
MY SQL
BETWEEN <> and
create table sample200(no int);
insert into sample200 values(1);
insert into sample200 values(2);
insert into sample200 values(3);
insert into sample200 values(4);
insert into sample200 values(5);
insert into sample200 values(6);
insert into sample200 values(7);
select * from sample200 where no between 3 and 5; -- 3 4 5 출력
select * from sample200 where no >=3 and no <=5; -- 3 4 5 출력between ~ and ~: and를 기준으로 왼쪽 수 이상 오른쪽 수 이하 출력 <> and와 같은 역할
테이블 제약 - primary key / unique key
alter table ~ modify / add를 이용해 제약
-
부모 테이블에서 참조될 열은 반드시 유일성(UNIQUE KEY, PRIMARY KEY)을 가진다.)등이 있다.
-
자식 테이블 측에서는 외부키(FOREIGN KEY)를 지정해 부모 테이블을 참조한다.
데이터 정합성 : 어떤 데이터들이 값이 서로 일치함.
정합성은 데이터가 서로 모순 없이 일관되게 일치해야 함을 의미
- 테이블 작성시 제약 정의
-
CREATE TABLE, 로 테이블을 작성할 때 제약을 같이 정의한다. >> ALTER TABLE로 제약을 지정하거나 변경 가능
- NOT NULL 제약 등 하나의 열에 대해 설정하는 제약은 열을 정의할 때 지정한다.
CREATE TABLE sample631(
a INTEGER NOT NULL,
#b INTEGER NOT NULL,
b INTEGER NOT NULL UNIQUE, # PRIMARY KEY로 지정한게 없을 시 PRIMARY KEY가 된다
c VARCHAR(30)
);
DESC sample631;unique : 중복을 허용하지 않지만, null은 허용한다.
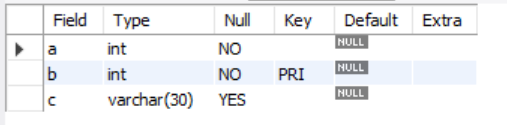
- a 열에는 NOT NULL 제약이 걸려있고, b열에는 not null제약과 unique제약이 걸려있다.
이렇게 열에 대해 정의하는 제약을 열 제약 이라 한다. 한 개의 제약으로 복수의 열에 제약을 설정하는 경우를 테이블 제약 이라한다.
primary key
-
유일한 레코드를 만들려면 다른 컬럼과 구별하고자 특별한 속성을 설정할 때 사용한다.
-
특징
- 값이 중복되지 않는다.
- 반드시 값을 입력해야 한다.
- 테이블 데이터의 고유 인식번호(ID)
unique key(고유 키)
-
특징
- 값이 중복되지 않는다.
- 값을 입력하지 않아도 된다.
- 중복되면 안되는 테이터(주민등록번호, 군번 등)
- 테이블에 '테이블 제약' 정의하기
CREATE TABLE sample631(
a INTEGER NOT NULL,
#b INTEGER NOT NULL,
b INTEGER NOT NULL UNIQUE, # PRIMARY KEY로 지정한게 없을 시 PRIMARY KEY가 된다
c VARCHAR(30)
);
DESC sample631;- 열 제약 추가
-
기존 테이블에도 나중에 제약을 추가할 수 있다. 이때 열 제약과 테이블 제약은 다른 방법으로 추가한다.
-
열 제약을 추가할 경우 ALTER TABLE로 열 정의를 변경할 수 있다.
- 만약 c 열에 NULL 값이 존재한다면 ALTER TABLE 명령은 에러가 발생한다.
c열에 not null 제약 걸기
ALTER TABLE sample631 MODIFY c VARCHAR(30) NOT NULL;
DESC sample631;- not null제약조건을 추가하는것
- 테이블 제약 추가하기
-
기본키는 테이블에 하나만 설정할 수 있다. 이미 기본키가 설정되어 있는 테이블에 추가로 기본키를 작성할 수는 없다.
