
해당 포스팅은 2022.05.31에 발행된 기사 데이터를 기준으로 작성되었습니다.
군집화 (Clustering)
클러스터링은 비지도 학습의 일종으로, 데이터 포인트들을 별개의 군집으로 그룹화하는 것을 의미한다. 유사성이 높은 데이터들은 동일한 그룹으로 분류하고, 서로 다른 그룹의 데이터들은 최대한 상이하게 만드는 것이 클러스터링의 최종적인 목표이다.
앞서 전처리 및 벡터화를 거친 뉴스 기사 데이터를 클러스터링 기법을 통해 유사한 주제의 기사끼리 분류하고자 하였다.
총 두 번의 클러스터링을 진행하였는데 첫 번째 클러스터링은 중복 기사를 제거하기 위함이었고, 두 번째 클러스터링은 유사한 기사들끼리 군집을 생성하기 위함이었다.
하루 동안 발행된 기사들에는 언론사만 다르고 내용이 같은 기사들이 많이 포함되어있다. 따라서 해당 중복된 기사들을 제거하는 과정이 필요하다.
(1) DBSCAN
DBSCAN은 Density Based Spatial Clustering of Applications with Noise의 약자로, 밀도 차이 기반 알고리즘이다.
해당 알고리즘은 K-means clusterng과 달리 군집의 개수 를 지정해줄 필요가 없으며, 알고리즘이 자체적으로 데이터 밀도 차이를 감지하여 군집을 생성한다. 하지만 데이터 밀도가 자주 변하거나, 밀도 차이가 극명하지 않은 데이터에는 좋은 성능을 기대하기 어렵다.

중복 기사를 제거하기 위한 첫 번째 클러스터링에서는, 중복되는 기사들의 군집 개수를 알 수 없기 때문에 군집의 개수를 설정해주지 않아도 되는 DBSCAN 사용하였다. 또한, 문맥을 고려하기 위해 TF-IDF Vectorization을 진행하였다.
해당 클러스터링 기법을 이용하여 유사한 제목을 가진 기사들의 군집을 생성함으로써 동일한 기사들끼리의 군집을 생성하고, 해당 군집에서 대표 기사 하나만 추출하도록 함으로써 중복되는 기사들을 제거하였다.

이 과정에서 중복 기사들끼리만 묶기 위해서, 군집화 기준을 까다롭게 설정하였다. epsilon 값은 0.1로 설정하여 군집 내부 유사도는 매우 높게 설정했고, min_samples 값을 1로 설정하여 군집 간 변별력을 낮게 만들어주었다.
그 결과 위 사진과 같이 동일한 기사끼리만 효과적으로 군집화가 이루어진 것을 확인할 수 있었다. 311개의 군집이 생성되었으며 각 군집에서 대표 기사 한 개씩, 총 311개의 기사를 추출하였다.
코드
#1 tf-idf 임베딩(+Normalize)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(min_df = 3, ngram_range=(1,5))
tfidf_vectorizer.fit(text)
vector = tfidf_vectorizer.transform(text).toarray()
vector = np.array(vector)#2 DBSCAN Clustering
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.1,min_samples=1, metric = "cosine")
# 거리 계산 식으로는 Cosine distance를 이용
# eps이 낮을수록, min_samples 값이 높을수록 군집으로 판단하는 기준이 까다로움.
result = model.fit_predict(vector)
train_extract['cluster1st'] = result
print('군집개수 :', result.max())
train_extract#3 대표 기사 추출
def print_cluster_result(train):
clusters = []
counts = []
top_title = []
top_noun = []
for cluster_num in set(result):
# -1,0은 노이즈 판별이 났거나 클러스터링이 안된 경우
# if(cluster_num == -1 or cluster_num == 0):
# continue
# else:
print("cluster num : {}".format(cluster_num))
temp_df = train[train['cluster1st'] == cluster_num] # cluster num 별로 조회
clusters.append(cluster_num)
counts.append(len(temp_df))
top_title.append(temp_df.reset_index()['Title'][0])
top_noun.append(temp_df.reset_index()['noun'][0]) # 군집별 첫번째 기사를 대표기사로 ; tfidf방식
for title in temp_df['Title']:
print(title) # 제목으로 살펴보자
print()
cluster_result = pd.DataFrame({'cluster_num':clusters, 'count':counts, 'top_title':top_title, 'top_noun':top_noun})
return cluster_result(2) K-Means Clustering
k-Means Clustering은 사전에 군집의 개수 를 설정해주어야 한다. 개의 군집은 각 하나의 중심점을 가지고, 각 데이터는 가까운 중심점에 할당된다. 각 군집과 데이터 간의 거리 분산을 최소화하는 방식으로 클러스터링이 진행된다.

