[CS231N] Lecture 02 : Image Classificaion pipeline
Contents
Image Classification 이란?
- 데이터 중심 접근 방법 (Data-Driven Approach)
- Nearest Neighbor (NN)
- K-Nearest Neighbors
- Linear Classification (선형 분류)
Image Classification 이란?
- 이미지를 분류하는 것
- 이미지가 입력되면 시스템에서 미리 label해놓은 분류된 이미지 집합 중, 어디에 속할지 컴퓨터가 판단하는 것.
- 하지만 기계는 사람과 달리 정밀 분류가 힘들다.
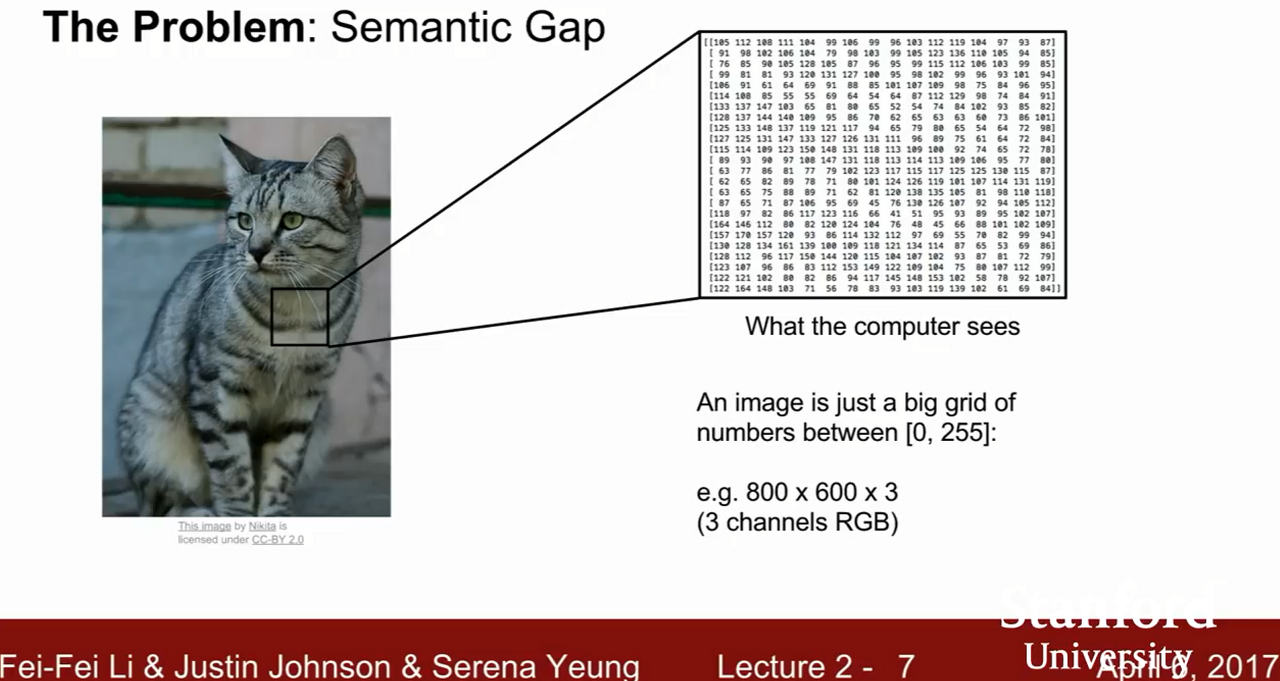
- 위 사진과 같이 기계는 고양이 사진을 입력 받으면
- RGB(Red, Blue, Green)값을 기준으로 격자 모양의 숫자들을 나열하여 인식한다.
- 하지만 기계는 카메라 각도나 밝기, 객채의 행동 혹은 가려짐 등 여러차이로 인해 이미지의 픽셀 값이 달리 읽어 사물을 다르게 인식.
=> 따라서, 이 문제를 해결하기 위해 새롭게 등장한 방법이 데이터 중심 접근 방법 (Data-Driven Approach) 이다.
