오전 문제
23, 24일차 문제들
- 접근제어자를 접근범위가 넓은 것에서 좁은 것의 순으로 나열하시오.
- public - protected - default - private
- final을 붙일 수 있는 대상과 붙였을 때 그 의미를 서술하시오.
-
변수 - 상수가 된다.(대문자)
-
메서드 - 오버라이딩 할 수 없다.
-
클래스 - 상속받을 수 없는 클래스가 된다.
- 다음 중 연산결과가 true가 아닌 것은? (모두 고르시오)
class Car {}
class FireEngine extends Car implements Movable {}
class Ambulance extends Car {}
FireEngine fe = new FireEngine();
a. fe instanceof FireEngine
b. fe instanceof Movable
c. fe instanceof Object
d. fe instanceof Car
e. fe instanceof Ambulance
- e
- 다음의 코드를 실행한 결과를 적으시오.
class Exercise7_20 {
public static void main(String[] args) {
Parent p = new Child();
Child c = new Child();
System.out.println("p.x = " + p.x);
p.method();
System.out.println("c.x = " + c.x);
c.method();
}
}
class Parent {
int x = 100;
void method() {
System.out.println("Parent Method");
}
}
class Child extends Parent {
int x = 200;
void method() {
System.out.println("Child Method");
}
}- 100 Child Method 200 Child Method
메서드의 경우 참조별수의 타입에 관계없이 항상 실제 인스턴스의 타입인 Child 클래스에 정의된 메서드가 호출되지만, 인스턴스 변수인 x는 참조변수의 타입에 따라 달라진다.
- 다음과 같이 attack메서드가 정의되어 있을 때, 이 메서드의 매개변수로 가능한
것 두 가지를 적으시오
interface Movable {
void move(int x, int y);
}
void attack(Movable f) {
/ 내용 생략 /
}
- Movable인터페이스를 구현한 클래스 , 그 자손의 인스턴스
- Outer클래스의 내부 클래스 Inner의 멤버변수 iv의 값을 출력하시오.
package com.test.memo;
class Outerclass {
class Innerclass {
int iv = 100;
}
}
public class Practice1 {
public static void main(String[] args) {
Outerclass outer = new Outerclass();
Outerclass.Innerclass inner = outer.new Innerclass();
System.out.println(inner.iv);
}
}6-1. Outer클래스의 static 내부 클래스 Inner의 멤버변수 iv의 값을 출력하시오.
package com.test.memo;
class Outerclass {
static class Innerclass {
int iv = 100;
}
}
public class Practice1 {
public static void main(String[] args) {
Innerclass inner = new Innerclass();
System.out.println(inner.iv);
}
}static inner class > 스태틱 클래스는 인스턴스 클래스와 달리 외부 클래스의 인스턴스를 생성하지 않고도 사용할 수 있다
마치 static멤버를 인스턴스 생성없이 사용할 수 있는것처럼
- 아래의 EventHandler를 익명 클래스(anonymous class)로 변경하시오.
import java.awt.;
import java.awt.event.;
class Exercise7_28
{
public static void main(String[] args)
{
Frame f = new Frame();
f.addWindowListener(new EventHandler());
}
}
class EventHandler extends WindowAdapter
{
public void windowClosing(WindowEvent e) {
e.getWindow().setVisible(false);
e.getWindow().dispose();
System.exit(0);
}
}
package com.test.memo;
import java.awt.Frame;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
public class Practice1 {
public static void main(String[] args) {
Frame f = new Frame();
f.addWindowListener(new WindowAdapter() {
public void windowClosing(WindowEvent e) {
e.getWindow().setVisible(false);
e.getWindow().dispose();
System.exit(0);
}
});
}
}- 익명 클래스를 생성해서 사용 후 괄호 잘 닫기!
- 다음 코드가 정상적으로 실행 될 수 있게 하시오.
class StaticImportEx1 {
public static void main(String[] args) {
// System.out.println(Math.random());
out.println(random());
// System.out.println("Math.PI :"+Math.PI);
out.println("Math.PI :" + PI);
}
}
package com.test.memo;
import static java.lang.Math.*;
import static java.lang.System.out;
public class Practice1 {
public static void main(String[] args) {
// System.out.println(Math.random());
out.println(random());
// System.out.println("Math.PI :"+Math.PI);
out.println("Math.PI :" + PI);
}
}- static으로 import해오면 저렇게 앞에 다 쓸 필요없이 사용 가능하다.
- 다음의 출력결과를 예상하여 쓰시오.
class DefaultMethodTest {
public static void main(String[] args) {
Child c = new Child();
c.method1();
c.method2();
MyInterface.staticMethod();
MyInterface2.staticMethod();
}
}
class Child extends Parent implements MyInterface, MyInterface2 {
public void method1() {
System.out.println("method1() in Child"); // 오버라이딩
}
}
class Parent {
public void method2() {
System.out.println("method2() in Parent");
}
}
interface MyInterface {
default void method1() {
System.out.println("method1() in MyInterface");
}
default void method2() {
System.out.println("method2() in MyInterface");
}
static void staticMethod() {
System.out.println("staticMethod() in MyInterface");
}
}
interface MyInterface2 {
default void method1() {
System.out.println("method1() in MyInterface2");
}
static void staticMethod() {
System.out.println("staticMethod() in MyInterface2");
}
}-
method1() in Child \n method2() in Parent
-
staticMethod() in MyInterface \n staticMethod() in MyInterface2
- 다음 소스코드의 catch 블록을 하나로 합치면?
import java.util.Scanner;
import java.util.InputMismatchException;
class ExceptionCase5 {
public static void main(String[] args) {
Scanner kb = new Scanner(System.in);
try {
System.out.print("a/b... a? ");
int n1 = kb.nextInt();
System.out.print("a/b... b? ");
int n2 = kb.nextInt();
System.out.printf("%d / %d = %d \n", n1, n2, n1/n2);
}
catch(ArithmeticException e) {
e.getMessage();
}
catch(InputMismatchException e) {
// 클래스 Scanner를 통한 값의 입력에서의 오류 상황을 의미하는 예외 클래스
e.getMessage();
}
System.out.println("Good bye~~!");
}
}
package com.test.memo;
import java.util.Scanner;
import java.util.InputMismatchException;
class Practice2 {
public static void main(String[] args) {
Scanner kb = new Scanner(System.in);
try {
System.out.print("a/b... a? ");
int n1 = kb.nextInt();
System.out.print("a/b... b? ");
int n2 = kb.nextInt();
System.out.printf("%d / %d = %d \n", n1, n2, n1 / n2);
} catch (ArithmeticException| InputMismatchException e ) {
e.getMessage();
}
System.out.println("Good bye~~!");
} // main
}- 다중 catch문 이용해서 하나로 합쳐준다.
예외처리 실행 결과 예측 문제
- 코드의 실행결과를 적으시오.
class Exercise8_5 {
static void method(boolean b) {
try {
System.out.println(1);
if(b) throw new ArithmeticException();
System.out.println(2);
} catch(RuntimeException r) {
System.out.println(3);
return;
} catch(Exception e) {
System.out.println(4);
return;
} finally {
System.out.println(5);
}
System.out.println(6);
}
public static void main(String[] args) {
method(true);
method(false);
} // main
}- true : 1 3 5 2 6 false : 1 2 5 6
- 실행결과를 적으시오
class Exercise8_6 {
public static void main(String[] args) {
try {
method1();
} catch(Exception e) {
System.out.println(5);
}
}
static void method1() {
try {
method2();
System.out.println(1);
} catch(ArithmeticException e) {
System.out.println(2);
} finally {
System.out.println(3);
}
System.out.println(4);
} // method1()
static void method2() {
throw new NullPointerException();
}
}- 1 3 5 4
- 실행결과를 적으시오.
class Exercise8_7 {
static void method(boolean b) {
try {
System.out.println(1);
if(b) System.exit(0);
System.out.println(2);
} catch(RuntimeException r) {
System.out.println(3);
return;
} catch(Exception e) {
System.out.println(4);
return;
} finally {
System.out.println(5);
}
System.out.println(6);
}
public static void main(String[] args) {
method(true);
method(false);
} // main
}- true : 1 > 프로그램 종료로 이후 실행 안됌
- 실행결과를 적으시오.
class Exercise8_10 {
public static void main(String[] args) {
try {
method1();
System.out.println(6);
} catch(Exception e) {
System.out.println(7);
}
}
static void method1() throws Exception {
try {
method2();
System.out.println(1);
} catch(NullPointerException e) {
System.out.println(2);
throw e;
} catch(Exception e) {
System.out.println(3);
} finally {
System.out.println(4);
}
System.out.println(5);
} // method1()
static void method2() {
throw new NullPointerException();
}
}- 2 4 7
예외클래스로 코드 짜기 복습
- 1~100사이 숫자를 맞추는 게임을 만드는데,
1~100사이의 숫자를 맞추는 게임을 실행할 때 숫자가 아닌 영문자를
넣어서 발생한 예외처리를 해서 숫자가 아닌 값을 입력했을 때는 다시 입력을
받도록 하라.
package com.test.memo;
import java.util.InputMismatchException;
import java.util.Scanner;
class Practice2 {
public static void main(String[] args) {
int userNum = 0;
int comNum = (int) (Math.random() * 100 + 1);
Scanner sc = new Scanner(System.in);
do {
System.out.print("숫자를 입력하세요 : ");
try {
userNum = sc.nextInt();
// sc.nextLine();여기다가 엔터값을 빼주려하면 안빠짐..
if (userNum >= 1 && userNum <= 100) {
if (userNum > comNum) {
System.out.println("입력하신 숫자보다 작습니다.");
} else if (userNum < comNum) {
System.out.println("입력하신 숫자보다 큽니다.");
} else {
System.out.println("정답입니다.");
break;
}
} else {
System.out.println("1부터 100사이의 숫자를 입력해주세요.");
sc.nextLine();
}
} catch (InputMismatchException e) {
System.out.println("올바르지 않은 값입니다. 다시 입력해주세요");
sc.nextLine();
}
} while (true);
sc.close();
}
}
-
예외를 발생시키면 갑자기 무한루프로 다시 입력하라는 출력이 계속 돌아서 시간을 좀 소비했다.