두 번째로는 유사한 주제의 기사들끼리 묶어주기 위해 클러스터링을 진행하였는데, 앞서 DBSCAN을 이용해 구축한 311개의 뉴스 기사 데이터를 다시 TF-IDF Vectorization 한 후, K-Means Clustering 기법을 이용하였다.
위에 설명한 것과 같이 해당 알고리즘은 사전에 군집 개수 를 설정해줘야 했기 때문에, 최적의 군집 개수를 찾기 위해 두가지 방법을 고려하였다.
Elbow Method
첫 번째로는 클러스터 내의 총 변동을 설명하는 WCSS(Within Clusters Sum of Squares)를 이용하는 Elbow Method이다. 각 클러스터를 WCSS 방법으로 계산한 뒤, SSE가 가장 급격하게 줄어드는 구간에서 군집 개수 를 결정하는 방법이다.
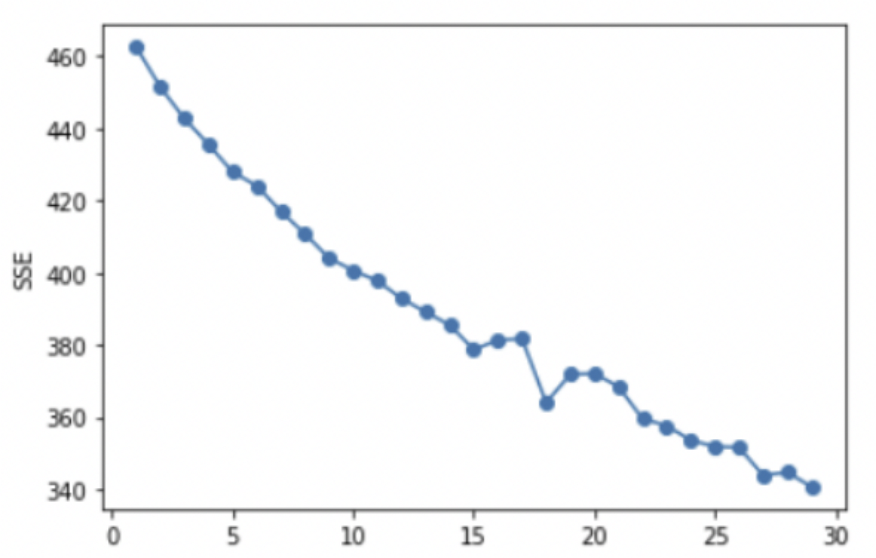
하지만 거의 일정한 SSE 감소율로 인해 적합한 를 결정하기에는 어려웠다.
Silhouette Score
두 번째로 고려한 방법은 다른 클러스터(seperation)에 비해 자신의 클러스터(cohesion)와의 유사도를 측도로 하는 Silhouette Score이다. 값이 높으면 객체가 자체 클러스터와 잘 일치하고 인접 클러스터와 잘 일치하지 않음을 나타낸다.
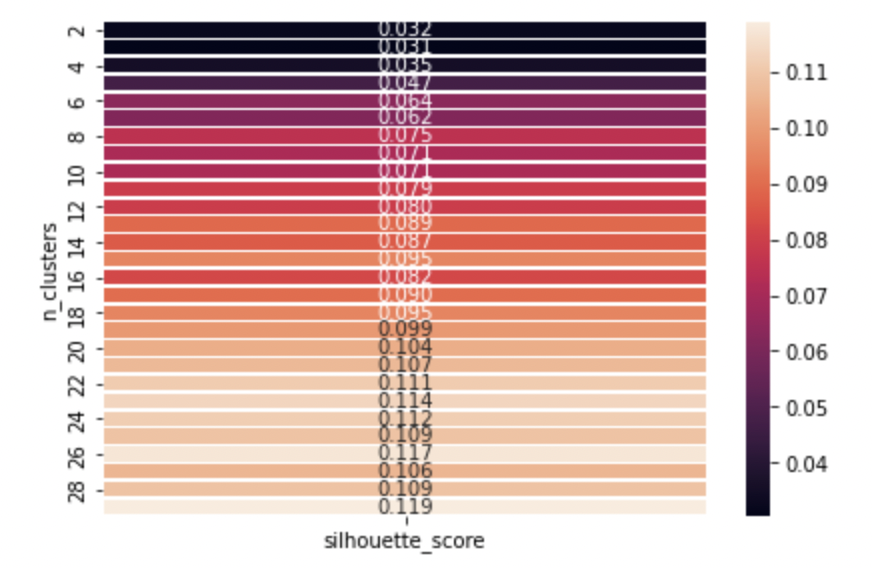
결과는 위와 같았고, 실루엣 계수가 가장 높은 이 최적 군집 개수라고 판단하였다. 따라서 cluster 0부터 cluster 28까지, 총 29개의 군집으로 311개의 기사를 분류하였다.

