
오전문제는 42일차 메모 문제 참조
My SQL
시스템 날짜
하드웨어 상의 시계로부터 실시간으로 얻을 수 있는 일시적인 데이터를 말한다. RDBMS에서도 시스템 날짜와 시간을 확인하는 함수를 제공
-
CURRENT_TIMESTAMP>> 함수를 실행했을 떄 기준으로 시간을 표시-
SELECT CURRENT_TIMESTAMP; -
인수를 필요로 하지 않는다. 일반적인 함수와는 달리 인수를 지정할 필요가 없으므로 괄호를 사용하지 않는 특수한 함수이다.
-
CURRENT_TIMESTAMP는 표준 SQL로 규정되어 있는 함수이다. Oracle에서는 SYSDATE 함수, SQL Server에서는 GETDATE 함수를 사용해도 시스템 날짜를 확인할 수 있다.
날짜를 문자열로 변환 - Date Fromat
-
SELECT now();: 현재 날짜와 시간 출력 -
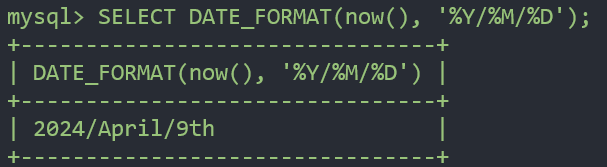
SELECT DATE_FORMAT(now(), '%Y/%M/%D')-
%Y : 4자리 년도
-
%M : 긴 월 이름(영문으로 월 이름)
-
%D : 월 내에서 서수 형식의 일(1th)
-
-
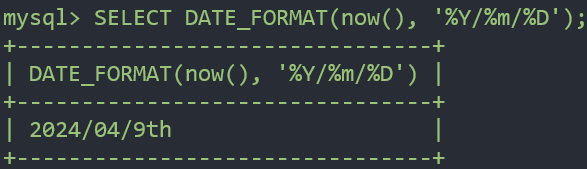
SELECT DATE_FORMAT(now(), '%Y/%m/%D');- 4자리 형태의 년도로 출력하고, %m : 숫자의 월 형태로 출력
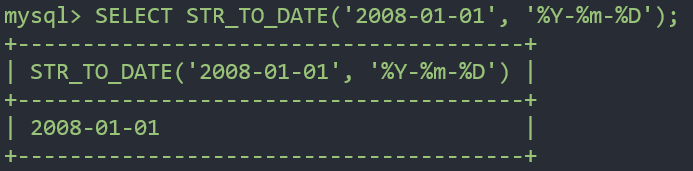
문자열을 날짜로 변환 - str_to_date
SELECT STR_TO_DATE('2008-01-01', '%Y-%m-%D');
날짜 시간형 데이터는 기간형 수치데이터와 덧셈 및 뺄셈을 할 수 있다. 날짜 시간형 데이터에 기간형 수치데이터를 더하거나 빼면 날짜시간형 데이터가 반환된다. 예를 들어 특정일로부터 1일 후를 계산하고 싶다면 a + 1 DAY 라는 식으로 계산할 수 있다. 1일 전이라면 a- 1 DAY로 하면 된다.
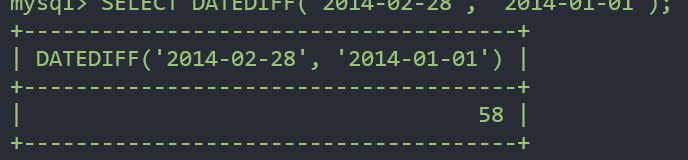
날짜형 간의 뺼셈- datediff
오라클에서는 - 로 뺼 수 있지만 mysql에서는 datediff이용
SELECT DATEDIFF('2014-02-28', '2014-01-01');
시스템 날짜의 1일 후를 계산
SELECT CURRENT_DATE + INTERVAL 1 DAY;: 날짜를 연산해 시스템 날짜의 1일 후를 검색
날짜 및 시간 처리
-
DATE
날짜 타입이다. '1000-01-01'에서 '9999-12-31' 까지 나타낼 수 있다.- 기본적으로 지원하는 형태는 'YYYY-MM-DD' 이다.
-
DATETIME
날짜와 시간이 합쳐진 타입이다. '1000-01-01 00:00:00'에서 '9999-12-31 23:59:59'까지 나타낼 수 있다.- 기본적으로 지원하는 형태는 'YYYY-MM-DD HH:MM:SS'이다.
-
TIMESTAMP[(M)]
날짜 및 시간 타입이다. '1970-01-01 00:00:00'에서 2037년까지 나타낸다. [(M)]자리에는 정밀도. 0~6을 쓸 수 있음. 숫자를 쓰지 않으면 기본적으로 0. TIMESTAMP의 특징은 자동 변경 칼럼 타입이라는 것이다. INSERT나 UPDATE문을 사용할 때 매우 유용하다.