- 그 이유는 nextInt();로 값을 받고 버퍼에 남은 문자 a를 빼주지 않아서 반복된 예외가 발생하는 것이였다.
- 그러니 nextLine();이나 next(); 를 이용해서 해당 문자를 버퍼에서 제거해줘야한다.
- 그 이유는 nextInt();로 값을 받고 버퍼에 남은 문자 a를 빼주지 않아서 반복된 예외가 발생하는 것이였다.
- 다음과 같은 조건의 예외클래스를 작성하고 테스트하시오.
[참고] 생성자는 실행결과를 보고 알맞게 작성해야한다.
- 클래스명 : UnsupportedFuctionException
- 조상클래스명 : RuntimeException
- 멤버변수 :
이 름 : ERR_CODE
저장값 : 에러코드
타 입 : int
기본값 : 100
제어자 : final private - 메서드 :
- 메서드명 : getErrorCode
기 능 : 에러코드(ERR_CODE)를 반환한다.
반환타입 : int
매개변수 : 없음
제어자 : public - 메서드명 : getMessage
기 능 : 메세지의 내용을 반환한다.(Exception클래스의 getMessage()를 오버라이딩)
반환타입 : String
매개변수 : 없음
제어자 : public
[실행결과]
Exception in thread "main" UnsupportedFuctionException: [100]지원하지 않는 기능
입니다.
at Exercise8_9.main(Exercise8_9.java:5)
package com.test.memo;
class UnsupportedFuctionException extends RuntimeException {
final private int ERR_CODE;
UnsupportedFuctionException(String message, int eRR_CODE) {
super(message);
ERR_CODE = eRR_CODE;
}
UnsupportedFuctionException(String message) {
this(message, 100);
}
public int getErrorCode() {
return ERR_CODE;
}
@Override
public String getMessage() {
return "[" + getErrorCode() + "]" + super.getMessage();
}
}
class Practice2 {
public static void main(String[] args) {
try {
throw new UnsupportedFuctionException("지원하지 않는 기능입니다.", 100);
} catch (UnsupportedFuctionException e) {
e.printStackTrace();
}
}
}
- main 메서드에서 catch로 잡아서 메시지를 보내야하는데, 메시지를 출력하는 코드를 안써놔서 계속 실행은 되는데 아무것도 나오지 않는 현상이 일어났다..
equals 메서드 이용한 문제
폴더에 있는 소스를 가지고 Rectangle 클래스에 내용비교를 위한 메소드를 삽입하자. 그리고 이를 테스트하기 위한 예제를 작성하자.
package com.test.memo;
class Point {
int xPos, yPos;
public Point(int x, int y) {
xPos = x;
yPos = y;
}
public void showPosition() {
System.out.printf("[%d, %d]", xPos, yPos);
}
@Override
public boolean equals(Object obj) {
Point ex = (Point) obj;
return this.xPos == ex.xPos && this.yPos == ex.yPos;
}
}
class Rectangle {
Point upperLeft, lowerRight;
public Rectangle(int x1, int y1, int x2, int y2) {
upperLeft = new Point(x1, y1);
lowerRight = new Point(x2, y2);
}
public void showPosition() {
System.out.println("직사각형 위치정보...");
System.out.print("좌 상단 : ");
upperLeft.showPosition();
System.out.println("");
System.out.print("우 하단 : ");
lowerRight.showPosition();
System.out.println("\n");
}
@Override
public boolean equals(Object obj) {
Rectangle rec = (Rectangle) obj;
return this.upperLeft.equals(rec.upperLeft) && this.lowerRight.equals(rec.lowerRight);
}
}
class Practice2 {
public static void main(String[] args) {
Rectangle rec1 = new Rectangle(10, 20, 30, 40);
Rectangle rec2 = new Rectangle(10, 20, 10, 20);
Rectangle rec3 = new Rectangle(10, 20, 10, 20);
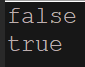
System.out.println(rec1.equals(rec2));
System.out.println(rec2.equals(rec3));
}
}
문자열 객체
-
String 을 new를 이용해 객체를 생성하는 것 보다 쌍따옴표를 이용해서 객체를 생성하는게 메모리 효율성이 더 좋다.
-
문자열 객체를 변경이 불가능하고 쌍따옴표로 객체를 생성했는데, 해당 내용이 같다면, 객체를 더 생성하는 것이 아니라 해당 객체를 참조하는 형태로 만들어진다.
-
문자열 객체는 change를 해도 변경되는게 아니라 객체를 새로 생성하는것이다.
깊은 복사 문제 - 문자열 객체
package com.test.memo;
class Business implements Cloneable {//clone()을 사용하려면 반드시 Cloneable을 구현해야함
private String company;
private String work;
public Business(String company, String work) {
this.company = company;
this.work = work;
}
public void showBusinessInfo() {
System.out.println("회사 : " + company);
System.out.println("업무 : " + work);
}
public void changeWork(String work) {
this.work = work;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
// Business cloned = (Business) super.clone();
// cloned.work = this.work;
// cloned.company = this.company;
// return cloned;
}
}
class PersonalInfo implements Cloneable {
private String name;
private int age;
private Business bness;
public PersonalInfo(String name, int age, String company, String work) {
this.name = name;
this.age = age;
bness = new Business(company, work);
}
public void showPersonalInfo() {
System.out.println("이름 : " + name);
System.out.println("나이 : " + age);
bness.showBusinessInfo();
System.out.println("");
}
public void changeWork(String work) {
bness.changeWork(work);
}
@Override
protected Object clone() throws CloneNotSupportedException {
PersonalInfo cloned = (PersonalInfo) super.clone();
cloned.bness = (Business) bness.clone();
return cloned;
}
}
class Practice2 {
public static void main(String[] args) {
PersonalInfo pInfo = new PersonalInfo("James", 22, "HiMedia", "encoding");
try {
PersonalInfo pCopy = (PersonalInfo) pInfo.clone();
pCopy.changeWork("decoding");
pInfo.showPersonalInfo();
pCopy.showPersonalInfo();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}-
회사와 업무는 Buisness 클래스에서 처리하고 있기 때문에 해당 clone()에서 변경해야되는 줄 알았는데, 실질적으로 personalInfo 클래스에서 값을 받고 넘겨주기 때문에 이 클래스의 clone()에서 변경시켜야하는 것이였다.
-
그런데 변경시킬때 cloned는 PersonalInfo인데 왜 bness.clone()에서는Business로 형변환 시켜서 넘겨주는지 모르겠다.
- 알았다. 저거 cloned.bness니까 bness가 Buisness니까 형변환 시켜주는것이였당..하하
-
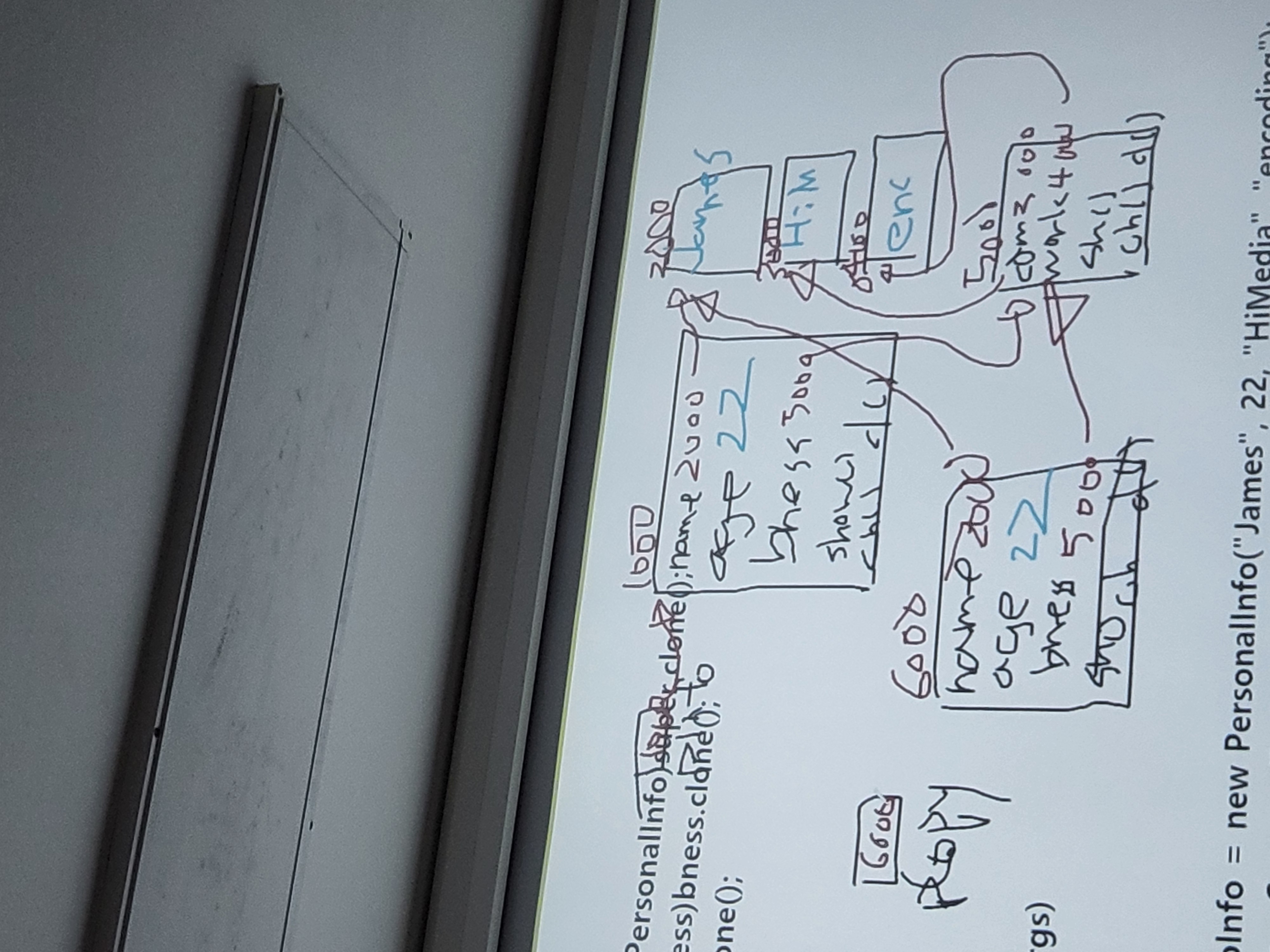
위 코드 메모리 구조
-
변경되기 전 메모리 구조
-
문자열은 clone()사용시 자동으로 깊은 복사를 수행한다.