2차 클러스터링을 진행한 후 다음의 두 기준에 해당하는 군집을 제외시켰다.
-
가장 많은 기사를 포함한 군집
: 여러 날짜의 데이터를 이용해 2차 클러스터링을 진행할 때마다, 꼭 한 군집에는 유독 많은 데이터가 몰려있는 것을 확인했다. 다른 군집들과 연관성이 낮은 나머지 기사들이 모여있기 때문에 군집 내 유사도가 낮다고 판단하여, 가장 많은 기사를 가지고 있는 군집은 제외하기로 결정하였다. -
군집 내 기사가 5개 이하인 경우
이렇게 해서 뉴스 기사는 최종적으로 총 23개의 군집으로 분류되었다.
코드
# Silhouette Score - 최적 k
def visualize_silhouette_layer(data, param_init='random', param_n_init=10, param_max_iter=300):
clusters_range = range(2,30)
results = []
for i in clusters_range:
clusterer = KMeans(n_clusters=i, init=param_init, n_init=param_n_init, max_iter=param_max_iter, random_state=0)
cluster_labels = clusterer.fit_predict(data)
silhouette_avg = silhouette_score(data, cluster_labels)
results.append([i, silhouette_avg])
result = pd.DataFrame(results, columns=["n_clusters", "silhouette_score"])
pivot_km = pd.pivot_table(result, index="n_clusters", values="silhouette_score")
plt.figure()
sns.heatmap(pivot_km, annot=True, linewidths=.5, fmt='.3f', cmap=sns.cm._rocket_lut)
plt.tight_layout()
plt.show()
visualize_silhouette_layer(vector_2nd) # 가장 높은 실루엣 계수와 매핑되는 k# K-Means Clustering
from sklearn.cluster import KMeans
result_2nd = KMeans(n_clusters=29).fit_predict(vector_2nd)
cluster1_result['cluster2nd'] = result_2nd
cluster2_result = print_cluster_result( train=cluster1_result,
result=result_2nd, col_cluster="cluster2nd")키워드 추출
각 군집에서 대표 키워드를 추출하기 위해 다음의 두 가지 방법을 고려하였다.
(1) Token별 카운트
한 군집 내의 모든 토큰을 카운트해, 가장 많은 등장하는 단어를 키워드로 추출하는 단순한 방식이다.
결론적으로, 선정, 획득, 지정과 같이 유의미하지 않은 단어들이 추출되었기 때문에 이 방식은 사용하지 않았다.
(2) KeyBERT
BERT를 적용한 오픈 소스 파이썬 모듈인 KeyBERT 모델을 사용해보았다. 군집 내의 모든 타이틀을 하나의 텍스트로 이어 KeyBERT 모델에 넣었고, '전체 문장'과 가장 유사한 키워드를 추출하였다.
KeyBERT는 여러 워드임베딩 방식을 포함해서 다양한 임베딩 모델을 지원했는데, sentence-tansformer 방식 중, paraphrase-multilingual-MiniLM-L12-v2 모델을 사용하였다.
또한 Manual Search로 keyphrase_ngram_range, use_mmr, diversity, use_maxsum, nr_candidate 등의 하이퍼파라미터를 조정해주었다.
모든 경우에 대해서 키워드 추출 결과를 확인해본 결과, 인접한 하나나 두 개의 단어로 이루어진 후보군들 중에서 코사인 유사도를 기반으로 키워드를 추출하는 방식이 가장 좋은 성능을 보였다.