SELECT TIMESTAMP('2020-09-15');
create table sample111(
a int auto_increment primary key,
b timestamp default current_timestamp on update current_timestamp,
#이 글을 쓴 시간이 기본값으로 / 업데이트하면 업데이트 했을때의 시간
c varchar(20)
);
insert into sample111(c) values('haha');
select * from sample111;
update sample111 set c='hoho'; # 이렇게 업데이트할때 해당 업데이트 했을 때의 시간으로 업데이트 되는것
select * from sample111; -
TIME
시간 타입이다. '-838:59:59'에서 '838:59:59'까지 나타낼 수 있다.- 기본적으로 지원하는 형태는 'HH:MM:SS'이다.
-
YEAR[(2/4)]
연도를 나타내는 타입이다. 2자리 혹은 4자리로 나타낼 수 있으며 자리수를 지정하지 않으면 기본적으로 4자리로 나타낸다. 4자리로 사용할 때는 1901년에서 2155년까지 지원하며 2자리로 사용할 때는 1970년에서 2069년까지 지원한다.
날짜 및 시간 관련 함수
1) NOW() / SYSDATE() : 현재 날짜와 시간을 반환한다.
select sysdate(), now();
2) curdate() / current_date() : 현재 날짜를 반환한다. >> Date형식의 반환값
select curdate(), current_date();
3) curtime() / current_time() : 현재 시간을 반환한다. >> Time형식의 반환값
select curtime(), current_time();
4) current_timestamp() : 현재 시스템 날짜와 시간을 모두 반환한다. >> timestamp형식의 반환값
5) dayofmonth(date) : 몇일 인지를 리턴 한다. >> 현재 날짜 반환
select now();
select dayofmonth(now());
6) dayofweek(date) / weekday(date) : 숫자로 요일을 반환
- 1-일요일, 2-월요일...7-토요일
- 0 = Monday, 1 = Tuesday,..... 6 = Sunday
select dayofmonth(now()), dayofweek(now());
표준을 따르는 dayofweek을 쓸 것
-
DAYNAME() : 요일의 이름을 반환 <> dayoweek
SELECT DAYNAME(now());
-
DAYOFYEAR(date) : 1년 중 며칠이 지났는가를 리턴 한다.
select dayofyear(now());
-
date_add() : 날짜에서기준값만큼 더한 값
date_sub() : 날짜에서 기준값을 뺀 값
interval 을 사용해 날짜에 일정한 간격을 더하고 뺌
(기준값 : YEAR, MONTH, DAY, HOUR, MINUTE, SECOND)
-
select date_add(now(), interval 3 day), date_sub(now(), interval 3 day);- 현재 날짜에서 3을 더하고, 현재 날짜에서 3을 뺀다.(3일 후 와 3일 전)
-
-
year() : 날짜의 연도
-
month() : 날짜의 월
select year(now()), month(now());
-
datediff() / months_between() : 두 날짜 사이의 월 간격을 계산 >> 오라클에서는 to_date함구 사용
-