-
그래서 위 메모리구조는 얕은 복사고 6000번지가 5000번지와 똑같은 새로운 객체를 생성해서 참조하고 있는것이다. 새로운 객체가 7000번지라고 치면 6000번지인 copy는 7000번지를 참조하고 있는것이다.
-
-
문자열을 변경시키면 해당 객체가 변경되는 것이 아니라, 새로운 문자열 객체를 가지고 해당 객체를 참조하는 것이다.
- 문자열 객체는 변경이 안되니까!
Wrapper Class
'Wrapper 클래스'라는 이름에는 '감싸는 클래스'라는 의미가 담겨있다.
기본 자료형의 데이터를 감싸는 Wrapper 클래스
-
기본 자료타입(primitive type)을 객체로 다루기 위해서 사용하는 클래스들을 wrapper class(래퍼 클래스)라고 한다.
-
자바는 모든 기본타입(primitive type)은 값을 갖는 객체를 생성할 수 있다. > 포장 객체라고도 한다.
-
wrapper 클래스로 감싸고 있는 기본 타입 값은 외부에서 변경할 수 없다.
-
만약 값을 변경하고 싶다면 새로운 포장 객체를 만들어야 한다.
-
Wrapper Class의 종류
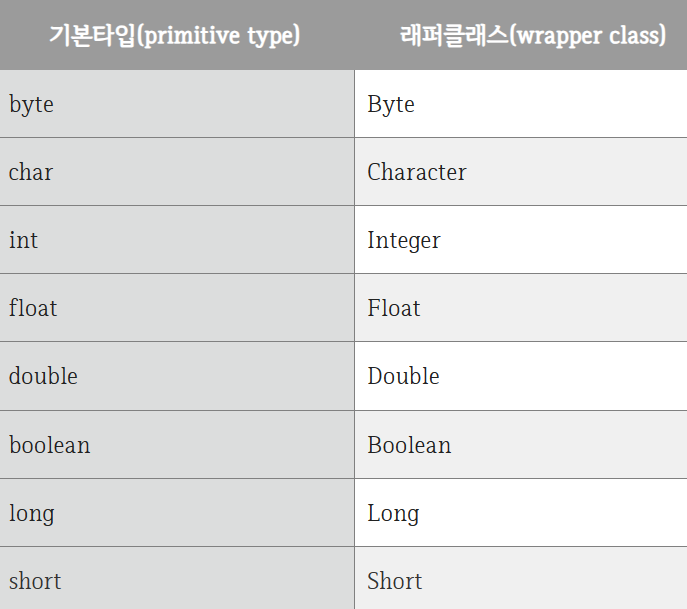
기본 타입의 첫 글자를 대문자로 바꾼 이름
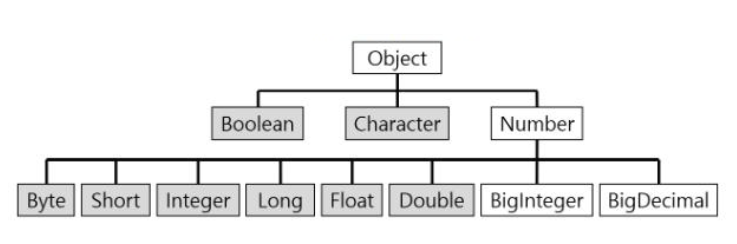
Wrapper class의 구조도
-
Object : 모든 래퍼클래스의 부모
-
Number class : 내부적으로 숫자를 다루는 Wrapper class의 부모 클래스
내가 아는 기본형타입을 객체로 만드는 래퍼 클래스는 Number클래스를 상속한다.
-
따라서 이를 상속하는 Integer, Double과 같은 클래스들은 위의 메소드 모두를 구현하고 있다. 때문에 어떠한 래퍼 인스턴스를 대상으로도 인스턴스에 저장된 값을 다양한 형태로 반환할 수 있다.
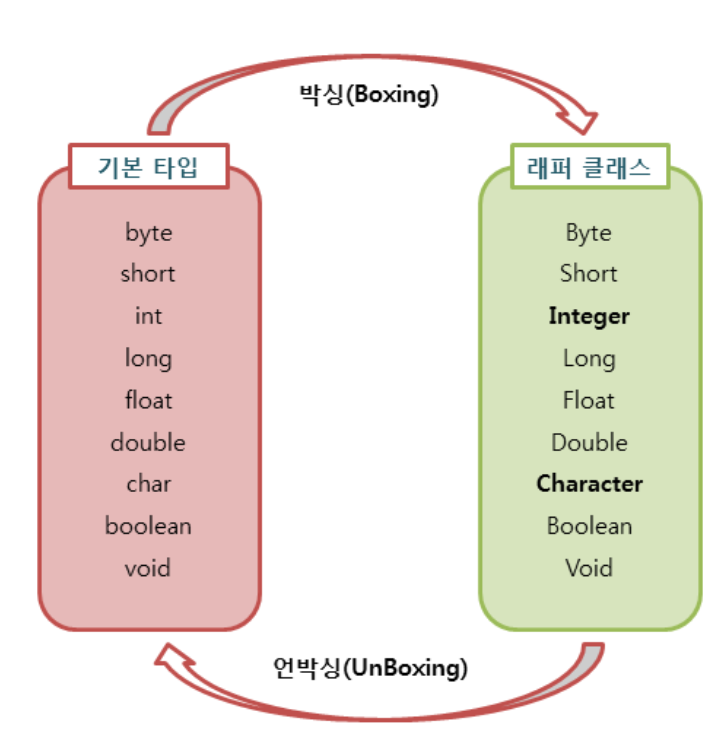
Boxing / UnBoxing
-
Boxing : 기본 타입의 값을 포장 객체로 만드는 과정
-
wrapper class의 생성자 파라미터값으로 기본타입의 값 또는
문자열을 넘겨주면 된다.Integer wrapper = new Integer(10);
-
-
Un-Boxing : 포장 객체에서 기본 타입의 값을 얻어내는 과정
-
각 wrapper class마다 가지고 있는 "기본타입명 + Value()" 메소드를 호출하면 된다.
int num = wrapper.intValue();
Boolean - booleanValue();
Character - charValue();
Integer - intValue();
Long - longValue();
*Double - doubleValue(); -
예제
public class Wrapper_Ex {
public static void main(String[] args) {
Integer num = new Integer(17); // 박싱
int n = num.intValue(); //언박싱
System.out.println(n);
}
}class BoxingUnboxing
{
public static void main(String[] args)
{
Integer iValue=new Integer(10); // Boxing
Double dValue=new Double(3.14); // Boxing
System.out.println(iValue);
System.out.println(dValue);
iValue=new Integer(iValue.intValue()+10); //UnBoxing
dValue=new Double(dValue.doubleValue()+1.2); //UnBoxing
System.out.println(iValue);
System.out.println(dValue);
}
}Auto Boxing / Auto Unboxing
기본 자료형과 Wrapper 클래스 간에는 서로 암묵적 형변환이 가능하다.
-
기본 타입 값을 직접 Boxing, UnBoxint 하지 않아도 자동적으로 일어나는 경우가 있다.
- AutoBoxing은 Wrapper 클래스 타입에 기본값이 대입될 경우,
AutoUnBoxing은 기본 타입에 wrapper class의 객체가 대입될 경우 발생한다.
public class Wrapper_Ex { public static void main(String[] args) { Integer num = 17; // 자동 박싱 int n = num; //자동 언박싱 System.out.println(n); - AutoBoxing은 Wrapper 클래스 타입에 기본값이 대입될 경우,
class BoxingUnboxing
{
public static void main(String[] args)
{
Integer iValue=Integer.valueOf(10); // deprecated API.
Double dValue=Double.valueOf(3.14); // deprecated API.
