프로젝트 소개
🤔 서울시 소재 셀프 주유소는 비셀프 주유소에 비해 더 저렴할까? (가설)🤔
셀프 주유소는 직원의 서비스를 요구하지 않으므로 더 저렴할 거 같다.
진짜 그런지 서울에 있는 주유소 정보들을 opinet에서 scrapping한 후, 여러가지 기법으로 증명해보자!
분석 프로세스
- 가설 설정
- 타겟 웹 페이지 탐색
- 스크래핑을 통해 얻고 싶은 정보 정리하기
- 웹 크롤링을 통해 원하는 정보를 스크래핑하는 자동화 코드 생성하기
- 정리한 정보를 데이터프레임화 및 csv 파일로 저장
- 여러 가지 기법을 활용한 가설 검증
- 결론
1. 가설 설정
2. 타겟 웹 페이지 탐색
한국석유공사 오피넷 - 이동하기
내가 원하는 지역의 주유소 목록과 주유 정보를 보기 위해서는 어떤 과정을 거쳐야 하는가?
- '메인 페이지 > 싼 주유소 찾기 > 지역별' 순으로 접속하기
- 지역을 '서울'로 고정한 후,
- 서울시 구 별로 데이터를 순회해보았음
3. 스크래핑을 통해 얻고 싶은 정보 정리하기
- 주유소 이름, 주유소 주소, 주유소 브랜드, (보통)휘발유 및 경유 가격, 셀프 주유 여부, 부가 서비스 유무(세차장, 충전소, 경정비, 편의점, 24시간 영업)
- 지도 시각화를 위한 주유소 위도 및 경도, 주유소 소재 구
4. 웹 크롤링 및 스크래핑 자동화 코드 생성하기
아래의 코드는 필요한 라이브러리를 이미 임포트했고, Selenium을 통해 타겟 웹 페이지에 접속했다는 가정 하의 코드임
✔️ '서울' 선택(고정) 및 서울 내 구 리스트 생성
seoul_button = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="SIDO_NM0"]/option[2]'))).click() html = driver.page_source soup = BeautifulSoup(html, "html.parser") gu_list = [option.text for option in soup.find('select', {'id': 'SIGUNGU_NM0'}).find_all('option')[1:]]
프린트 결과)
['강남구', '강동구', '강북구', '강서구', '관악구', '광진구', '구로구', '금천구',
'노원구', '도봉구', '동대문구', '동작구', '마포구', '서대문구', '서초구', '성동구',
'성북구', '송파구', '양천구', '영등포구', '용산구', '은평구', '종로구', '중구', '중랑구']✔️ 정보 스크래핑 자동화 코드
oil_station_info = [] for gu_name in tqdm(gu_list): # 구 선택 gu_selector = f'//*[@id="SIGUNGU_NM0"]/option[@value="{gu_name}"]' wait.until(EC.element_to_be_clickable((By.XPATH, gu_selector))).click() # 구 클릭 stations = driver.find_elements_by_css_selector('#body1 > tr') # 주유소 목록 추출 totCnt = driver.find_element_by_css_selector("#totCnt").text # '검색 결과' 옆 주유소 개수가 gu_totalCnt = driver.find_elements_by_css_selector("#body1 > tr") # '검색 결과'에 나오는 테이블(주유소) 수와 일치하는지 확인 print(gu_name, totCnt, len(gu_totalCnt)) wait.until(lambda d: d.execute_script('return document.readyState') == 'complete') # 페이지 갱신 대기 for idx in tqdm(range(len(stations))): detail_selector = f'#body1 > tr:nth-child({idx+1}) > td.rlist > a' # 주유소 개별 클릭 driver.find_element_by_css_selector(detail_selector).click() name = driver.find_element_by_css_selector('.header #os_nm').get_attribute('innerText') # 주유소 이름 gasoline = driver.find_element_by_css_selector('#b027_p').get_attribute('innerText') # 휘발유 가격 diesel = driver.find_element_by_css_selector('#d047_p').get_attribute('innerText') # 경유 가격 brand = driver.find_element_by_css_selector('#poll_div_nm').get_attribute('innerText') # 주유소 브랜드 car_wash = 'N' if '_off' in driver.find_element_by_css_selector('.service #cwsh_yn').get_attribute('src').split('/')[-1] else 'Y' # 세차장 유무 lpg_yn = 'N' if '_off' in driver.find_element_by_css_selector('.service #lpg_yn').get_attribute('src').split('/')[-1] else 'Y' # 충전소 유무 maint_yn = 'N' if '_off' in driver.find_element_by_css_selector('.service #maint_yn').get_attribute('src').split('/')[-1] else 'Y' # 경정비 유무 cvs_yn = 'N' if '_off' in driver.find_element_by_css_selector('.service #cvs_yn').get_attribute('src').split('/')[-1] else 'Y' # 편의점 유무 sel24_yn = 'N' if '_off' in driver.find_element_by_css_selector('.service #sel24_yn').get_attribute('src').split('/')[-1] else 'Y' # 24시간 영업 유무 try: driver.find_element_by_css_selector('#self_icon').get_attribute('alt') is_self = 'Y' # 셀프 주유 여부 except: is_self = 'N' # address address = driver.find_element_by_css_selector('#rd_addr').get_attribute('innerText') # 주유소 주소 # gu gu = address.split()[1] # 어느 구에 해당 주유소가 있는지 # lat, lng tmp = gmaps.geocode(address, language='ko') lat = tmp[0].get('geometry')['location']['lat'] # 주유소 위도 lng = tmp[0].get('geometry')['location']['lng'] # 주유소 경도 oil_station_info.append({ 'name': name, 'address': address, 'brand': brand, 'is_self': is_self, 'gasoline': gasoline, 'diesel': diesel, 'car_wash': car_wash, 'charging_station': lpg_yn, 'car_maintenance': maint_yn, 'cvs': cvs_yn, '24_hour': sel24_yn, 'gu': gu, 'lat': lat, 'lng': lng }) print(f'{gu} - {idx}. {name} // 완료') time.sleep(0.5) print('=====================================') print() time.sleep(0.5) print('******* 전체 주유소 스크래핑 완료 *******') driver.quit() df = pd.DataFrame(oil_station_info) df.tail()
프린트 결과 생략
5. 정리한 정보를 데이터프레임화 및 csv 파일로 저장
df['lat'].min(), df['lat'].max() # 위도 이상치 x df['lng'].min(), df['lng'].max() # 경도 이상치 x df.columns df.info() df.to_csv('./서울_구별_주유소_정보.csv', encoding='utf-8)
6. 여러 가지 기법을 활용한 가설 검증
# 서울시 셀프, 비셀프 주유소 개수 df['is_self'].value_counts()
프린트 결과)
is_self
Y 273
N 160
Name: count, dtype: int64서울시에는 셀프 주유소가 더 많다.
- 단순 시각화를 통한 검증
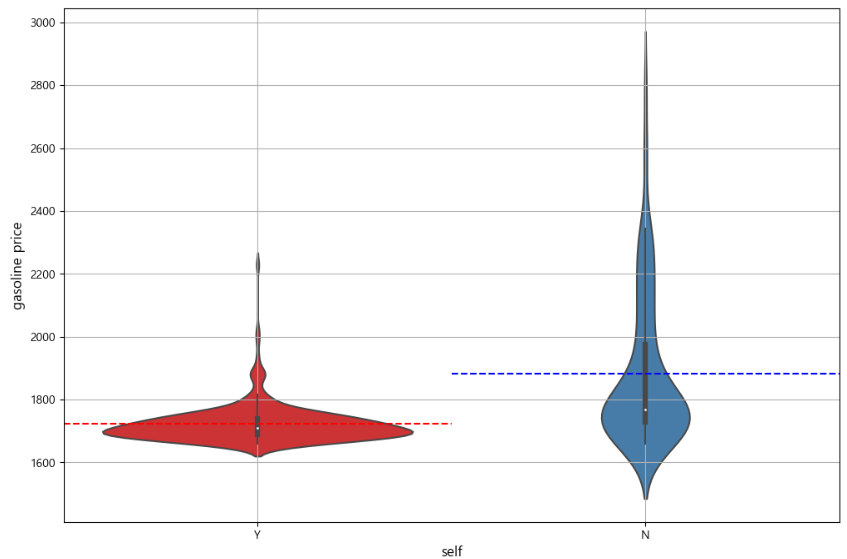
gasoline_mean = df.groupby('is_self')['gasoline'].mean() diesel_mean = df.groupby('is_self')['diesel'].mean() # 휘발유 plt.figure(figsize=(12, 8)) sns.violinplot(x="is_self", y="gasoline", data=df, palette="Set1") plt.axhline(gasoline_mean['Y'], color='red', linestyle='--', xmax=0.5, xmin=0) plt.axhline(gasoline_mean['N'], color='blue', linestyle='--', xmax=1, xmin=0.5) plt.xlabel('self', fontsize=12) plt.ylabel('gasoline price', fontsize=12) plt.grid(True) plt.show()
프린트 결과)
