자료구조/알고리즘
1.스택/큐/재귀함수

탐색(Search)이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정 DFS와 BFS를 본격적으로 알아보기 전, 두가지의 자료구조를 먼저 살펴보자. 1. 스택 자료구조 : 먼저 들어 온 데이터가 나중에 나가는 형식의 자료구조 (입구와 출구가 동일한 형태) 👉
2.DFS/BFS
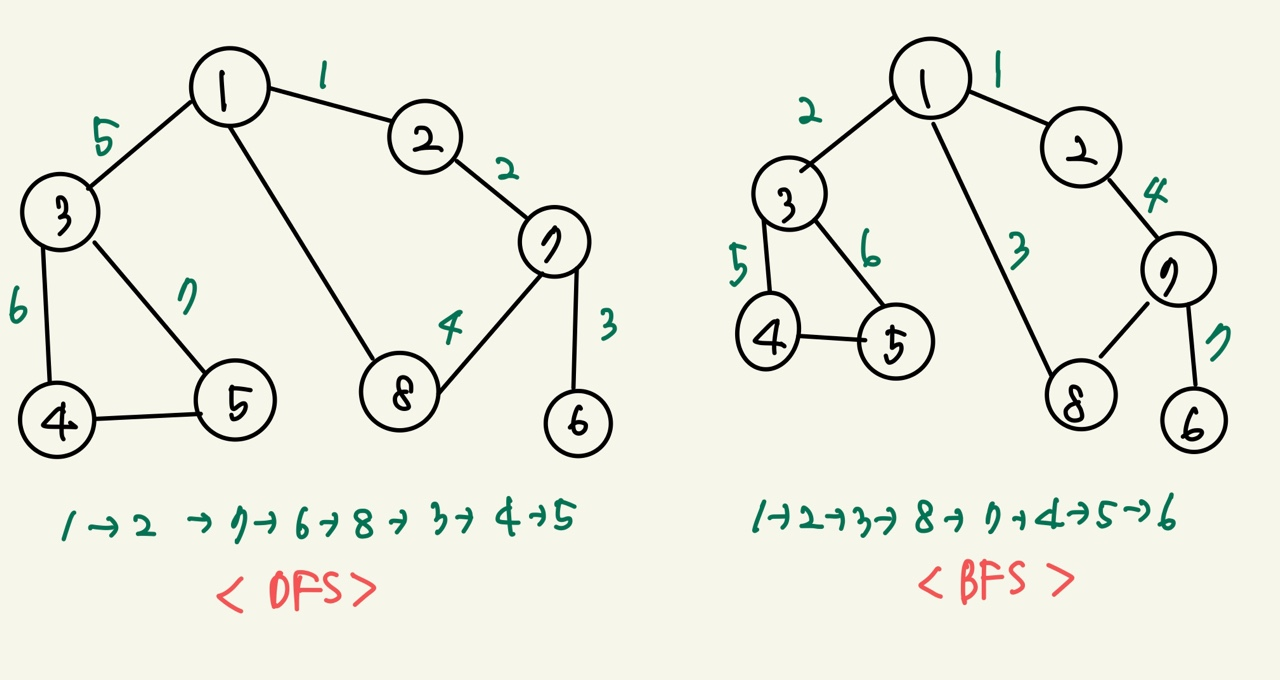
DFS(Depth-First Search) 깊이 우선 탐색이라고도 부르며 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘으로서 스택 자료구조(혹은 재귀함수)를 이용한다. 구체적인 동작 과정 1) 탐색 시작 노드를 스택에 삽입하고 방문 처리 2) 스택의 최상단 노드
3.구현
구현 :머릿 속에 있는 알고리즘을 소스코드로 바꾸는 과정구현 문제란? 1) 풀이를 떠올리는 것은 쉽지만 소스코드로 옮기기 어려운 문제2) 실수 연산을 다루고, 특정 소수점까지 출력해야 하는 문제3) 문자열을 특정 기준에 따라 끊어 처리해야 하는 문제4) 적절한 라이브
4.정렬 알고리즘
정렬(sorting) : 데이터를 특정한 기준에 따라 순서대로 나열하는 것. 👉 일반적으로 문제 상황에 따라서 적절한 정렬 알고리즘이 공식처럼 사용된다. : 처리되지 않은 데이터 중에서 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복 (현재 데이