date_format(날짜, '형식') : 날짜를 형식에 맞게 출력
문제
-
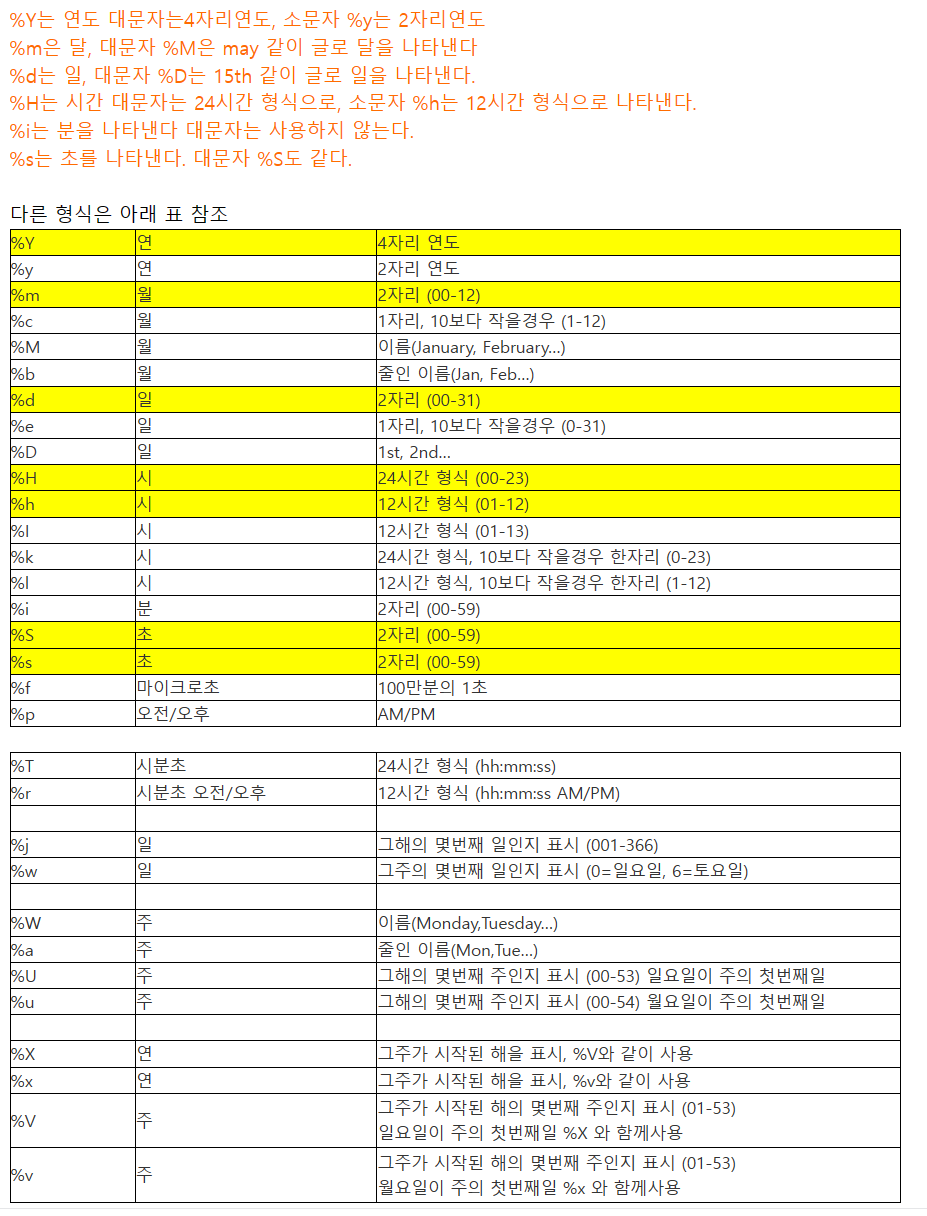
교수테이블에서 교수코드, 교수이름, 임용일자를 년도(4자리), 월(영문), 일(0이 포함된 날짜) 형식으로 출력하라.(haksa_database)
select prof_code, prof_name, date_format(create_date, '%Y %M %d') from professor;
4자리 년도, 영어로 월, 일수
문제
-
현재의 시스템 날짜 확인
SELECT CURRENT_TIMESTAMP;
-
오라클은 FROM구를 생략할 수 있다 없다?
- 없다.
-
지금 시각을 다음의 출력결과처럼 출력하자.
select date_format(now(), '%Y/%m/%D');
-
다음 두 날짜 사이의 간격을 일수로 출력할려면? '2014-02-28' - '2014-01-01'
select datediff('2014-02-28', '2014-01-01');
-
시스템 날짜의 1일 후를 계산하기
select current_date() + interval 1 day;>>괄호 있어도 되고 없어도 됨
-
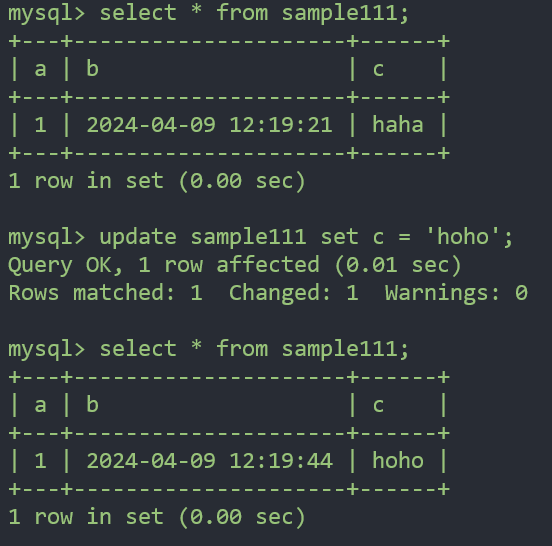
sample111이라는 테이블을 만드는데
a int 자동증가
b 시간 디폴트로 입력한 시간을 저장하고 변경시에 변경된 시간을 저장하게 한다.
c varchar(20)create table sample111(a int auto_increment primary key, b timestamp default current_timestamp on update current_timestamp, c varchar(20));
sample111에 'haha' 입력하고 데이터 확인
haha라고 저장된 값을 hoho로 바꾸고 데이터 확인
-
현재 날짜와 시간을 반환하여 출력.
-
select now(); -
select sysdate();
-
-
현재 날짜를 반환하여 출력.
-
select curdate(); -
select current_date;
-
-
현재 시간을 반환하여 출력
-
select curtime(); -
select current_time;
-
-
오늘이 몇일인지를 출력.
select dayofmonth(now());
-
오늘이 무슨 요일인지를 출력
select dayname(now());
-
일년 중 며칠이 지났는지 출력
select dayofyear(now());
-
오늘부터 3일 후와 오늘부터 3일 전을 출력
-
select date_add(now(), interval 3 day);>> 3일 후 -
select date_sub(now(), interval 3 day);>> 3일 전
-
-
현재 년도와 현재 달을 출력
select year(now()), month(now());
-
교수테이블(professor)에서 교수코드(prof_code), 교수이름(prof_name), 임용일자(create_date)를 년도(4자리), 월(영문), 일(0이 포함된 날짜) 형식으로 출력하라.(haksa_database)
select prof_code, prof_name, date_format(create_date, '%Y/%M/%d') from professor;
NULL 함수 - case, coalesce
switch case와 비슷한 형태
CASE 구조
CASE
WHEN 조건식1 THEN 식1
[WHEN 조건식2 THEN 식2 ...][ELSE 식3]
END
-
WHEN 절에는 참과 거짓을 반환하는 조건식을 기술한다.