# 경유 plt.figure(figsize=(12, 8)) sns.violinplot(x="is_self", y="diesel", data=df, palette="Set1") plt.axhline(diesel_mean['Y'], color='red', linestyle='--', xmax=0.5, xmin=0) plt.axhline(diesel_mean['N'], color='blue', linestyle='--', xmax=1, xmin=0.5) plt.xlabel('self', fontsize=12) plt.ylabel('diesel', fontsize=12) plt.grid(True) plt.show()
프린트 결과)
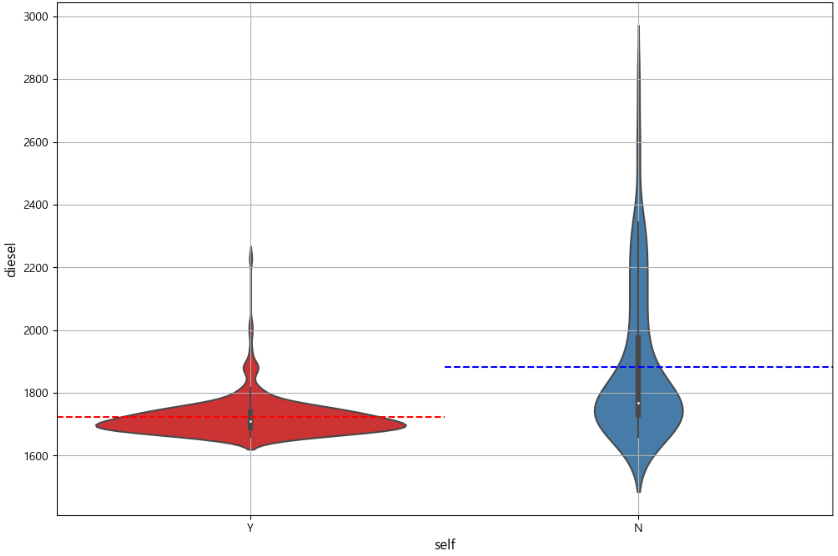
비셀프 주유소의 기름 가격 분포가 더 넓지만, 전반적으로 셀프 주유소 가격이 더 저렴함
- 통계 검정을 활용한 검증 (맨-휘트니 U 검정)
df_y = df[df['is_self'] == 'Y'] # 셀프 주유소 df_n = df[df['is_self'] == 'N'] # 비셀프 주유소 print(stats.mannwhitneyu(df_y['gasoline'], df_n['gasoline'])) print(stats.mannwhitneyu(df_y['gasoline'], df_n['gasoline']))
프린트 결과)
MannwhitneyuResult(statistic=9636.0, pvalue=2.7162145942252965e-22)
MannwhitneyuResult(statistic=9636.0, pvalue=2.7162145942252965e-22) # 왜 둘이 똑같지?휘발유와 경유 모두 셀프 주유 가능 여부에 따른 기름값 차이가 있다. (통계적으로 유의하다)
그러나 정규화, 등분산화 등을 통해 통계적 결과에 대한 유의성을 더 높일 필요가 있다.
- 지도 시각화를 통한 검증 (프린트 결과 생략)
# 가장 비싼 휘발유 주유소 10개 df.sort_values(by="gasoline", ascending=False).head(10) # 가장 싼 휘발유 주유소 10개 df.sort_values(by="gasoline", ascending=True).head(10) # 가장 비싼 경유 주유소 10개 df.sort_values(by="diesel", ascending=False).head(10) # 가장 싼 경유 주유소 10개 df.sort_values(by="diesel", ascending=True).head(10) gu_gas_data = pd.pivot_table(data=df, index="gu", values="gasoline", columns="is_self", aggfunc=np.mean) gu_gas_data['price_diff'] = gu_gas_data['N'] - gu_gas_data['Y'] gu_ds_data = pd.pivot_table(data=df, index="gu", values="diesel", columns="is_self", aggfunc=np.mean) gu_ds_data['price_diff'] = gu_ds_data['N'] - gu_ds_data['Y'] my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="OpenStreetMap") folium.Choropleth( geo_data=geo_str, data=gu_gas_data, columns=[gu_gas_data.index, "price_diff"], key_on="feature.id", fill_color="Yl", ).add_to(my_map) my_map # 용산구에는 셀프 주유소가 없음 (셀프 유무에 따른 가격 비교 불가) my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="OpenStreetMap") folium.Choropleth( geo_data=geo_str, data=gu_ds_data, columns=[gu_ds_data.index, "price_diff"], key_on="feature.id", fill_color="PuRd" ).add_to(my_map) my_map # 용산구에는 셀프 주유소가 없음 (셀프 유무에 따른 가격 비교 불가)
4. 결론
서울시 소재 셀프 주유소는 비셀프 주유소에 비해 더 저렴할까?
- 셀프 주유소가 비셀프 주유소에 비해 더 저렴한 경향이 있다!
- 휘발유와 경유 모두, 셀프 주유소의 기름 가격의 분포가 다양하지만, 셀프 주유소가 더 저렴하다.
- 통계 검정 결과, 휘발유와 경유 모두 셀프 여부에 따른 가격 차이가 통계적으로 유의하다. 그러나 정규화, 등분산화를 통해 통계적 유의성을 더 높일 필요가 있다.
- 지도 시각화 결과, 용산구 > 강남구, 중구, 종로구 > 영등포구, 성동구, 강동구 순으로 기름 가격이 비싸다.
- 그러나 전반적으로 모든 구에서 셀프 주유소가 더 저렴하다. (용산구에는 셀프 주유소가 없어서 가격 비교 불가함)

적당히 공부한 거 정리하는 곳