- 열 제약을 추가할 때와 마찬가지로 기존의 행을 검사해 추가할 제약을 위반하는 데이터가 있으면 에러가 발생한다.
ALTER TABLE sample631 ADD CONSTRAINT PRIMARY KEY(a); # constraint를 명시해 제약조건을 정의하고있을을 명시
DESC sample631;- 제약키 조회 :
SELECT constraint_name, constraint_type FROM information_schema.table_constraints WHERE table_name = 'sample631';
c열에 제약 삭제하기
ALTER TABLE sample631 MODIFY c VARCHAR(30);
DESC sample631;- 테이블 제약은 ALTER TABLE의 DROP 하부명령으로 삭제할 수 있다.
테이블 제약 삭제하기 - 기본 키 삭제
ALTER TABLE sample631 DROP PRIMARY KEY;
DESC sample631;기본키 primary key
테이블의 행 한 개를 특정할 수 있는 검색키이다.
CREATE TABLE sample634(
p INTEGER NOT NULL,
a VARCHAR(30),
PRIMARY KEY(p) # sample 634의 기본키로 설정
);
INSERT INTO sample634 VALUES(1, '첫째줄');
INSERT INTO sample634 VALUES(2, '둘째줄');
INSERT INTO sample634 VALUES(3, '셋째줄');- 기본키로 지정할 열은 NOT NULL 제약이 설정되어 있어야 한다. >> 따로 안해도 기본키로 선언하면 알아서 변경
- 기본키 제약이 설정된 테이블에서는 기본키로 검색했을 때 복수의 행이 일치하는 데이터를 작성할 수 없다. >> 기본키의 열이 중복될 수 없다.
sample634에 중복되는 행 추가 에러 예시
-
INSERT INTO sample634 VALUES(2, '넷째행');: 기본키가 2인개 이미 위에서 넣어줬는데 또 넣으려해서 중복되어 에러 -
INSERT INTO sample634 VALUES(2, '넷째행');: 이미 있는 기본키의 값으로 업데이트하려해서 에러열을 기본키로 지정해 유일한 값을 가지도록 하는 구조가 바로 기본키 제약 >> 유일성 제약이라 불리기도 함
기본키 제약이 설정된 열에는 중복된 값을 저장할 수 없다!
- 복수의 열로 기본키 지정하기
- 기본 키를 구성하는 열은 복수라도 상관없다.
- 복수의 열을 기본키로 지정했을 경우, 키를 구성하는 모든 열을 사용해서 중복하는 값이 있는지 없는지를 검사한다.
CREATE TABLE sample635(
a int,
b int,
CONSTRAINT PRIMARY KEY(a, b) # primary key로 설정해서 자동으로 not null이 기본 설정으로 걸려있다.
); # constraint는 테이블의 데이터에 적용되는 조건을 정의하는데 사용되는 규칙
DESC sample635;
INSERT INTO sample635 values(1, 1);
INSERT INTO sample635 values(1, 2);
INSERT INTO sample635 values(1, 3);
INSERT INTO sample635 values(2, 1);
INSERT INTO sample635 values(2, 2);- a열만을 봤을 때는 중복하는 값이 있지만, b열이 다르면 키 전체로서는 중복하지 않는다고 간주되기 때문에 기본키 제약에 위반되지 않는다.
- 만약 이 상태에서 키가 완전히 동일한 데이터값으로 INSERT 명령을 실행하면 기본키 제약에 위반된다.
INSERT INTO sample635 values(1, 3);>> 중복된 데이터 에러
제약 문제
-
다음 sample632 테이블을 만든다.
no 정수 NULL 허용하지 않음
sub_no 정수 NULL 허용하지 않음
name 가변형 문자열
기본키 no, sub_no 조합create table sample632(no int not null, sub_no int not null, name varchar(20), primary key(no, sub_no));
-
다음 sample631 테이블을 만든다.
a 정수 NULL 허용하지 않음
b 정수 NULL 허용하지 않음
c 가변형 문자열 -
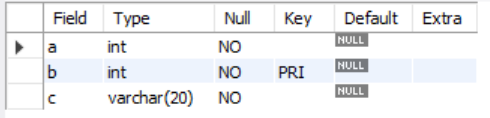
sample631 테이블 c열에 NOT NULL 제약 걸기(열제약 추가)
alter table sample631 modify c varchar(20) not null;
-
sample631 테이블 구조 보기
desc sample631;아래 표를 보면 not null제약이 추가된것을 볼 수 있다.