System.out.println(iValue);
System.out.println(dValue);
iValue=iValue.intValue()+10; //UnBoxing을 하고, 내부적으로 AutoBoxing 해서 int객체를 만들고, Integer.valueOf(20)을 만들어 이 객체의 주소갑을 iValue에 넣는 것이다.
dValue=dValue.doubleValue()+1.2; //Double.valueOf(4.34)를가지고 AuotoBoxing을 해서 double객체를 만들어 해당 주소값을 dValue에 넣는 것이다.
System.out.println(iValue);
System.out.println(dValue);
}
}iValue - 참조변수인데, 해당 참조 값을 꺼내서 +10해주는 원리이다.
Wrapper 클래스의 static데이터
- 모든 Wrapper 클래스는 static 데이터 형태로 Wrapper 클래스에 대응되는
자료형에 대한 최소 값과 최대 값을 가지고 있다.
int max = Integer.MAX_VALUE;
int min = Integer.MIN_VALUE;Wrapper 클래스 값 비교
-
Wrapper 클래스의 객체는 내부의 값을 비교하는 것이 아니라 객체의
참조를 비교하기 때문에 ==와 != 연산자를 사용할 수 없다. -
그러므로 직접 내부 값을 언박싱해서 비교하거나, equals() 메서드로
내부 값을 비교해야 한다. -
Wrapper 클래스들은 모두 equals()가 오버라이딩되어 있어서 주소값이 아닌 객체가
가지고 있는 값을 비교할 수 있다.
✍ 코드 예시
public class Main {
public static void main(String[] args) {
Integer a = new Integer(200);
Integer b = new Integer(200);
System.out.println("equals() 결과 : " + a.equals(b));
}
}👉 실행 결과
equals() 결과 : true이렇게 equals()를 이용한 두 Integer객체의 비교결과가 ture라는 것을 알 수 있다.
WRapper클래스 예제 및 설명
예제1
class AutoBoxingUnboxing
{
public static void main(String[] args)
{
Integer iValue=10;
// Interger형 참조 변수에는 Integer형 인스턴스의 참조 값이 저장되어야 한다.
// 그런데 이 문장에서는 정수 10을 저장하려 하고 있다. 이러한 경우에는
// 정수 10을 바탕으로 Integer형 인스턴스가 자동으로 생성되고,
// 이 인스턴스의 참조 값이 대신 저장된다. 그리고 이러한 현상을 가리켜
// Auto Boxing이라 한다.
Double dValue=3.14; // Auto Boxing
System.out.println(iValue); //10출력
System.out.println(dValue); //3.14출
int num1=iValue; // num1에 저장될 값으로 int형 데이터가 등장해야 하는데, Integer형 참조변수 iValue
// 가 등장하였다. 이 경우에는 iValue.intValue()가 자동으로 호출되어, 그 반환 값이 변수
// num1에 저장된다. 그리고 이러한 현상을 가리켜 Auto Unboxing이라 한다.
double num2=dValue; // Auto Unboxing
System.out.println(num1);
System.out.println(num2);
}
}Integer형 참조변수가 와야 할 위치에 int형 데이터가 오면 Auto Boxing이 진행
int형 데이터가 와야 할 위치에 Integer형 참조변수가 오면 Auto Unboxing이 진행
예제2
class AutoBoxingUnboxing2
{
public static void main(String[] args)
{
Integer num1=10;
Integer num2=20;
num1++; // Unboxing과 Boxing이 동시에 진행된다.
// num1 = Integer.valueOf(num1.intValue() + 1);
System.out.println(num1);
num2+=3; // num2 = Integer.valueOf(num2.intValue() + 3);
System.out.println(num2);
int addResult=num1+num2;
System.out.println(addResult);
int minResult=num1-num2;
System.out.println(minResult);
}
}Wrapper 클래스는 산술연산을 위해 정의된 클래스가 아니다.
- Wrapper클래스가 Auto Boxing 과 Auto Unboxing으로 인해서 산술연산이 가능해졌을 뿐이다.
예제 3
class NumberMethod {
public static void main(String[] args) {
Integer num1 = new Integer(29);
System.out.println(num1.intValue()); // int 형 값으로 반환
System.out.println(num1.doubleValue()); // double형 값으로 반환
Double num2 = new Double(3.14);
System.out.println(num2.intValue()); // int형 값으로 반환
System.out.println(num2.doubleValue()); // double형 값으로 반환
}
}//실행결과 29 29.0 3 3.14- 출력 결과를 보면 Double형 인스턴스에 저장된 값을 int형으로 반환할 경우 소수점 이하의 값이 삭제 되는것을 알 수 있다.
- 래퍼 클래스에는 static으로 선언된 다양한 메소드들이 있다.(아래와 같이)
예제 4 - static으로 선언된 메소드
class WrapperClassMethod {
public static void main(String[] args) {
// 클래스 메소드를 토한 인스턴스 생성 방법 두 가지
Integer n1 = Integer.valueOf(5); // 숫자 기반 Integer 인스턴스 생성
Integer n2 = Integer.valueOf("1024"); // 문자열 기반 Integer 인스턴스 생성
// 대소 비교와 합을 계산하는 클래스 메소드
System.out.println("큰 수: " + Integer.max(n1, n2));
System.out.println("작은 수: " + Integer.min(n1, n2));
System.out.println("합: " + Integer.sum(n1, n2));
System.out.println();
// 정수에 대한 2진, 8진, 16진수 표현 결과를 반환하는 클래스 메소드
System.out.println("12의 2진 표현: " + Integer.toBinaryString(12));
System.out.println("12의 8진 표현: " + Integer.toOctalString(12));
System.out.println("12의 16진 표현: " + Integer.toHexString(12));
}
}실행 결과
큰 수 :1024
작은 수 : 5
합: 1029
12의 2진 표현: 1100
12의 8진 표현: 14
12의 16진 표현: c
-
인자 값을 가지고 비교하거나 더해서 결과를 출력한다.
-
max- 인자값을 비교해 더 큰값을 출력한다. -
min- 인자값을 비교해 더 작은 값을 출력한다. -
sum- 인자값을 더해서 더한 값을 출력한다.
-
예제 5
class Test {
public static void main(String[] args) {
Double n1 = Double.valueOf(5.5);
Double n2 = Double.valueOf("7.7");
System.out.println("큰 수 : " + Double.max(n1, n2));
System.out.println("작은 수 : " + Double.min(n1, n2));
System.out.println("합 : " + Double.sum(n1, n2));
}
}실행 결과
큰 수 : 7.7
작은 수 : 5.5
합 : 13.2
예제 6
class Test {
public static void main(String[] args) {
Double n1 = Double.valueOf(5.5);
Double n2 = Double.valueOf("7.7");
System.out.println("큰 수 : " + Double.max(n1, n2));
System.out.println("작은 수 : " + Double.min(n1, n2));
System.out.println("합 : " + Double.sum(n1, n2));
}
}실행 결과
큰 수 : 7.7
작은 수 : 5.5
합 : 13.2
- 참고로 Integer와 Double에 정의된 max, min, sum 메소드는 기본 자료형의 값을 인자로 받는다. 즉 위의 예제에서는 이 메소드의 호출 과정에서 오토 언박싱이 발생하게 된다.
문자열 관련 함수 (암기!!)
문자열 데이터의 형변환
-
wrapper 클래스의 가장 중요한 기능은 기본 자료형의 모양을 띄고 있는
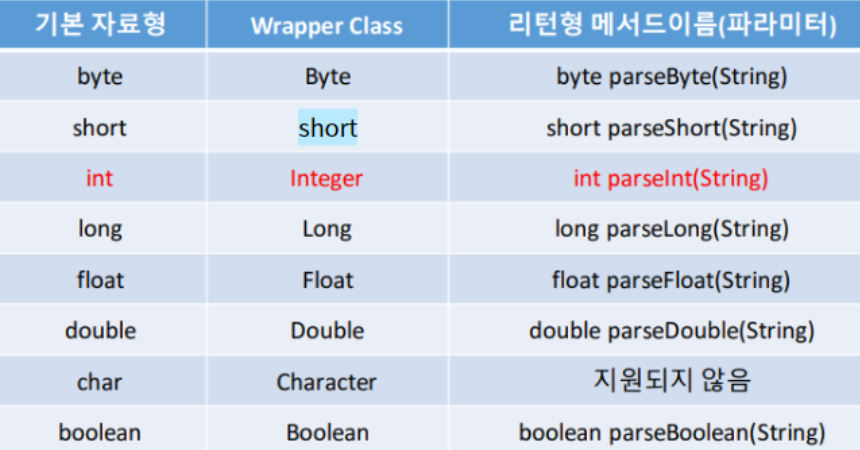
문자열 데이터를 실제 기본 자료형으로 변환시키는 기능이다. -
대부분의 wrapper 클래스에는 'parse + 기본타입' 메소드를 이용해
문자열을 파라미터로 받아 기본 타입 값으로 변환한다.- 이때 각 자료형에 알맞은 문자열을 사용해야 한다.
