Stack 클래스
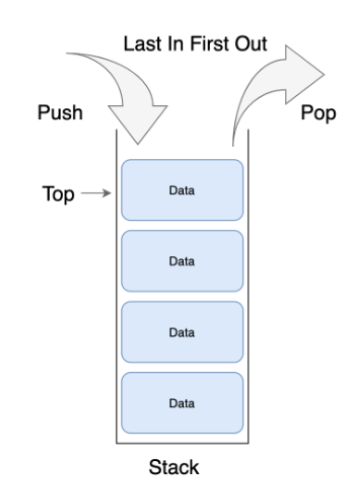
Last In First Out
java.util.Stack
Stack 의 특징
제일 마지막에 들어간 값부터 0번째 인덱스가 되는것이다. > 제일 처음 들어가 마지막에 있는 값은 마지막 인덱스가 된다.
-
마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out) 구조
-
수식 계산이나 워드 프로세서의 undo/redo, 또는 웨브라우저의 뒤로/앞으로, 문자열의 역순 출력, 후위(postfix) 표기법 연산 같은 기능들을 구현
-
완전히 꽉 찼을 떄
Overflow상태라고 하고, 완전히 비어 있으면Underflow상태 라고한다. -
삽입(Push)과 제서(Pop)는 모두
Top이라는 스택의 한쪽 끝에서만 일어난다. -
스택의 인덱스는 제일 위에(top) 있는 요소의 인덱스가 0이며, 아래로 내려갈수록 1, 2, 3..과 같이 증가하게 된다.
Stack 사용법
아래 선언은 배열을 기반으로 구현한건데, 학습목적으로 배열이나 LinkedList로 구현하게끔 연습하는것
보통은 Stack의 형식으로 사용하고싶으면 java.util.Stack import해오면 된다.
Stack 선언
import java.util.Stack; //import
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
Stack<String> stack = new Stack<>(); //String형 스택 선언Stack 메서드
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.pop(); // stack에 가장 상단의 저장된 객체를 꺼내며 그 값을 반환 >> 동시에 값 제거
stack.peek(); // stack에 가장 상단의 객체를 반환 > pop()과 달리 꺼내지 않음 (스택에 존재)
stack.size(); // stack의 크기 출력 : 2
stack.getSize(); // stack에 있는 요소 수를 반환
stack.empty(); // stack이 비어있는지 check (비어있다면 true)
stack.isEmpty(); // stack이 비어있는지 확인
stack.isFull(); // stack이 가득 차 있는지 확인
stack.contains(1); // stack에 1이 있는지 check (있다면 true)
stack.search(1); // stack에서 인자값으로 주어진 객체(1)를 찾아서 그 위치를 반환, 못 찾으면 -1 을 반환-
기능이 같은 메서드는 둘 다 사용해도 되지만, 아래에 있는 메소드가 최신버전이다.
getSize(),isEmpty()
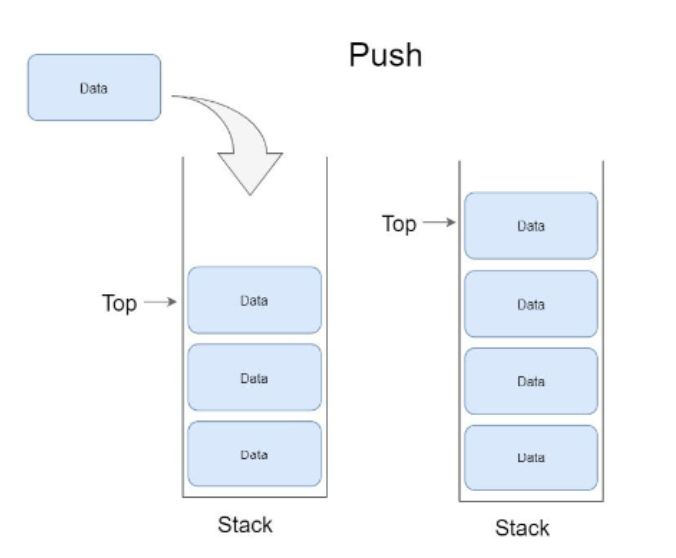
Push작업
데이터를 스택에 넣는 작업
과정
-
스택이 가득 찼는지 확인한다. > 차있으면 오류가 발생하고 종료
-
스택이 가득 차지 않으면 Top을 증가시킨다.
-
Top이 가리키는 스택 위치에 데이터를 추가한다.
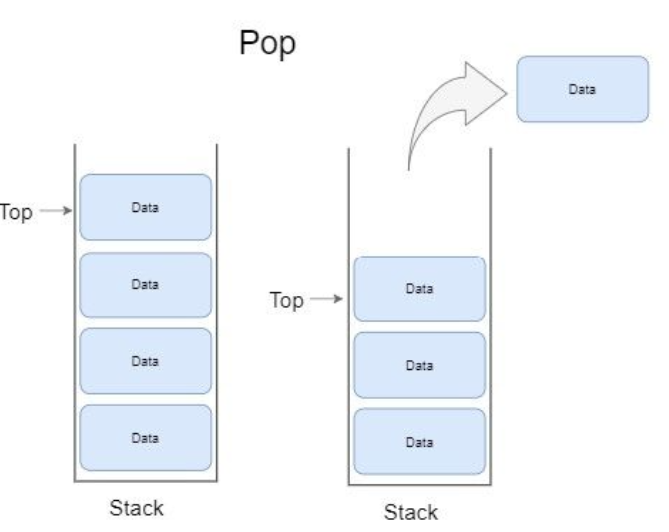
Pop 작업
데이터를 스택에서 제거하는 작업
과정
-
스택이 비어있는지 확인한다. > 비어있으면 오류가 발생하고 종료
-
스택이 비어있지 않으면 Top이 가리키는 데이터 제거
-
Top 값을 감소
-
반환
Stack구현
-
배열 사용
-
장점 : 구현하기 쉬움
-
단점 : 크기가 동적이지 않아서, 런타임시 필요에 따라 늘어나거나 줄어들지 않음
-
-
연결 리스트 사용
-
장점: 크기가 동적이고, 런타임시 필요에 따라 크기가 확장 및 축소될 수 있음
-
단점 : 포인터를 위한 추가 메모리 공간이 필요
-
배열로 Stack구현
package com.test.memo;
class UserStack {
int top;
int[] stack;
int size;
UserStack(int size) {
this.size = size;
stack = new int[size];
top = -1; // top의 값 초기화
}
void push(int item) {
stack[++top] = item;
System.out.println(stack[top] + "push");
}
void peek() {
System.out.println(stack[top] + "peek");
}
void pop() {
System.out.println(stack[top] + "pop");
top--;
}
int search(int item) {
for (int i = 0; i <= top; i++) {
if (stack[i] == item) {
return (top - i); // top = 탐색한 배열의 인덱스 배열이므로 +1
}
}
return -1;
}
boolean empty() {
return size == 0;
}
}
public class Practice1 {
public static void main(String[] args) {
UserStack stack = new UserStack(5); // 스택의 크기를 5로 설정
stack.push(1); // 스택에 요소 추가
stack.push(2);
stack.push(3);
System.out.println();
stack.peek(); // 스택의 맨 위 요소 확인 -3
System.out.println();
stack.pop(); // 스택에서 요소 제거 -3
System.out.println();
stack.peek(); // 제거 후 스택의 맨 위 요소 확인 -2
System.out.println();
stack.pop(); // 스택의 맨 위 요소 제거 -2
System.out.println();
int searchResult = stack.search(1); // 스택에서 요소 찾기
if (searchResult != -1) {
System.out.println("값 1번 요소가 " + searchResult + "번째에 있습니다.");
} else {
System.out.println("요소를 찾을 수 없습니다.");
}
boolean isEmpty = stack.empty(); // 스택이 비어있는지 확인
System.out.println("스택이 비어있습니까? " + isEmpty);
}
}- 스택 자료구조를 배열로 구현해, push, pop등의 메서드는 스택의 동작을 정의하고 구현하기 위한 메서드인것이다.

LinkedList로 Stack구현
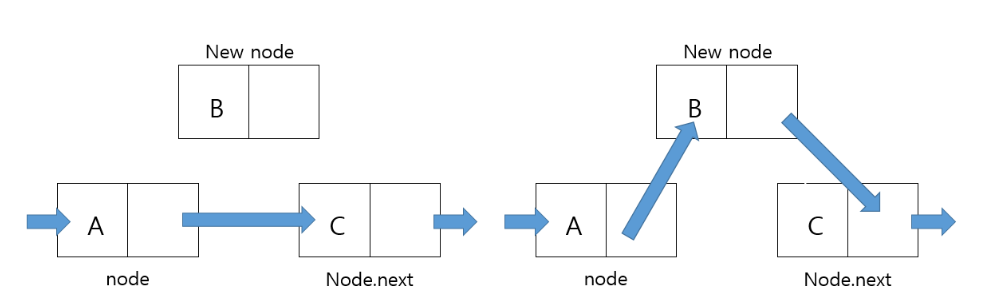
LinkedList로 스택을 구현하기 위해서는 Node를 먼저 만들어, 데이터와 다음 노드를 가르키는 주소로 구성되게끔 해야한다.
package com.test.memo;
class Node {
private int data;
private Node nextNode;
Node(int data) {
this.data = data;
this.nextNode = null;
}
void linkNode(Node node) {
this.nextNode = node;
}
int getData() {
return this.data;
}
Node getNextNode() {
return this.nextNode;
}
}
class UserLinkedListStack {
Node top;
UserLinkedListStack() {
this.top = null;
}
void push(int data) {
Node node = new Node(data);
node.linkNode(top);
top = node;
}
int peek() {
return top.getData();
}
void pop() {
if (empty())
throw new ArrayIndexOutOfBoundsException();
else {
top = top.getNextNode();
}
}
int search(int item) {
Node searchNode = top;
int index = 1;
while (true) {
if (searchNode.getData() == item) {
return index;
} else {
searchNode = searchNode.getNextNode();
index++;
if (searchNode == null)
break;
}
}
return -1;
}
boolean empty() {
return top == null;
}
}
public class Practice1 {
public static void main(String[] args) {
UserLinkedListStack stack = new UserLinkedListStack();
stack.push(1); // 스택에 요소 추가
stack.push(2);
stack.push(3);
System.out.println("Peek: " + stack.peek()); // 스택의 맨 위 요소 확인
stack.pop(); // 스택에서 요소 제거
System.out.println("Peek: " + stack.peek()); // 제거 후 스택의 맨 위 요소 확인
int searchResult = stack.search(2); // 스택에서 요소 찾기
if (searchResult != -1) {
System.out.println("값 2번 요소가 " + searchResult + "번째에 있습니다.");
} else {
System.out.println("요소를 찾을 수 없습니다.");
}
boolean isEmpty = stack.empty(); // 스택이 비어있는지 확인
System.out.println("스택이 비어있습니까? " + isEmpty);
}
}
-
제일 처름 push를 할 때 새 노드를 만들고, 이전에 있던 노드(top)과 연결을 한다.
- 그 후 새로운 노드가 가장 앞에 있어야 하니 새로운 노드를 Top으로 명시한다.
pop의 'ArrayIndexOutOfBoundsException()'은 노드가 아무 것도 없을 때의 에러를 막아주는 아이라고 생각하자
- pop은 top이 push를 했을 떄 새 노드로 재선언 했지만 pop은 지우는 것이므로, top과 연결된 노드 >> top아래의 있는 노드로 top을 재선언하는 것이다.