-
해당 조건을 만족하여 참이 되는 경우는 WTHEN 절에 기술한 식이 처리된다.
-
이때 WHEN과 THEN을 한데 조합해 지정할 수 있다. WHEN 절의 조건식을 차례로 평가해 나가다가 가장 먼저 조건을 만족한 WHEN 절과 대응하는 THEN 절 식의 처리결과를 CASE 문의 결괏값으로 반환한다.
-
그 어떤 조건식도 만족하지 못한 경우에는 ELSE 절에 기술한 식이 채택된다. ELSE는 생략 가능하며 생략했을 경우 'ELSE NULL'로 간주된다.
-
CREATE TABLE sample37(a int);
INSERT INTO sample37 VALUES(1);
INSERT INTO sample37 VALUES(2);
INSERT INTO sample37 VALUES(NULL);
SELECT a, CASE WHEN a IS NULL THEN 0 ELSE a END "a(null=0)" FROM sample37;
# a가 null이면 0을 출력, 그렇지 않으면 a를 출력한다.>> 이 결과값의 별명을 a(null=0)으로 줌
SELECT a, COALESCE(a, 0) "a의값중 null을 찾는용도" FROM sample37;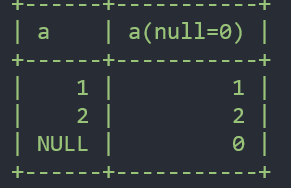
COALESCE
여러 개의 인수를 지정 가능
-
SELECT a, COALESCE(a, 0) "a의값중 null을 찾는용도" FROM sample37;-
주어진 인수 가운데 NULL이 아닌 값에 대해서는 가장 먼저 지정된 인수의 값을 반환한다.
-
a가 NULL이 아니면 a값을 그대로 출력하고, 그렇지 않으면(a가 NULL 이면) 0을 출력한다.
-
인코드, 디코드
- 문자화하는 것을 '디코드'라 부르고 반대로 수치화하는 것을 '인코드'라고 부른다. >> CASE문으로 처리 가능
단순 CASE식
'CASE 식 WHEN 식 THEN 식 ...' 구문 >> 단순 CASE에서는 CASE 뒤에 식을 기술하고 WHEN 뒤에 (조건식이 아닌) 식을 기술한다.
CASE 식1
WHEN 식2 THEN 식3
[WHEN 식4 THEN 식5 ...]
[ELSE 식6]
END-
식1의 값이 WHEN의 식2의 값과 동일한지 비교하고, 값이 같다면 식3의 값이 CASE 문 전체의 결괏값이 된다.
-
값이 같지 않으면 그 뒤에 서술한 WHEN 절과 비교하는 식으로 진행된다.
-
비교 결과 일치하는 WHEN 절이 하나도 없는 경우에는 ELSE 절이 적용된다.
식1의 값과 식4의 값이 같은지를 비교하고 같다면 식5의 값이 CASE 문의 결괏값이 된다.
-
성별 코드 변환하기
SELECT a AS "코드",
CASE a # 식을 CASE에 주고
WHEN 1 THEN '남자'
WHEN 2 THEN '여자'
ELSE '미지정'
END
AS "성별" FROM sample37;as 생략가능
검색 CASE식
'CASE WHEN 조건식 THEN 식 ...' 구문
성별 코드 변환하기
SELECT a AS "코드",
CASE # 식을 아래 WHEN에서 준다
WHEN a = 1 THEN '남자'
WHEN a = 2 THEN '여자'
ELSE '미지정'
END
AS "성별" FROM sample37;주의
-
ELSE를 생략하면 ELSE NULL이 되는 것에 주의
-
대응하는 WHEN이 하나도 없으면 ELSE 절이 사용된다. 이때 ELSE를 생략하면 상정한 것 이외의 데이터가 왔을 때 NULL이 반환된다.
따라서 ELSE를 생략하지 않고 지정하는 편이 낫다.
-
WHEN에 NULL지정하기
-
데이터가 NULL인 경우를 고려해 WHEN NULL THEN '데이터 없음'과 같이 지정해도 문법적으로는 문제가 없지만 단순 case문은 정상적으로 처리되지 않는다.
틀린 예제#단순 CASE 문에서 WHEN 절에 NULL 지정하기 SELECT a AS "코드", CASE a WHEN 1 THEN '남자' WHEN 2 THEN '여자' WHEN NULL THEN '데이터 없음' // = null이나, null로 비교 불가능 a is null로만 비교가 ELSE '미지정' END AS "성별" FROM sample37;
① a = 1
② a = 2
③ a = NULL
-
비교 연산자 = 로는 NULL 값과 같은지 아닌지를 비교할 수 없다 >> a 열의 값이 NULL이라 해도 a = NULL은 참이 되지 않는다.
-
NULL 값인지 아닌지를 판정하기 위해서는 IS NULL을 사용
- 다만 단순 CASE 문은 특성상 = 연산자로 비교하는 만큼, NULL 값인지를 판정하려면 검색 CASE 문을 사용해야 한다.