- 변화된 값은 사칙연산이 가능하고, 기본 데이터 형과 객체화 된 데이터도 서로 연산이 가능하다.
int v1 = num_a + 500;
float v2 = num_b + 500;
System.out.println("v1 = " + v1);
System.out.println("v2 = " + v2);
System.out.println("-------------------------------------");
// 기본 데이터 형의 객체화
Integer i = new Integer(500);
int j = i + 300;
System.out.println("j = " + j);👉 실행 결과
v1 = 520
v2 = 503.14
-------------------------------------
j = 800-
Integer.toBinaryString()- 정수를 2진수로 변환 -
Integer.toOctalString()- 정수를 8진수로 변환 -
Integer.toHexString()- 정수를 16진수로 변환
암기하고 있어야 할 메서드
-
.substring(a)- a의 인덱스 부터 끝까지 문자열 자르기.substring(a, b)- a의 인덱스부터 b-1인덱스 까지(배열이니까) 자르기
-
.replace("a", " ")- 대상 문자열에 a가 있는 부분은 공백으로 변환 -
.indexOf("AB")- 대상 문자열에서 "AB"문자열을 검색하여 제일 처음에 나오는 문자열의 시작 인덱스를 반환-
. indexOf("AB", 2)- 대상 문자열에서 "AB"문자열을 2번째부터 검색하여 처음 나오는 "AB" 문자열의 시작위치를 반환 -
.lastIndexOf()- indexOf()와 같지만 오른쪽에서 왼쪽으로 검색한다.
-
-
.contains("a")- 대상 문자열에 특정 문자열이 포함되어 있는지 확인하는 함수.- 대/소문자 구분
-
toCharArray()- 문자열을 character배열로 변경시켜주는 함수return new String((char 배열의 참조 변수 이름))- 배열이 문자열로 생성되어 반환되는 형식으로 사용할 수 있다.
-
Math.round()- 반올림 -
Math.pow(a, b)- a의 b제곱 -
Math.abs(a)- a의 절대값 -
Math.min(a,b)- a 와 b를 비교해서 더 적은 값 출력Math.max(a,b)- a와 b를 비교해서 더 큰 값 출력
문자열 관련 함수 응용 문제
- 전화번호를 검색하는 프로그램을 작성해보자.
String[] phoneNumArr = {
"012-3456-7890",
"099-2456-7980",
"088-2346-9870",
"013-3456-7890"
};
234를 입력하면
[012-3456-7890, 088-2346-9870] 출력
내가 한 풀이
package com.test.memo;
import java.util.Scanner;
class Practice2 {
public static void main(String[] args) {
String finNum = null;
String[] phoneNumArr = { "012-3456-7890", "099-2456-7980", "088-2346-9870", "013-3456-7890" };
Scanner sc = new Scanner(System.in);
System.out.print("찾으실 번호를 입력하세요: ");
finNum = sc.next();
boolean found = false;
for (String phoneNumber : phoneNumArr) {
if (phoneNumber.contains(finNum)) {
System.out.println(phoneNumber);
found = true;
}
}
if (!found) {
System.out.println("해당하는 전화번호가 없습니다.");
}
}
}- for문 떄문에 출력이 계속 4번씩되서 오래걸렸다..왜 이걸..ㅠ
선생님 풀이
import java.util.Scanner;
import java.util.Vector;
public class SearchTest {
public static void main(String[] args) {
String[] phoneNumArr = {
"012-3456-7890",
"099-2456-7980",
"088-2346-9870",
"013-3456-7890"
};
// Vector<String> vec = new Vector<String>(); // 검색결과를 담을 Vector
Vector vec = new Vector();
Scanner s = new Scanner(System.in);
while(true) {
System.out.print(">>");
String input = s.nextLine().trim(); // trim()으로 입력내용에서 공백을 제거
if(input.equals("")) {
continue;
} else if(input.equalsIgnoreCase("Q")) {
System.exit(0);
}
for(int i=0;i<phoneNumArr.length;i++) {
String phoneNum = phoneNumArr[i];
String tmp = phoneNum.replace("-",""); // phoneNum에서 '-'를 제거
if(tmp.contains(input)) { // 찾는 문자열이 있으면
vec.add(phoneNum);
}
}
if(vec.size()>0) { // 검색결과가 있으면
System.out.println(vec); // 검색결과를 출력하고
vec.clear(); // 검색결과를 삭제
} else {
System.out.println("일치하는 번호가 없습니다.");
}
}
}
}-
두 개의 배열을 이용하여
다음과 같이 출력 결과가 나오도록 하자.char[] dest = new char[10];
char[] src = {'1', '2', '3', '4'};왼쪽 정렬
1234000000
오른쪽 정렬
0000001234
가운데 정렬0001234000
내가 푼 풀이
package com.test.memo;
public class Practice1 {
public static void main(String[] args) {
char[] dest = new char[10];
char[] src = { '1', '2', '3', '4' };
// 왼쪽 정렬
System.arraycopy(src, 0, dest, 0, src.length);
for (int i = src.length; i < dest.length; i++) {
dest[i] = '0';
}
System.out.println(new String(dest));
// 오른쪽 정렬
System.arraycopy(src, 0, dest, dest.length - src.length, src.length);
for (int i = 0; i < dest.length - src.length; i++) {
dest[i] = '0';
}
System.out.println(new String(dest));
// 가운데 정렬
int startPos = (dest.length - src.length) / 2;
System.arraycopy(src, 0, dest, startPos, src.length);
for (int i = 0; i < startPos; i++) {
dest[i] = '0';
}
for (int i = startPos + src.length; i < dest.length; i++) {
dest[i] = '0';
}
System.out.println(new String(dest));
}
}선생님 풀이
import java.util.Arrays;
public class SortTest {
public static void main(String[] args) {
char[] dest = new char[10];
char[] src = {'1', '2', '3', '4'};
// for(int i=0;i<dest.length;i++) // 배열 전체를 '0'으로 초기화
// dest[i] = '0';
Arrays.fill(dest, '0'); // Arrays.fill을 사용하여 대상 배열을 '0'으로 채워 초기
System.out.println("왼쪽 정렬");
System.arraycopy(src, 0, dest, 0, src.length);
System.out.println(dest);
Arrays.fill(dest, '0');
System.out.println("오른쪽 정렬");
System.arraycopy(src, 0, dest, dest.length - src.length, src.length);
System.out.println(dest); //문자 배열은 해당 주소값만 주면 차례로 출력
Arrays.fill(dest, '0');
System.out.println("가운데 정렬");
System.arraycopy(src, 0, dest, (dest.length - src.length)/2, src.length);
System.out.println(dest);
}
}-
그냥 처음부터 0으로 채우고 해당 위치에 복사하는게 훨씬 나은 것이였다,,
- 나는 왜 printf로 채우려고 한거지 허허..
정규식 표현식(Regular Expresion)
- 정규표현식 혹은 정규식은 특정 문자열의 규칙을 가지는 문자열의 집합을 표현하는 데 사용되는 언어를 의미한다.
- 미리 정의된 기호와 문자를 이용해서 작성한 문자열

- 미리 정의된 기호와 문자를 이용해서 작성한 문자열
-
정규식을 이용하면 많은 양의 텍스트 파일 중에서 원하는 데이터를 손쉽게 뽑아낼 수 있고, 입력된 데이터가 형식에 맞는지 체크할 수 있다.
- 그러나 복잡한 문자 기호 조합으로 가독성이 떨어진다.
정규표현식 패턴(Regular Expression Pattern)

어설션(Assertions)
행이나 단어의 시작 · 끝을 나타내는 경계와 (앞, 뒤 읽고 조건식을 포함한) 어떤 식으로든 매치가 가능한 것을 나타내는 다른 패턴이 포함됩니다.
| 정규식 패턴 | 설명 | 예제 |
|---|---|---|
| ^ | 문장의 시작 (특정 문자열로 시작) | String regExp = “^www”; |
| $ | 문장의 끝 (특정 문자열로 끝남) | String regExp = “com$”; |
수량자(Quantifiers)
일치시킬 문자 또는 표현식의 수를 의미합니다.
| 정규식 패턴 | 설명 | 예제 |
|---|---|---|
| ? | 없음 또는 최대 한 개 (zero or one) | a1? : 1이 최대 한개만 있거나 없을수도 있다→ a(o), a1(o), a11(x), a111(x) |
| * | 없거나 한 개 이상을 의미 (zero or more) | a1* : 1이 있을수도 없을수도 있다→ a(o), a1(o), a11(o), a111(o) |
| + | 한 개 이상을 의미 (one or more) | a1* : 1이 1개 이상있다→ a(x), a1(o), a11(o), a111(o) |
| {n} | n개를 의미한다. | a{3} : a가 딱 3개 있다→ aa(x), aaa(o), aaaa(x), aaaaaaa(x) |
| {n,} | n개 이상을 의미한다. | a{3,} : a가 3개 이상 있다→ aa(x), aaa(o), aaaa(o), aaaaaaa(o) |
| {n, m} | n개부터 m개까지 | a{3,5} : a가 3개 이상 5개 이하 있다→ aa(x), aaa(o), aaaa(o), aaaaaaa(x) |
| {min,} | 최소 | |
| {min, max} | 최소, 그리고 최대 |
문자 클래스(Character classes)
문자와 숫자를 구분하는 것과 같이 문자 종류를 구분하는 데 사용합니다.