-
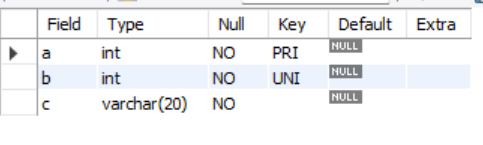
sample631 테이블에 a열을 기본키로 설정(테이블 제약 추가)
-
alter table sample631 modify a INT primary key; -
ALTER TABLE sample631 ADD CONSTRAINT PRIMARY KEY(a);
-
-
sample631 테이블의 c열에 NOT NULL 제약 없애기(열 제약 삭제)
alter table sample631 modify c varchar(30);
-
sample631 테이블 기본키 제약 삭제하기(테이블 제약 삭제)
alter table sample631 drop primary key;
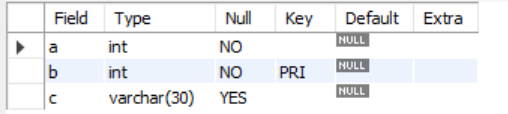
c열에 not null
-
다음 sample634 테이블을 만든다.
p 정수 NULL 허용하지 않음
a 가변문자열
p 기본키 설정- sample634 테이블에 다음 3개의 데이터를 추가하자.
1, '첫째줄'
2, '둘째줄'
3, '셋째줄'
- sample634 테이블에 다음 3개의 데이터를 추가하자.
-
sample634 테이블에 다음 데이터를 추가하자. 어떤 현상이 일어나는가?
그리고 그 이유는? 2, '넷째행'-
에러가 발생한다. 그 이유는 기본키로 지정한 p 의 값인 2가 중복되기 때문이다.
-
create table sample634(p int not null primary key, a varchar(5)); # p에 not null생략 가능 primary key선언했으니까 insert into sample634 values(1, '첫째줄'), (2, '둘째줄'), (3, '셋째줄'); insert into sample634 values(2, '넷째행);#에
-
-
sample634 테이블에 p가 3인 데이터를 2로 변경하자.어떤 현상이 일어나는가?
그리고 그 이유는?- 에러가 발생한다. 위와 같이 2로 변경하면 이미 기본키의 값인 2가 존재하는데 변경한다면 중복이 되기 때문이다.
- sample635테이블을 다음과 같이 만들자.
a 정수
b 정수
기본키 조합 a, b
- 다음 5개의 데이터를 sample635에 삽입하시오.
1, 1
1, 2
1, 3
2, 1
2, 2
- 다음 데이터를 sample635에 삽입하시오. 어떤 현상이 일어나는가?
그리고 그 이유는? 1, 3- 에러가 발생한다. 기본키가 a, b이므로, 이 a와 b가 하나씩 겹쳐도 상관 없지만 둘 모두가 중복되면중복으로 인식하기 때문이다.
정처기에 나온 DBMS문제
1, 3, 3, 4, 3, 1, 1, 4, 4, 3 - DML은 INSERT, UPDATE, DELETE, SELECT가 존재

인덱스 index
검색속도의 향상을 위해 쓴다. >> SELECT 명령에 WHERE 구로 조건을 지정하고 그에 일치하는 행을 찾는 일련의 과정을 빨리 찾기 위해
이진 트리, 해시가 유명
-
풀 테이블 스캔(full table scan) : 인덱스가 지정되지 않은 테이블을 검색할 때 사용
- 테이블에 저장된 모든 값을 처음부터 차례로 조사해나간다.