배열, LinkedList구현의 장단점
-
배열
-
장점 : 구현이 쉽고, 데이터의 접근 속도(조회)가 빠르다
-
단점 : 항상 최대 개수를 정해놔야 사용이 가능하다.(구현과 접근은 좋지만, 다른 프로젝트에서 활용할때는 불편한 점 존재)
-
-
LinkedList
-
장점: 데이터의 최대 개수가 한정되어 있지 않고, 삽입, 삭제가 용이
-
단점 : 데이터의 조회가 힘들다. >> 노드를 따라가서 조회해야 데이터를 찾을 수 있기 때문이다.
-
Stack의 특성상 마지막 데이터를 쉽게 빼낼 수 있어 마지막 기록, 최근 기록등등을 저장할 경우만 사용한다.
조회에 강점을 가지는 자료구조들이 많기 떄문에 stack을 굳이 사용할 필요가 없다.
만약 Stack클래스를 사용한다면, Linked스택으로 구현하는것이 좋다.
Queue 인터페이스
First In FirstOut
줄을 지어 순서대로 처리되는 자료구조이다.
Queue는 사이즈가 고정되어 있고, 데이터의 삽입과 삭제시 나머지 요소들은 이동하지 않아, 별도로 앞으로 재배치하는 작업이 필요하다.
- 자바에서는 Stack을 클래스로 구현하여 제공하고 있지만, Queue는 인터페이스만 존재하고, 별도의 클래스가 없다. 그래서 Queue인터페이스를 구현한 클래스들을 사용해야 한다.
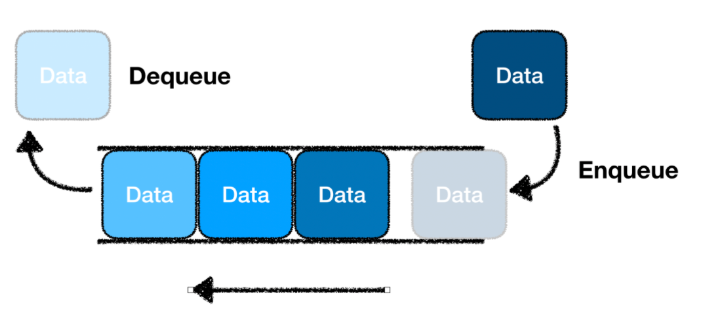
큐 용어
-
Enqueue: 데이터 삽입 >> Front에서 요소를 추가
-
Dequeue (JS의 shift): 데이터 삭제 >> Front에서 요소를 제거
-
Front(맨 앞): Dequeue시 삭제되는 데이터 (가장 먼저 저장된 데이터)를 가르킵니다.
-
Rear(끝): 추가될 새로운 요소의 위치를 가르킵니다.
가득 찬 큐에 요소를 추가하려 할 때
OverFlow가 발생,빈 큐에 요소를 제거하려 할 때
UnderFlow가 발생
Queue의 특징
제일 처음들어가 있는 값이 0번째 인덱스, 마지막에 들어가 있는 인덱스가 마지막 인덱스가 되는것이다.
-
먼저 들어간 자료가 먼저 나오는 구조 FIFO(First In FIrst Out) 구조
-
큐는 한 쪽 끝은 프런트(front)로 정하여 삭제 연산만 수행함
-
다른 한 쪽 끝은 리어(rear)로 정하여 삽입 연산만 수행함
4. 그래프의 넓이 우선 탐색(BFS), 프린터의 대기열등 에서 사용
5. 컴퓨터 버퍼에서 주로 사용, 마구 입력이 되었으나 처리를 하지 못할 때, 버퍼(큐)를 만들어 대기 시킴
Queue 사용법
Queue 선언
java에서 큐는 LinkedList를 활용해 생성해야 하기 때문에 Queue와 LinkedLIst가 다 import되어있어야 사용이 가능하다.
import java.util.LinkedList; //import
import java.util.Queue; //import
Queue<Integer> queue = new LinkedList<>(); //int형 queue 선언, linkedlist 이용
Queue<String> queue = new LinkedList<>(); //String형 queue 선언, linkedlist 이용Queue 메서드
import java.util.LinkedList;
import javaj.util.Queue;
Queue<Integer> que = new LinkedList<>();
que.add(1); //지정된 객체를 que에 추가 > 성공하면 true 반환, 저장공간이 부족하면 IllegalStateException발생
que.offer(2); //que에 객체를 저장 > 성공하면 true, 실패하면 false를 반환
que.enqueue(3); //큐에 끝(rear)에 객체 추가
que.dequeue(); //큐에 맨 앞(front)에 항목을 제거
que.poll(); //큐에 맨 앞(front)을 제거하고 반환 > 만약 비어있다면 null
que.remove(); // 큐에 맨 앞(front) 값 제거하고 반환 > 비어있다면 NouSuchElementException발
que.clear(); //큐 초기화 > 모든 요소 제거
que.peek(); //큐에 맨 앞(front)에 있는 항목 반환 > 비어있다면 null
que.isfull(); //큐가 가득 찼는지 확인
que.isempty(); // 큐가 비어있는지 확인- Queue의 요소를 삭제하면, 삭제된 자리가 비어있게 되고, 뒤에 있는 요소들은 이동하지 않는다.
- 주로pop은 스택, poll은 큐에서 사용한다.
Queue 구현
-
배열 사용
-
장점: 구현하기 쉽다.
-
단점: 크기가 동적이지 않다.
-
-
연결 리스트 사용
-
장점: 크기가 동적이다. 필요에 따라 크기가 확장 및 축소될 수 있다.
-
단점: 포인터를 위한 추가 메모리 공간이 필요하다.
-
Queue 종류
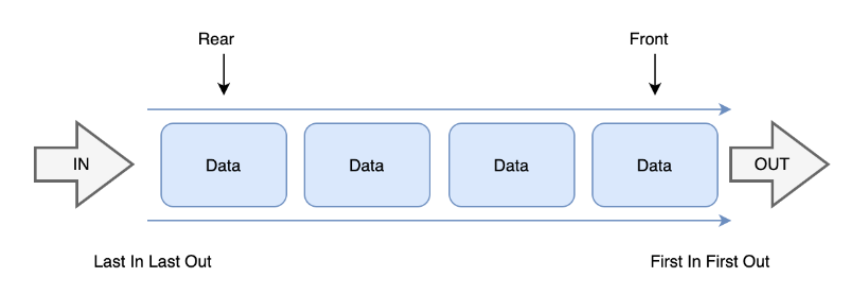
선형 큐(Linear Queue)
위의 내용들은 선형 큐
-
기본적인 큐의 형태로 막대 모양으로 된 큐다.
-
배열로 구현 > 크기 제한, 빈공간을 사용하면, 자료를 한 칸 씩 옮겨야한다.
우선순위 큐(Priority Queue)
우선순위를 먼저 결정하고, 우선순위가 높은 엘리먼트가 먼저 나간다.
-
이진트리 구조로 이루어져 있다.
-
높은 우선순위의 요소를 먼저 꺼내 처리하는 구조(큐에 들어가는 원소는 비교가 가능한 기준이 있어야한다.)
-
응급실과 같이 우선순위를 중요시해야 하는 상황에서 쓰인다.
-
진행 방식
- 데이터를 삽입할 떄 우선순위를 기준으로 최대힙, 최소힙을 구성하고, 데이터를 꺼낼 때 루트 노드를 얻어낸 뒤 루트 노드를 삭제할 때는 빈 루트노드 위치에 맨 마지막 노드를 삽입한 후 아래로 내려가면서 적절한 자리를 찾아서 옮기는 방식
우선순위 큐 선언 방식
기본적으로 우선순위가 낮은 숫자 순으로 부여
import java.util.PriorityQueue; //import
//int형 priorityQueue 선언 (우선순위가 낮은 숫자 순)
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
//int형 priorityQueue 선언 (우선순위가 높은 숫자 순)
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());
//String형 priorityQueue 선언 (우선순위가 낮은 숫자 순)
PriorityQueue<String> priorityQueue = new PriorityQueue<>();
//String형 priorityQueue 선언 (우선순위가 높은 숫자 순)
PriorityQueue<String> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());
add / offer하게되면 위의 추가과정처럼 삽입
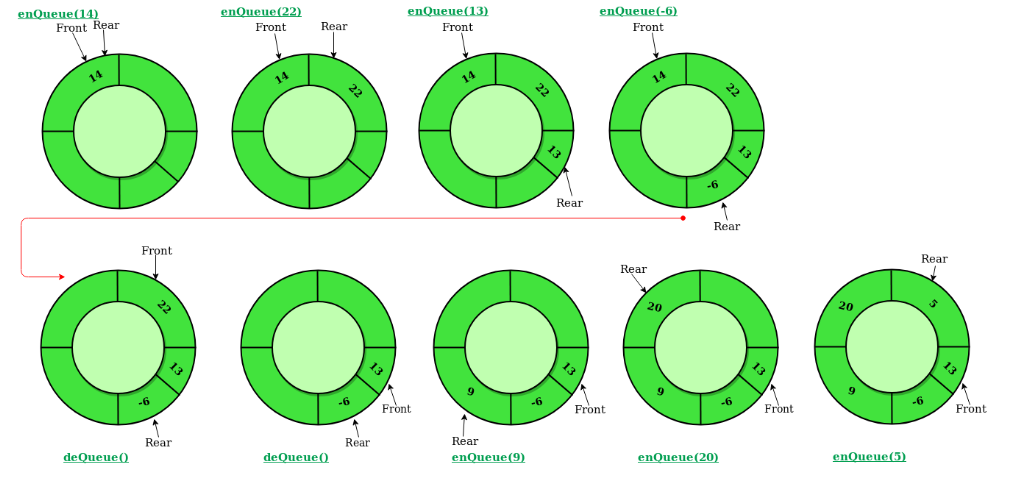
원형 큐(= 환형 큐, Circular Queue, RIng Buffer)
선형 큐의 문제점을 보완해 만든 것으로, 1차원 배열 형태의 큐를 원형(Circular)으로 구성하여 배열의 처음과 끝을 연결해 만든다.
- 원형 큐의 경우 Front와 Rear가 아래 그림처럼 순환하기 때문에 빈 공간을 사용하기 위한 별도의 작업이 필요하지 않는다. >> 작업자가 따로 순환 코드를 짜줘야한다.
-
어떠한 작업/데이터를 순서대로 실행/사용하기 위해 대기시킬 때 사용한다.
- CPU스케줄링, 디스크 스케줄링
-
서로 다른 쓰레드 또는 프로세스 사이에서 자료를 주고 받을 때 자료를 일시적으로 저장한는 용도로 많이 사용한다.
- IO버퍼, 파이프, 파일 IO
원형 큐 순환 코드
void enqueue() {
// ...
rear = (rear + 1) % queue_size;
}
void dequeue() {
// ...
front = (front + 1) % queue_size;
}-
예를 들어, 큐의 전체사이즈가 5고 현재 Rear가 마지막 인덱스 4를 가리키고 있다면,
- 여기서 Enqueue를 하게되면 Rear의 인덱스는 5가 될텐데 여기에 큐의 전체사이즈를 나눈 나머지를 구합니다.
5 % 5 = 0이므로 이 값을 Rear에 할당하여 인덱스가 다시 0을 가르킬 수 있도록 합니다.
- 여기서 Enqueue를 하게되면 Rear의 인덱스는 5가 될텐데 여기에 큐의 전체사이즈를 나눈 나머지를 구합니다.
이렇게 하면 정렬 과정없이 Front와 Rear가 순환하는 형태를 만들 수 있다.
