🔎 Python을 이용하여 특정 웹 페이지의 원하는 요소를 추출해 보자
1. 타깃으로 잡은 웹 페이지와 추출할 데이터의 위치를 분석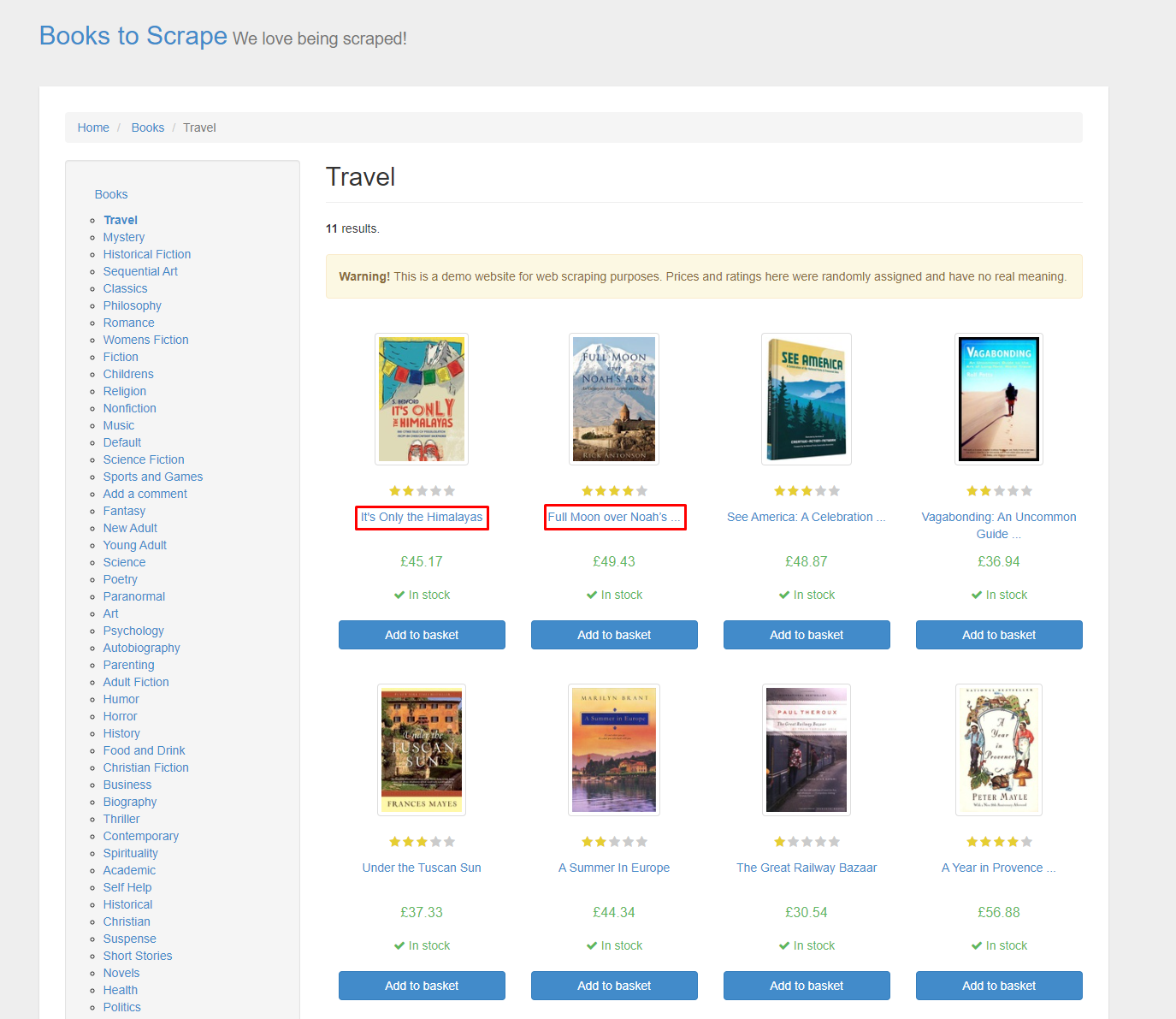
- 웹 페이지에서 추출할 요소의 위치를 찾는 방법은 두 가지가 있다.
개발자 도구(F12)를 이용해 직접 위치를 찾기.우 클릭 후 검사선택해서 찾아 주는 위치를 파악하기.