-
이진 탐색(binary search) : 데이터가 정렬되어 있어야한다. 고속으로 검색할 수 있는 탐색 방법이다.
-
그러나 테이블 내의 행을 항상 정렬된 상태로 두기는 힘들어서, 테이블에 인덱스를 작성하면 테이블 데이터와 별개로 인덱스용 데이터가 저장장치에 만들어 진다. >> 이진 트리라는 데이터 구조로 작성
-
이진 트리에는 중복하는 값을 등록할 수 없다.
-
인덱스 작성 / 삭제
CREATE INDEX
DROP INDEX-
인덱스 작성 : CREATE INDEX 명령으로 만든다. >> 인덱스에 이름을 붙여 관리해서, 객체가 될지 테이블의 열처럼 취급될지는 DB제품마다 다르다.
-
Oracle이나 DB2 등에서 인덱스는 스키마 객체가 된다. >> 스키마 내에서 이름이 중복되지 않도록 지정해서 관리한다.
-
SQL Server나 MySQL에서 인덱스는 테이블 내의 객체가 된다. >> 테이블 내에 이름이 중복되지 않도록지정해 관리한다.
-
- 인덱스를 작성할 때는 저장장치에 색인용 데이터가 만들어진다. 테이블 크기에 따라 인덱스 작성시간도 달라지는데, 행이 대량으로 존재하면 시간도 많이 걸리고 저장공간도 많이 소비한다. >> 그래도 효율은 그만큼 좋아진다.
인덱스를 작성할 때는 해당 인덱스가 어느 테이블의 어느 열에 관한 것인지 지정해야 한다. >> 열은 복수로 지정 가능
SYNTAX CREATE INDEX CREATE INDEX 인덱스명 ON 테이블명 (열명1, 열명2, ...) # 열을 꼭 명시해야함
CREATE TABLE sample62(no int, a varchar(10));
INSERT INTO sample62 VALUES(2, 'ABC');
INSERT INTO sample62 VALUES(1, 'DEF');
INSERT INTO sample62 VALUES(100, 'GHI');
INSERT INTO sample62 VALUES(3, 'JKL');
INSERT INTO sample62 VALUES(101, 'MNO');인덱스 작성 / 보기 / 삭제하기
# 인덱스 생성 - Create index
CREATE INDEX isample62 ON sample62(a); #이진트리 구조로 만들어짐 a컬럼을 기준으로 생
SELECT * FROM sample62 WHERE a = 'a'; # a열의 값이 a인 행을 검색
# 인덱스 보기 - Show index
SHOW INDEX FROM sample62;
# 인덱스 삭제하기 - Drop index - sample62의 인덱스인isample62만 삭제
DROP INDEX isample62 ON sample62;-
인덱스는 테이블에 의존하는 객체이므로, 테이블을 Drop시키면 인덱스도 같이 삭제된다.
-
INSERT 명령의 경우에는 인덱스를 최신 상태로 갱신하는 처리가 늘어나므로 처리속도가 조금 떨어진다.
인덱스 작성
-
WHERE 구에 a열에 대한 조건식을 지정한 경우 SELECT 명령은 인덱스를 사용해 빠르게 검색할 수 있다.
- WHERE 구의 조건식에 a열이 전혀 사용되지 않으면 SELECT 명령은 isample62 라는 인덱스를 사용할 수 없다. >> 컬럼 a를 기준으로 만들었기 때문에 where문에 a가 사용되지 않으면 하나씩 다 비교해서 실행하므로, 인덱스의 의미가 없다.
데이터의 종류가 적을수록 인덱스의 효율은 낮아지며, 반대로 서로 다른 값으로 여러 종류의 데이터가 존재하면 그만큼 효율이 높아진다.
EXPLAIN
표준 SQL에는 존재하지 않는, 데이터베이스 제품 의존형 명령이다.
- 인덱스 작성을 통해 쿼리의 성능 향상을 기대할 수 있는데, 인덱스를 사용해 검색하는지를 확인하려면 EXPLAIN 명령을 사용한다.