5.다이나믹 프로그래밍
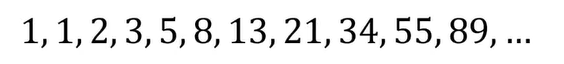
다이나믹 프로그래밍 : 메모리를 적절히 사용하여 수행 시간 효율성을 비약적으로 향상시키는 방법👉 이미 계산된 결과(작은 문제)는 별도의 메모리 영역에 저장하여 다시 계산하지 않도록 한다. 1) 최적 부분 구조 (Optimal Substructure): 큰 문제를 작
6.최단경로 알고리즘
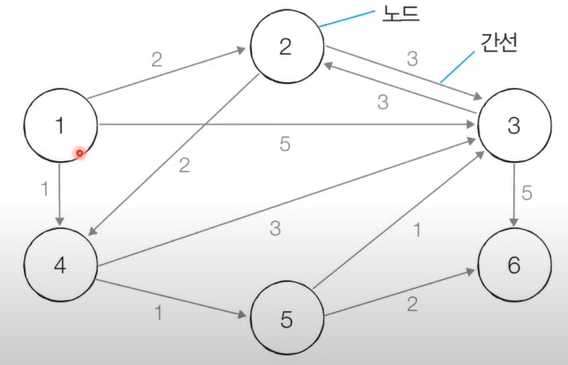
최단경로 알고리즘 : 가장 짧은 경로를 찾는 알고리즘 👉 다양한 문제 상황1) 한 지점에서 다른 한 지점까지의 최단 경로2) 한 지점에서 다른 모든 지점까지의 최단 경로3) 모든 지점에서 다른 모든 지점까지의 최단 경로 👉 각 지점은 그래프에서 노드로 표현하고, 지
7.서로소 집합 자료구조
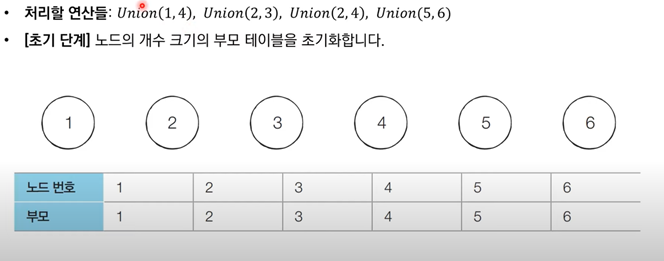
서로소 집합(Disjoint Sets): 공통 원소가 없는 두 집합📍 예시.{1, 2}와 {3, 4}는 서로소 관계이다.{1, 2}와 {2,3}은 서로소 관계가 아니다.1) 서로소 집합 자료구조서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조(합
8.신장트리와 위상정렬
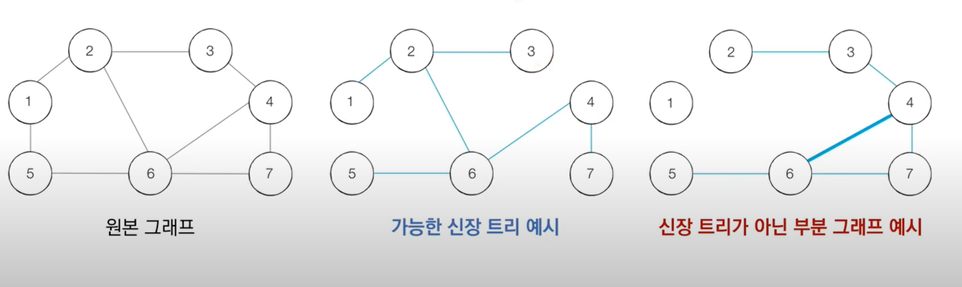