1. 데이터 중심 접근 방법 (Data-Driven Approach)

1. 객체의 특징을 규정하지 않음.
2. 다양한 사진들과 label을 수집.
3. 이를 이용해 모델을 학습해 사진을 새롭게 분류하는 방식.
2. Nearest Neighbor (NN)
- 입력받은 데이터를 저장한 후 -> 새로운 데이터 들어오면 -> 기존 데이터에서 비교해 -> 가장 유사한 데이터를 찾아내는 방식.
- 강의에서는 CIFAR-10 (10가지 종류의 물체와 동물을 모은 사진 데이터 셋)데이터를 사용
-
기계가 어떻게 이미지를 비교하고 입력과 비슷한 이미지를 찾아낼까?
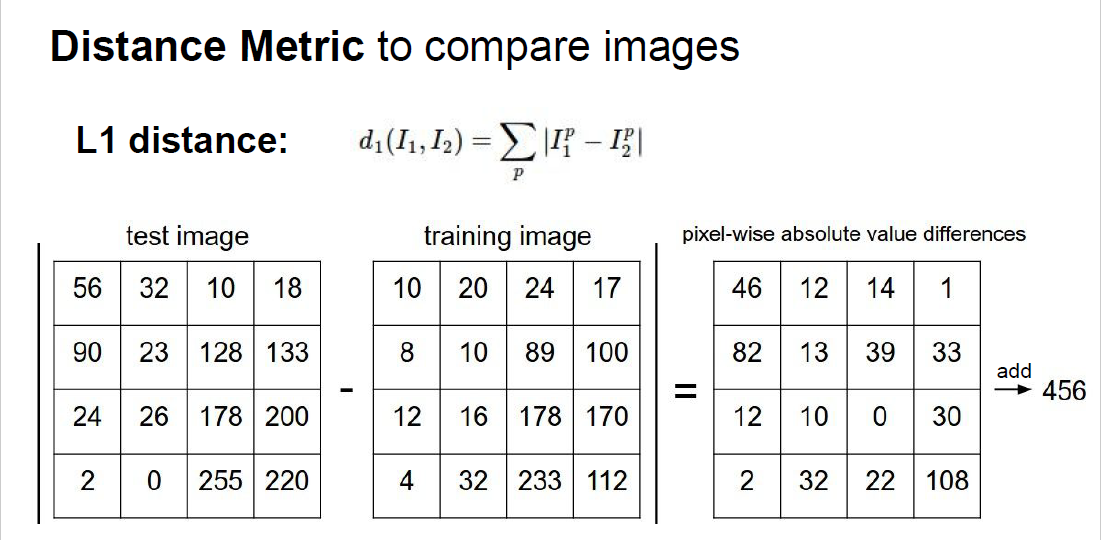
=>Distance Metric공식을 통사용. -
이 방법은 이미지는 pixel-wise로 비교하는데
-
test 이미지의 픽셀값에서 train 이미지의 픽셀값의 차를 구하고 절대값을 취함.
-
다음 각 픽셀 값을 모두 더해 하나의 출력값으로 만든다.
[단점]
- 모든 사진의 픽셀값을 계산하기 때문에
- 예측 과정 시간 소요가 큼
- 이를 보완하기 위해 K-Nearest Neigbor 나옴
3. K-Nearest Neighbors

-
distance mertic를 이용해서 가까운 이웃을 k개 만큼 찾고
-
이웃 간 투표해 득표 많이 얻은 label로 예측하는 방법.
-
가까운 이웃이 존재하지 않으면 흰색으로 표기
-
KNN을 사용하려면 학습 전 사전에 K와 거리 척도인 하이퍼 파라미터를 설정해야함.
-
하이퍼 파라미터 선택법은 preoblem-dependant(문제 의존적) 이므로, 여러 시도 후 성능 좋은 것을 선택한다.
-
일반적으로 데이터를 train,validation,test로 나누어 학습하고 예측하는 방법과, Cross vaildation(교차검증)이 있다.
-
교차 검증은 작은 데이터에 사용하며 딥러닝에는 많이 사용하지 않는다.
