오전문제
컬렉션 프레임 워크
- "Box", "Toy", "Box", "Toy"로 초기화 된 리스트를 만들고, 중복된 요소를 제거하시오.
package com.test.memo;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
public class Practice {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("Box");
list.add("Toy");
list.add("Box");
list.add("Toy");
Iterator<String> itr = list.iterator();
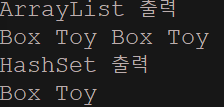
System.out.println("ArrayList 출력");
while (itr.hasNext()) {
System.out.print(itr.next() + " ");
}
System.out.println();
Set<String> set = new HashSet<>(list);
Iterator<String> it = set.iterator();
System.out.println("HashSet 출력");
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
}
}
- TreeMapIteration.java 소스 코드를 이용하여 Key를 기준으로 역순으로 정렬되게끔하자.
package com.test.memo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
public class Practice {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.intValue() - o1.intValue();//Integer객체의 정수값을 비
} //이 값이 양수면 o2가 더크다고 판단 > 내립차순
});
// Key-Value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// Key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 Key 출력 (for-each문 기반)
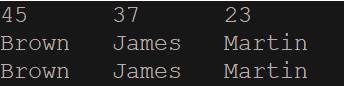
for (Integer n : ks)
System.out.print(n.toString() + '\t');
System.out.println();
// 전체 Value 출력 (for-each문 기반)
for (Integer n : ks)
System.out.print(map.get(n).toString() + '\t');
System.out.println();
// 전체 Value 출력 (반복자 기반)
for (Iterator<Integer> itr = ks.iterator(); itr.hasNext();)
System.out.print(map.get(itr.next()) + '\t');
System.out.println();
}
}
- String source = "0123456789abcdefghijABCDEFGHIJ!@#$%^&*()ZZZ";
위에 문자열을 10글자씩 잘라서 ArrayList에 넣자.
package com.test.memo;
import java.util.ArrayList;
public class Practice {
public static void main(String[] args) {
String source = "0123456789abcdefghijABCDEFGHIJ!@#$%^&*()ZZZ";
ArrayList<String> list = new ArrayList<>();
// 문자열을 10글자씩 자르고 추가
for (int i = 0; i < source.length(); i += 10) {
// 마지막에 남은 부분이 10글자보다 작을 수 있으므로
if (i + 10 <= source.length()) {
list.add(source.substring(i, i + 10));
} else {
list.add(source.substring(i));
}
}
for (String s : list) {
System.out.print(s + "\t");
}
}
}-
substring()메서드는 첫 번째 매개변수부터 두 번째 매개변수-1 까지의 문자열을 잘라 반환한다. -
위에서는 0부터 9까지 자르고, 10부터 19까지 잘라 배열에 저장되는 기능을 수행하고 있다.
- 공간이 1000000개 짜리 ArrayList와 LinkedList를 각각 생성하고
두 객체다 0부터 100000요소까지 요소를 초기화하자.
그리고 0부터 10000요소까지 값을 순차적으로 가져오자.
0부터 10000번째 요소까지 값을 가져오는 시간을 각각 측정하여 출력해보자.
package com.test.memo;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Practice {
public static void main(String[] args) {
List<Integer> aList = new ArrayList<>(1000000);
List<Integer> lList = new LinkedList<>();// LinkedList는 용량을 지정할 수 없다.
// 요소 초기화
for (int i = 0; i <= 1000000; i++) {
aList.add(i);
lList.add(i);
}
// 시작시간
long startTime = System.currentTimeMillis();
for (int i = 0; i <= 10000; i++) {
int Array = aList.get(i);
}
// 끝난 시간
long endTime = System.currentTimeMillis();
// 결론적으로 걸린 시간
long ArrayTime = endTime - startTime;
startTime = System.currentTimeMillis();
for (int i = 0; i <= 10000; i++) {
int Linke = lList.get(i);
}
endTime = System.currentTimeMillis();
long linkedTime = endTime - startTime;
System.out.println("ArrayList : " + ArrayTime);
System.out.println("LinkedList : " + linkedTime);
}
}Stack
package com.test.memo;
import java.util.Stack;
public class Practice {
public static Stack back = new Stack();
public static Stack forward = new Stack();
static void printStatus() {
System.out.println("back: " + back);
System.out.println("forward: " + forward);
System.out.println("현재화면은 '" + back.peek() + "' 입니다.");
System.out.println();
}
static void goURL(String s) {
back.push(s);
if (!forward.empty()) {
forward.clear();
}
}
static void goForward() {
if (!forward.empty()) {
back.push(forward.pop());
}
}
static void goBack() {
if (!back.empty()) {
forward.push(back.pop());
}
}
public static void main(String[] args) {
goURL("1.네이트");
goURL("2.야후");
goURL("3.네이버");
goURL("4.다음");
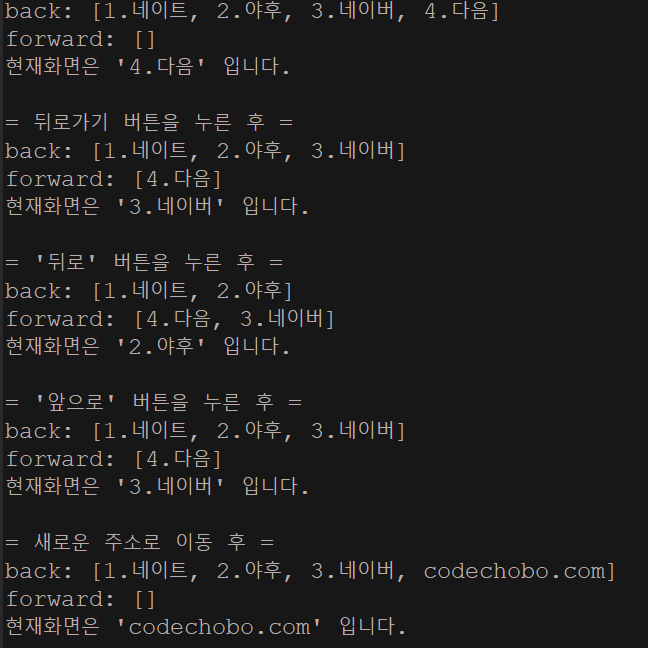
printStatus();
// back:[1.네이트, 2.야후, 3.네이버, 4.다음]
// forward:[]
// 현재화면은 '4.다음' 입니다.
goBack();
System.out.println("= 뒤로가기 버튼을 누른 후 =");
printStatus();
// = 뒤로가기 버튼을 누른 후 =
// back:[1.네이트, 2.야후, 3.네이버]
// forward:[4.다음]
// 현재화면은 '3.네이버' 입니다.
goBack();
System.out.println("= '뒤로' 버튼을 누른 후 =");
printStatus();
// = '뒤로' 버튼을 누른 후 =
// back:[1.네이트, 2.야후]
// forward:[4.다음, 3.네이버]
// 현재화면은 '2.야후' 입니다.
goForward();
System.out.println("= '앞으로' 버튼을 누른 후 =");
printStatus();
// = '앞으로' 버튼을 누른 후 =
// back:[1.네이트, 2.야후, 3.네이버]
// forward:[4.다음]
// 현재화면은 '3.네이버' 입니다.
goURL("codechobo.com");
System.out.println("= 새로운 주소로 이동 후 =");
printStatus();
// = 새로운 주소로 이동 후 =
// back:[1.네이트, 2.야후, 3.네이버, codechobo.com]
// forward:[]
// 현재화면은 'codechobo.com' 입니다.