신장트리 : 그래프에서 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프 👉 신장 트리가 아닌 부분 그래프를 보면, 1번 노드는 연결되어 있지 않고, 사이클이 존재하기 때문에 신장 트리라고 할 수 없다.📍 예시. N개의 도시가 존재하는 상황에서 두 도시 사
9.이진탐색

이진탐색 : 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이진 탐색은 시작점, 끝점, 중간점을 이용하여 탐색 범위를 설정한다. cf) 순차 탐색 : 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 확인하는 방법✅ 시
10.공간복잡도

알고리즘을 공부하면서 시간복잡도에 대해선 익숙한데, 공간복잡도에 대해서는 거의 생각해보지 않았다. <문제> 길이 n의 수열을 입력하고 주어진 수 x보다 작은 값을 출력하라.\--> 수열을 모두 입력하고 배열에 다 넣은 다음, x와 비교할 때 : O(n)의 공간이
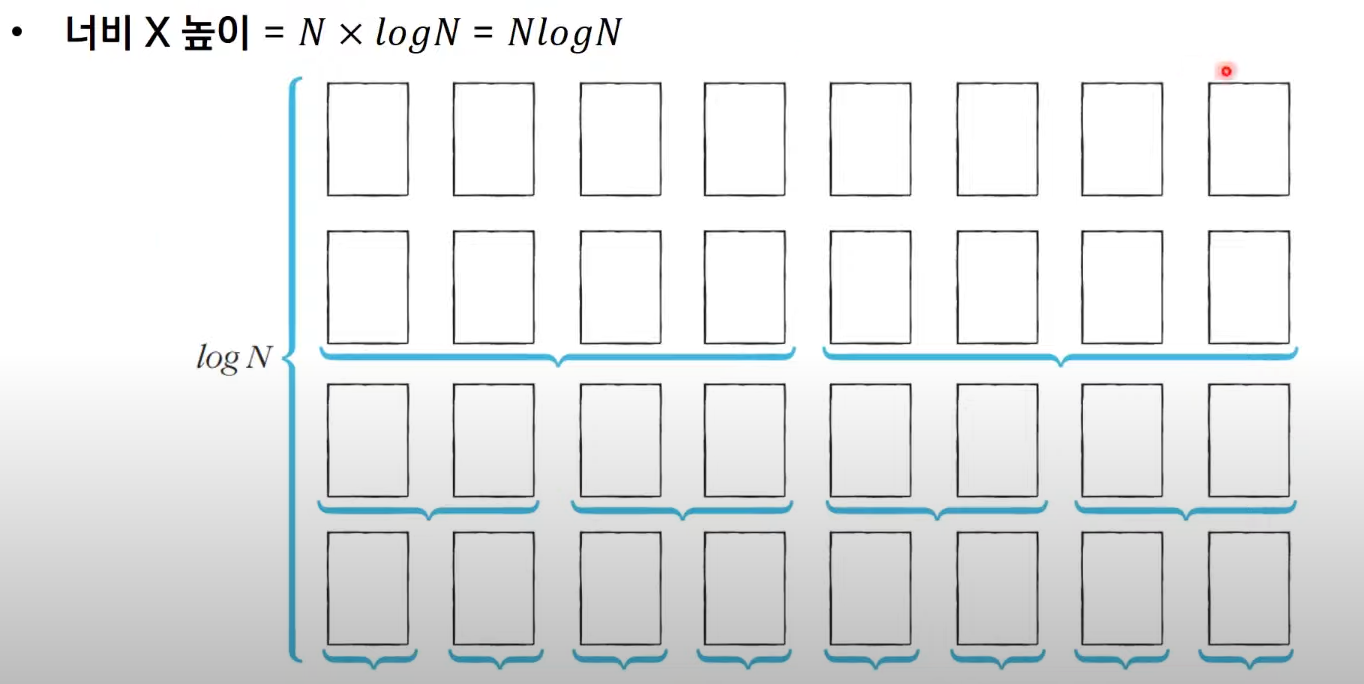
11.logn과 nlogn
이진 탐색 일때 => 반으로 쪼개면서 둘 중에 한 부분에서 원하는 값을 찾음.예. 8 --> 4 & 4 --> 2&2 / 2&2 --> 1&1/1&1 // 1&1/1&1👉 한 부분만 보는거니까 총 3번, 즉 $\\log{2}{8}$으로, O($\\log{}{n}$)이