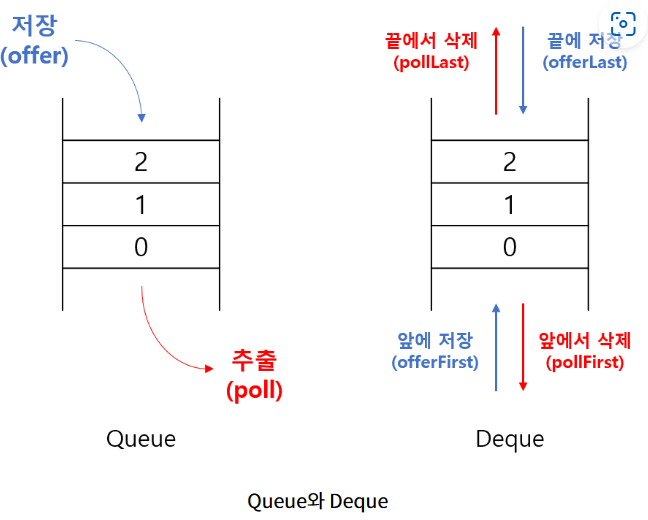
Deque (Double-Ended Queue)
데크는 큐와 스택을 하나로 합쳐놓은 것돠 같아서 스택으로도 사용할 수 있고, 큐로도 사용할 수 있다.
큐의 양쪽에 데이터를 넣고 뺼 수 있는 형태의 자료구조 >> 큐 + 스택
-
Scroll (스크롤) : 입력 제한 덱
- 입력이 한쪽에서만 발생하고, 출력은 양쪽에서 일어날 수 있다.
-
Shelf(셸프) : 출력 제한 덱
- 입력은 양쪽에서 일어나고, 출력은 한쪽에서 일어나도록 제한
Deque의 상속도
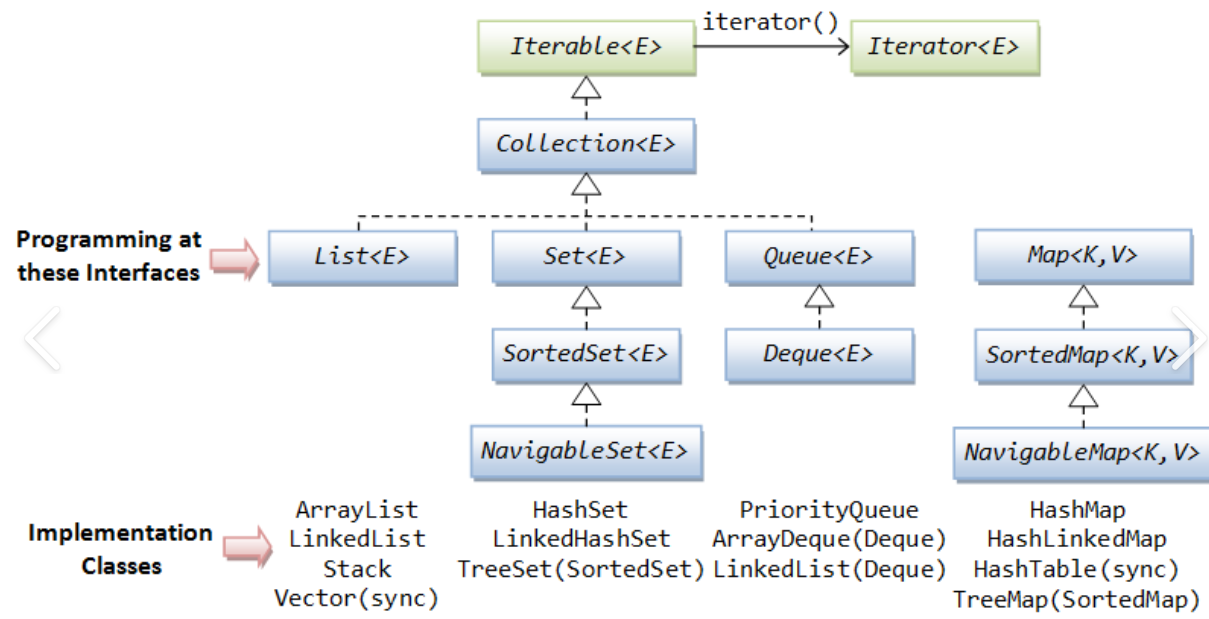
Deque 사용법
Deque 생성
자바에서 Deque은 인터페이스로 구현되어있다.
Deque자료구조의 여러 연산들은 Deque인터페이스에 정의되어있고, 아래 클래스들은 이를 구현한 클래스다.
Deque<String> deque1 = new ArrayDeque<>();
Deque<String> deque2 = new LinkedBlockingDeque<>();
Deque<String> deque3 = new ConcurrentLinkedDeque<>();
Deque<String> linkedList = new LinkedList<>();Deque 메서드
Deque<String> deque = new ArrayDeque<>();
deque.addFirst(); // Deque의 맨앞에 데이터를 삽입, 용량 초과시 Exception
deque.addLast(); // Deque의 뒤쪽에 데이터를 삽입, 용량 초과시 Exception
deque.offerFirst(); // Deque의 맨앞에 데이터를 삽입 후 true, 용량 초과시 false
deque.offerLast(); //Deque의 뒤쪽에 데이터를 삽입 후 true, 용량 초과시 false
deque.removeFirst(); //Deque의 맨 앞에 있는 요소를 제거하고 반환
deque.removeLast(); //Deque의 맨 뒤에 있는 요소를 제거하고 반환
deque.pollFirst(); //Deque의 맨 앞에 있는 요소를 제거하고 반환 > 비어있으면 null
deque.pollLast(); //Deque의 맨 뒤에 있는 요소를 제거하고 반환 > 비어있으면 null
deque.getFirst(); //Deque의 첫번째 요소 반환 > 비어있으면 예외
deque.getLast(); //Deque의 마지막 요소 반환 > 비어있으면 예외
deque.peekFirst(); //첫번째 요소 반환 > 비어있으면 null
deque.peek();// peekFirst()와 동일
deque.add(); //요소를 Deque의 끝에 추가하고 성공 여부 반환 > 용량 초과시 Exception == addLast()
deque.offer(); //요소를 Deque의 끝에 추가하고 성공여부를 반환 == offerLast()
deque.push(); // addFirst()와 동일 > ArrayDeque일 경우 이 메서드 사용이 더 좋다.
deque.pop(); // removeFirst()와 동일 > ArrayDeque일 경우 이 메서드 사용이 더 좋다.
//deque를 스택으로 사용할때 위 두 메소드가 쓰임
deque.contain(Object o); // Object 인자와 동일한 엘리먼트가 포함되어 있는지 확인
deque.size(); // Deque에 들어있는 엘리먼트의 개수
//*특이한 메소드
// Deque의 앞쪽에서 인자를 찾아서 첫 번째 데이터를 삭제 > 없으면 아무일도 x
deque.removeFirstOccurrence(Object o);
// Deque의 뒤쪽에서 인자를 찾아서 첫 번째 데이터를 삭제
deque.removeLastOccurrence(Object o);
// removeFirstOccurrence() 메소드와 동일
deque.remove(Object o);addLast(), add(), offerLast(), offer()메소드는 뒤쪽에 데이터를 넣는다.
add로 시작하는 메소드는 용량 초과시 예외 발생, offer로 시작하는 메소드는 용량 초과시 false리턴
remove로 시작하는 메소드는 비어있으면 에외 발생, poll로 시작하는 메소드는 비어있으면 null을 리턴
get으로 시작하는 메소드는 비어있을 때 예외 발생, peek으로 시작하는 메소드는 비어있을 떄 null리턴
이 메소드들은 확인만하고 제거하지 않는다.
- 데크가 비어있을 때 예외를 처리하고자 한다면
remove() - 비어있는 데크에서 안전하게 요소를 제거하고자 한다면
poll()
Deque 순회
for문과 iterator를 이용해 저장되어있는 값들을 순회할 수 있따.
// for 문을 이용한 순회
for (String elem : deque1) {
System.out.println(elem);
}
// Iterator를 이용한 순회
Iterator<String> iterator = deque1.iterator();
while (iterator.hasNext()) {
String elem = iterator.next();
System.out.println(elem);
}
// 역순순회
Iterator<String> reverseIterator = deque1.descendingIterator();
while (reverseIterator.hasNext()) {
String elem = reverseIterator.next();
System.out.println(elem);
}Collection Framework 예제
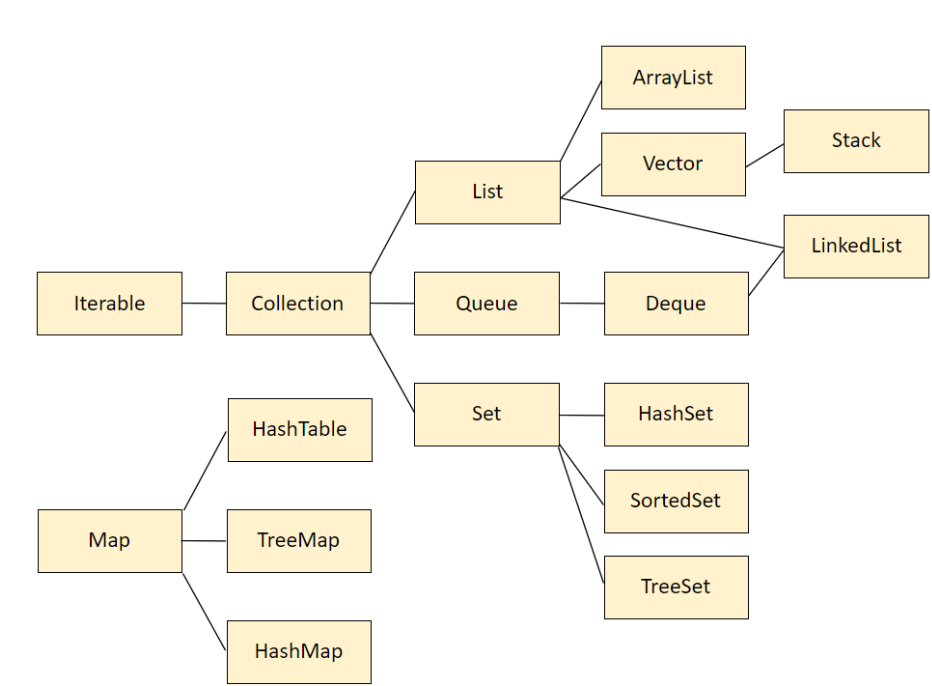
Collection은 Iterable을 상속받고 있다. 그래서 Iterator 인터페이스를 사용할 수 있는것이다.
예제 1 ArrayList
import java.util.List;
import java.util.ArrayList;
class ArrayListCollection {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 인스턴스 저장
list.add("Toy");
list.add("Box");
list.add("Robot");
// 인스턴스 참조
for(int i = 0; i < list.size(); i++)
System.out.print(list.get(i) + '\t');
System.out.println();
// 첫 번째 인스턴스 삭제
list.remove(0);
// 삭제 후 인스턴스 참조
for(int i = 0; i < list.size(); i++)
System.out.print(list.get(i) + '\t');
System.out.println();
}
}
/*
Toy Box Robot
Box Robot
*/ -
ArrayList의 단점
-
저장 공간을 늘리는 과정에서 시간이 비교적 많이 소요된다.
-
인스턴스의 삭제 과정에서 많은 연산이 필요할 수 있다. 따라서 느릴 수 있다.
-
-
ArrayList의 장점
- 저장된 인스턴스의 참조가 빠르다.