\ 기호가 붙으면 키워드처럼 쓰인다.
| 정규식 패턴 | 설명 | 패턴 종류 | 예제 |
|---|---|---|---|
| \w | 문자만 허용하는 정규표현식 | (a-z, A-Z, 0-9, …) | String PATTERN_CHAR = "^[\w]*$"; |
| \W | 한 개의 알파벳, 언더바(_), 숫자를 의미한다. 정확한 용어로는 '확장문자'라고 한다. | ! (a-z, A-Z, 0-9, …) | String PATTERN_NO_CHAR = "^[\W]*$"; |
| \d | 숫자만 허용하는 정규표현식 - 0에서 9까지 숫자 중의 하나라는 뜻이다. | [0-9] | String PATTERN_NUMBER = "^[\d]*$"; |
| \D | 숫자가 아닌 경우에만 허용하는 정규표현식 | ! (0-9) | String PATTERN_NO_NUMBER = "^[\D]*$"; |
| \s | 공백 문자, 탭만을 허용한 정규 표현식 | (space, tabe, newline) | String PATTERN_SPACE_CHAR = "^[\s]*$"; |
| \S | 공백 문자, 탭이 아닌 경우에만 허용하는 정규표현식 | ! (space, tabe, newline) | String PATTERN_SPACE_NO_CHAR = "^[\s]*$"; |
| \. | 점 문자를 의미 |
그룹과 범위(Group and Range)
정규식 문법을 그룹화하거나 범위를 지정할 때 사용하는 패턴입니다.
| 정규식 패턴 | 설명 |
|---|---|
| () | 그룹핑. 소괄호 안의 문자를 하나로 인식. |
| [] | 문자 집합 내에 포함된 문자는 OR로 작동 한 개의 문자를 의미한다.[abc]라면 a 또는 b 또는 c 중의 하나라는 뜻 문자의 범위를 나타낸다.문자 사이에 -(하이픈) 기호가 있다면 다음 뜻으로 쓰인다. [a-z] 이면 a부터 z까지이고 만약에[^] 이런 식으로 ^기호가 들어가면 not 연산을 의미한다. |
| [^] | 부정 문자셋, 괄호안의 어떤 문자가 아닐때 |
| (?:) | 찾지만 기억하지는 않음 |
자주 사용되는 정규식 샘플
| 정규 표현식 | 설명 |
|---|---|
| ^[0-1]*$ | 숫자 |
| ^[a-zA-Z]*$ | 영문자 |
| ^[가-힣]*$ | 한글 |
| \w+@\w+\.\w+(\.\w+)? | |
| ^\d{2,3}-\d{3,4}-\d{4}$ | 전화번호 |
| ^01(?:0|1|[6-9])-(?:\d{3}|\d{4})-\d{4}$ | 휴대 전화번호 |
| \d{6} - [1-4]\d{6} | 주민등록번호 |
| ^\d{3}-\d{2}$ | 우편번호 |
자바 정규식 문법
String 클래스의 정규식 문법
String 문자여렝 바로 정규표현식을 적용하여 필터링이 가능하다.
| String 정규식 메서 | 설명 |
|---|---|
| boolean matches(String regex) | 인자로 주어진 정규식에 매칭되는 값이 있는지 확인 |
| String replaceAll(String regex, String replacement) | 문자열내에 있는 정규식 regex와 매치되는 모든 문자열을 replacement 문자열로 바꾼 문자열을 반환 |
| String[] split(String regex) | 인자로 주어진 정규식과 매치되는 문자열을 구분자로 분할 |
// matches (일치하는지 확인)
String txt = "123456";
boolean result1 = txt.matches("[0-9]+"); // 숫자로 이루어져 있는지
System.out.println(result1); // true// replaceAll (정규표현식과 일치하는 모든 값 치환)
String txt2 = "power987*-;";
String result2 = txt2.replaceAll("[^a-z0-9]","0"); // 영문자와 숫자를 제외한 문자를 모두 0으로 치환
System.out.println(result2); // power987000// split (정규표현식과 일치하는 값 기준으로 나누기)
String txt3 = "power987*-;";
String[] txts = txt3.split("[0-9]+"); // 숫자부분을 기준으로 분할
System.out.println(txts[0]); // power
System.out.println(txts[1]); // *-;regex 패키지 클래스
-
자바에서 정규 표현식을 전문적으로 다루는 클래스인 java.util.regex패키지를 제공해준다. 패키지 안의 클래스 중 주로 Patter클래스와 Matcher클래스가 사용된다.
-
정규식 클래스의 장점은 정규식을 Patten객체로 미리 컴파일 해둘 수 있어서 처리 속도가 좀더 빠르고, 매칭된 데이터를 좀 더 상세히 다룰 수 있다.
Pattern 클래스
-
이 클래스의 주요 역할은 문자열을 정규표현식 패턴 객체로 변환해주는 역할을 한다.
-
물론 이때 문자열을 정규 문법에 알맞게 구성해주어야 한다.
- 그렇지 않으면 예외(Exception)가 발생하게 된다.
-
-
Pattern클래스는 일반 클래스러첨 공개된 생성자를 제공하지 않는다. 그래서 정규식 패턴 객체를 생성하려면
compile()정적 메소드를 호출해야한다.
// 문자열 형태의 정규표현식 문법을 정규식 패턴으로 변환
String patternString = "^[0-9]*$";
Pattern pattern = Pattern.compile(patternString); // Pattern 객체로 컴파일된 정규식은 뒤의 Matcher 클래스에서 사용된다-
Patter객체로 컴파일된 정규식은 Matcher클래스에서 사용된다.
-
혹은 바로
matches()메소드를 활용하여 정규식 검증을 할 수도 있다. -
matches()메서드의 첫번째 입력값은 정규식 문자열이고, 두 번째 입력값은 검증 대상 문자열이다. 검증 후 대상 문자열이 정규 표현식과 일치하면 true, 아니면 false값을 리턴한다.
-
// 샘플 문자열
String txt1 = "123123";
String txt2 = "123이것은숫자입니다00";
boolean result = Pattern.matches("^[0-9]*$", txt1); // 첫번째 매개값은 정규표현식이고 두번째 매개값은 검증 대상 문자열
System.out.println(result); // true
boolean result2 = Pattern.matches("^[0-9]*$", txt2);
System.out.println(result2); // false| Pattern 클래스 메서드 | 설명 |
|---|---|
| compile(String regex) | 정규 표현식의 패턴을 작성 |
| matches(String regex, CharSequence input) | 정규 표현식의 패턴과 문자열이 일치하는지 체크, 일치할 경우 true, 그렇지 않은 경우 false를 리턴 > 일부 문자열이 아닌 전체 문자열과 완벽히 일치 해야한다. |
| asPredicate() | 문자열을 일치시키는데 사용할 수 있는 술어를 작성 |
| pattern() | 컴파일된 정규 표현식을 String형태로 반환 |
| split(CharSequence input) | 문자열을 주어진 인자값 CharSequence패턴에 따라 분리 |
Matcher 클래스
대상 문자열의 패턴을 해석하고 주어진 패턴과 일치하는지 판별하고 반환된 필터링 된 결과값들을 지니고 있따.
-
Matcher클래스 역시 Pattern클래스와 마찬가지로 공개된 생성자가 없다.
- Matcher객체는 Pattern객체의
matcher()메소드를 호출해서 얻는다.
- Matcher객체는 Pattern객체의
자바의 정규식 결과 반환 로직 순서를 정리하자면 다음과 같다.
-
Pattern.compile()을 통해 정규식문자열을 패턴 객체로 변환 -
패턴 객체에서
matcher()메소드를 통해 문자열을 비교하고 검사한 결과값을 담은 matcher객체를 반환 -
matcher객체에서 메소드로 원하는 결과값을 뽑음
Pattern.matches()메소드는 단순히 참/거짓의 결과를 반환하지만 Matcher클래스의group()메소드를 통해 필터링 된 문자열을 출력할 수 있다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
// 비교할 문자열
String txt = "1487안녕";
// 문자열 형태의 정규표현식 문법
String patternString = "^[0-9]+";
// 1) 문자열 형태의 정규표현식 문법을 정규식 패턴으로 변환
Pattern pattern = Pattern.compile(patternString);
// 2) 패턴 객체로 matcher 메서드를 통해 문자열을 검사하고 필터링된 결과를 매처 객체로 반환
Matcher matcher = pattern.matcher(txt);
// 3) 정규식 필터링된 결과를 담은 matcher에서 메소드를 통해 결과를 출력
System.out.println(matcher.find()); // 매칭된 결과가 있는지? : true
System.out.println(matcher.group()); // 매칭된 부분을 반환 : 1487
}
}| Matcher 클래스 메서드 | 설명 |
|---|---|
| find() | 패턴이 일치하는 경우 true를 반환, 불일치하는 경우 false반환(여러개가 매칭되는 경우 반복실행하면 일치하는 부분 다음부터 이어서 매칭됨) |
| find(int start) | start 위치 이후부터 매칭 검색 |
| start() | 매칭되는 문자열의 시작위치 반환 |
| start(int group) | 지정된 그룹이 매칭되는 시작위치 반환 |
| end() | 매칭되는 문자열 끝위치의 다음 문자위치 반환 |
| end(int group) | 지정된 그룹이 매칭되는 끝위치의 다음 준자위치 반환 |
| group() | 매칭된 부분을 반환 |
| group(int group) | 그룹화되어 매칭된 패턴 중 group번째 부분 반환 |
| groupCount() | 괄호로 지정해서 그룹핑한 패턴의 전체 개수 반환 |
| matches() | 패턴이 전체 문자열과 일치할 경우 true반환(일부 문자열이 아닌 전체 문자열과 완벽히 일치 해야한다.) |
다중 결과값 출력하기
필터링된 결과값이 여러개일 경우 아래와 같이 반복문을 통해 순회하여 출력해야 한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String something = "hello987*-;hi66"; // 비교할 문자열
Pattern pattern = Pattern.compile("[a-z]+[0-9]+"); // 정규표현식 문자열로 패턴 객체 생성
Matcher matcher = pattern.matcher(something); // 패턴 객체로 문자열을 필터링한뒤 그 결과값들을 담은 매처 객체 생성
while (matcher.find()) {
System.out.println(matcher.group());
// 루프 1번 : hello987
// 루프 2번 : hi66
}
}
}그룹핑 결과 출력하기
패턴을 그룹 괄호()로 이용해서 세 부분으로 묶으면, 각 그룹마다 매칭되게 된다.