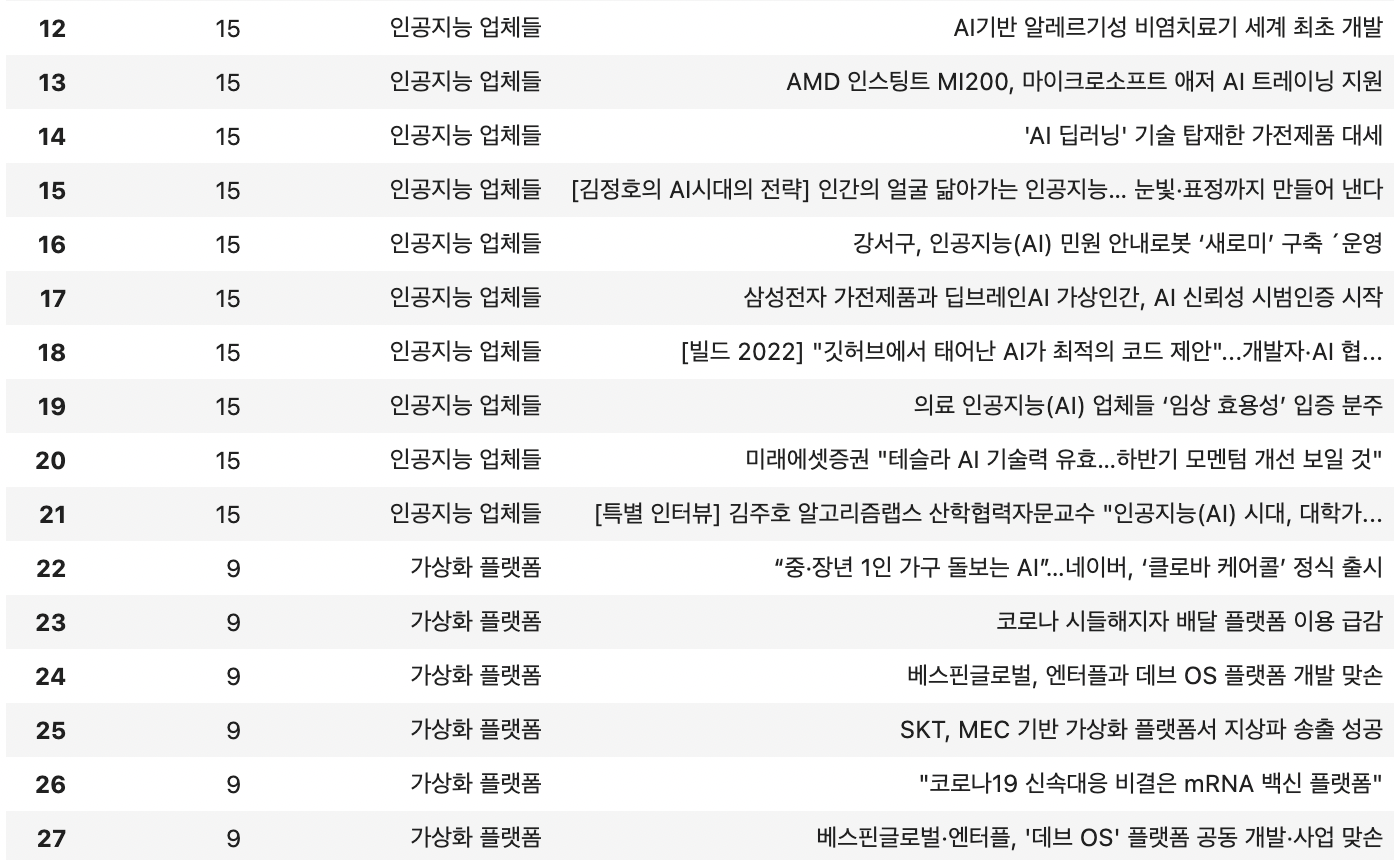
코드
key_model = KeyBERT('paraphrase-multilingual-MiniLM-L12-v2') #distilbert-base-nli-mean-tokens / paraphrase-multilingual-MiniLM-L12-v2def keyword(data, col_cluster): #data = cluster_result (데이터프레임) #1분 30초 소요됨
result = []
for i in range(len(data)):
key_text = cluster1_result[cluster1_result[col_cluster]==i]['noun']
key_text = ' '.join(key_text)
keyword = key_model.extract_keywords(key_text, keyphrase_ngram_range=(1,2), top_n=1)
result.append(keyword[0][0])
return result
def merge_keyword(data, col_cluster): #새 열로 추가.