사용 문법
-
EXPLAIN에 뒤이어 확인하고 싶은 SELECT 명령 등의 SQL 명령을 지정하면 된다.
- 어떤 상태로 실행되는 지를 데이터베이스가 설명해줄 뿐이다.
인덱스 사용 확인하기1
EXPLAIN SELECT * FROM sample62 WHERE a = 'a';-
EXPLAIN의 뒤를 잇는 SELECT 명령은 a 열의 값을 참조해 검색하므로 isample62(인덱스)을 사용해 검색한다.
- possible_keys 라는 곳에 사용될 수 있는 인덱스가 표시되며, key는 사용된 인덱스가 표시된다.
인덱스 사용 확인하기 2 - where조건을 바꿔서
EXPLAIN SELECT * FROM sample62 WHERE no > 10;- possible_keys와 key가 NULL이 되었다. >> 순차검색으로 인덱스를 사용하지 않는다는 의미 >> 리뉴얼 서치 >> 순차검색 >> full table scan
최적화
-
SELECT 명령을 실행할 때 인덱스의 사용 여부를 선택한다는 것을 알았다. >> DB내부의 최적화에 의해 처리된다.
-
내부 처리에서는 SELECT 명령을 실행하기에 앞서 실행계획을 세운다.
- 실행계획에서는 '인덱스가 지정된 열이 WHERE 조건으로 지정되어 있으니 인덱스를 사용하자'와 같은 처리가 이루어진다. >> EXPLAIN 명령은 이 실행계획을 확인하는 명령이다.
뷰 view
뷰는 테이블과 같은 부류의 데이터베이스 객체 중 하나이다.
- 서브쿼리는 FROM 구에서도 기술할 수 있다. >> 인라인 뷰
CREATE VIEW 뷰명 AS SELECT 명령
DROP VIEW 뷰명뷰
뷰는 SELECT 명령을 기록하는 데이터베이스 객체다!
- 데이터베이스 객체란 테이블이나 인덱스 등 데이터 베이스 안에 정의하는 모든 것을 말한다.
- 반면 SELECT 명령은 객체가 아니다. SELECT 명령에 이름을 지정할 수도 없고 데이터베이스에 등록되지도 않기 때문이다.
- 데이터베이스 객체로 등록할 수 없는 SELECT 명령을, 객체로서 이름을 붙여 관리할 수 있도록 한 것이 뷰이다.
- SELECT 명령은 실행했을 때 테이블에 저장된 데이터를 결괏값으로 반환한다.
- 따라서 뷰를 참조하면 그에 정의된 SELECT 명령의 실행결과를 테이블처럼 사용할 수 있다.
서브쿼리를 뷰 객체로
CREATE VIEW sample_view_54 AS SELECT * FROM sample54; #sample_view_54는 뷰의 이름
SELECT * FROM sample_view_54;- 뷰를 정의할 때는 이름과 SELECT 명령을 지정한다. 뷰를 만든 후에는 SELECT 명령에서 뷰의 이름을 지정하면 참조할 수 있다.
- 자주 사용하거나 복잡한 SELECT 명령을 뷰로 만들어 편리하게 사용할 수 있다.
가상 테이블
뷰는 '실체가 존재하지 않는다'라는 의미로 '가상 테이블'이라 불리기도 한다.
- SELECT 명령으로 이루어지는 뷰는 테이블처럼 데이터를 쓰거나 지울 수 있는 저장공간을 가지지 않는다.
- 이 때문에 테이블처럼 취급할 수 있다고는 해도 'SELECT 명령에서만 사용'하는 것을 권장한다.
- INSERT나 UPDATE, DELETE 명령에서도 조건이 맞으면 가능하지만 사용에 주의할 필요가 있다.
뷰 작성과 삭제
-
뷰는 데이터베이스 객체이기 때문에 DDL로 작성하거나 삭제한다.
