True break # b 카페 지점을 다른 색으로 표시 color = 'red' if in_radius else 'blue' folium.CircleMarker( location=[b_row['lat'], b_row['lng']], radius=3, tooltip=f'<span style="color: black;"><i>{b_row["name"]}</i></span>', color=color, fill=True, fill_color=color, fill_opacity=1.0 ).add_to(m) m
프린트 결과)
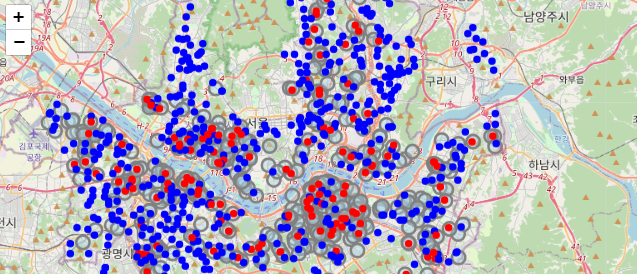
4. 결론
B 카페는 진짜 A 카페 매장 근처에 입점하는가?
- 개수(눈으로 봤을 때) : 파란색 포인트 >> 빨간색 포인트
- 즉, 근처에 입점한 경우가 많다!
- 그러나 우리나라에는 카페가 너무 많기 때문에, 어딜가든 카페를 볼 수 있다. B 카페가 아닌 다른 카페 또한 A 카페 근처에 입점하는 것처럼 보일 수 있다.
- B 카페가 A 카페 근처에 '무조건' 입점한다고 볼 수는 없음 (A 카페 없이 B 카페만 있는 지역도 있기 때문)
코드를 급히 짜보느라 매우 번잡하지만.....
혹시나 참고할 분들이 계신다면 참고하셔도 됩니다....