data_temp = data.copy()
data_temp['keyword'] = keyword(data, col_cluster)
return data_temp
keyword_result = merge_keyword(cluster2_result, col_cluster='cluster2nd')
keyword_df = keyword_result[['cluster_num', 'count', 'keyword']]
keyword_df.sort_values(by='count', ascending=False, inplace=True, ignore_index=True)
keyword_df.drop(index=[0], inplace=True)
keyword_df = keyword_df[keyword_df['count']>5]
lst = []
for i in keyword_df['keyword']:
lst.append(i.upper())
keyword_df['keyword'] = lst
keyword_dfcsv file
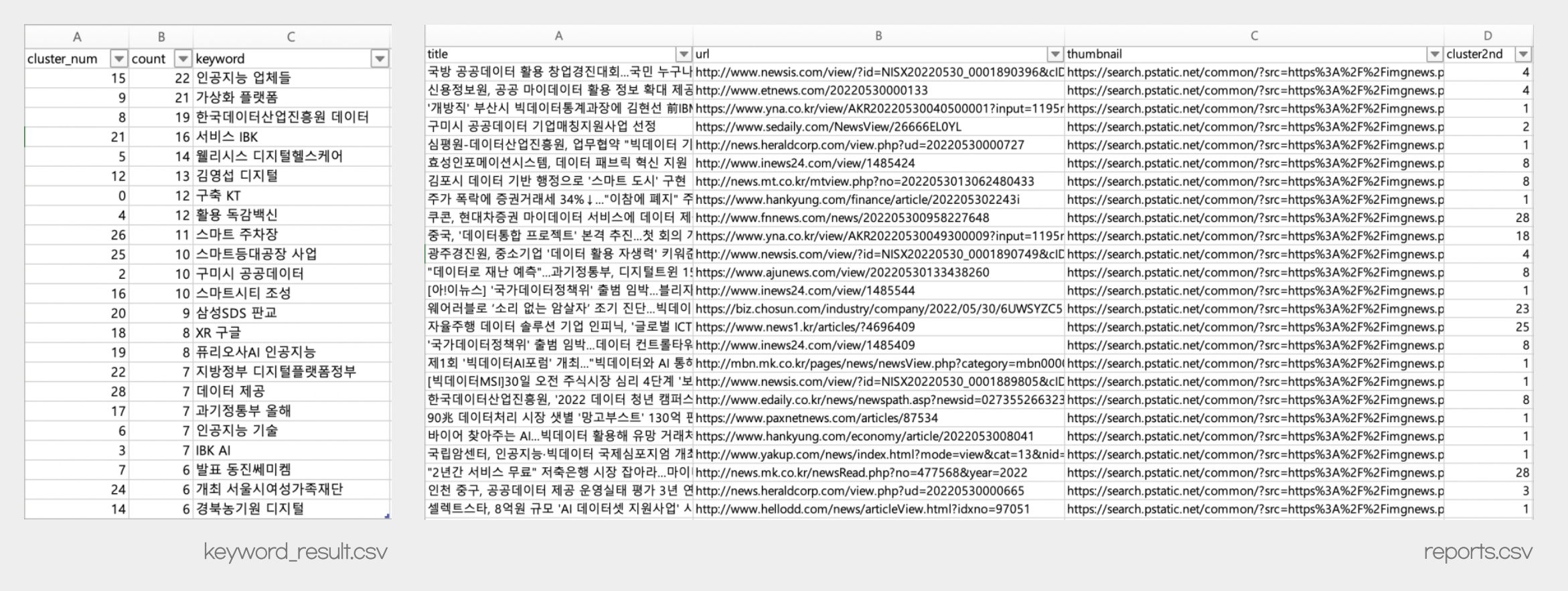
최종 결과를 다음과 같이 2개의 csv 파일로 저장한 후, 두개의 테이블을 조인해서 사용하였다.
keyword_result.csv: 군집 넘버, 군집별 기사 개수, 키워드reports.csv: 군집 넘버, 기사 제목, 기사 링크, 이미지 링크
시각화 및 웹 구현
최종 결과를 사용자에게 제공하기 위해 시각화 및 웹 구현을 진행하고자 하였다. 이 과정에서 두가지 방법을 시도하였고, 결론적으로는 Tableau와 React를 이용해 데이터 분야 뉴스레터를 제작하였다.
(1) Power BI
Power BI는 테이블 열을 웹 링크, 이미지 링크로 지정이 가능하기에 원래 의도하던 바를 쉽게 구현할 수 있다는 장점이 있었다. 하지만 디자인 자유도가 낮아 직관적이고 깔끔한 뉴스레터를 제공할 수 없다는 점이 아쉬웠다.