정답 - 검색 case문으로만 가능
SELECT a AS "코드",
CASE
WHEN a = 1 THEN '남자'
WHEN a = 2 THEN '여자'
WHEN a IS NULL THEN '데이터 없음'
ELSE '미지정'
END
AS "성별" FROM sample37;단순 CASE문으로는 NULL 값을 비교할 수 없다! (에러) >> 검색 case문 이용
= 을 사용해 a = null도 에러는 안나지만 결과가 제대로 출력 x >> is null이용
DECODE NVL
Oracle에는 이 같은 디코드를 수행하는 DECODE 함수가 내장되어 있다. DECODE 함수는 CASE 문과 같은 용도로 사용할 수 있다.
DECODE 함수는 Oracle에서만 지원하는 함수인 만큼 다른 데이터베이스 제품에서는 사용할 수 없다.
-
NULL 값을 변환하는 함수도 있는데 Oracle 에서는 NVL 함수, SQL Server에서는 ISNULL 함수가 이에 해당한다.
- 이 함수들은 특정 데이터베이스에 국한된 함수인 만큼 NULL 값을 변환할 때는 표준 SQL로 규정되어 있는 COALESCE 함수를 사용한다.
문제

서브쿼리 / 변수@
SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의를 의미한다.
-
SQL 명령문 안에 지정하는 하부 SELECT 명령으로 괄호로 묶어 지정한다.
- 문법에는 간단하게 'SELECT 명령'이라고 적었지만 SELECT 구, FROM 구, WHERE 구 등 SELECT 명령의 각 구를 기술할 수 있다.
-
서브쿼리는 SQL명령의 WHERE 구에서 주로 사용된다.
- WHERE구는 SELECT, DELETE, UPDATE 구에서 사용할 수 있는데 이들 중 어떤 명령에서든 서브쿼리를 사용할 수 있다.
delete의 where문에서 서브쿼리 사용하기
CREATE TABLE sample54(no int AUTO_INCREMENT PRIMARY KEY, a int);
INSERT INTO sample54 (a) values(100);
INSERT INTO sample54 (a) values(90);
INSERT INTO sample54 (a) values(20);
INSERT INTO sample54 (a) values(80);
SELECT * FROM sample54;
SELECT MIN(a) FROM sample54;
# 조건에 맞게 삭제
delete from sample54 where a = (select a from (select min(a) "a" from sample54) as x);-
최솟값을 가지는 행 삭제하기 - 괄호로 서브쿼리를 지정해 삭제
에러나는 코드
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);
정답
-
DELETE FROM sample54 WHERE a = (SELECT a FROM (SELECT MIN(a) AS a FROM SAMPLE54) AS x);>> x에 있는 a값을 가져옴(참조를 이용해 데이터 가져옴) >> 20을 가져와서 삭제 >> where a = 을 하는 이유는 삭제하고자 하는 행을 식별하기 위함- 에러를 발생하지 않고 실행하려면 다음과 같이 인라인 뷰로 임시 테이블을 만들도록 처리하면 된다. (두 번째 FROM절에 있는 서브쿼리 : 인라인 뷰)
에러나는 이유
"You can't specify target table 'sample54' for update in FROM clause" 라는 에러가 발생
- 데이터를 추가하거나 갱신할 경우 동일한 테이블을 서브쿼리에서 사용할 수 없도록 되어 있기 때문이다.
클라이언트 변수 - @ 변수의 사용
#@a가 변수가 되고 set이 변수에 대입하는 명령이 된다.
set @a = (SELECT MIN(a) FROM sample54);
@a 에 있는 값 확인
select @a; # >> 값 출력됨
DELETE FROM sample54 WHERE a = @a;
SELECT * FROM sample54;스칼라 값 <> 서브쿼리 패턴
select의 결과값으로 하나만 반환되는게 스칼라 값이라고 함
-
서브쿼리를 사용할 때는 그 SELECT 명령이 어떤 값을 반환하는지 주의할 필요가 있다.
여러 가지 패턴 중에서도 다음과 같은 네 가지가 일반적인 서브쿼리 패턴이다.
-
하나의 값을 반환하는 패턴
SELECT MIN(a) FROM sample54;>> 스칼라 값
다른 패턴과 다르게, 단일 값이라고 통용되지만 DB에서는 스칼라 값이라고 불린다.
-
복수의 행이 반환되지만 열은 하나인 패턴
SELECT no FROM sample54;>> 열은 하난데 행은 여러개
-
하나의 행이 반환되지만 열이 복수인 패턴
SELECT MIN(a), MAX(no) FROM sample54;>> 행은 하난데 열이 여러개
-
복수의 행, 복수의 열이 반환되는 패턴
SELECT no, a FROM sample54;
-
SELECT 명령이 하나의 값만 반환하는 것을 '스칼라 값을 반환한다'고 한다!
- 스칼라 값을 반환하도록 SELECT 명령을 작성하고자 한다면 SELECT 구에서 단일 열을 지정한다.
스칼라 서브 쿼리
스칼라 값을 반환하는 서브쿼리
-
= 연산자를 사용하여 비교할 경우에는 스칼라 값끼리 비교할 필요가 있다.
-
WHERE 구에 사용할 수 있으므로 집계함수를 사용해 집계한 결과를 조건식으로 사용할 수 있다.