예제 2 LinkedList
import java.util.List;
import java.util.LinkedList;
class LinkedListCollection {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
// ArrayListCollection.java와 비교해서 유일한 변화
// 인스턴스 저장
list.add("Toy");
list.add("Box");
list.add("Robot");
// 인스턴스 참조
for(int i = 0; i < list.size(); i++)
System.out.print(list.get(i) + '\t');
System.out.println();
// 첫 번째 인스턴스 삭제
list.remove(0);
// 삭제 후 인스턴스 참조
for(int i = 0; i < list.size(); i++)
System.out.print(list.get(i) + '\t');
System.out.println();
}
}
/*
Toy Box Robot
Box Robot
*/-
LinkedList의 단점
- 저장된 인스턴스의 참조 과정이 배열에 비해 복잡하다. 따라서 느릴 수 있다.
-
LinkedList의 장점
-
저장 공간을 늘리는 과정이 간단하다.
-
저장된 인스턴스의 삭제 과정이 단순하다.
-
예제 3 enhanced for문 (for each문)
import java.util.List;
import java.util.LinkedList;
class EnhancedForCollection {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
// 인스턴스 저장
list.add("Toy");
list.add("Box");
list.add("Robot");
// 인스턴스 참조
for(String s : list)
System.out.print(s + '\t');
System.out.println();
// 첫 번째 인스턴스 삭제
list.remove(0);
// 삭제 후 인스턴스 참조
for(String s : list)
System.out.print(s + '\t');
System
.out.println();
}
}
/*
Toy Box Robot
Box Robot 삭제 후 출력 값
*/-
for - each문을 통한 순차적 접근의 대상이 되려면, 해당 컬렉션 클래스는 다음 인터페이스를 구현해야 한다.
-
public interface Iterable<T>>> Iterable을 구현한 클래스만 for-each문을 사용할 수 있다. -
Collection\가 Iterable\를 상속하는데, ArrayList\,
LinkedList\ 클래스는 Collection\ 인터페이스를 구현하고 있다.public interface Collection<E> extends Iterable<E>
-
public static void main(String[] args) {
List<String> list = new LinkedList<>();
...
Iterator<String> itr = list.iterator(); // 반복자 획득, itr이 지팡이를 참조한다.
// 반복자를 이용한 참조 과정 중 인스턴스의 삭제
while(itr.hasNext()) {
str = itr.next();
if(str.equals("Box")
itr.remove(); // 위에서 next 메소드가 반환한 인스턴스 삭제
}
}-
이러한 반복자는 생성과 동시에 첫 번째 인스턴스를 가리키고, next가 호출될 때마다 가리키는 대상이 다음 인스턴스로 옮겨진다. 그렇다면 이 반복자를 원하는 때에 다시 첫 번째 인스턴스를 가리키게 하려면 어떻게 해야 할까?
가리키던 위치를 되돌리는 방법은 없으니 다음과 같이 반복자를 다시 얻어야 한다.
Iterator<String> itr = list.iterator();
예제 4 Iterator
import java.util.List;
import java.util.LinkedList;
import java.util.Iterator;
class IteratorCollection {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
// 인스턴스 저장
list.add("Toy"); list.add("Box");
list.add("Robot"); list.add("Box");
// 반복자 획득
Iterator<String> itr = list.iterator();
// 반복자를 이용한 순차적 참조
while(itr.hasNext())
System.out.print(itr.next() + '\t');
System.out.println();
// 반복자 다시 획득
itr = list.iterator();
// "Box"의 삭제
String str;
while(itr.hasNext()) {
str = itr.next();
if(str.equals("Box"))
itr.remove();
}
// 반복자 다시 획득
itr = list.iterator();
// 삭제 후 결과 확인
while(itr.hasNext())
System.out.print(itr.next() + '\t');
System.out.println();
}
}
// 실행결과
/*
Toy Box Robot Box
Toy Robot
*/ -
for-each문도,
for(String s : list)
System.out.print(s + '\t');
-
컴파일 과정에서 다음과 같이 반복자를 이용하는 코드로 수정된다.
즉 for-each문 역시 반복자에 의한 순차적 접근으로 진행이 된다.
-
`for(Iterator itr = list.iterator();itr.hasNext(); )
System.out.print(itr.next() + '\t');` 의 형태로 for - each문 진행 가능
-
예제 5 Arrays.asList
Arrays.asList로 만든 List는 추가와 삭제가 불가능하다. >> 수정은 가능하다.
생성과 초기화를 동시에 하는 형태.
어차피 ArrayList로 보낼거니까 그냥 처음부터 ArryaList로 만들어도 된다.
import java.util.List;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Arrays;
class AsListCollection {
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy", "Box", "Robot", "Box");
list = new ArrayList<>(list);
//list의 내용을 가지고 ArrayList를 다시 생성
//Arrays.asList는 추가와 삭제가 불가능했는데 위처럼 ArrayList를 다시 생성해 추가와 삭제가 되는 형태로 만든것이다.
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
for(Iterator<String> itr = list.iterator(); itr.hasNext(); ) {
if(itr.next().equals("Box")) //메소드 체이
itr.remove();
}
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
}
}
// 실행결과
/*
Toy Box Robot Box
Toy Robot
*/배열보다는 컬렉션 인스턴스가 좋다. : 컬렉션 변환
-
배열과 ArrayList는 특성이 유사하다. (ArrayList가 배열을 기반으로 인스턴스를 저장하므로) 그런데 대부분의 경우 배열보다 ArryList가 더 좋다.
- 인스턴스의 저장과 삭제가 편하다.
- '반복자'를 쓸 수 있다. 단 배열처럼 '선언과 동시에 초기화'를 할
수 없어서 초기에 무엇인가를 채워 넣는 일이 조금 번거롭다. 하지만 다음과 같이 컬렉션 인스턴스를 생성할 수 있어서 이것도 문제가 되지 않는다.
-
public ArrayList(Collection<? extends E> c)-
Collection를 구현한 컬렉션 인스턴스를 인자로 전달받는다.
-
그리고 E는 인스턴스 생성 과정에서 결정되므로 무엇이든 될 수 있다.
-
덧붙여서 매개변수 c로 전달된 컬렉션 인스턴스에서는 참조만(꺼내기만) 가능하다.
-
-
public static void main(String[] args) { // List<E>는 collection<E>를 상속한다. List<String> list = Arrays.asList("Toy", "Box", "Robot", "Box"); // 생성자 public ArrayList(Collection<? extends E> c)를 통한 인스턴스 생성 list = new ArrayList<>(list); ... } -
위와 같이 ArrayList 인스턴스를 생성하면, 생성자로 전달된 컬렉션 인스턴스에 저장된 모든 데이터가, 새로 생성되는 ArrayList 인스턴스에 복사된다. 따라서 위와 같은 코드의 구성은 배열을 대신하는 컬렉션 인스턴스의 생성에 주로 사용된다.
예제6 인스턴스 변환
import java.util.List;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Iterator;
import java.util.Arrays;
class ConversionCollection {
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy", "Box", "Robot", "Box");
list = new ArrayList<>(list);
// ArrayList<E> 인스턴스의 순환
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
// ArrayList<E>를 LinkedList<E>로 변
list = new LinkedList<>(list);
// LinkedList<E> 인스턴스의 순환
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
}
}
// 실행결과
/*
Toy Box Robot Box
Toy Box Robot Box
*/대다수 컬렉션 클래스들은 다른 컬렉션 인스턴스를 인자로 전달받는 생성자를 가지고 있어서,다른 컬렉션 인스턴스에 저장된 데이터를 복사해서 새로운 컬렉션 인스턴스를 생성할 수 있다.
-
public ArrayList(Collection<? extends E> c)- 인자로 전달된 컬렉션 인스턴스로부터 ArrayList 인스턴스 생성
-
public LinkedList(Collection<? extends E> c)- 인자로 전달된 인스턴스로부터 LinkedList 인스턴스 생성
-
public HashSet(Collection<? extends E> c)- 인자로 전달된 인스턴스로부터 HashSet 인스턴스 생성
따라서 ArrayList 인스턴스를 사용하다가 연결 리스트 자료구조의 특성이 필요하면
이를 기반으로 LinkedList 인스턴스를 생성하면 된다.
예제 7 listIterator()
양방향 반복자
import java.util.List;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
import java.util.Arrays;
class ListIteratorCollection {
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy", "Box", "Robot", "Box");
list = new ArrayList<>(list);
ListIterator<String> litr = list.listIterator();
String str;
// 왼쪽에서 오른쪽으로
while(litr.hasNext()) {
str = litr.next();
System.out.print(str + '\t');
if(str.equals("Toy"))
litr.add("Toy2");
}
System.out.println();
//Toy Box Robot Box
// 오른쪽에서 왼쪽으로
while(litr.hasPrevious()) { //이전 요소가 있는지 확인
str = litr.previous(); //이전 요소를 가지고
System.out.print(str + '\t');
if(str.equals("Robot"))
litr.add("Robot2");
}
System.out.println();
// Box Robot Robot2 Box Toy2 Toy
// 다시 왼쪽에서 오른쪽으로
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
// Toy Toy2 Box Robot2 Robot Box
}
}
// 실행결과
/*
Toy Box Robot Box
Box Robot Robot2 Box Toy2 Toy
Toy Toy2 Box Robot2 Robot Box
*/Collection를 구현하는 클래스의 인스턴스는 iterator 메소드의 호출을 통해서 '반복자'를 얻을 수 있다.
-
public ListIterator listIterator() -> ListIterator는 Iterator을 상속한다.
-
양쪽 방향으로 이동이 가능하다는 특징이 있는데, 이는 배열이나 연결 리스트와 같은 자료구조의 특성상 가능한 일이다. 그리고 위 메소드가 반환하는 반복자를 대상으로 호출할 수 있는 대표 메소드들은 다음과 같다.
-
E next(): 다음 인스턴스의 참조 값을 반환 -
boolean hasNext(): next 메소드 호출 시 참조 값 반환 가능 여부 확인 -
void remove(): next 메소드 호출을 통해 반환했던 인스턴스를 삭제 -
E previous(): next 메소드와 기능은 같고 방향만 반대 -
boolean hasPrevious(): hasNext 메소드와 기능은 같고 방향만 반대 -
void add(E e): 인스턴스의 추가 -
void set(E e): 인스턴스의 변경
"next 호출 후에 add 호출하면, 앞서 반환된 인스턴스 뒤에 새 인스턴스 삽입된다."
"previous 호출 후에 add 호출하면, 앞서 반환된 인스턴스 앞에 새 인스턴스가 삽입된다."
-
-
예제 8 HashSet
중복을 허용하지 않고, 순서가 없다.
import java.util.Iterator;
import java.util.HashSet;
import java.util.Set;
class SetCollectionFeature {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Toy");
set.add("Box");
set.add("Robot");
set.add("Box");
System.out.println("인스턴스 수: " + set.size());
for(Iterator<String> itr = set.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
for(String s : set)
System.out.print(s + '\t');
System.out.println();
}
}
/*
인스턴스 수: 3
Box Robot Toy
Box Robot Toy
*/-
Set를 구현하는 클래스의 특성과 HashSet 클래스
-
Set 인터페이스를 구현하는 제네릭 클래스의 특성
-
저장 순서가 유지되지 않는다.
-
데이터의 중복 저장을 허용하지 않는다.
그리고 이는 Set 이라는 이름처럼 수학에서 말하는 '집합'의 특성이다.