(2) Tableau & React
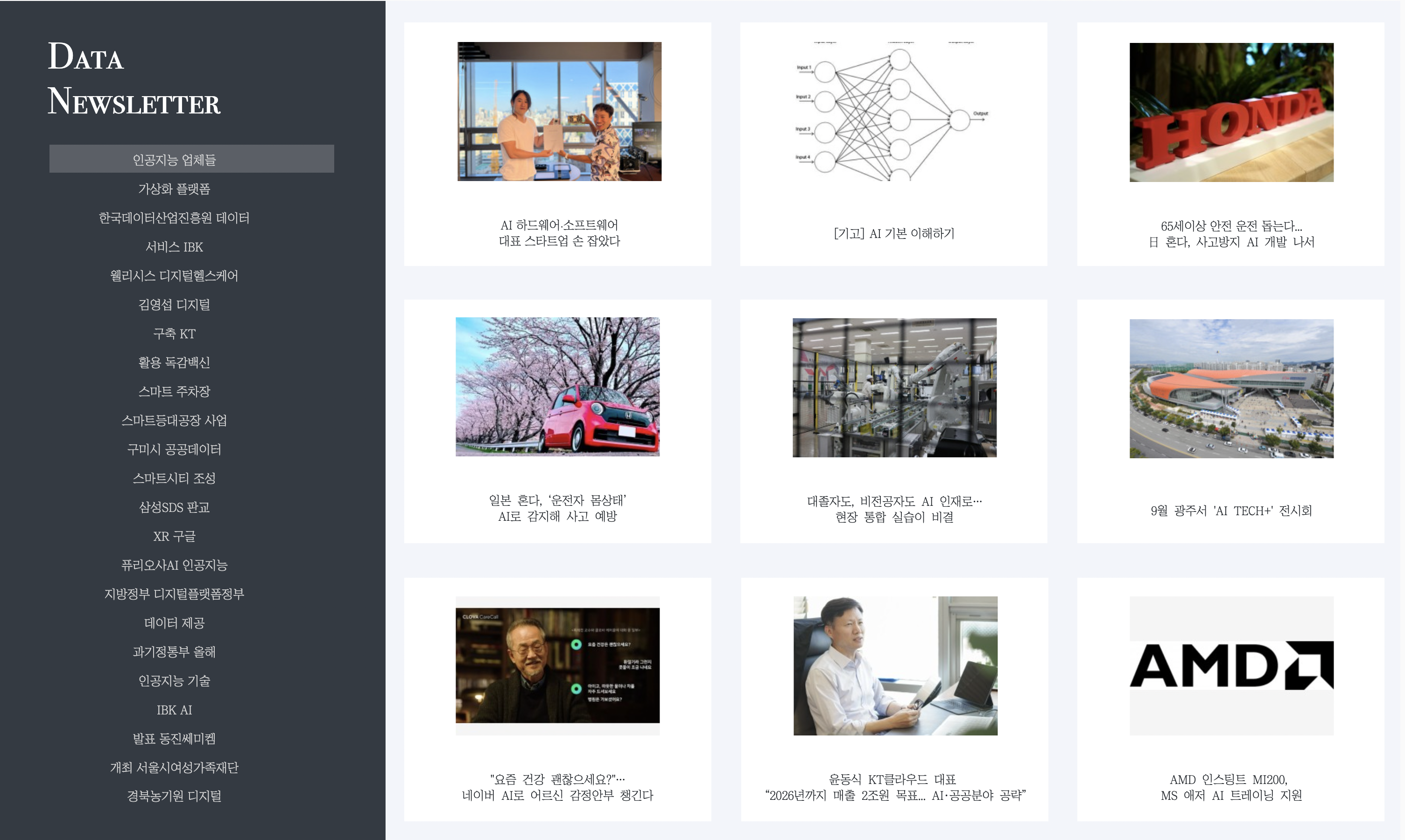
Tableau는 테이블 열을 웹 링크, 이미지 링크로 인식하지 못해 대시보드 제작에 오랜시간이 소요되었지만, 디자인 자유도가 높아 깔끔한 디자인의 데이터 뉴스레터 대시보드를 제작할 수 있었다. 키워드를 선택하면 관련된 뉴스 기사들이 나열되고, 기사 이미지를 클릭하면 해당 기사 링크로 이동할 수 있도록 만들었다.
또한 리액트를 이용해 태블로 대시보드를 임베딩한 웹을 구현하여, 사용자에게 제공할 수 있는 형태로 완성하였다.


와 클러스터링 하는데에서 끝나지 않고 이용해서 웹 대시보드까지 구현한 점이 인상깊네요..! 자극 받고 갑니다