-
'GROUP BY에서 지정한 열 이외의 열을 SELECT 구에 지정하면 에러가 된다'라는 것도 있다. 하나의 그룹에 다른 값이 여러 개 존재할 경우는 스칼라 값이라고 할 수 없다.
select문에서 서브쿼리 사용하기
서브쿼리는 SELECT 구, WHERE 구, UPDATE의 SET구 등 다양한 구 안에서 지정할 수 있다.
-
서브쿼리는 '하나의 항목'으로 취급한다. 단, 문법적으로는 문제없지만 실행하면 에러가 발생하는 경우가 자주 있다.
- 스칼라 값의 반환여부에 따라 생기는 현상으로, 서브쿼리를 사용할 때는 스칼라 서브쿼리로 되어있는지 확인해야 한다. >> SELECT구에서 서브쿼리를 지정할 때는 스칼라 서브쿼리 필요
SELECT
(SELECT COUNT(*) FROM sample51) AS sq1, # 소괄호가 스칼라 서브쿼리 라고함
(SELECT COUNT(*) FROM sample54) AS sq2;-
주의할 점
-
서브쿼리가 아닌 상부의 SELECT 명령에는 FROM 구가 없다. >> MYSQL에서는 생략 가능 BUT 오라클등의 전통적인 데이터베이스 제품에서는 FROM생략 불가능
-
Oracle에서는 다음과 같이 FROM DUAL로 지정하면 실행할 수 있다. DUAL은 시스템 쪽에서 데이터베이스에 기본으로 작성되는 테이블이다.
-
# SELECT 구에서 서브쿼리 사용하기(Oracle의 경우) SELECT (SELECT COUNT(*) FROM sample51) AS sq1, (SELECT COUNT(*) FROM sample54) AS sq2 FROM DUAL;
-
-
SET 구에서 서브쿼리 사용하기
UPDATE sample54 SET a=(SELECT MAX(a) FROM sample54); # MySQL ERROR
UPDATE sample54 SET a=(SELECT a FROM (SELECT MAX(a) AS a FROM SAMPLE54) AS x); #서브쿼리의 결과값을 a에 다 업데이트
SELECT * FROM sample54;FROM 구에서 서브쿼리 사용하기
지금까지는 FROM 구에서 테이블 지정만 해왔지만 이번에는 FROM 구에 테이블 이외의 것도 지정 가능하다.
SELECT * FROM (SELECT * FROM sample54) sq;>> 괄호안에 문이 스칼라 값SELECT * FROM(SELECT * FROM sample54) AS sq;>> 테이블에는 이름이 붙여져 있지만 서브쿼리에는 이렇다 할 이름이 붙여져 있지 않고, 서브쿼리 사용별명을 붙이는 것으로 비로소 서브쿼리의 이름을 지정된다. >> as사용 (오라클에서는 as붙이지 않는다. 붙이면 에러)
중첩구조
네스티드 구조, 내포구조
-
SELECT * FROM (SELECT * FROM (SELECT * FROM sample54) sq1) sq2;>> 중첩구조는 몇단계로든 구성 가능위에 예제처럼 테이블 한 개를 지정하는 데 3단계 중첩구조로 작성하지는 않는다. 의미가 없음 위는 설명하는 예제로 사용한 것
oracle에서 limit구의 대체 명령
Oracle에는 LIMIT 구가 없다. ROWNUM으로 행 개수를 제한할 수 있지만, 정렬 후 상위 몇 건을 추출하는 조건은 붙일 수 없다.
FROM 구에서 서브쿼리를 사용하는 것으로 Oracle에서도 정렬 후 상위 몇 건을 추출한다는 행 제한을 할 수 있다.
SELECT * FROM(
SELECT * FROM sample54 ORDER BY a DESC
) sq
WHERE ROWNUM <= 2;INSERT명령과 서브쿼리
방법 2가지
- INSERT 명령에는 VALUES 구의 일부로 서브쿼리를 사용하는 경우 >> 서브쿼리는 스칼라 서브쿼리로 지정할 필요 o, 자료형 일치해야함
CREATE TABLE sample541(a int, b int);
# VALUES 구에서 서브쿼리 사용하기
INSERT INTO sample541 VALUES(
(SELECT COUNT(*) FROM sample51),
(SELECT COUNT(*) FROM sample54)
);
SELECT * FROM sample541;- VALUES 구 대신 SELECT 명령을 사용하는 경우
SELECT결과를 INSERT하기
괄호를 붙이지 않아 서브쿼리라고 부르기 어려울 수도 있겠다.
INSERT INTO sample541 SELECT 1, 2; # 1, 2를 대입
SELECT * FROM sample541;-
SELECT가 결괏값으로 1과 2라는 상수를 반환하므로,
INSERT INTO sample541 VALUES(1, 2)의 경우와 같다.- SELECT 명령이 반환하는 값이 꼭 스칼라 값일 필요는 없다. SELECT가 반환하는 열 수와 자료형이 INSERT할 테이블과 일치하기만 하면 된다.