}
}
Collection Framework 핵심 정리
컬렉션 프레임워크는 다 제네릭형태로 쓰지만 책내용을 인용한 것이기 때문에, 제네릭을 사용하지 않고 먼저 컬렉션 프레임워크에 대해 공부하는것
Stack 과 Queue
-
스택은 ArrayList로 구현이 좋다.
-
큐는 첫번째 값이 항상 삭제되기에 LinkedLIst가 좋다.ㅡ> 일리있는 말인지는..
PriorityQueue
- 저장한 순서에 관계없이 우선순위가 높은 순위로 저장된다.
- null값을 저장할 수 없다.
숫자가 작은게 우선순위가 높다. >> 자손들은 자체적으로 숫자를 비교하는 방법을 정의하고 있기 때문에 비교방법을 지정하지 않아도 된다.
객체를 저장할 수도 있는데 그럴 경우 각 객체의 크기를 비교할 수 있는 방법 제공해야 한다.
import java.util.*;
class PriorityQueueEx {
public static void main(String[] args) {
Queue pq = new PriorityQueue();
pq.offer(3); // pq.offer(new Integer(3)); 오토박싱
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq); // pq의 내부 배열을 출력
Object obj = null;
// PriorityQueue에 저장된 요소를 하나씩 꺼낸다.
while((obj = pq.poll())!=null)
System.out.println(obj);
}
}
/*
[1, 2, 5, 3, 4]
1
2
3
4
5
*/-
참조변수 pq를 출력하면, PriorityQueue가 내부적으로 가지고 있는 배열의 내용이
출력되는데, 저장한 순서와 다르게 저장되었다. 힙이라는 자료구조의 형태로 저장된 것
이라서 그렇다.[참고]
힙 자료구조는 완전 이진 트리를 기초로 하는 자료구조이다. 완전 이진트리는 마지막을 제외한 모든 노드에서 자식들이 꽉 채워진 이진트리를 말한다.
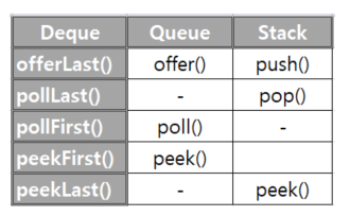
Dequeue
- 양쪽 끝에 추가/삭제가 가능하다.
Set
- TreeSet이 HashSet보다 추가 삭제가 오래걸린다. >> TreeSet은 정렬되어 저장되기 때문에 시간이 더 걸리는것임
import java.util.*;
class HashSetEx1 {
public static void main(String[] args) {
Object[] objArr = {"1",Integer.valueOf(1),"2","2","3","3","4","4","4"};
Set set = new HashSet();
for(int i=0; i < objArr.length; i++) {
set.add(objArr[i]); // HashSet에 objArr의 요소들을 저장한다.
}
// HashSet에 저장된 요소들을 출력한다.
System.out.println(set);
// [1, 1, 2, 3, 4]
}
}-
중복이 제거되고, 문자열 1과, Integer객체 1 인것이다
제네릭을 사용하게되면 위처럼 사용되지 못한다.
HashSet은 저장순서를 유지하지 않으므로, 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야한다.
initialCapacity, loadFactor


Iterator, ListIterator, Enumeration
collection에 저장된 데이터를 접근하는데 사용되는 인터페이스
-
Iterator
List와 Set인터페이스를 구현하는 컬렉션은 iterator()가 컬렉션의 특징에 맞게 작성되어있다.
주로 while문을 사용해 컬렉션 클래스들의 요소를 읽어온다.
-
컬렉션에 저장된 요소들을 읽어오는 방법을 표준화
-
컬렉션에 iterator()를 호출해서 Iterator를 구현한 객체를 얻어서 사용
-
Iterator는 1회용이므로 다 사용했다면 다시 얻어와야 한다.
-

-
ListIterator
-
Iterator의 접근성을 향상시킨 것이 ListIterator이다
- 단방향 > 양방향
-
ListIterator()를 통해서 얻을 수 있다(List를 구현한 컬렉션 클래스에 존재)
-
-
Enumeration
-
Enumerations은 Iterator의 구버전이다. > 왠만하면 Iterator사용
- 이전 버전으로 작성된 소스와의 호환을 위해 남겨둔
-

-
Map과 Iterator
-
Map은 Collection의 자손이 아니므로 Iterator()가 없다.
-
그래서 Map은 keySet(), entrySet(), values()를 호출해 Iterator()를 호출해야한다.
-
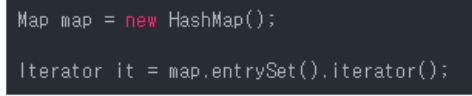
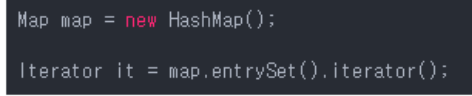
Iterator 커서 예제1
import java.util.*;
public class MyVector2 extends MyVector implements Iterator {
int cursor = 0;
int lastRet = -1;
public MyVector2(int capacity) {
super(capacity);
}
public MyVector2() {
this(10);
}
public String toString() {
String tmp = "";
Iterator it = iterator();
for(int i=0; it.hasNext();i++) {
if(i!=0) tmp+=", ";
tmp += it.next(); // tmp += next().toString();
}
return "["+ tmp +"]";
}
public Iterator iterator() {
cursor=0; // cursor와 lastRet를 초기화 한다.
lastRet = -1;
return this;
}
public boolean hasNext() {
return cursor != size();
}
public Object next(){//커서가 가리키는 요소를 반환하고, 커서를 다음 위치로 이동
Object next = get(cursor);// 커서가 0이면 0번째 인덱스의 값을 가져옴
lastRet = cursor++; //후치증감임
return next;
}
public void remove() {//마지막으로next()로 반환된 요소 삭제 하면서 땡
// 더이상 삭제할 것이 없으면 IllegalStateException를 발생시킨다.
if(lastRet==-1) {
throw new IllegalStateException();
} else {
remove(lastRet);
cursor--; // 삭제 후에 cursor의 위치를 감소시킨다. > 앞으로 땡겨야하니까
lastRet = -1; // lastRet의 값을 초기화 한다.