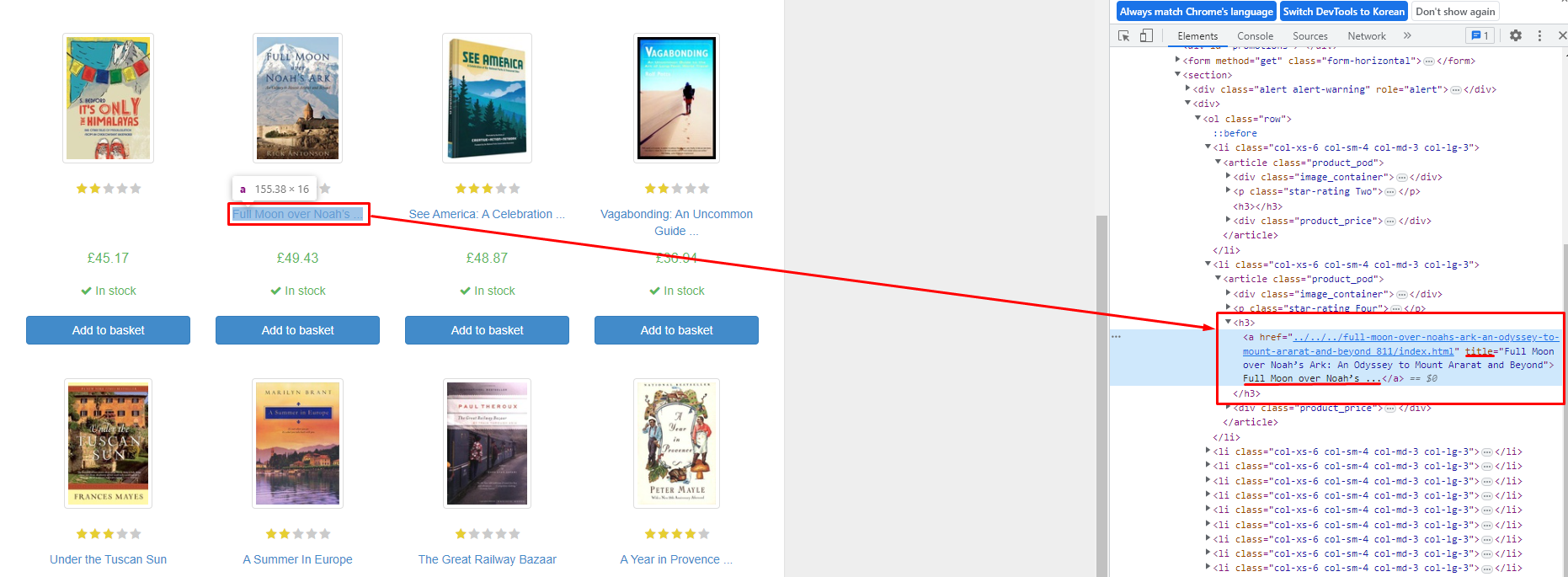
- 우리가 추출할 요소는
책들의 제목이기 때문에 제목에서우 클릭 후 검사를 눌러 주면 다음과 같이 웹 페이지HTML코드에서의 요소 위치가 뜨게 된다. - 이를 통해 우리가 추출해야 할 요소는
h3태그 안에 있으며a태그의context에는 화면상 보여 주는 일부 제목이 들어 있고title에는 전체 제목이 들어 있음을 알 수 있다.
2. 스크래핑 할 웹 페이지에 요청을 하고 응답을 바탕으로 객체를 생성
import requests
from bs4 import BeautifulSoup
res = requests.get("http://books.toscrape.com/catalogue/category/books/travel_2/index.html") #해당 사이트에 보낸 요청의 응답을 get
soup = BeautifulSoup(res.text, "html.parser") #BeautifulSoup을 통해 응답받은 HTML 정보를 분석하여 객체로 생성import requests: 웹 스크래핑을 할 웹 페이지에 요청을 보내고 응답을 받기 위해requests라이브러리를 호출한다.from bs4 import BeautifulSoup:HTML Parsing을 위한BeautifulSoup라이브러리를 호출합니다.request.get("웹페이지URL"):get을 통해 해당 사이트에 요청을 보낸 후 받은 응답을res라는 객체에 넣어 줍니다.BeautifulSoup(응답 TEXT, 파싱할 언어):res의text값을html.parser를 통해파싱해 줍니다.
3. 원하는 요소 찾기
- 1의 과정에서 우리는 추출해야 하는
책의 제목이h3태그 안에 있으며a태그의title이라는 것을 확인했다. - 찾고자 하는 태그의
제일 처음 등장하는 요소만 구하고자 할 때는find를 사용하며모든 요소를 구할 때는find_all을 사용해 준다. - 이후
find_all의 경우 여러 데이터가 출력돼list가 되기 때문에for문을 통해 추출해 준다.
book = soup.find("h3") # h3의 요소 하나만 추출하고자 할 때
books = soup.find_all("h3") #h3의 모든 요소를 추출하고자 할 때
print(book.a.text) #book은 하나의 요소만 추출한 것이기 때문에 그에 해당하는 context가 추출된다.
for bk in books:
print(bk.a["title"]) -
a 태그안에 있는context를 추출하고자 할 때는.text를 사용해 준다. -
a 태그안에 있는title을 추출하고자 할 때는Dictionary를 떠올리며key를title로 지정해 호출한다.# 결과 It's Only the Himalayas Full Moon over Noahâs Ark: An Odyssey to Mount Ararat and Beyond See America: A Celebration of Our National Parks & Treasured Sites Vagabonding: An Uncommon Guide to the Art of Long-Term World Travel Under the Tuscan Sun A Summer In Europe The Great Railway Bazaar A Year in Provence (Provence #1) The Road to Little Dribbling: Adventures of an American in Britain (Notes From a Small Island #2) Neither Here nor There: Travels in Europe 1,000 Places to See Before You Die

송의 개발 LOG