group(1), group(3), group(5)...으로 호출할 수 있다.
group()이나 group(0)은 그룹으로 매칭 된 문자열 전체를 반환한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
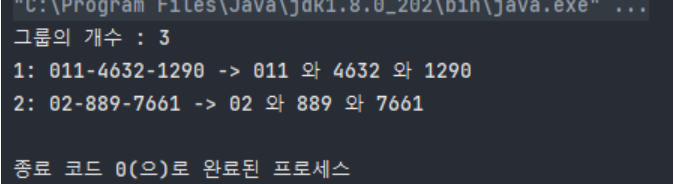
String source = "011-4632-1290, 02-889-7661";
String pattern = "(0\\d{1,2})-(\\d{3,4})-(\\d{4})";
Matcher matcher = Pattern.compile(pattern).matcher(source); // 한방에 매처 객체 반환
System.out.println("그룹의 개수 : " + matcher.groupCount()); //그룹화된 개수가 몇개인지 출력
int i = 0;
while (matcher.find()) {
System.out.println(++i + ": " + matcher.group() + " -> " + matcher.group(1) + " 와 " + matcher.group(2) + " 와 " + matcher.group(3));
}
}
}
매칭 위치 출력하기
start()와 end()메서드로 매칭되는 문자열 부분의 위치를 알아낼 수 있다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
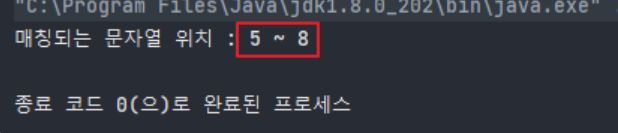
String source = "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세";
String pattern = "백두산";
Matcher matcher = Pattern.compile(pattern).matcher(source);
while (matcher.find()) {
// start()와 end()로 일치하는 부분의 위치를 알아낼 수 있다.
System.out.println("매칭되는 문자열 위치 : " + matcher.start() + " ~ " + matcher.end());
}
}
}
정규 표현식 예제
예제 1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a","b","c","d","aa","ab","ac","abc","abcd", "bc", "bcd", "cde"};
Pattern p = Pattern.compile("."); // .(온점)으로, 임의의 한 문자를 나타낸다.
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // a,b,c,d,
}
}
}- 만약 .(온점)이 ..면 임의의 두문자 / ... 세개면 임의의 세문자를 나타냄
예제 2
| or 연산
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a","b","c","d","aa","ab","ac","abc","abcd", "bc", "bcd", "cde"};
Pattern p = Pattern.compile("a|b");
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // a,b,
}
}
}- a | b | c라면 a, b,c를 나타냄
예제 3
[]
- 문자 집합 메타 문자.
- 문자 집합 내에 포함된 문자는 OR로 작동
- 한 개의 문자를 의미한다.[abc]라면 a 또는 b 또는 c 중의 하나라는 뜻
- 문자의 범위를 나타낸다.
- 문자 사이에 -(하이픈) 기호가 있다면 다음 뜻으로 쓰인다.
- [a-z] 이면 a부터 z까지이고 만약에[^] 이런 식으로 ^기호가 들어가면 not 연산을
- 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a","b","c","d","aa","ab","ac","abc","abcd", "bc", "bcd", "bcde", "cd", "cde", "cdef"};
Pattern p = Pattern.compile("a[abc]"); // a로 시작하고 abc중에 한 글자로 끝나는 두글자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // aa,ab,ac,
}
}
}- a[abc][abc][abc] 라면 a로 시작하고 abc중에 한글자 > 총 3글자의 문자이다.
예제 4
없거나 한 개 이상을 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a","b","c","d","aa","ab","ac","abc","aaa", "aaaa", "acc", "bc", "bcd", "bcde", "cd", "cde", "cdef"};
Pattern p = Pattern.compile("a*"); // a로 시작하고 a가 없거나 한 개 이상
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // a,aa,aaa,aaaa,
}
}
}- *은 뒤에 없어도 되고, 더 많아도 된다는 의미다(개수의 제한이 x)
예제 4-1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a", "b", "ab", "ba", "abc", "bac", "baa", "bbc", "baaa", "baaaa", "bbc", "bbca"};
Pattern p = Pattern.compile("ba*"); // b로 시작하고 a가 없거나 한 개 이상
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // b,ba,baa,baaa,baaaa,
}
}
}- *앞에 문자로 시작하는데 없어도 되고, 여러개여도 되지만, a가 아닌 문자가 올수는 없다.
예제 5
- 한 개 이상을 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a","b","c","d","aa","ab","ac","abc","aaa", "aaaa", "acc", "bc", "bcd", "bcde", "cd", "cde" , "cdef"};
Pattern p = Pattern.compile("a+"); // a로 시작하고 a가 한 개 이상을 의미한다.
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // a,aa,aaa,aaaa,
}
}
}- 반드시 한개 이상! (개수의 제한은 없음)
예제 5-1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"a", "b", "ab", "ba", "abc", "bac", "baa", "bbc", "baaa", "baaaa", "bbc", "bbca"};
Pattern p = Pattern.compile("ba+"); // b로 시작하고 a가 한 개 이상
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // ba,baa,baaa,baaaa,
}
}
}- 반드시 한 개 이상이지만, a가 아닌 다른 문자가 올 수는 없다. 반드시 + 앞에 문자 a만 올 수 있다.
예제 6
범위 지정 메타 문자 마이너스(-)! 왼쪽 문자를 시작으로 오른쪽 문자까지 순차적으로 문자를 증가!
- [A-Z] 는 [ABCDEGHIJKLMNOPQRSTUVWXYZ] 과 동일! 문자 집합 내에서만 사용 가능
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "a", "b", "c", "0", "1", "2", "ab", "01"};
Pattern p = Pattern.compile("[A-Z]"); // A-Z 사이 한글자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // A,B,C,
}
}
}-
[] 안에 는 범위이고 []렇게 감싸져있다면 무조건 한 글자이다.
-
만약 "[A-Z][A-Z]" 이라면 A-Z 사이 한 글자로 총 두 글자가 올 수 있는 것이다.
-
"[0-9]" > 이런 형태는 0~9 사이의 한 글자 이다.
예제 6-1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0", "1", "2", "ab", "01"};
Pattern p = Pattern.compile("[A-Za-z]"); // A-Za-z 사이 한글자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // A,B,C,a,b,c,
}
}
}[A-Za-z] 범위는 하나의 패턴으로 취급
- 모든 대문자 알파벳, 모든 소문자 알파벳을 의미.
-
[]하나니까 한 글자고 해당 안에 있는 범위를 하나로 취급해 A-Z 와 a-z사이의 한 글자인것이다.
-
만약 "[A-Za-z][A-Za-z]" 이라면 A-Z 와 a-z사이 한 글자로 총 두 글자가 올 수 있는 것이다.
예제 6-2
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23"};
Pattern p = Pattern.compile("[0-9][0-9]"); // 0-9 사이 한글자 0-9 사이 한글자 총 두글자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // 01,23,
}
}
}- 위와 마찬가지로 0-9사이 한글자로 총 문자로되어있는 두 글자가 올 수 있는 것이다.
예제 7
\d
digit의 약자로 한 개의 숫자를 의미한다.
[0-9] 의 의미와 돌일하다. > 0에서 9까지 숫자 중의 하나라는 뜻이다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23"};
Pattern p = Pattern.compile("\\d"); // 0-9 사이 한글자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // 0,1,2,
}
}
}예제 8
\s
공백 문자를 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"ABC", "A C", "123", "A1B"};
Pattern p = Pattern.compile("[A-Z]\\s[A-Z]"); // A-Z한자 공백문자 A-Z 한자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // A C,
}
}
}예제 9
\w
한 개의 알파벳, 언더바(_), 숫자를 의미한다. > [a-zA-Z_0-9]와 같은 뜻이다.
이처럼 \ 기호가 붙으면 키워드처럼 쓰인다.
직접 풀어쓰는 것에 비해 편리하다. > 정확한 용어로는 '확장문자'라고 한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23", "012"};
Pattern p = Pattern.compile("\\w"); // [a-zA-Z_0-9]
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // A,B,C,a,b,c,0,1,2,
}
}
}예제 10
{n}
n개를 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23", "012", "ABC", "A0E"};
Pattern p = Pattern.compile("\\w{2}"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // AB,Bc,BD,ab,01,23,
}
}
}예제 11
{n, }
n개 이상을 의미한다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23", "012", "ABC", "A0E"};
Pattern p = Pattern.compile("\\w{2,}"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // AB,Bc,BD,ab,01,23,012,ABC,A0E,
}
}
}예제 12
{n, m}
n개부터 m개 까지
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"A","B","C", "AB", "Bc", "BD", "a", "b", "c", "0",
"1", "2", "ab", "01", "23", "012", "ABC", "A0E"
,"A1B", "ABcD", "a2G0", "abcDE", "12ASD"};
Pattern p = Pattern.compile("\\w{2,4}"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // AB,Bc,BD,ab,01,23,012,ABC,A0E,A1B,ABcD,a2G0,
}
}
}예제 13
?