}
}
} // class
class MyVector2Test {
public static void main(String args[]) {
MyVector2 v = new MyVector2();
v.add("0");
v.add("1");
v.add("2");
v.add("3");
v.add("4");
System.out.println("삭제 전 : " + v);
Iterator it = v.iterator();
it.next();
it.remove(); // it에 0이 들어갔으므로, 0번쨰 인덱스 값을 삭제
it.next(); //인덱스 0에 이제 1이 들어가있는것 > 0이 삭제되었으니 앞으로 땡겨지도록 코드를 짰기 때문
it.remove();
System.out.println("삭제 후 : " + v);
}
}
/*
삭제 전 : [0, 1, 2, 3, 4]
삭제 후 : [2, 3, 4]
cursor는 앞으로 읽어 올 요소의 위치를 저장하는데 사용되고, lastRet는 마지막으로
읽어 온 요소의 위치(index)를 저장하는데 사용된다.
그래서 lastRet는 cursor보다 항상 1이 작은 값이 저장되고 remove()를 호출하면
이미 next()를 통해서 읽은 위치의 요소, 즉 lastRet에 저장된 값의 위치에 있는 요소를
삭제하고 lastRet의 값을 -1로 초기화 한다.
만일 next()를 호출하지 않고 remove()를 호출하면 lastRet의 값은 -1이 되어
IllegalStateException이 발생한다. remove()는 next()로 읽어 온 객체를 삭제하는 것이기
때문에 remove()를 호출하기 전에는 반드시 next()가 호출된 상태이어야 한다.
public void remove() {
// 더이상 삭제할 것이 없으면 IllegalStateException를 발생시킨다.
if(lastRet==-1) {
throw new IllegalStateException();
} else {
remove(lastRet); // 최근에 읽어온 요소를 삭제한다.
cursor--; // cursor의 위치를 1 감소시킨다.
lastRet = -1; // 읽어온 요소가 삭제되었으므로 초기화 한다.
}
}
위의 코드에서 보면 remove(lastRet)를 호출하여 lastRet의 위치에 있는 객체를 삭제한
다음에 cursor의 값을 감소시킨다. 그리고 lastRet의 값을 초기화(-1)한다.
그 이유는 remove메서드를 호출해서 객체를 삭제하고 나면, 삭제된 위치 이후의 객체들이
빈 공간을 채우기 위해 자동적으로 이동되기 때문에 cursor의 위치도 같이 이동
시켜주어야 한다. 그리고 읽어온 요소가 삭제되었으므로 읽어온 요소의 위치를 저장하는
lastRet의 값은 -1로 초기화해야 한다. lastRet의 값이 -1이라는 것은 읽어온 값이 없다는
것을 의미한다.
[참고] lastRet의 값이 -1이라는 것은 읽어 온 값이 없다는 의미이다. remove()는 읽어온 값이
있어야 호출될 수 있음을 기억하자.
*/remove() 메서드에서 cursor 변수를 감소시켜 땡겨지는 기능을 구현하고 있습니다. 이는 삭제된 후의 커서 위치를 조정하여 요소를 제대로 참조할 수 있도록 한다.

ArrayList
처음에 크기를 지정해주는게 좋다.
import java.util.*;
public class IteratorEx2 {
public static void main(String[] args) {
ArrayList original = new ArrayList(10);
ArrayList copy1 = new ArrayList(10);
ArrayList copy2 = new ArrayList(10);
for(int i=0; i < 10; i++)//오토박싱
original.add(i+"");
Iterator it = original.iterator();
while(it.hasNext())
copy1.add(it.next());//copy할곳에 반복자를 통해 순차적으로 복사중인것
System.out.println("= Original에서 copy1로 복사(copy) =");
System.out.println("original:"+original);
System.out.println("copy1:"+copy1);
System.out.println();
it = original.iterator(); // Iterator는 재사용이 안되므로, 다시 얻어와야 한다.
while(it.hasNext()){
copy2.add(it.next());
it.remove();
}
System.out.println("= Original에서 copy2로 이동(move) =");
System.out.println("original:"+original);
System.out.println("copy2:"+copy2);
} // main
} // class
/*
= Original에서 copy1로 복사(copy) =
original:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
copy1:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
= Original에서 copy2로 이동(move) =
original:[]
copy2:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
*/Array 클래스
Arrays에 정의된 메서드는 모두 static 이다.
배열의 복사 - copyOf(), copyOfRange()

배열 채우기 - fill(), setAll()

배열의 정과 검색 - sort(), binarySearch()
배열의 비교와 출력 - equals(), toString()

배열을 List로 변환 - asList()
asList()는 추가 삭제 >> 변경이 불가능하다.

예제
import java.util.*;
class ArraysEx {
public static void main(String[] args) {
int[] arr = {0,1,2,3,4};
int[][] arr2D = {{11,12,13}, {21,22,23}};
System.out.println("arr="+Arrays.toString(arr));
// arr=[0, 1, 2, 3, 4]
System.out.println("arr2D="+Arrays.deepToString(arr2D));
// arr2D=[[11, 12, 13], [21, 22, 23]]
int[] arr2 = Arrays.copyOf(arr, arr.length);
int[] arr3 = Arrays.copyOf(arr, 3);
int[] arr4 = Arrays.copyOf(arr, 7);
int[] arr5 = Arrays.copyOfRange(arr, 2, 4);
int[] arr6 = Arrays.copyOfRange(arr, 0, 7);
System.out.println("arr2="+ Arrays.toString(arr2));
// arr2=[0, 1, 2, 3, 4]
System.out.println("arr3="+ Arrays.toString(arr3));
// arr3=[0, 1, 2]
System.out.println("arr4="+ Arrays.toString(arr4));
// arr4=[0, 1, 2, 3, 4, 0, 0]
System.out.println("arr5="+ Arrays.toString(arr5));
// arr5=[2, 3]
System.out.println("arr6="+ Arrays.toString(arr6));
// arr6=[0, 1, 2, 3, 4, 0, 0]
int[] arr7 = new int[5];
Arrays.fill(arr7, 9); // arr=[9,9,9,9,9]
System.out.println("arr7="+Arrays.toString(arr7));
// arr7=[9, 9, 9, 9, 9]
Arrays.setAll(arr7, i -> (int)(Math.random()*6)+1);//람다식 사용
System.out.println("arr7="+Arrays.toString(arr7));
// arr7=[3, 4, 2, 2, 3]
for(int i : arr7) {
char[] graph = new char[i];//i만큼의 배열길이 생성
Arrays.fill(graph, '*');
System.out.println(new String(graph)+i);
}
/*
***3
****4
**2
**2
***3
*/
String[][] str2D = new String[][]{{"aaa","bbb"},{"AAA","BBB"}};
String[][] str2D2 = new String[][]{{"aaa","bbb"},{"AAA","BBB"}};
System.out.println(Arrays.equals(str2D, str2D2)); // false
System.out.println(Arrays.deepEquals(str2D, str2D2)); // true 2차원 이상의 배열을비교할 때 쓰는 메서드
char[] chArr = { 'A', 'D', 'C', 'B', 'E' };
//binarySearch는 반드시 정렬필수 !!