3.1) Distance Metric
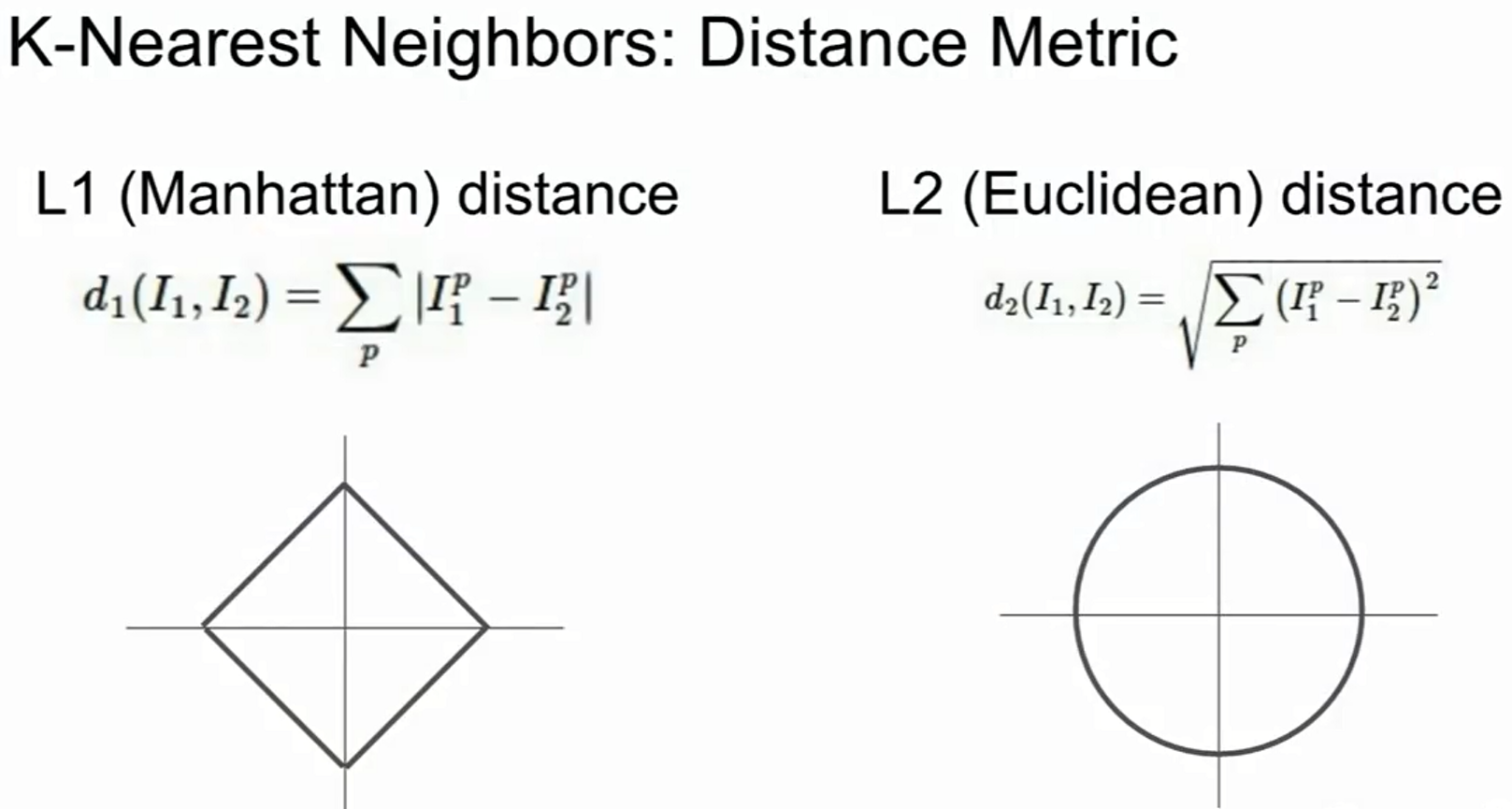
1. 맨해튼 거리 (Manhattan distance) : L1 distance
- 좌표계 회전 시 거리 값이 달라짐
- 유클리디안 거리 (Euclidean distance) : L2 distance
- 좌표계 회전 시 영향 받지 않음
4. Linear Classification (선형 분류)
- Neral Network(NN)과 Convolution Neral Network(CNN) 기반 알고리즘
- NN을 구축할 때 다양한 컴포넌트를 사용할 수 있는데
- 이 컴포넌트를 한 데 모아 CNN을 이루게 된다.