-
작성할 때는 CREATE VIEW를, 삭제할 때는 DROP VIEW를 사용한다.
- 뷰의 작성
CREATE VIEW 뷰명 AS SELECT 명령
CREATE VIEW sample_view_54 AS SELECT * FROM sample54; # 따로 컬럼명을 지정하지 않았기에 모든 열이 뷰에 들어감 컬럼명도 똑같이 들어감
SELECT * FROM sample_view_54;- 뷰의 열 지정을 생략한 경우에는 SELECT 명령의 SELECT 구에서 지정하는 열 정보가 수집되어 자동적으로 뷰의 열로 지정된다.
- 반대로 열을 지정한 경우에는 SELECT 명령의 SELECT 구에 지정한 열보다 우선된다.
열에 지정해 뷰 작성
CREATE VIEW sample_view_541(n, v, v2) AS SELECT no, a, a*2 FROM sample54;
# no의 컬럼명은 n / a 는 v / a*2는 v2
SELECT * FROM sample_view_541 WHERE n = 1;
CREATE VIEW sample_view_542 AS SELECT no, a FROM sample54; # 컬럼명을 지정하지 않아서 no, a가 컬럼명으로 같게 들어감
SELECT * FROM sample_view_542;뷰 삭제
DROP VIEW 뷰명
DROP VIEW sample_view_54;뷰 조회
SHOW FULL TABLES IN haksa_database WHERE TABLE_TYPE LIKE 'VIEW'; #해당 db에 있는 타입이 뷰인것을 검색 뷰의 약점
-
뷰는 데이터베이스 객체로서 저장장치에 저장되지만, 테이블과 달리 대량의 저장공간을 필요로 하지 않는다. >> 데이터베이스에 저장되는 것은 select 명령뿐이기에
-
저장공간을 소비하지 않는 대신 CPU 자원을 사용한다.
SELECT 명령은 데이터베이스의 테이블에서 행을 검색해 클라이언트로 반환하는 명령이다. 검색뿐만 아니라 ORDER BY로 정렬하거나 GROUP BY로 집계할 수 있다. 이러한 처리는 계산능력을 필요로 하기 때문에 컴퓨터의 CPU를 사용한다.
-
뷰의 근원이 되는 테이블에 보관하는 데이터양이 많은 경우, 집계처리를 할 때도 뷰가 사용된다면 처리속도가 많이 떨어질 수밖에 없다.
-
뷰를 중첩해서 사용하는 경우에도 처리 속도가 떨어지기 쉽다. >> 그래서 머티리얼라이즈드 뷰 사용
-
- 머티리얼라이즈드 뷰(Materialized View) - mysql에서는 사용 불가능
- 머티리얼라이즈드 뷰는 데이터를 일시적으로 저장해 사용하는 것이 아니라 테이블처럼 저장장치에 저장해두고 사용한다. >> 미리 저장했기 때문에 성능이 좋아지고 cpu자원도 덜 사용
- 머티리얼라이즈드 뷰는 처음 참조되었을 때 데이터를 저장해둔다. 이후 다시 참조할 때 이전에 저장해 두었던 데이터를 그대로 사용한다.
- 일반적인 뷰처럼 매번 select명령을 실행할 필요 없지만, 뷰에 지정된 테이블의 데이터가 변경된 경우에는 SELECT 명령을 재실행하여 데이터를 다시 저장한다.
MySQL에서는 머티리얼라이즈드 뷰를 사용할 수 없다. 지금으로서는 Oracle과 DB2에서만 사용할 수 있는 데이터베이스 객체이다.
함수 테이블
- 뷰를 구성하는 SELECT 명령은 단독으로도 실행할 수 있어야 한다.
- 테이블을 결괏값으로 반환해주는 사용자정의 함수이다.
- 함수에는 인수를 지정할 수 있기 때문에 인수의 값에 따라 WHERE 조건을 붙여 결괏값을 바꿀 수 있다. >> 그에 따라 상관 서브쿼리처럼 동작할 수 있다.