int idx = Arrays.binarySearch(chArr, 'B');
System.out.println("chArr="+Arrays.toString(chArr));
// chArr=[A, D, C, B, E]
System.out.println("index of B ="+Arrays.binarySearch(chArr, 'B'));
// index of B =-2
System.out.println("= After sorting =");
Arrays.sort(chArr);
System.out.println("chArr="+Arrays.toString(chArr));
// chArr=[A, B, C, D, E]
System.out.println("index of B ="+Arrays.binarySearch(chArr, 'B'));
// index of B =1
}
}-
람다식 : `
Arrays.setAll(arr7, i -> (int)(Math.random()*6)+1);- arr7의 각 요소를 초기화하는 부분으로 인덱스 i에 대해 1부터 6사이의 무작위 정수를 반환하는 함수다. arr7배열의 각 요소를 1부터 6사이의 무작위 정수로 초기화한다.
-
Arrays.deepEquals: 2차원 이상의 배열들을 비교할 때 사용하는 메서드
Comparator와 Comparable
Character클래스의 Comparable의 구현에 의해 Arrays.sort()가 정렬되었던것이다.
-
Comparable: Integer 와 같은 wrapper 클래스와 String Date, File과 같은것들이며 기본적으로 오름차순 >> 작은 값에서 큰 값의 순으로 정렬되도록 구현되어 있다.
- 기본 오름차순이지만, 내립차순이나, 다른 기준에 의해서 정렬되도록 하고 싶을 때 Comparator를 구현해서 정렬기준을 제공한다.

Integer클래스의 일부로, Comparable 의 compareTo()를 구현
Comparable : 기본정렬 기준을 구현하는데 사용
Comparator : 기본 정렬 기준 외에 다른 기준으로 정렬할때 사용

문자열을 대소문자 구분없지 정렬하는 법 - String.CASE_INSENSITIVE_ORDER
import java.util.*;
class ComparatorEx {
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr); // String의 Comparable구현에 의한 정렬
System.out.println("strArr=" + Arrays.toString(strArr));
// strArr=[Dog, cat, lion, tiger] 아스키코드값으로 정렬
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분안함
System.out.println("strArr=" + Arrays.toString(strArr));
// strArr=[cat, Dog, lion, tiger]
Arrays.sort(strArr, new Descending()); // 역순 정렬 - Comparator로 정렬기준 정
System.out.println("strArr=" + Arrays.toString(strArr));
// strArr=[tiger, lion, cat, Dog]
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2){
if( o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2) * -1 ; // -1을 곱해서 기본 정렬방식의 역으로 변경한다.
// 또는 c2.compareTo(c1)와 같이 순서를 바꿔도 된다.
}
return -1;
}
}
/*
Comparable 기본 정렬기준을 구현하는데 사용.
Comparator 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용.
*/- Comparable로 형변환하는 이유 : Comparable인터페이스를 구현했는지 확인하고, 구현했다면 형변환해 compareTo()메서드를 사용해 비교한다.
컬렉션 프레임워크 문제 - 중요(꼭 다시 풀어보기)
- HashSet과 LinkedList를 이용하여 로또번호 만들기.(정렬하여 출력)
내가 푼 코드
package com.test.memo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
public class Practice {
public static void main(String[] args) {
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 6; i++) {
int ran = (int) (Math.random() * 45) + 1;
list.add(ran);
}
Set<Integer> set = new HashSet<>(list);
List<Integer> setList = new LinkedList<>(set);
Collections.sort(setList);
Iterator<Integer> it = setList.iterator();
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
}
}- 굳이 LinkedList로 생성할 필요없이 HashSet으로 바로 생성해 값을 넣고 LinkedList로 변환시켜주면 되는것이였다.
선생님 코드
import java.util.Collections;
import java.util.HashSet;
import java.util.LinkedList;
public class Test1 {
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
while(set.size()<6) {
set.add((int)(Math.random()*45)+1);
}
LinkedList<Integer> list = new LinkedList<Integer>(set);
Collections.sort(list);
System.out.println(list);
}
}
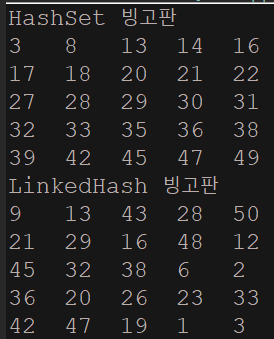
//1. HashSet과 LinkedList를 이용하여 로또번호 만들기.(정렬하여 출력)- HashSet과 LinkedHashSet을 이용하여 5 * 5 빙고를 만들어 출력하자. 번호는 1이상 50이하로 하자.(HashSet으로 한번, LinkedHashSet으로 한번)
package com.test.memo;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Random;
import java.util.Set;
public class Practice {
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
Random ran = new Random();
while (set.size() < 25) {
int random = ran.nextInt(50) + 1;
set.add(random);
}
Set<Integer> linkedSet = new LinkedHashSet<>();
while (linkedSet.size() < 25) {
int random = ran.nextInt(50) + 1;
linkedSet.add(random);
}
System.out.println("HashSet 빙고판");
int cnt = 0;
for (int i : set) {
System.out.printf("%-4d", i);
cnt++;
if (cnt % 5 == 0) {
System.out.println();
}
}
cnt = 0;
System.out.println("LinkedHash 빙고판");
for (int i : linkedSet) {
System.out.printf("%-4d", i);
cnt++;
if (cnt % 5 == 0) {
System.out.println();
}
}
}
}
선생님 코드
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class Test2 {
public static void main(String[] args) {
// Set<Integer> set = new LinkedHashSet<>();
Set<Integer> set = new HashSet<>();
while(set.size()<25) {
set.add((int)(Math.random()*50)+1);
}
Iterator<Integer> itr = set.iterator();
int i=0;
while(itr.hasNext()) {
System.out.print(itr.next()+"\t");
i++;
if(i%5==0) {
System.out.println();
i=0;
}
}
}
}
//2. HashSet과 LinkedHashSet을 이용하여 5 * 5 빙고를 만들어 출력하자. 번호는 1이상 50이하로 하자.- HashSet 객체를 두 개를 만들고, 하나에는 1, 2, 3, 4, 5를 넣고
다른 하나에는 4, 5, 6, 7, 8을 넣자.