- 이 방법은 Nearest Neighbor보다 효율적이고 빠름
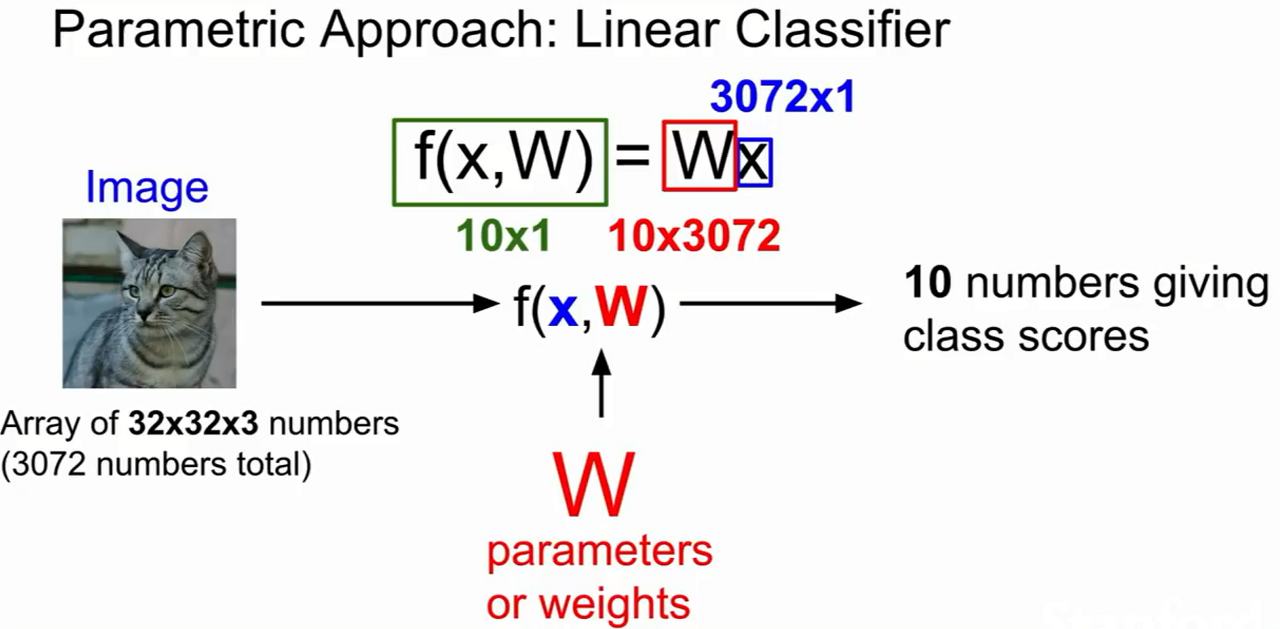
ex) 고양이 사진 (32x32x3)을 예시로 입력(X) 받음
-> 가중치 파라미터 (W)와 곱하여
-> 카테고리 score 값 (f(x,w))인 10을 만듦.
- score 값이 높을 수록 고양이일 확률이 높음.
bias(편향값)
- W * x 에 bias(편향값)을 더하는데,
- bias는 입력과는 직접적 관계를 가지지 않으나
- 이미지 라벨의 불균형한 상태 보완 위해 사용된다.