없음 또는 한개
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"abc", "abb", "abbb", "ab","a", "abbbb","abcd"};
Pattern p = Pattern.compile("ab?"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // ab,a,
}
}
}예제 14
()
그룹핑, 소괄호 안의 문자를 하나로 인식
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"abc", "abbc", "abbbc", "abac","aabc", "babc","abcd"};
Pattern p = Pattern.compile("\\w(abc)"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // aabc,babc,
}
}
}예제 15
^
문자열의 시작
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"http://www.naver.com", "hellohttp://www.daum.net", "goodhttp"};
Pattern p = Pattern.compile("^http.*"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // http://www.naver.com,
}
}
}예제 16
$
문자열의 종료지점
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"http://www.naver.com", "hellohttp://www.daum.net", "goodhttp"};
Pattern p = Pattern.compile(".*http$"); //
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ","); // goodhttp,
}
}
}예제 16-1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"123","012", "3GT", "안녕", "Hello"};
Pattern p = Pattern.compile("^[0-9]+$"); // 숫자
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.println(data[i] + " 숫자입니다.");
else
System.out.println(data[i] + " 숫자가 아닙니다.");
}
}
}
/*
* 실행 결과
123 숫자입니다.
012 숫자입니다.
3GT 숫자가 아닙니다.
안녕 숫자가 아닙니다.
Hello 숫자가 아닙니다.
*/-
"^[0-9]+$"- 숫자 -
"^[a-zA-Z]+$"- 영문자 -
"^[가-힣]+$"- 한글
예제 17
import java.util.regex.*; // Pattern과 Matcher가 속한 패키지
class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"bat", "baby", "bonus", "c", "cA",
"ca", "co", "c.", "c0", "c#",
"car","combat","count", "date", "disc"
};
String[] pattern = {".*","c[a-z]*","c[a-z]", "c[a-zA-Z]",
"c[a-zA-Z0-9]","c.","c.*","c\\.","c\\w",
"c\\d","c.*t", "[b|c].*", ".*a.*", ".*a.+",
"[b|c].{2}"
};
for(int x=0; x < pattern.length; x++) {
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : " + pattern[x] + " 결과: ");
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ",");
}
System.out.println();
}
} // public static void main(String[] args)
}
/*
실행 결과
Pattern : .* 결과: bat,baby,bonus,c,cA,ca,co,c.,c0,c#,car,combat,count,date,disc,
Pattern : c[a-z]* 결과: c,ca,co,car,combat,count,
Pattern : c[a-z] 결과: ca,co,
Pattern : c[a-zA-Z] 결과: cA,ca,co,
Pattern : c[a-zA-Z0-9] 결과: cA,ca,co,c0,
Pattern : c. 결과: cA,ca,co,c.,c0,c#,
Pattern : c.* 결과: c,cA,ca,co,c.,c0,c#,car,combat,count,
Pattern : c\. 결과: c.,
Pattern : c\w 결과: cA,ca,co,c0,
Pattern : c\d 결과: c0,
Pattern : c.*t 결과: combat,count,
Pattern : [b|c].* 결과: bat,baby,bonus,c,cA,ca,co,c.,c0,c#,car,combat,count,
Pattern : .*a.* 결과: bat,baby,ca,car,combat,date,
Pattern : .*a.+ 결과: bat,baby,car,combat,date,
Pattern : [b|c].{2} 결과: bat,car,
*/자주 쓰이는 정규식 조건
전화번호
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"02", "02-123", "02-123-456", "02-123-4567",
"02-1234-4567", "031-1234-5678"};
Pattern p = Pattern.compile("^\\d{2,3}-\\d{3,4}-\\d{4}$"); // 전화번호
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.println(data[i] + " 유효한 전화번호입니다.");
else
System.out.println(data[i] + " 유효한 전화번호가 아닙니다.");
}
}
}
/*
* 실행 결과
*
02 유효한 전화번호가 아닙니다.
02-123 유효한 전화번호가 아닙니다.
02-123-456 유효한 전화번호가 아닙니다.
02-123-4567 유효한 전화번호입니다.
02-1234-4567 유효한 전화번호입니다.
031-1234-5678 유효한 전화번호입니다.
*/핸드폰 번호
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"010", "010-1234-5678", "02-123-456", "02-123-4567",
"02-1234-4567", "031-1234-5678"};
Pattern p = Pattern.compile("^01(0|1|[6-9])-(\\d{3}|\\d{4})-\\d{4}$"); // 핸드폰 번호
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.println(data[i] + " 유효한 핸드폰 번호입니다.");
else
System.out.println(data[i] + " 유효한 핸드폰 번호가 아닙니다.");
}
}
}
/*
실행 결과
010 유효한 핸드폰 번호가 아닙니다.
010-1234-5678 유효한 핸드폰 번호입니다.
02-123-456 유효한 핸드폰 번호가 아닙니다.
02-123-4567 유효한 핸드폰 번호가 아닙니다.
02-1234-4567 유효한 핸드폰 번호가 아닙니다.
031-1234-5678 유효한 핸드폰 번호가 아닙니다.
*/이메일
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpressionTest {
public static void main(String[] args) {
String[] data = {"hello", "hello@", "hello@naver", "hello@naver.com", "good@good.co.kr"};
Pattern p = Pattern.compile("\\w+@\\w+\\.\\w+(\\.\\w+)?"); // 이메일 주소
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.println(data[i] + " 유효한 이메일 주소입니다.");
else
System.out.println(data[i] + " 유효한 이메일 주소가 아닙니다.");
}
}
}
/*
* 실행 결과
*
hello 유효한 이메일 주소가 아닙니다.
hello@ 유효한 이메일 주소가 아닙니다.
hello@naver 유효한 이메일 주소가 아닙니다.
hello@naver.com 유효한 이메일 주소입니다.
good@good.co.kr 유효한 이메일 주소입니다.
*/문장에서 문자열을 찾고, 단어 변환
import java.util.regex.*; // Pattern과 Matcher가 속한 패키지
class RegularExpressionTest {
public static void main(String[] args) {
String source = "A broken hand works, but not a broken heart.";
String pattern = "broken";
StringBuffer sb = new StringBuffer();
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(source);
System.out.println("source:"+source);
int i=0;
while(m.find()) {
System.out.println(++i + "번째 매칭:" + m.start() + "~"+ m.end());
// broken을 drunken으로 치환하여 sb에 저장한다.
m.appendReplacement(sb, "drunken");
}
m.appendTail(sb);
System.out.println("Replacement count : " + i);
System.out.println("result:"+sb.toString());
}
}
/*
실행 결과
source:A broken hand works, but not a broken heart.
1번째 매칭:2~8
2번째 매칭:31~37
Replacement count : 2
result:A drunken hand works, but not a drunken heart.
*/-
Matcher의
find()로 정규식과 일치하는 부분을 찾으면, 그 위치를start()와end()로 알아낼 수 있다. -
appendReplacement(StringBuffer sb, String replacement)를 이용해서 원하는
문자열(replacement)로 치환할 수 있다.- 치환된 결과는 StringBuffer인 sb에 저장되는데,
sb에 저장되는 내용을 단계별로 살펴보면 이해하기 쉬울 것이다.
- 치환된 결과는 StringBuffer인 sb에 저장되는데,
-
문자열 source에서 "broken"을
m.find()로 찾은 후 처음으로
m.appendReplacement(sb, "drunken");가 호출되면 source의 시작부터 "broken"을 찾은
위치까지의 내용에 "drunken"을 더해서 저장한다.- sb에 저장된 내용 : "A drunken"
-
m.find()는 첫 번째로 발견된 위치의 끝에서부터 다시 검색을 시작하여 두 번째
"broken"을 찾게 된다. 다시 m.appendReplacement(sb, "drunken");가 호출- sb에 저장된 내용 : "A drunken hand works, but not a drunken"
-
m.appendTail(sb);이 호출되면 마지막으로 치환된 이후의 부분을 sb에 덧붙인다.
- sb에 저장된 내용 : "A drunken hand works, but not a drunken heart."
정규식 문제
- 아래 코드의실행결과를 적으시오.
import java.util.regex.*; // Pattern과 Matcher가 속한 패키지
class RegularEx1 {
public static void main(String[] args)
{
String[] data = {"bat", "baby", "bonus",
"cA","ca", "co", "c.", "c0", "car","combat","count",
"date", "disc"};
Pattern p = Pattern.compile("c[a-z]*");
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ",");
}
}
}- cA, ca, co,
- 아래 코드의 실행결과를 적으시오.
import java.util.regex.*; // Pattern과 Matcher가 속한 패키지
class RegularEx2 {
public static void main(String[] args) {
String[] data = {"bat", "baby", "bonus", "c", "cA",
"ca", "co", "c.", "c0", "c#",
"car","combat","count", "date", "disc"
};
String[] pattern = {".*","c[a-z]*","c[a-z]", "c[a-zA-Z]",
"c[a-zA-Z0-9]","c.","c.*","c\\.","c\\w",
"c\\d","c.*t", "[b|c].*", ".*a.*", ".*a.+",
"[b|c].{2}"
};
for(int x=0; x < pattern.length; x++) {
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : " + pattern[x] + " 결과: ");
for(int i=0; i < data.length; i++) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ",");
}
System.out.println();
}
} // public static void main(String[] args)
}-
bat,baby,bonus,c,cA,ca,co,c.,c0,c#,car,combat,count,date,disc, 틀림
-
ca, co, car, combat, count
-
ca, co
-
cA, ca, co
-
cA, ca, co, c0
-
cA, ca, co, c., c0, c#
-
c, cA, ca, co, c., c0, c#, car, combat, count
-
c.
-
cA, ca, co, c0
-
c0
-
combat, count
-
bat, baby, bonus, c, cA, ca, co, c., c0, c#, car, combat, count 틀림
-
bat, baby, ca, car, combat, date,
-
bat, baby, car, combat, date
-
bat, car