그리고 두 개의 합 집합, 교집합, 차집합을 구해서 출력하자.
package com.test.memo;
import java.util.HashSet;
import java.util.Set;
public class Practice {
public static void main(String[] args) {
Set<Integer> set1 = new HashSet<>();
Set<Integer> set2 = new HashSet<>();
for (int i = 0; i < 5; i++) {
set1.add(i + 1);
set2.add(i + 4);
}
Set<Integer> union = new HashSet<>(set1);//직접 출력하면 연산의 성공 여부만을 확인가능
union.addAll(set2); //
System.out.println("합집합 : " + union);
Set<Integer> inter = new HashSet<>(set1);
inter.retainAll(set2);
System.out.println("교집합 : " + inter);
Set<Integer> relative = new HashSet<>(set1);
relative.removeAll(set2);
System.out.println("차집합 : " + relative);
}
}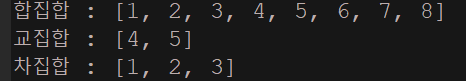
-
HashSet은 addAll()메서드를 사용해 한 집합에 다른 집합의 모든 요소를 추가할 수 있다.
-
set1.addAll(set2);로 코드를 작성하면 set1에 set2의 모든 요소가 추가되기에 본래의 배열이 변경되는것이다. -
변경된 결과를 별도의 객체로 얻고싶기 때문에 별도의 HashSet을 생성하여 결과를 저장했다. >> 이 방법이 일반적이다.
-
union에 합집합 값이 들어간 이유
union이라는 새로운 HashSet을 생성하고, 이 HashSet에set1의 모든 요소를 추가합니다.- 그 후에
addAll()메서드를 사용하여set2의 모든 요소를union에 추가합니다. 이로써union은set1과set2의 합집합이 됩니다.
혼자 사용하면 boolean으로 반환, 그러므로 새로운 집합에 저장되는 것임
- 결국직접 출력하려하면, 연산의 성공여부(boolean)만을 확인할 수 있기 때문에, 연산 결과를 직접적으로 출력하고 싶다면, 집합 연산 메서드를 호출하여연산을 수행하고 그 결과를 다시 집합에 저장해 출력하는 방식을 사용해야한다.
선생님 코드
import java.util.*;
class Test3 {
public static void main(String args[]) {
HashSet<String> setA = new HashSet<>();
HashSet<String> setB = new HashSet<>();
HashSet<String> setHab = new HashSet<>();
HashSet<String> setKyo = new HashSet<>();
HashSet<String> setCha = new HashSet<>();
setA.add("1"); setA.add("2");
setA.add("3"); setA.add("4");
setA.add("5");
System.out.println("A = "+setA);
// A = [1, 2, 3, 4, 5]
setB.add("4"); setB.add("5");
setB.add("6"); setB.add("7");
setB.add("8");
System.out.println("B = "+setB);
// B = [4, 5, 6, 7, 8]
Iterator<String> it = setB.iterator();
while(it.hasNext()) {
String tmp = it.next();
if(setA.contains(tmp))// setA에 tmp가 포함되어있는지를 확인한다.
setKyo.add(tmp);
}
it = setA.iterator();
while(it.hasNext()) {
String tmp = it.next();
if(!setB.contains(tmp))
setCha.add(tmp);
}
it = setA.iterator();
while(it.hasNext())
setHab.add(it.next());
it = setB.iterator();
while(it.hasNext())
setHab.add(it.next());
System.out.println("A ∩ B = "+setKyo); // 한글 ㄷ을 누르고 한자키
// A ∩ B = [4, 5]
System.out.println("A ∪ B = "+setHab); // 한글 ㄷ을 누르고 한자키
// A ∪ B = [1, 2, 3, 4, 5, 6, 7, 8]
System.out.println("A - B = "+setCha);
// A - B = [1, 2, 3]
}
}- TreeSet을 이용하여 로또 번호 만들기.
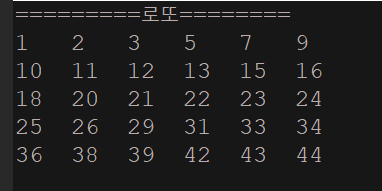
내가 푼 코드 - 로또 5줄을 출력하려했으나 실패 - 애초에 이걸의도한 문제가 아니였기에
package com.test.memo;
import java.util.Set;
import java.util.TreeSet;
public class Practice {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
while (set.size() < 30) {
int ran = (int) (Math.random() * 45) + 1;
set.add(ran);
}
System.out.println("=========로또========");
int cnt = 0;
for (int i : set) {
System.out.printf("%-4d", i);
cnt++;
if (cnt % 6 == 0) {
System.out.println();
}
}
}
}
-
6*5로 전체 출력하고싶었는데, 생각해보니 TreeSet을 정렬을한다.. 실패
-
내가 원하는데로 하고싶었으면 HashSet으로 했어야했다.
다시 푼 코드 - 문제대로 성공
package com.test.memo;
import java.util.Set;
import java.util.TreeSet;
public class Practice {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
while (set.size() < 6) {
int ran = (int) (Math.random() * 45) + 1;
set.add(ran);
}
for (int i : set) {
System.out.print(i + " ");
}
//System.out.println(set); 의 형식으로 바로 출력 가능
}
}
- HashMap에 각가 key와 Value를
"myId", "1234"
"asdf", "1111"
"asdf", "1234"
를 저장하고 id와 password를 입력받자.
그리고 id가 없으면 없다고 출력하고,
id가 있고 비밀번호가 일치하면 일치한다고 출력하고, 일치하지 않으면 일치하지 않는다고 출력하자.
내가 짠 코드
package com.test.memo;
import java.util.HashMap;
import java.util.Scanner;
public class Practice {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
String userId = null;
String userPass = null;
Scanner sc = new Scanner(System.in);
System.out.print("id를 입력하세요 :");
userId = sc.nextLine().trim();
System.out.print("password를 입력하세요 :");
userPass = sc.nextLine().trim();
if (map.containsKey(userId)) {
if (map.get(userId).equals(userPass)) {//get()메서드는 특정 키를 넘겨주고 해당 값을 가져오는 메소드다.
System.out.println("id와 password가 일치합니다.");
} else {
System.out.println("id가 일치하지만, password가 틀립니다.");
}
} else {
System.out.println("해당 id가 존재하지 않습니다.");
}
// for (int i = 0; i < map.size(); i++) {
// if (map.get(i).contains(userId) && map.get(i).contains(userPass)) {
// System.out.println("id와 password가 일치합니다.");
// } else if (map.get(i).contains(userId)) {
// System.out.println("id가 일치하지만, password가 틀립니다.");
// } else if (map.get(i).contains(userPass)) {
// System.out.println("password는 일치하지만, id가 틀립니다.");
// } else
// continue;
// }앞에가 키고 뒤가 Value인데 반대로 생각했다.