-
예제9 HashSet 중복 처리
import java.util.HashSet;
class Num {
private int num;
public Num(int n) {
num = n;
}
@Override
public String toString() {
return String.valueOf(num);
}
}
class HashSetEqualityOne {
public static void main(String[] args) {
HashSet<Num> set = new HashSet<>();
set.add(new Num(7799));
set.add(new Num(9955));
set.add(new Num(7799));
System.out.println("인스턴스 수: " + set.size());
for(Num n : set)
System.out.print(n.toString() + '\t');
System.out.println();
}
}
// 실행결과
/*
인스턴스 수: 3
7799 7799 9955
*/-
위 코드를 출력하면 중복으로 인식되지 못하고 저장된것을 알 수 있다.
-
해당 중복을 확인하기 위해서는
- Object클래스의 메소드인 equals메소드와 hashCode()메소드를 오버라이딩해서 중복으로 인식할 수 있도록 해줘야 한다.
예제 9-1 제대로된 코드
import java.util.HashSet;
class Num {
private int num;
public Num(int n) {
num = n;
}
@Override
public String toString() {
return String.valueOf(num);
}
@Override
public int hashCode() {
return num % 3;
}
@Override
public boolean equals(Object obj) {
if(num == ((Num)obj).num)
return true;
else
return false;
}
}
class HashSetEqualityTwo {
public static void main(String[] args) {
HashSet<Num> set = new HashSet<>();
set.add(new Num(7799));
set.add(new Num(9955));
set.add(new Num(7799));
System.out.println("인스턴스 수: " + set.size());
for(Num n : set)
System.out.print(n.toString() + '\t');
System.out.println();
}
}
// 실행결과
/*
인스턴스 수: 2
9955 7799
*/-
hashCode()가 먼저 호출되서 해시 기반의 자료구조에서 객체의 저장 위치를 결정하고 , 주소값을 반환한다.
-
같은 해시코드를 가진 객체가 존재하면, equals()가 그 뒤에 호출되서 실제로 두 객체가 동등한지 여부를 확인한다.
예제 10 String hashCode()/equals()
import java.util.HashSet;
class Car {
private String model;
private String color;
public Car(String m, String c) {
model = m;
color = c;
}
@Override
public String toString() {
return model + " : " + color;
}
@Override
public int hashCode() {//왠만하면 아래와 같이 작성하
return (model.hashCode() + color.hashCode()) / 2;
}
/*
@Override
public int hashCode() {
return java.util.Objects.hash(model, color);
}
*/
@Override
public boolean equals(Object obj) {
String m = ((Car)obj).model;
String c = ((Car)obj).color;
if(model.equals(m) && color.equals(c))
return true;
else
return false;
}
}
class HowHashCode{
public static void main(String[] args) {
HashSet<Car> set = new HashSet<>();
set.add(new Car("HY_MD_301", "RED"));
set.add(new Car("HY_MD_301", "BLACK"));
set.add(new Car("HY_MD_302", "RED"));
set.add(new Car("HY_MD_302", "WHITE"));
set.add(new Car("HY_MD_301", "BLACK"));
System.out.println("인스턴스 수: " + set.size());//4개
for(Car car : set)
System.out.println(car.toString() + '\t');
}
}
// 실행결과
/*
인스턴스 수: 4
HY_MD_301 : RED
HY_MD_302 : RED
HY_MD_301 : BLACK
HY_MD_302 : WHITE
*/-
클래스를 정의할 때마다 hashCode() 메소드를 정의하기 번거롭기 때문에 아래와 같은 메소드를 사용한다.
-
public static int hash(Object ... values)-
java.util.Objects에 정의된 메소드, 전달된 인자 기반의 해쉬 값 반환
-
위 메소드의 매개변수 선언에는 '가변 인자 선언'이 포함되어있다. > 메소드 호출 시마다 달리할 수 있는 선언이다.
@Override public int hashCode() { return Objects.hash(model, color); // 전달인자 model, color 기반 해쉬 값 반환 } -
-
이렇듯 hash 메소드는 하나 이상의 인자를 조합하여 하나의 해쉬 값을 만들어 반환한다. 따라서
특별한 경우가 아니라면 직접 해쉬 알고리즘을 만들지 않고 이 메소드에 의존해도 된다.
예제 11 TreeSet
TreeSet 클래스는 '트리(Tree)'라는 자료구조를 기반으로 인스턴스를 저장한다.
정렬된 상태를 유지되면서, 인스턴스가 저장 >> 트리라는 자료구조의 특성이 그러함
import java.util.TreeSet;
import java.util.Iterator;
class SortedTreeSet {
public static void main(String[] args) {
TreeSet<Integer> tree = new TreeSet<Integer>();
tree.add(3); tree.add(1);
tree.add(2); tree.add(4);
System.out.println("인스턴스 수: " + tree.size());
// for-each문에 의한 반복
for(Integer n : tree)
System.out.print(n.toString() + '\t');
System.out.println();
// Iterator 반복자에 의한 반복
for(Iterator<Integer> itr = tree.iterator(); itr.hasNext(); )
System.out.print(itr.next().toString() + '\t');
System.out.println();
}
}
/*
실행 결과
인스턴스 수: 4
1 2 3 4
1 2 3 4
*/- TreeSet 의 반복자는 "인스턴스들의 참조 순서는 오름차순을 기준으로 한다."
예제12 Comparable TreeSet
import java.util.TreeSet;
import java.util.Iterator;
class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + " : " + age;
}
// 나이가 같으면 저장 하지 않는다.
@Override
public int compareTo(Person p) {
return this.age - p.age; // 오름차순 정렬
}
// @Override
// public int compareTo(Person p) {
// return p.age - this.age; // 내림차순 정렬
// }
}
class ComparablePerson {
public static void main(String[] args) {
TreeSet<Person> tree = new TreeSet<>();
tree.add(new Person("YOON", 37));
tree.add(new Person("HONG", 53));
tree.add(new Person("PARK", 22));
for(Person p : tree)
System.out.println(p);
}
}
/*
실행 결과
PARK : 22
YOON : 37
HONG : 53
*/- Comparable 인터페이스를 구현할 때 compareTo()메소드를 구현해야한다.
예제 13 Comparator TreeSet
import java.util.Comparator;
import java.util.TreeSet;
class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() { return name + " : " + age; }
@Override
public int compareTo(Person p) {
return this.age - p.age;
}
}
class PersonComparator implements Comparator<Person> {
public int compare(Person p1, Person p2) {
return p2.age - p1.age;
}
}
class ComparatorPerson {
public static void main(String[] args) {
TreeSet<Person> tree = new TreeSet<>(new PersonComparator());//정렬기준을 해당 클래스를 통해 정해지는것이다.
tree.add(new Person("YOON", 37));
tree.add(new Person("HONG", 53));
tree.add(new Person("PARK", 22));
for(Person p : tree)
System.out.println(p);
}
}
/*
실행 결과
HONG : 53
YOON : 37
PARK : 22
*/TreeSet tree = new TreeSet<>(new PersonComparator());이 부분에 익명클래스나, 람다식을 넣을 수 있는것
예제 13-1 String
import java.util.TreeSet;
import java.util.Iterator;
import java.util.Comparator;
class StringComparator implements Comparator<String> {
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
}
class ComparatorString {
public static void main(String[] args) {
TreeSet<String> tree = new TreeSet<>(new StringComparator());
tree.add("Box");
tree.add("Rabbit");
tree.add("Robot");
for(String s : tree)
System.out.print(s.toString() + '\t');
System.out.println();
}
}
/*
실행 결과
Box Robot Rabbit
자바에서 제공하는 기본 클래스를 대상으로 정렬 기준을 바꿔야 하는 상황에서는
Comparator<T>의 구현이 좋은 해결책이 된다.
*/- String은 기본적으로 문자의 사전적 정렬 기준이 정의되어 있기 때문에, 문자열 길이순으로 정렬 기준을 세우고 싶다면 위와 같이 Comparator을 구현해 기준을 세울 수 있다.
예제 14 asList/Inhanced/HashSet 이용해 중복저장된것을 없애는 방법
import java.util.List;
import java.util.Arrays;
import java.util.ArrayList;
import java.util.HashSet;
class ConvertCollection {
public static void main(String[] args) {
List<String> lst = Arrays.asList("Box", "Toy", "Box", "Toy");
ArrayList<String> list = new ArrayList<>(lst);
for(String s : list)
System.out.print(s.toString() + '\t');
System.out.println();
HashSet<String> set = new HashSet<>(list);//HashSet은 중복이 안되서 2개가 들어
list = new ArrayList<>(set);//중복된것들이 빠진 상태로 들어감
for(String s : list)
System.out.print(s.toString() + '\t');
System.out.println();
}
}
/*
실행 결과
Box Toy Box Toy
Box Toy
*/-
asList는 추가, 삭제가 불가능 하기 때문에 ArrayList으로 새로 생성해주고, 중복된것을 삭제하고 싶다면 HashSet에 넣어 생성한뒤에 다시 ArrayList에 넣어 출력해준다.
- Set인터페이스의 성격에 맞게 중복된 인스턴스는 걸러지게 된다.
예제 15 Queue
FIFO
import java.util.Queue;
import java.util.LinkedList;
class LinkedListQueue {
public static void main(String[] args) {
Queue<String> que = new LinkedList<>();
// 데이터 저장
que.offer("Box");
que.offer("Toy");
que.offer("Robot");
// 무엇이 다음에 나올지 확인하는 메소드
System.out.println("next: " + que.peek());//FIFO이므로 Box가 출력
// 첫 번째, 두 번째 인스턴스 꺼내기
System.out.println(que.poll());
System.out.println(que.poll());
// 무엇이 다음에 나올지 확인
System.out.println("next: " + que.peek());
// 마지막 인스턴스 꺼내기
System.out.println(que.poll());
}
}
/*
실행 결과
next: Box
Box
Toy
next: Robot
Robot
*/peek()메소드:peek()메소드는 큐에서 요소를 제거하지 않고, 큐의 맨 앞에 있는 요소를 반환한다. > 비어있으면 null을 반환 >> 큐의 상태를 변경하지 않는다.poll()메소드:poll()메소드는 큐에서 요소를 제거하고, 제거한 요소를 반환한다. >> 요소를 반환하기 전에 큐에서 해당 요소를 제거한다.offer()메소드:offer()메소드는 큐에 요소를 추가한다.
- 큐에 요소가 추가되었으면
true를 반환하고, 큐의 용량이 제한되어 요소를 추가할 수 없는 경우에는false를 반환합니다. - 큐의 용량이 제한되어 요소를 추가할 수 없을 때, 예를 들어 고정된 크기의 큐에 이미 요소가 가득 차 있는 경우에는 요소가 추가되지 않습니다.
- 요소를 큐에 추가하는 동작은 큐의 상태를 변경합니다. 일반적으로 FIFO(선입선출) 순서에 따라 새로운 요소가 큐의 끝에 추가됩니다.