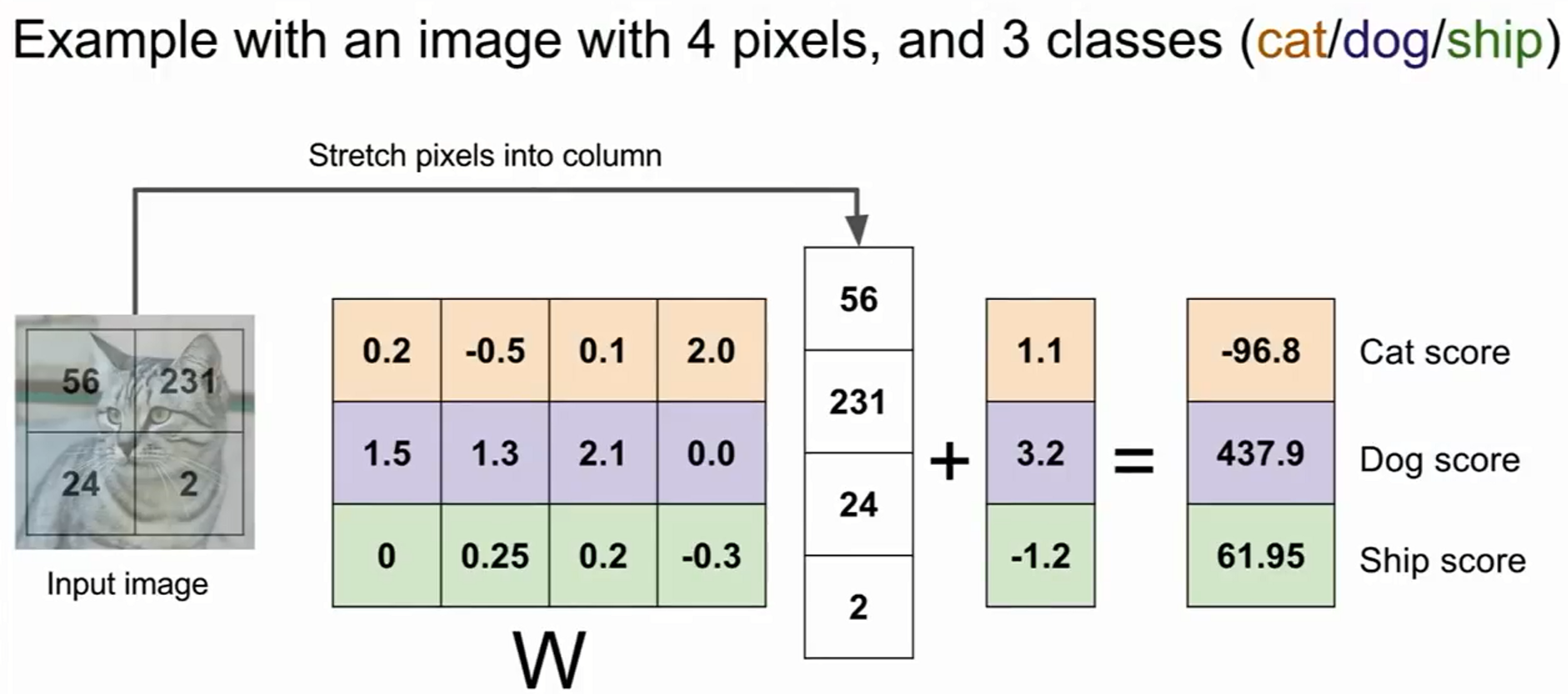
- 입력으로 2*2 형태 고양이 사진을 받으면, linear classifier는 4-dim 열 형태로 퍼지게 됨.
- 그리고 각각의 가중치(W)와 입력 이미지의 값(X)들의 내적한 값(클래스 간 템플릿 유사도를 측정한 값)에 bias를 더하면 score 값이 구해짐.