}
}- 주석 처리한 부분은 HashMap은 인덱스로 직접 접근할 수 없어
KeySet(),entrySet()메서드를 사용해 키나 값에 접근해야하는데, for문을이용해 인덱스처럼 접근하려했었다.
keySet() : 모든 키를 포함하는 Set을 반환한다. 이 Set을 통해 모든 키에 접근가능하고, 값은 Map에서 가져올 수 있다.
entrySet() : Map에 포함된 모든 키-값 쌍을 포함하는 Set을 반환한다.
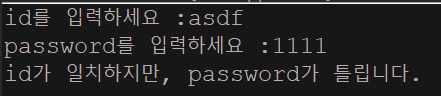
- 위처럼 출력된 이유는 Map특성상 키는 중복될 수 없기때문에 asdf의 value인 값이 1111에서 1234로 대체된다.
- HashMap에 각각 key와 value를
"김자바", 90
"김자바", 100
"이자바", 100
"강자바", 80
"안자바", 90
을 입력하고
각각의 이름과 점수를 출력하자.
그리고 총점, 평균, 최고점, 최저점을 출력하자.
내가 푼 풀이 틀림(평균이 이상)
package com.test.memo;
import java.net.Inet4Address;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Practice {
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>();
// map.add("김자바", 90);
// map.put("김자바", 100);
// map.put("이자바", 100);
// map.put("강자바", 80);
// map.put("안자바", 90); List를 값으로 사용하고있기때문에 따로 List에 추가해주고 맵에 추가해야한다.
// String name1 = "김자바";
// List<Integer> scores1 = new ArrayList<>();
// scores1.add(90);
// scores1.add(100);
// map.put(name1, scores1);
//
// // "이자바"의 점수들
// String name2 = "이자바";
// List<Integer> scores2 = new ArrayList<>();
// scores2.add(100);
// map.put(name2, scores2);
//
// // "강자바"의 점수들
// String name3 = "강자바";
// List<Integer> scores3 = new ArrayList<>();
// scores3.add(80);
// map.put(name3, scores3);
//
// // "안자바"의 점수들
// String name4 = "안자바";
// List<Integer> scores4 = new ArrayList<>();
// scores4.add(90);
// map.put(name4, scores4); 이 방법도다 아래 방법이 더 효율적이다.
addScore(map, "김자바", 90);
addScore(map, "김자바", 100);
addScore(map, "이자바", 100);
addScore(map, "강자바", 80);
addScore(map, "안자바", 90);
// 각 이름과 점수 출력
System.out.println("이름과 점수");
for (String name : map.keySet()) {
System.out.println(name + " : " + map.get(name));
}
int total = 0;
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (List<Integer> list : map.values()) {
for (int score : list) {
total += score;
if (score > max) {
max = score;
}
if (score < min) {
min = score;
}
}
}
double average = (double) total / map.size();
System.out.println("총점: " + total);
System.out.println("평균: " + average);
System.out.println("최고점: " + max);
System.out.println("최저점: " + min);
}
static void addScore(Map<String, List<Integer>> scores, String name, int score) {
if (!scores.containsKey(name)) {//scores에 name이라는 키가 있는지 확
scores.put(name, new ArrayList<>());
}
scores.get(name).add(score);
}
}값을 저장할때 인자로 map도 함께 넘겨주는데,처음 map을 선언했을때 상태 그대로 인자로 두고, 이 맵에서 이름과 점수들을 저장하라고 맵 객체를 보내주는 것이다. >> 여러 메서드에서 하나의 맵을 공유해 사용할 수 있다.
-
Map<String, List<Integer>>형태의 맵을 사용할 때 각 키에 대해 여러 개의 값을 가지려면, 각 값들을 리스트에 저장한 후에 그 리스트를 해당 키에 대응하는 값으로 맵에 넣어야한다.Map<String, List<Integer>>형태의 맵에 각 학생의 이름을 키로 하고 점수 리스트를 값으로 하는 방식을 사용
선생님 코드
package com.test.memo;
import java.util.Collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.Map.Entry;
public class Practice {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("김자바", Integer.valueOf(90));
map.put("김자바", Integer.valueOf(100));
map.put("이자바", Integer.valueOf(100));
map.put("강자바", Integer.valueOf(80));
map.put("안자바", Integer.valueOf(90));
// set에 map의 키와 쌍을 옮긴다.
Set<Entry<String, Integer>> set = map.entrySet();
Iterator<Entry<String, Integer>> it;
it = set.iterator();
// 이름과 점수 출력
while (it.hasNext()) {
Map.Entry<String, Integer> e = it.next();// key와 value를 꺼내오기위해 map에 넣어준다.
System.out.println("이름 : " + e.getKey() + ", 점수 : " + e.getValue());
}
// //이름과 점수 출력
// System.out.println(set + " ");
// [안자바=90, 김자바=100, 강자바=80, 이자바=100]
// 참가자 명단
Set<String> kset = map.keySet();
System.out.println("참가자 명단: " + kset);
Collection<Integer> val = map.values();// map의 값들을 컬렉션에 반환(맵에 저장된 값들에 대한 반복이나 집계를 수행할 때 유용
Iterator<Integer> itt = val.iterator();
int total = 0;
while (itt.hasNext()) {// 자동 박싱/언박싱
total += itt.next();
// Integer i = itt.next(); > 이렇게도 가능
// total += i.intValue();
}
System.out.println("총점 : " + total);
System.out.println("평균 : " + (float) total / set.size());
System.out.println("최고점수 : " + Collections.max(val));
System.out.println("최저점수 : " + Collections.min(val));
}
}
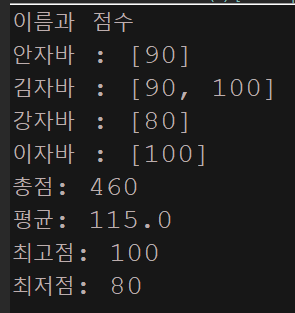
/*
이름 : 안자바, 점수 : 90
이름 : 김자바, 점수 : 100
이름 : 강자바, 점수 : 80
이름 : 이자바, 점수 : 100
참가자 명단 : [안자바, 김자바, 강자바, 이자바]
총점 : 370
평균 : 92.5
최고점수 : 100
최저점수 : 80
*/
/*
HaspMap의 기본적인 메서드를 이용해서 데이터를 저장하고 읽어오는 예제이다. entrySet()을
이용해서 키와 값을 함께 읽어 올 수도 있고 keySet()이나 values()를 이용해서 키와 값을 따로
읽어 올 수 있다.