-
INSERT SELECT 명령은 SELECT 명령의 결과를 INSERT INTO로 지정한 테이블에 전부 추가한다. SELECT 명령의 실행 결과를 클라이언트로 반환하지 않고 지정된 테이블에 추가하는 것이다. >> 데이터의 복사, 이동을 할 때 자주 사용
테이블의 행 복사하기
- INSERT SELECT명령으로 행을 복사할 수 있다.
# 테이블 생성
CREATE TABLE sample542(a int, b int);
# 행 복사
INSERT INTO sample542 SELECT * FROM sample541;
SELECT * FROM sample542;-
서브쿼리의 위치에 따른 명칭
- SELECT문에 있는 서브쿼리 : 스칼라 서브쿼리 > 서브쿼리의 결과값이 한개
- FROM절에 있는 서브쿼리 : 인라인 뷰
- WHERE절에 있는 서브쿼리 : 서브쿼리
-
서브쿼리의 반환 값에 따른 서브쿼리 종류
- 단일 행 서브쿼리(Single-Row Subquery) : 서브쿼리의 결과가 1행
- 다중 행 서브쿼리(Multiple-Row Subquery) : 서브쿼리의 결과가 여러 행
- 다중 컬럼 서브쿼리(Multi-Column Subquery) : 서브쿼리의 결과가 여러 컬럼
-
스칼라 서브쿼리(Scala Subquery)
- SELECT문에서 사용하는 서브쿼리로 1행만 반환
-
상호연관 서브쿼리(Correlated Subquery)
- 메인쿼리의 값을 서브쿼리가 사용하고, 서브쿼리의 값을 받아서 메인쿼리가 계산하는 구조의 쿼리
상관 서브쿼리 - exists
그냥 서브쿼리는 단독으로 실행될 수 있지만, 상관 서브쿼리는 다른 컬럼의 데이터를 엮어서 이어주는 것이기 때문에, 주쿼리랑 부쿼리가 서로 연관되어 있어 단독 실행이 불가능하다.
-
EXISTS 술어를 사용하면 서브쿼리가 반환하는 결괏값이 있는 지를 조사할 수 있다. >> exists를 사용하는 경우에는 서브쿼리가 반드시 스칼라 값일 필요 x
-
단지 반환된 행이 있는지를 확인해보고 값이 있으면 참, 없으면 거짓을 반환하므로 어떤 패턴이라도 상관없다.
-
서브쿼리를 사용해 검색할 때 '데이터가 존재하는지 아닌지' 판별하기 위해 조건을 지정할 수도 있다. 이런 경우 EXISTS 술어를 사용해 조사할 수 있다.
CREATE TABLE sample551(no int, a char(10));
INSERT INTO sample551 VALUES(1, NULL);
INSERT INTO sample551 VALUES(2, NULL);
INSERT INTO sample551 VALUES(3, NULL);
INSERT INTO sample551 VALUES(4, NULL);
INSERT INTO sample551 VALUES(5, NULL);
CREATE TABLE sample552(no2 int);
INSERT INTO sample552 VALUES(3);
INSERT INTO sample552 VALUES(5);EXISTS를 사용해 '있음'으로 갱신하기
-
sample551에 no열이 sample552의 no2열과 같은 행이 있으면 a열을 '있음'으로 갱신하기.
-
UPDATE sample551 SET a = '있음' WHERE EXISTS(SELECT * FROM sample552 WHERE no2 = no);>> no2는 sample552, no는 sample551- 서브쿼리의 WHERE 구는 no2=no 라는 조건식으로 되어 있다. no2는 sampl552의 열이고 no는 sample551의 열이다. >> no가 3과 5일 때만 서브쿼리가 행을 반환한다.
-
- EXISTS 술어에 서브쿼리를 지정하면 서브쿼리가 행을 반환할 경우에 참을 돌려준다. 결과가 한 줄이라도 그 이상이라도 참이 된다. 반면 반환되는 행이 없을 경우에는 거짓이 된다.
보통은 컬럼 이름을 같게 주는데, no=no 로주는데, 해당 테이블의 이름을 앞에 붙이고 .no 로 붙여서 알기 쉽게 붙여준다. (sample551.no = sample552.no)
NOT EXISTS를 사용해 '없음'으로 갱신하기
-
sample551에 no열이 sample552의 no2열과 같은 행이 아니면 a열을 '없음'으로 갱신하기.
UPDATE sample551 SET a = '없음' WHERE NOT EXISTS(SELECT * FROM sample552 WHERE no2 = no);
- '없음'의 경우, 행이 존재하지 않는 상태가 참이 되므로 이때는 NOT EXISTS를 사용한다. NOT을 붙이는 것으로 값을 부정할 수 있다.
DELETE != 상관 서브쿼리
DELETE는 상관 서브쿼리가 아닌 단순한 서브쿼리로 단독 쿼리로 실행할 수 있다.