예제 16 Deque
양방향으로 넣고 뺴고가 가능해 Stack의 형태로도 사용하고, Queue의 형태로도 사용한다.
import java.util.Deque;
import java.util.ArrayDeque;
class ArrayDequeCollection {
public static void main(String[] args) {
Deque<String> deq = new ArrayDeque<>();
// 앞으로 넣고
deq.offerFirst("1.Box");
deq.offerFirst("2.Toy");
deq.offerFirst("3.Robot");
// 앞에서 꺼내기
System.out.println(deq.pollFirst());
System.out.println(deq.pollFirst());
System.out.println(deq.pollFirst());
}
}
/*
실행 결과
3.Robot
2.Toy
1.Box
/*-
앞으로 넣고, 꺼내고, 확인하기
boolean offerFirst(E e) 넣기, 공간 부족하면 false 반환
E pollFirst() 꺼내기, 꺼낼 대상 없으면 null 반환
E peekFirst() 확인하기, 확인할 대상 없으면 null 반환 -
뒤로 넣고, 꺼내고, 확인하기
boolean offerLast(E e) 넣기, 공간이 부족하면 false 반환
E poolLast() 꺼내기, 꺼낼 대상 없으면 null 반환
E peekLast() 확인하기, 확인할 대상 없으면 null 반환
- 앞으로 넣고, 꺼내고, 확인하기
void addFirst(E e) 넣기
E removeFirst() 꺼내기
E getFirst() 확인하기- 뒤로 넣고, 꺼내고, 확인하기
void addLast(E e) 넣기
E removeLast() 꺼내기
E getLast() 확인하기
- 보통 위에있는 메소드를 활용한다.
예제 17 push(넣기)/pop(빼기)
import java.util.ArrayDeque;
import java.util.Deque;
interface DIStack<E> {
public boolean push(E item);
public E pop();
}
class DCStack<E> implements DIStack<E> {
private Deque<E> deq;
public DCStack(Deque<E> d) {
deq = d;
}
public boolean push(E item) {
return deq.offerFirst(item);
}
public E pop() {
return deq.pollFirst();
}
}
class DefinedStack {
public static void main(String[] args) {
//아래와 같이 문장을 구성하면 리스트 기반의 스택이 생성된다.
//DIStack<String> stk = new DCStack<>(new LinkedList<String>());
DIStack<String> stk = new DCStack<>(new ArrayDeque<String>());
// PUSH 연산
stk.push("1.Box");
stk.push("2.Toy");
stk.push("3.Robot");
// POP 연산
System.out.println(stk.pop());
System.out.println(stk.pop());
System.out.println(stk.pop());
}
}
/*
실행 결과
3.Robot
2.Toy
1.Box
*/예제 18 HashMap
Key와 Value가 한 쌍을 이루는 형태로 데이터를 저장
import java.util.HashMap;
class HashMapCollection {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
// Key-Value 기반 데이터 저장
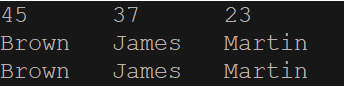
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// 데이터 탐색
System.out.println("23번: " + map.get(23)); //key를 넣으면 Value(값)을 가져온다.
System.out.println("37번: " + map.get(37));
System.out.println("45번: " + map.get(45));
System.out.println();
// 데이터 삭제
map.remove(37);
// 데이터 삭제 확인
System.out.println("37번: " + map.get(37)); //null
}
}
/*
실행 결과
23번: Martin
37번: James
45번: Brown
37번: null
*/-
Key는 지표이므로 중복될 수 없다. 반면 Key만 다르면 Value는 중복되어도 상관없다
-
Map<K, V>를 구현하는 대표 클래스로 HashMap<K, V>와 TreeMap<K, V>가
있다. 둘의 가장 큰 차이점은, 트리 자료구조를 기반으로 구현된 TreeMap<K, V>
은 정렬 상태를 유지한다는데 있다.정렬의 대상은 Value가 아니라 Key이다.
예제 18-1 HashMap
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
class HashMapIteration {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반)
for(Integer n : ks)
System.out.print(n.toString() + '\t'); //toString()은 키를 문자열로 변환 후 출력
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for(Integer n : ks)
System.out.print(map.get(n).toString() + '\t');
System.out.println();
// 전체 Value 출력 (반복자 기반)
for(Iterator<Integer> itr = ks.iterator(); itr.hasNext(); )
System.out.print(map.get(itr.next()) + '\t');//map.get(n)은 주어진 키 'n'에 해당하는 값을 반환 > 문자열로 변환후 출력
System.out.println();
}
}
/*
실행 결과
37 23 45
James Martin Brown
James Martin Brown
*/Set<Integer> ks = map.keySet();- Set은 Iterable을 상속하므로 예제에서 보이듯이 위의 문장 실행 이후에 for-each문을
통해서, 또는 반복자를 얻어서 순차적 접근을 진행할 수 있다.
예제 19 TreeMap
키를 기준으로 오름차순으로 정렬되어 있따.
import java.util.TreeMap;
import java.util.Iterator;
import java.util.Set;
class TreeMapIteration {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반)
for(Integer n : ks)
System.out.print(n.toString() + '\t');
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for(Integer n : ks)
System.out.print(map.get(n).toString() + '\t');
System.out.println();
// 전체 Value 출력 (반복자 기반)
for(Iterator<Integer> itr = ks.iterator(); itr.hasNext(); )
System.out.print(map.get(itr.next()) + '\t');
System.out.println();
}
}
/*
실행 결과
23 37 45
Martin James Brown
Martin James Brown
*/- 대상 컬렉션 인스턴스에 따라서 반환되는 반복자의 성격은 달라진다. TreeMap<K, V>
인스턴스에서 반환된 반복자는 오름차순으로 Key에 접근한다.
예제 20 TreeMap - Comparator
import java.util.TreeMap;
import java.util.Iterator;
import java.util.Set;
import java.util.Comparator;
class AgeComparator implements Comparator<Integer> {//내립차순으로 저장되도록
public int compare(Integer n1, Integer n2) {
return n2.intValue() - n1.intValue();
}
}
class ComparatorTreeMap {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>(new AgeComparator());
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반) - Comparator를 이용해 내림차순으로 저장되어 있다.
for(Integer n : ks)
System.out.print(n.toString() + '\t');
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for(Integer n : ks)
System.out.print(map.get(n).toString() + '\t'); //map.get(n) > 키를 주면 Value를 반환
System.out.println();
// 전체 Value 출력 (반복자 기반)
for(Iterator<Integer> itr = ks.iterator(); itr.hasNext(); )
System.out.print(map.get(itr.next()) + '\t');
System.out.println();
}
}
/*
실행 결과
45 37 23
Brown James Martin
Brown James Martin
*/TreeMap<Integer, String> map = new TreeMap<>(new AgeComparator());> 정렬기준을 AgeComparator()로 준다
AgeComparator 클래스가 Comparator를 구현하면서 T를 Integer로 결정한 이유는 정렬 대상인 Key가 Integer이기 때문이다.
위 예제 문제
- "Box", "Toy", "Box", "Toy"로 초기화 된 리스트를 만들고, 중복된 요소를 제거하시오.
package com.test.memo;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
public class Practice1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("Box", "Toy", "Box", "Toy");
ArrayList<String> lst = new ArrayList<>(list);
HashSet<String> hlst = new HashSet<>(lst);
list = new ArrayList<>(hlst);
for (String s : list) {
System.out.print(s + "\t");
}
}
}
더 효율적인 방법
package com.test.memo;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
public class Practice1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("Box", "Toy", "Box", "Toy");
HashSet<String> hlst = new HashSet<>(list);
for(String s : hlst) {
System.out.print(s + "\t");
}
}
}위 처음 코드처럼 ArrayList로 변환시켜주는 이유는, 저런 방법도 있다는것을 알려주는 것이다. 처음 ArrayList로 생성했을때 중복을 제거하고싶다면, HashSet에 넣어 중복을 제거하는 방법이 있다고 알려준것
- TreeMapIteration.java 소스 코드를 이용하여 Key를 기준으로 역순으로 정렬되게끔하자.
package com.test.memo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
class Com implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2.intValue() - o1.intValue();
}
}
public class Practice1 {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>(new Com());
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반)
for (Integer n : ks)
System.out.print(n.toString() + '\t');
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for (Integer n : ks)
System.out.print(map.get(n).toString() + '\t');
System.out.println();
// 전체 Value 출력 (반복자 기반)
for (Iterator<Integer> itr = ks.iterator(); itr.hasNext();)
System.out.print(map.get(itr.next()) + '\t');
System.out.println();
}
}
- 본래의 정렬 기준과 다른 기준으로 출력하고 싶기 때문에 Comparator를 구현해 기준을 세워주는 것이다.
익명클래스 이용한 코드
package com.test.memo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
public class Practice1 {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.intValue() - o1.intValue();
}
});
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반)
for (Integer n : ks)
System.out.print(n.toString() + '\t');
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for (Integer n : ks)
System.out.print(map.get(n).toString() + '\t');
System.out.println();
// 전체 Value 출력 (반복자 기반)
for (Iterator<Integer> itr = ks.iterator(); itr.hasNext();)
System.out.print(map.get(itr.next()) + '\t');
System.out.println();
}
}키로 비교하기 때문에 Integer 로 제네릭을 준다.
- 이렇게 한번 사용하는 형식이면 클래스를 따로 만들어주기 보다는 익명클래스로 만들어 일회용으로 사용하는게 더 효율적이다.
Arrays Class 메소드
Arrays.copyOf
import java.util.Arrays;
class CopyOfArrays {
public static void main(String[] args) {
double[] arOrg = {1.1, 2.2, 3.3, 4.4, 5.5};
// 배열 전체를 복사하여 배열 생성
double[] arCpy1 = Arrays.copyOf(arOrg, arOrg.length);
// 배열의 세번째 요소까지만 복사하여 배열 생성
double[] arCpy2 = Arrays.copyOf(arOrg, 3);
for(double d : arCpy1)
System.out.print(d + "\t");
System.out.println();
for(double d : arCpy2)
System.out.print(d + "\t");
System.out.println();
}
}
/*
실행 결과
1.1 2.2 3.3 4.4 5.5
1.1 2.2 3.3
*/- 복사할 배열을 생성하면서 붙여넣기
Arrays.equals > 배열의 내용 비교(boolean)
import java.util.Arrays;
class ArrayEquals {
public static void main(String[] args) {
int[] ar1 = {1, 2, 3, 4, 5};
int[] ar2 = Arrays.copyOf(ar1, ar1.length);
System.out.println(Arrays.equals(ar1, ar2));
}
}
/*
실행 결과
true
*/import java.util.Arrays;
class INum {
private int num;
public INum(int num) {
this.num = num;
}
}
class ArrayObjEquals {
public static void main(String[] args) {
INum[] ar1 = new INum[3];
INum[] ar2 = new INum[3];
ar1[0] = new INum(1);
ar2[0] = new INum(1);
ar1[1] = new INum(2);
ar2[1] = new INum(2);
ar1[2] = new INum(3);
ar2[2] = new INum(3);
System.out.println(Arrays.equals(ar1, ar2));
}
}
/*
실행 결과
false
*/-
기본적으로 비교를 할때 Object클래스에 정의되어 있는 equlas메소드는 참조값을 비교하기 때문에 참조 값 비교가 목적이 아닌 비교가 목적이라면 equlas메소드를 목적에 맞게 다시 오버라이딩해야한다.
public boolean equals(Object obj){ return this.num == ((INum)obj).num;}
System.arraycopy
class CopyOfSystem {
public static void main(String[] args) {
double[] org = {1.1, 2.2, 3.3, 4.4, 5.5};
double[] cpy = new double[3];
System.arraycopy(org, 1, cpy, 0, 3);
for(double d : cpy)
System.out.print(d + "\t");
System.out.println();
}
}
/*
실행 결과
2.2 3.3 4.4
*/- 기존에 존재하던 배열에 붙여넣기
Comparable
import java.util.Arrays;
class Person implements Comparable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Object o) {
Person p = (Person)o;
if(this.age > p.age)
return 1;
else if(this.age < p.age)
return -1;
else
return 0;
}
@Override
public String toString() {
return name + ": " + age;
}
}
class ArrayObjSort {
public static void main(String[] args) {
Person[] ar = new Person[3];
ar[0] = new Person("Lee", 29);
ar[1] = new Person("Goo", 15);
ar[2] = new Person("Soo", 37);
Arrays.sort(ar);
for(Person p : ar)
System.out.println(p);
}
}
/*
실행 결과
Goo: 15
Lee: 29
Soo: 37
*/binarySearch
반드시 배열이 정렬된 상태여야 한다.