*/- 다음 메인 메소드와 출력 결과를 보고 필요한 메소드를 완성하시오.
import java.util.*;
class HashMapEx3 {
static HashMap phoneBook = new HashMap();
public static void main(String[] args) {
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("회사", "이과장", "010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
} // main
}
실행 결과
- 기타[1]
세탁 010-888-8888- 친구[3]
이자바 010-111-1111
김자바 010-222-2222
김자바 010-333-3333 - 회사[4]
이과장 010-777-7777
김대리 010-444-4444
김대리 010-555-5555
박대리 010-666-6666
- 친구[3]
내가 푼 코드
package com.test.memo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Practice {
static HashMap<String, ArrayList<String>> phoneBook = new HashMap();
static void addPhoneNo(String category, String name, String phoneNum) {
// 해당 카테고리 키가 존재하지 않으면 새로운 ArrayList를 생성하여 추가
phoneBook.putIfAbsent(category, new ArrayList<>());
// 해당 카테고리 키에 대응하는 ArrayList에 전화번호 추가
phoneBook.get(category).add(name + " " + phoneNum);
}
static void addPhoneNo(String category, String PhoneNum) {// 오버로딩
phoneBook.putIfAbsent(category, new ArrayList<>());
phoneBook.get(category).add(PhoneNum);
}
static void printList() {
Iterator<Map.Entry<String, ArrayList<String>>> iterator = phoneBook.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, ArrayList<String>> entry = iterator.next();
String cate = entry.getKey();
ArrayList<String> phoneNum = entry.getValue();
Collections.sort(phoneNum, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.substring(o1.length() - 11).compareTo(o2.substring(o2.length() - 11));
}
});
System.out.println(" * " + cate + "[" + phoneNum.size() + "]");
for (String number : phoneNum)
System.out.println(number);
}
}
public static void main(String[] args) {
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("회사", "이과장", "010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
}
}
선생님 코드
import java.util.*;
import java.util.Map.Entry;
class HashMapEx3 {
static HashMap<String, HashMap<String, String>> phoneBook = new HashMap<>();
public static void main(String[] args) {
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("회사", "이과장", "010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
} // main
// 그룹을 추가하는 메서드 > phoneBook에 해당 그룹명이 없으면 새로 만든
static void addGroup(String groupName) {
if(!phoneBook.containsKey(groupName))//phonebook에 grouptName(친구,회사등)의 키가 있는지 확인 여부
phoneBook.put(groupName, new HashMap<String, String>());
}
// 그룹에 전화번호를 추가하는 메서드
static void addPhoneNo(String groupName, String name, String tel) {
addGroup(groupName);
HashMap<String, String> group = phoneBook.get(groupName);//만든 HashMap을 반환
group.put(tel, name); // 이름은 중복될 수 있으니 전화번호를 key로 저장한다.
} //group에서 전화번호를 key로 놓고 하위맵을 생성한것
static void addPhoneNo(String name, String tel) {
addPhoneNo("기타", name, tel);
}
// 전화번호부 전체를 출력하는 메서드
static void printList() {
Set<Entry<String, HashMap<String, String>>> set = phoneBook.entrySet();
Iterator<Entry<String, HashMap<String, String>>> it = set.iterator();
while(it.hasNext()) {
Map.Entry<String,HashMap<String,String>> e = it.next();
//Entry인터페이스를 통해 각 엔트리에 접근할 수 있다(키와 값 모두 접근가능)
Set<Entry<String, String>> subSet = e.getValue().entrySet();
Iterator<Entry<String, String>> subIt = subSet.iterator();
System.out.println(" * "+e.getKey()+"["+subSet.size()+"]");
while(subIt.hasNext()) {
Map.Entry<String, String> subE = subIt.next();
String telNo = subE.getKey();
String name = subE.getValue();
System.out.println(name + " " + telNo );
}
System.out.println();
}
} // printList()
} // class
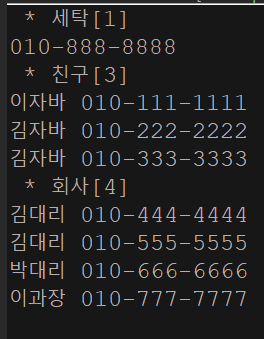
/*
* 기타[1]
세탁 010-888-8888
* 친구[3]
이자바 010-111-1111
김자바 010-222-2222
김자바 010-333-3333
* 회사[4]
이과장 010-777-7777
김대리 010-444-4444
김대리 010-555-5555
박대리 010-666-6666
*/
/*
HashMap은 데이터를 키와 값을 모두 Object타입으로 저장하기 때문에 HashMap의 값
(value)으로 HashMap을 다시 저장할 수 있다. 이렇게 함으로써 하나의 키에 다시 복수의
데이터를 저장할 수 있다.
먼저 전화번호를 저장할 그룹을 만들고 그룹 안에 다시 이름과 전화번호를 저장하도록
했다. 이때 이름대신 전화번호를 키로 사용했다는 것을 확인하자. 이름은 동명이인이 있
을 수 있지만 전화번호는 유일하기 때문이다.
[참고] 배열의 배열인 이차원 배열과 비교해보면 이해하기 쉬울 것이다.
*/-
Entry인터페이스의 엔트리 메서드
-
getKey(): 현재 엔트리의 키를 반환 -
getValue(): 현재 엔트리의 값을 반환 -
setValue(V value): 현재 엔트리의 값을 주어진 값으로 설정하고, 이전 값을 반환Entry인터페이스를 사용하면 맵의 키와 값에대한 접근 및 조작이 가능하다.
- 다음과 같이 실행 결과가 나오도록 하자.
실행결과
A : ### 3
D : ## 2
Z : # 1
K : ###### 6
내가 푼 코드
package com.test.memo;
import java.util.HashMap;
import java.util.Map;
public class Practice {
public static void main(String[] args) {
String[] data = { "A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D" };
HashMap<String, Integer> map = new HashMap();
// 각 문자의 등장 횟수를 세어 HashMap에 저장
for (String s : data) {
map.put(s, map.getOrDefault(s, 0) + 1);//대응하는 값이 없으면 0, 초기화하기 위해 0을 포함해 인자로 전
} //+1하는 이유는 1을 더해 카운트를 증가시키기 위해서다. > s가 키고, 카운트는 값으로 젖아
// 결과 출력
for (Map.Entry<String, Integer> ent : map.entrySet()) {
String key = ent.getKey();//위에서, key는 data알파벳이고,
int count = ent.getValue(); //카운트를 vlue로 넣었기 때문에 해당 메소드로 꺼내준다.