단독 쿼리
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54); # MySQL Error
###
DELETE FROM sample54 WHERE a = (SELECT a FROM (SELECT MIN(a) AS a FROM SAMPLE54) AS x);
###
SELECT MIN(a) FROM sample54;상관 서브쿼리 - 해당 서브쿼리가 단독으로 사용될 수 없음
UPDATE sample551 SET a = '있음' WHERE
EXISTS(SELECT * FROM sample552 WHERE no2 = no );
SELECT * FROM sample552 WHERE no2 = no;
#-> 에러 no가 불명확하다열에 테이블명 붙이기
UPDATE sample551 SET a = '있음' WHERE
EXISTS (SELECT * FROM sample552 WHERE sample552.no2 = sample551.no);-
양쪽 테이블 모두 no라는 열로 되어있다면 잘 동작하지 않는다.(대부분은 열이 애매하다는 내용의 에러가 발생한다.
- MySQL에서는 서브쿼리의 'WHERE no = no'는 'WHERE sample552.no = sample552.no'가 되어 조건식은 항상 참이 된다.
서브쿼리 연산자 IN / NOT IN
IN(집합)
집합 안의 값이 존재하는 지를 조사할 수 있다.
-
스칼라 값끼리 비교할 때는 = 연산자를 사용한다. BUT 스칼라 값끼리 비교할 때는 = 연산자를 사용한다.
-
IN에서는 오른쪽에 집합을 지정해서, 왼쪽에 지정된 값과 같은 값이 집합 안에 존재하면 참을 반환한다.
- 집합은 상수 리스트를 괄호로 묶어 기술한다.
-
IN을 사용해 조건식 기술
SELECT * FROM sample551 WHERE no IN (3, 5);>> no가 3이거나 5인 애의 데이터를 출력
집합 부분을 서브쿼리로 지정 가능
-
서브쿼리로 지정하지 않고 아래 처럼 사용 가능, 메인 쿼리에서 직접 sample552테이블의 열을 참조
SELECT * FROM sample551 WHERE no IN (SELECT no2 FROM sample552);>> IN에는 집합을 지정할 수 있기에
NOT IN
- 집합에 값이 포함되어 있지 않을 경우 참이 된다.
IN과 NULL
-
집계함수에서는 집합 안의 NULL 값을 무시하고 처리했RH, IN에서는 집합안에 NULL 값이 있어도 무시하지 않고, 처리한다.
-
그러나, NULL = NULL을 제대로 계산할 수 없으므로 IN을 사용해도 NULL 값은 비교할 수 없다.
-
즉, NULL을 비교할 때는 IS NULL을 사용해야 한다. 또한 NOT IN의 경우, 집합 안에 NULL 값이 있으면 설령 왼쪽 값이 집합 안에 포함되어 있지 않아도 참을 반환하지 않는다. >> 불명( unknown)
-
집합에 null이 포함되는 경우
-
IN : 왼쪽 값이 집합에 포함되어 있으면 참을, 그렇지 않으면 NULL을 반환한다.
-
NOT IN : 왼쪽 값이 집합에 포함되어 있으면 거짓을, 그렇지 않으면 NULL을 반환한다.
-
NOT IN의 경우 집합에 NULL이 포함되어 있다면 그 결괏값은 0건이 된다. NULL을 반환한다는 것은 비교할 수 없다는 것을 의미한다. >> NULL을 넣지 않는게 좋다.(제대로된 결과 도출 불가 , IN은 가능)
왼쪽의 값이 NULL인 경우에도 오른쪽의 값과 관계없이 비교할 수 없으므로, 조건식은 참 또는 거짓이 아닌 NULL을 반환한다.
-
SELECT * FROM SAMPLE551 WHERE NO IN(3, 5, NULL); #참이라 반환하는데, 그렇지 않으면 NULL반환
SELECT * FROM SAMPLE551 WHERE NO NOT IN(3, 5, NULL); #NULL이 들어있으면 제대로된 결과값 도출 불가
SELECT * FROM SAMPLE551 WHERE NO NOT IN(3, 5); # 1, 2, 4반환 <> SELECT 절에서 조회한 칼럼 값으로 비교하므로 EXISTS에 비해 IN은 성능이 떨어진다.
데이터베이스 객체
테이블이나 뷰, 인덱스 등 데이터베이스 내에 정의하는 모든 것을 일컫는 말이다.
SELECT나 INSERT 등은 클라이언트에서 객체를 조작하는 SQL 명령이로, DB내에 존재하는 것이 아니므로 객체라 부를 수 없다.
명명규칙
- 기존 이름이나 예약어와 중복하지 않는다.
- 숫자로 시작할 수 없다.
- 언더스코어(_) 이외의 기호는 사용할 수 없다.
- 한글을 사용할 때는 더블쿼트로 둘러싼다.
- 시스템이 허용하는 길이를 초과하지 않는다.
스키마
SQL명령의 DDL을 이용해 정의한다.
-
객체의 이름이 같아도 스키마가 서로 다르다면 상관없다.
-
데이터베이스에 테이블을 작성해서 구축해나가는 작업을 '스키마 설계'라고 부른다.
툴 단축키
초기 설정으로 preference들어가서 sql editor의 맨 아래 safe update~ 를 체크 해제해야 update, delete문을 사용할 수 있다.
-
ctrl + enter : 커서가 있는 줄만 하나 실행
-
ctrl + shift + enter : 전체 실행
-
ctrl + w : 해당 탭 치우기
-
ctrl + l : 해당 라인 삭제