Multimodal problem (가중치 설정의 필요성)
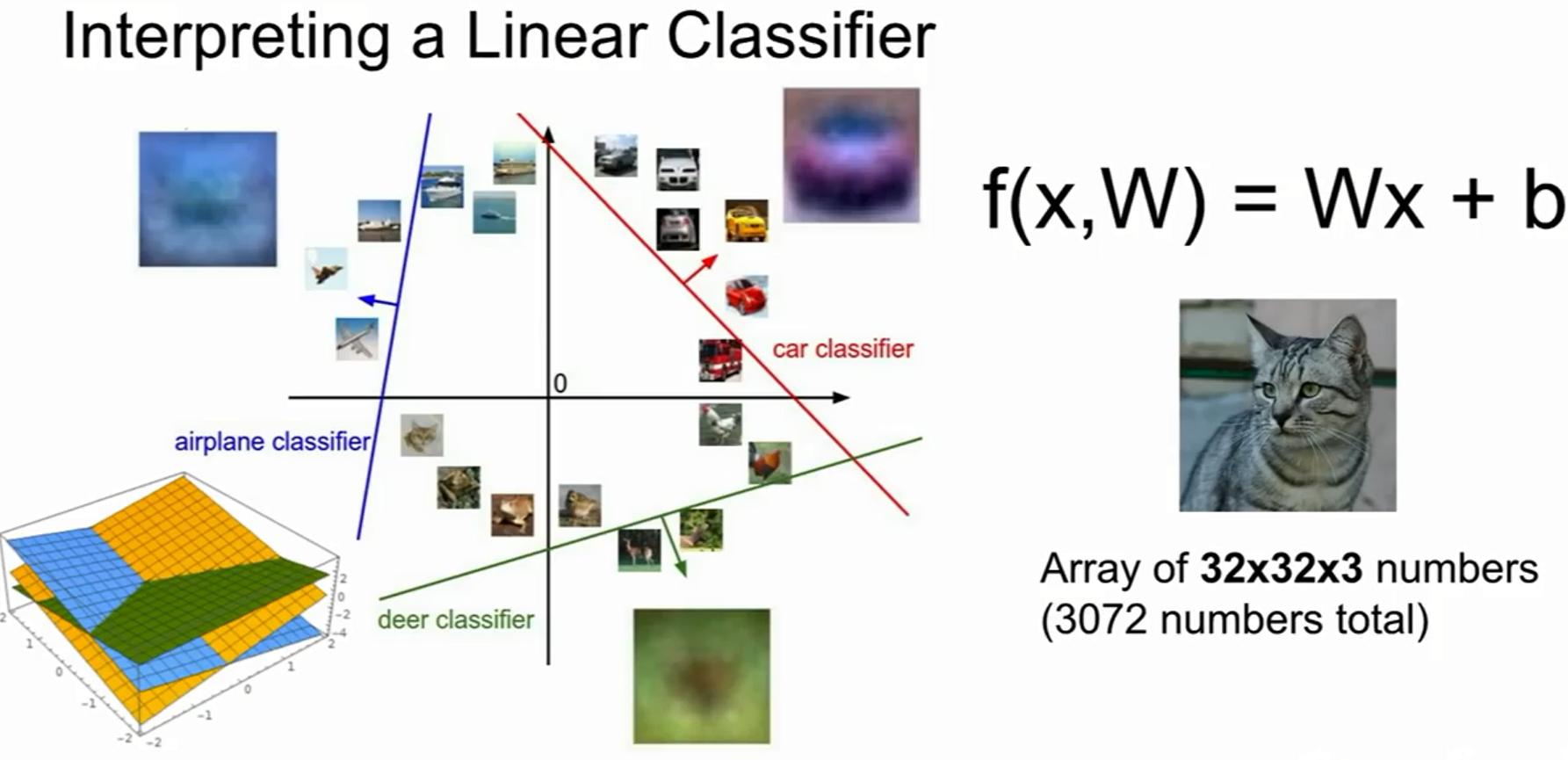
- 이미지를 고차원 공간으로 보게 되면, Linear Classifier는 각 클래스를 구분해주는 선형 경계 역할을 하지만,
- 일차 함수 직선으로 분류되지 않은, 즉 데이터의 분포에 따른 선형으로 분류할 수 없는 데이터가 대부분이다 (Multimodal problem)
- 이러한 단점 보완을 위해 W 가중치 설정이 중요하며, 다음 강의부터 W를 설정할 방법을 알아볼 것이다.
Reference