String bar = "#".repeat(count);//문자열을 인자값만큼 반복하게하는 메소드다. (문자열을 생성하는
System.out.println(key + " : " + bar + " " + count);
// 결과 출력
//for (Map.Entry<String, Integer> ent : map.entrySet()) {
// String key = ent.getKey();
// String bar = "#".repeat(ent.getValue());
// System.out.println(key + " : " + bar + " " + ent.getValue());
//} 이렇게도 사용 가능
}
}
}
- 데이터 배열인 data를 향상된 for문안에서 순회한다.
- map.getOrDefault(s, 0)를 통해 HashMap에서 키 s에 해당하는 값을 가져온다.> 카운팅이나 빈도수 계산등에서 사용 > 특정키에대해 이전에 발생한 횟수를 추적하고 싶을 때
- 만약 키 s가 존재하지 않으면 기본값으로 0을 반환합니다.
- 가져온 값에 1을 더하여 map.put() 메서드를 사용하여 HashMap에 다시 저장합니다. 여기서 s가 존재하지 않으면 새로운 키-값 쌍이 추가되고, 이미 존재하는 경우에는 기존 값에 1이 더해져 업데이트됩니다.
선생님 코드
import java.util.*;
import java.util.Map.Entry;
class Test8 {
public static void main(String[] args) {
String[] data = { "A","K","A","K","D","K","A","K","K","K","Z","D" };
HashMap<String, Integer> map = new HashMap<>();
for(int i=0; i < data.length; i++) {
if(map.containsKey(data[i])) {
Integer value = (Integer)map.get(data[i]);
map.put(data[i], Integer.valueOf( (value.intValue() + 1)) );
} else {
map.put(data[i], 1);
}
}
Iterator<Entry<String, Integer>> it = map.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value );
}
} // main
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i < bar.length; i++) {
bar[i] = ch;
}
return new String(bar); // String(char[] chArr)
}
}
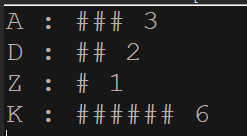
/*
A :
### 3
D : ## 2
Z : # 1
K : ###### 6
*/
/*
문자열 배열에 담긴 문자열을 하나씩 읽어서 HashMap에 키로 저장하고 값으로
1을 저장한다. HashMap에 같은 문자열이 키로 저장되어 있는지 containsKey()로
확인하여 이미 저장되어 있는 문자열이면 값을 1증가시킨다.
그리고 그 결과를 printBar()를 이용해서 그래프로 표현했다. 이렇게 하면 문자열
배열에 담긴 문자열들의 빈도수를 구할 수 있다.
한정된 범위 내에 있는 순차적인 값들의 빈도수는 배열을 이요하지만, 이처럼
한정되지 않은 범위의 비순차적인 값들의 빈도수는 HashMap을 이용해서 구할 수
있다.
[참고] 결과를 통해 HashMap과 같이 해싱을 구현한 컬렉션 클래스들은 저장순서를
유지하지 않는다는 사실을 다시 한 번 확인하자.
*/- 다음 실행결과를 보고 main메소드를 완성하시오. 필요하다면 추가적인 메소드랑 클래스도 만드시오.
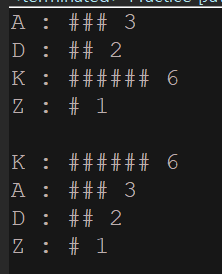
= 기본정렬 =
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
= 값의 크기가 큰 순서로 정렬 =
K : ###### 6
A : ### 3
D : ## 2
Z : # 1
내가 푼 풀이
package com.test.memo;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class Practice {
public static void main(String[] args) {
String[] data = { "A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D" };
HashMap<String, Integer> map = new HashMap<>();
// 각 문자의 등장 횟수를 세어 HashMap에 저장
for (String s : data) {
map.put(s, map.getOrDefault(s, 0) + 1);
}
// 값의 크기가 큰 순서대로 정렬 - HashMap은 정렬된 키의 컬렉션이 아니기 때문에 TreeMap으로 생성해 정렬해준다.
TreeMap<String, Integer> reverMap = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return map.get(o2).compareTo(map.get(o1));
}
});
reverMap.putAll(map);
// 기본 정렬 결과 출력
for (Map.Entry<String, Integer> ent : map.entrySet()) {
String key = ent.getKey();
String bar = "#".repeat(ent.getValue());
System.out.println(key + " : " + bar + " " + ent.getValue());
}
System.out.println();
// 크기가 순 순서대로 정렬
for (Map.Entry<String, Integer> ent : reverMap.entrySet()) {
String key = ent.getKey();
String bar = "#".repeat(ent.getValue());
System.out.println(key + " : " + bar + " " + ent.getValue());
}
}
}
-
처음부터 HashMap이 아닌 TreeMap으로 만들어서 했어도 되지 않았을까..
TreeMap은 키를 기준으로 기본정렬하기때문에, 위 코드는 키가 String 이기 때문에 기본정렬은 알파벳 순으로 이뤄지고있다.
-
다른 형식의 정렬을 하고싶다면 Comparator를 이용해 정렬하면 된다.
위 코드에서는 익명클래스로 정렬기준을 정해줬다.
선생님 코드
import java.util.*;
import java.util.Map.Entry;
class Test9 {
public static void main(String[] args) {
String[] data = { "A","K","A","K","D","K","A","K","K","K","Z","D" };
TreeMap<String, Integer> map = new TreeMap<>();
for(int i=0; i < data.length; i++) {
if(map.containsKey(data[i])) {
Integer value = (Integer)map.get(data[i]);
map.put(data[i], Integer.valueOf(value.intValue() + 1));
} else {
map.put(data[i], Integer.valueOf(1));
}
}
Iterator<Entry<String, Integer>> it = map.entrySet().iterator();
System.out.println("= 기본정렬 =");
while(it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value );
}
System.out.println();
// map을 ArrayList로 변환한 다음에 Collectons.sort()로 정렬
Set<Entry<String, Integer>> set = map.entrySet();
List<Entry<String, Integer>> list = new ArrayList<>(set); // ArrayList(Collection c)
// static void sort(List list, Comparator c)
Collections.sort(list, new ValueComparator());
it = list.iterator();
System.out.println("= 값의 크기가 큰 순서로 정렬 =");
while(it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value );
}
} // public static void main(String[] args)
static class ValueComparator implements Comparator<Entry<String, Integer>> {
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
Map.Entry<String, Integer> e1 = o1;
Map.Entry<String, Integer> e2 = o2;
int v1 = e1.getValue().intValue();
int v2 = e2.getValue().intValue();
return v2 - v1;
}
} // static class ValueComparator implements Comparator {
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i < bar.length; i++) {
bar[i] = ch;
}
return new String(bar);
}
}
/*
= 기본정렬 =
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
= 값의 크기가 큰 순서로 정렬 =
K : ###### 6
A : ### 3
D : ## 2
Z : # 1
*/