import java.util.Arrays;
class ArraySearch {
public static void main(String[] args) {
int[] ar = {33, 55, 11, 44, 22};
Arrays.sort(ar); // 탐색 이전에 정렬이 선행되어야 한다.
for(int n : ar)
System.out.print(n + "\t");
System.out.println();
int idx = Arrays.binarySearch(ar, 33); // 배열 ar에서 33을 찾아라
System.out.println("Index of 33: " + idx);
}
}
/*
출력 결과
11 22 33 44 55
Index of 33: 2
*/public static int binarySearch(int[] a, int key)> 배열 a에서 key를 찾아서 있으면 key의 인덱스 값, 없으면 0보다 작은 수 반환
Comparable을 이용해 정렬해 binarySearch
import java.util.Arrays;
class Person implements Comparable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Object o) {
Person p = (Person)o;
return this.age - p.age; // 나이가 같으면 0을 반환
}
@Override
public String toString() {
return name + ": " + age;
}
}
class ArrayObjSearch {
public static void main(String[] args) {
Person[] ar = new Person[3];
ar[0] = new Person("Lee", 29);
ar[1] = new Person("Goo", 15);
ar[2] = new Person("Soo", 37);
Arrays.sort(ar); // 탐색에 앞서 정렬
int idx = Arrays.binarySearch(ar, new Person("Who are you?", 37));
System.out.println(ar[idx]);
}
}
/*
실행 결과
Soo: 37
*/Arrays 클래스 문제 복습
-
ArrayObjSort.java 파일안에 있는 배열을 다음의 실행 결과가 나오도록 정렬하여 출력하시오.
실행 결과
Boee: 10
Gee: 20
Cee: 30
package com.test.memo;
import java.util.Arrays;
class Person implements Comparable<Person> {
private String name;
private int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + " : " + age;
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
}
public class Practice1 {
public static void main(String[] args) {
Person[] pe = new Person[3];
pe[0] = new Person("Bee", 10);
pe[1] = new Person("Cee", 30);
pe[2] = new Person("Gee", 20);
Arrays.sort(pe);
for (Person p : pe) {
System.out.println(p);
}
}
}- Arrays.sort로 정렬 시키도않고 왜 정렬이 왜안되지..했네 ㅋㅋㅋ
- double[] arOrg = {1.1, 2.2, 3.3, 4.4, 5.5};
Arrays클래스를 이용하여 배열 전체 복사
package com.test.memo;
import java.util.Arrays;
public class Practice1 {
public static void main(String[] args) {
double[] arOrg = { 1.1, 2.2, 3.3, 4.4, 5.5 };
double[] cOrg = Arrays.copyOf(arOrg, arOrg.length);
for (double d : cOrg) {
System.out.println(d);
}
}
}- double[] arOrg = {1.1, 2.2, 3.3, 4.4, 5.5};
Arrays클래스를 이용하여 배열 세번째 요소까지 복사
package com.test.memo;
import java.util.Arrays;
public class Practice1 {
public static void main(String[] args) {
double[] arOrg = { 1.1, 2.2, 3.3, 4.4, 5.5 };
double[] cOrg = Arrays.copyOf(arOrg, 3);
for (double d : cOrg) {
System.out.println(d);
}
}
}- double[] arOrg = {1.1, 2.2, 3.3, 4.4, 5.5};
Arrays클래스를 이용하여 배열의 2.2가 저장된 요소부터 4.4가 저정된 요소까지 복사
package com.test.memo;
import java.util.Arrays;
public class Practice1 {
public static void main(String[] args) {
double[] arOrg = { 1.1, 2.2, 3.3, 4.4, 5.5 };
double[] cOrg = Arrays.copyOfRange(arOrg, 1, 4);
for (double d : cOrg) {
System.out.println(d);
}
}
}Arrays.copyOfRange();> 배열의 일부를 복사
- Arrays클래스를 이용하여 ar1 배열과 ar2 배열을 비교하여 두 배열의 내용이 같으면 true를 출력하자.
int[] ar1 = {1, 2, 3, 4, 5};
int[] ar2 = Arrays.copyOf(ar1, ar1.length);
package com.test.memo;
import java.util.Arrays;
public class Practice1 {
public static void main(String[] args) {
int[] ar1 = { 1, 2, 3, 4, 5 };
int[] ar2 = Arrays.copyOf(ar1, ar1.length);
System.out.println(Arrays.equals(ar1, ar2));
}
}Arrays.equals( , );> 배열의 내용이 같은지 비교하여 boolean으로 결과 출력
- 다음 소스 코드의 ar1배열과 ar2배열의 내용을 비교하여 내용이 같으면 true를 출력하자. Arrays 클래스 이용.
package com.test.memo;
import java.util.Arrays;
class INum {
private int num;
public INum(int num) {
this.num = num;
}
@Override
public boolean equals(Object obj) {
return this.num == ((INum) obj).num;
}
}
public class Practice1 {
public static void main(String[] args) {
INum[] ar1 = new INum[3];
INum[] ar2 = new INum[3];
ar1[0] = new INum(1);
ar2[0] = new INum(1);
ar1[1] = new INum(2);
ar2[1] = new INum(2);
ar1[2] = new INum(3);
ar2[2] = new INum(3);
System.out.println(Arrays.equals(ar1, ar2));
}
}Collection Framework 예제
예제 1-1 Arrays.sort - Collections.sort / Comparable
import java.util.List;
import java.util.Arrays;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Collections;
class SortCollections {
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy", "Box", "Robot", "Weapon");
list = new ArrayList<>(list);
// 정렬 이전 출력
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
// 정렬
Collections.sort(list);
// 정렬 이후 출력
for(Iterator<String> itr = list.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
}
}
/*
Toy Box Robot Weapon
Box Robot Toy Weapon
*/-
public static <T extends Comparable<T>> void sort(List<T> list)> 그런데 이 T는 Comparable 인터페이스를 구현한 상태이어야 한다.-
인자로 List의 인스턴스는 모두 전달 가능
-
단, T는 Comparable 인터페이스를 구현한 상태이어야 한다.
-
String 클래스의 compareTo 메소드는 사전 편찬 순으로(lexicographically) 정렬되도록 구현되어 있다.
public final class String extends Object implements Comparable<String>>> final이므로 다른 class가 String을 상속하지 못한다.
예제 1-2 ArraysList / Comparable - compareTo()
import java.util.List;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Collections;
class Car implements Comparable<Car> {
private int disp; // 배기량
public Car(int d) { disp = d; }
@Override
public String toString() {
return "cc: " + disp;
}
@Override
public int compareTo(Car o) { //오름차순 정렬되도록
return disp - o.disp;
}
}
class CarSortCollections {
public static void main(String[] args) {
List<Car> list = new ArrayList<>();
list.add(new Car(1200));
list.add(new Car(3000));
list.add(new Car(1800));
// 정렬
Collections.sort(list);
// 출력
for(Iterator<Car> itr = list.iterator(); itr.hasNext(); )
System.out.println(itr.next().toString() + '\t');
}
}
/*
실행 결과
cc: 1200
cc: 1800
cc: 3000
*/- \이 Comparable을 구현하고 있어야 정렬이 된다.
예제 2-1 Comparable을 구현하는 클래스를 상속하면?
import java.util.List;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Collections;
class Car implements Comparable<Car> {
protected int disp; // 배기량
public Car(int d) { disp = d; }
@Override
public String toString() {
return "cc: " + disp;
}
@Override
public int compareTo(Car o) {
return disp - o.disp;
}
}
class ECar extends Car {// ECar는 Comparable<Car>를 간접 구현
private int battery; // 배터리
public ECar(int d, int b) {
super(d);
battery = b;
}
@Override
public String toString() {
return "cc: " + disp + ", ba: " + battery;
}
}
class ECarSortCollections {
public static void main(String[] args) {
List<ECar> list = new ArrayList<>();
list.add(new ECar(1200, 99));
list.add(new ECar(3000, 55));
list.add(new ECar(1800, 87));
// 정렬
Collections.sort(list);
// 출력
for(Iterator<ECar> itr = list.iterator(); itr.hasNext(); )
System.out.println(itr.next().toString() + '\t');
}
}
/*
실행 결과
cc: 1200, ba: 99
cc: 1800, ba: 87
cc: 3000, ba: 55
*/
public static <T extends Comparable<T>> void sort(List<T> list)> \ 는 Comparable을 구현하고 있어야한다.
-
위처럼 간접적으로 Comparable을 상속받고있지만,
-
ECar는 Comparable는 구현하는 상태이지만 Comparable는 구현하지 않는 상태이다.
Comparable을 구현하고있는 상태이므로 Collections.sort()에 들어가지 못한다.
-
-
public static <T extends Comparable<? super T>> void sort(List<T> list)-
ECar 클래스는 다음 인터페이스 중 하나만 구현해도 위의 sort 메소드 호출은 성공한다.(다형성)
Comparable, Comparable, Comparable
주의
-
ECar클래스가Car클래스를 상속받는 것이 아니라Car클래스의 인스턴스를 포함하고 있다. -
이것은 상속(inheritance)과는 다른 개념으로
ECar는Car를 포함하고 있으므로ECar객체들을 정렬할 때Car객체의compareTo()메서드를 사용하여 정렬해야한다.
예제 2-2 Comparable을 구현한 클래스의 객체를 Collections.sort() 에서 함께 정의
import java.util.List; import java.util.ArrayList; import java.util.Iterator; import java.util.Comparator; import java.util.Collections; class Car { protected int disp; public Car(int d) { disp = d; } @Override public String toString() { return "cc: " + disp; } } // Car의 정렬을 위한 클래스 class CarComp implements Comparator<Car> { //Car와 ECar도 정렬할 수 있 @Override public int compare(Car o1, Car o2) { return o1.disp - o2.disp; } } class ECar extends Car { private int battery; public ECar(int d, int b) { super(d); battery = b; } @Override public String toString() { return "cc: " + disp + ", ba: " + battery; } } class CarComparator { public static void main(String[] args) { List<Car> clist = new ArrayList<>(); clist.add(new Car(1800)); clist.add(new Car(1200)); clist.add(new Car(3000)); List<ECar> elist = new ArrayList<>(); elist.add(new ECar(3000, 55)); elist.add(new ECar(1800, 87)); elist.add(new ECar(1200, 99)); CarComp comp = new CarComp(); // 각각 정렬 Collections.sort(clist, comp); Collections.sort(elist, comp); // 각각 출력 for(Iterator<Car> itr = clist.iterator(); itr.hasNext(); ) System.out.println(itr.next().toString() + '\t'); System.out.println(); for(Iterator<ECar> itr = elist.iterator(); itr.hasNext(); ) System.out.println(itr.next().toString() + '\t'); } } /* 실행 결과 cc: 1200 cc: 1800 cc: 3000 cc: 1200, ba: 99 cc: 1800, ba: 87 cc: 3000, ba: 55 */sort 메소드의 두 번째 매개변수 타입이 Comparator가 아닌 Comparator<? super T> 이기에 가능한 일이다.
예제 3 ArrayList - binarySearch
import java.util.List; import java.util.ArrayList; import java.util.Collections; class StringBinarySearch { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("Box"); list.add("Robot"); list.add("Apple"); // 정렬 Collections.sort(list); // 탐색 int idx = Collections.binarySearch(list, "Robot"); // 탐색 결과 출력 System.out.println(list.get(idx)); } } /* 실행 결과 Robot */-
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key)> list에서 key를 찾아 그 인덱스 값 반환, 못 찾으면 음의 정수 반환 -
List 인스턴스는 정렬된 상태를 유지하지 않으므로 위와 같이 정렬을 먼저
진행해야 한다. 만약에 정렬되지 않은 상태에서 binarySearch 메소드를 호출하면
정상적인 결과를 얻지 못한다
예제 4 ArrayList/Collections.sort / binarySearch
import java.util.List; import java.util.ArrayList; import java.util.Comparator; import java.util.Collections; class StrComp implements Comparator<String> { @Override public int compare(String s1, String s2) { return s1.compareToIgnoreCase(s2); } } class StringComparator { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("ROBOT"); list.add("APPLE"); list.add("BOX"); StrComp cmp = new StrComp(); // 정렬과 탐색의 기준 Collections.sort(list, cmp); // 정렬 int idx = Collections.binarySearch(list, "Robot", cmp); // 탐색 System.out.println(list.get(idx)); // 탐색 결과 출력 } } /* 실행 결과 ROBOT */
예제 5 Collectioins.copy/되돌려놓기
import java.util.List; import java.util.Arrays; import java.util.ArrayList; import java.util.Collections; class CopyList { public static void main(String[] args) { List<String> src = Arrays.asList("Box", "Apple", "Toy", "Robot"); // 복사본을 만들어서 사용 List<String> dest = new ArrayList<>(src); // 정렬하여 그 결과를 출력 Collections.sort(dest); System.out.println(dest); // 사정상 정렬 이전의 상태로 되돌려야 함 Collections.copy(dest, src); // 되돌림 확인 System.out.println(dest); } } /* 실행 결과 [Apple, Box, Robot, Toy] [Box, Apple, Toy, Robot] */이미 생성된 컬렉션 인스턴스의 내용을 통째로 바꾸려는 경우에 copy 메소드는 유용하게 사용된다.
Stack 문제
실행 결과가 다음과 같이 나오도록 소스코드를 완성해 보자.
back:[1.네이트, 2.야후, 3.네이버, 4.다음]
forward:[]
현재화면은 '4.다음' 입니다.= 뒤로가기 버튼을 누른 후 =
back:[1.네이트, 2.야후, 3.네이버]
forward:[4.다음]
현재화면은 '3.네이버' 입니다.= '뒤로' 버튼을 누른 후 =
back:[1.네이트, 2.야후]
forward:[4.다음, 3.네이버]
현재화면은 '2.야후' 입니다.= '앞으로' 버튼을 누른 후 =
back:[1.네이트, 2.야후, 3.네이버]
forward:[4.다음]
현재화면은 '3.네이버' 입니다.= 새로운 주소로 이동 후 =
back:[1.네이트, 2.야후, 3.네이버, codechobo.com]
forward:[]
현재화면은 'codechobo.com' 입니다.내가 푼 풀이
import java.util.*; public class StackEx1 { // 사용자가 이전에 방문한 페이지들의 URL을 저장합니다. 이전 페이지로 돌아가기 위해 back 스택에서 URL을 꺼내옵니다. public static Stack<String> back = new Stack<>(); // 사용자가 뒤로가기를 하고 나서 다시 앞으로 가기를 할 때 사용 public static Stack<String> forward = new Stack<>(); public static void main(String[] args) { goURL("1.네이트"); goURL("2.야후"); goURL("3.네이버"); goURL("4.다음"); printStatus(); // back:[1.네이트, 2.야후, 3.네이버, 4.다음] // forward:[] // 현재화면은 '4.다음' 입니다. goBack(); System.out.println("= 뒤로가기 버튼을 누른 후 ="); printStatus(); // = 뒤로가기 버튼을 누른 후 = // back:[1.네이트, 2.야후, 3.네이버] // forward:[4.다음] // 현재화면은 '3.네이버' 입니다. goBack(); System.out.println("= '뒤로' 버튼을 누른 후 ="); printStatus(); // = '뒤로' 버튼을 누른 후 = // back:[1.네이트, 2.야후] // forward:[4.다음, 3.네이버] // 현재화면은 '2.야후' 입니다. goForward(); System.out.println("= '앞으로' 버튼을 누른 후 ="); printStatus(); // = '앞으로' 버튼을 누른 후 = // back:[1.네이트, 2.야후, 3.네이버] // forward:[4.다음] // 현재화면은 '3.네이버' 입니다. goURL("codechobo.com"); System.out.println("= 새로운 주소로 이동 후 ="); printStatus(); // = 새로운 주소로 이동 후 = // back:[1.네이트, 2.야후, 3.네이버, codechobo.com] // forward:[] // 현재화면은 'codechobo.com' 입니다. } public static void printStatus() { System.out.println("back:"+back); System.out.println("forward:"+forward); System.out.println("현재화면은 '" + back.peek()+"' 입니다."); System.out.println(); } public static void goURL(String url){ back.push(url); if(!forward.empty()) forward.clear(); } public static void goForward(){ if(!forward.empty()) back.push(forward.pop()); } public static void goBack(){ if(!back.empty()) forward.push(back.pop()); } }스택과 큐의 활용
-
스택의 활용 예 - 수식계산, 수식괄호검사, 워드프로세서의 undo/redo,웹브라우저의 뒤로/앞으로
-
큐의 활용 예 - 최근사용문서, 인쇄작업 대기목록, 버퍼(buffer)
- 각각의 스택은 사용자가 방문한 페이지들의 이력을 따로 저장하고 관리하여 사용자가 효율적으로 브라우징할 수 있도록 한다.
-
goURL(String url) 메서드는 현재 URL을 스택에 저장하고 새 URL로 이동합니다. 만약 현재 URL이 비어있지 않다면, 이전 페이지를 back 스택에 추가하고 forward 스택을 비웁니다.
-
goBack() 메서드는 back 스택에서 URL을 꺼내 forward 스택에 추가하여 뒤로가기 동작을 구현합니다.
-
goForward() 메서드는 forward 스택에서 URL을 꺼내 back 스택에 추가하여 앞으로 가기 동작을 구현합니다.
-
printStatus() 메서드는 back 스택과 forward 스택의 내용을 출력하고, 현재 URL을 출력하여 현재 화면을 표시합니다.
괄호가 제대로 쳐져있는지 검증하는 코드 -Stack
c:\JavaStudy\java ExpValidCheck
Usage : java ExpValidCheck "EXPRESSION"
Example : java ExpValidCheck "((2+3)*1)+3"c:\JavaStudy\java ExpValidCheck\java ExpValidCheck (2+3)1
expression:(2+3)1
괄호가 일치합니다.c:\JavaStudy\java ExpValidCheck\java ExpValidCheck (2+31
expression:(2+31
괄호가 일치하지 않습니다.
위와 같은 실행결과가 나오도록 코딩하시오(입력한 수식의 괄호가 올바른지 체크)선생님 풀이
import java.util.*; public class ExpValidCheck { public static void main(String[] args) { if(args.length!=1){ System.out.println("Usage : java ExpValidCheck \"EXPRESSION\""); System.out.println("Example : java ExpValidCheck \"((2+3)*1)+3\""); System.exit(0); } Stack<String> st = new Stack<>(); String expression = args[0]; System.out.println("expression:"+expression); try { for(int i=0; i < expression.length();i++){ char ch = expression.charAt(i); if(ch=='('){ st.push(ch+""); } else if(ch==')') { st.pop(); } } if(st.isEmpty()){ System.out.println("괄호가 일치합니다."); } else { System.out.println("괄호가 일치하지 않습니다."); } } catch (EmptyStackException e) {//스택에 아무것도 없는데 가져오려 할때 발생하는 예외 System.out.println("괄호가 일치하지 않습니다."); } // try } } /* java ExpValidCheck (2+3)*1 expression:(2+3)*1 괄호가 일치합니다. */
Queue 문제
help를 입력하면 도움말을 볼 수 있습니다.
help
help - 도움말을 보여줍니다.
q 또는 Q - 프로그램을 종료합니다.
history - 최근에 입력한 명령어를 5개 보여줍니다.
dir
dir
cd
cd
mkdir
mkdir
dir
dir
history
1.dir
2.cd
3.mkdir
4.dir
5.history
qimport java.util.*; class QueueEx1 { static Queue<String> q = new LinkedList<>(); static final int MAX_SIZE = 5; // Queue에 최대 5개까지만 저장되도록 한다. Scanner s = new Scanner(System.in); public static void main(String[] args) { System.out.println("help를 입력하면 도움말을 볼 수 있습니다."); while(true) { System.out.print(">>"); try { // 화면으로부터 라인단위로 입력받는다. String input = s.nextLine().trim();//입력에 공백제거 if("".equals(input)) continue; if(input.equalsIgnoreCase("q")) { System.exit(0); s.close(); } else if(input.equalsIgnoreCase("help")) { System.out.println(" help - 도움말을 보여줍니다."); System.out.println(" q 또는 Q - 프로그램을 종료합니다."); System.out.println(" history - 최근에 입력한 명령어를 " + MAX_SIZE +"개 보여줍니다."); } else if(input.equalsIgnoreCase("history")) { int i=0; // 입력받은 명령어를 저장하고, save(input); // LinkedList의 내용을 보여준다. LinkedList<String> tmp = (LinkedList<String>)q; ListIterator<String> it = tmp.listIterator();//양방향 반복 while(it.hasNext()) { System.out.println(++i+"."+it.next()); } } else { save(input); System.out.println(input); } } catch(Exception e) { System.out.println("입력오류입니다."); } } // while(true) } // main() public static void save(String input) { // queue에 저장한다. if(!"".equals(input)) q.offer(input); // queue의 최대크기를 넘으면 제일 처음 입력된 것을 삭제한다. if(q.size() > MAX_SIZE) // size()는 Collection인터페이스에 정의 q.remove();//제일 처음에 있는 값 삭제 (제일 처음에 들어온 } } // end of class /* 이 예제는 유닉스의 history 명령어를 Queue를 이용해서 구현한 것이다. history명령어 는 사용자가 입력한 명령어의 이력을 순서대로 보여 준다. 여기서는 최근 5개의 명령어 만을 보여주는데 MAX_SIZE의 값을 변경함으로써 더 많은 명령어 입력기록을 남길 수 있다. */실제로 콘솔에서 F7을 누르거나,
doseky /history를 입력하면 이전에 작성했던 것들을 볼 수 있다.LinstIterator는 ArrayList와 LinkedList와 같은 List인터페이스를 구현한 컬렉션에서 사용할 수 있고, 순회하며 요소를 추가, 수정, 삭제할 수 있다.
List 문제 - ListIterator()활용
다음의 실행 결과는?
import java.util.*; class ListIteratorEx1 { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add("1"); list.add("2"); list.add("3"); list.add("4"); list.add("5"); ListIterator it = list.listIterator(); while(it.hasNext()) { System.out.print(it.next()); // 순방향으로 진행하면서 읽어온다. } System.out.println(); while(it.hasPrevious()) { System.out.print(it.previous()); // 역방향으로 진행하면서 읽어온다. } System.out.println(); } } /* 12345 54321 */hasPrevious()- 이전 요소가 있는지 확인prevoius()- 역순으로 이전 요소를 읽어온다.
-
-
