
📌 AWS RedShift의 벌크 업데이트 (Bulk Update)를 해 보자.
COPY명령을 통해raw_data스키마 밑 3 개의 테이블에 레코드를 적재하자.- 이때 레코드는 각 테이블에 상응하는
csv 파일이다. - 이 적재할 파일을
S3 bucket에 업로드해 주고Redshift가S3에 접근하여COPY명령을 통해 데이터를 적재하는 과정을 거쳐야 한다.
✍ 보통 벌크 업데이트 (Bulk Update)를 할 때는 csv 파일보다는 binary file format을 쓰게 된다.
1. raw_data 스키마 밑 테이블 생성
-
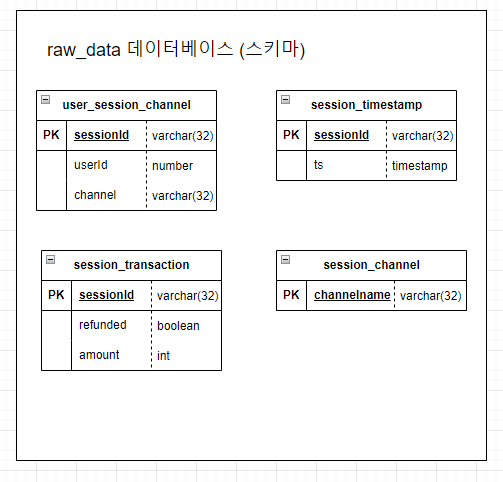
raw_data의 목적은 ETL을 통해 외부에서 읽어온 데이터를 저장한 스키마이다.
-
위의 raw_data 스키마를 참고하여 다음과 같이 총 세 개의 테이블을 생성해 준다.
- user_session_channel
- session_timestamp
- session_transaction
CREATE TABLE raw_data.user_session_channel(
USERID INTEGER
, SESSIONID VARCHAR(32) PRIMARY KEY
, CHANNEL VARCHAR(32)
);
CREATE TABLE raw_data.session_timestamp(
SESSIONID VARCHAR(32) PRIMARY KEY
, TS TIMESTAMP
);
CREATE TABLE raw_data.session_transaction(
SESSIONID VARCHAR(32) PRIMARY KEY
, REFUNDED BOOLEAN
, AMOUNT INT
);- 테이블의 생성 여부는
PG_TABLES을 조회해 주면 된다. - 특정 스키마 내부의 테이블만 확인하고 싶을 때는
WHERE절을 통해SCHEMANAME의 값을 설정해 주면 된다.
SELECT *
FROM PG_TABLES
WHERE SCHEMANAME = 'raw_data';
- 이를 통해
RAW_DATA스키마에 세 개의 테이블이 생긴 것을 확인할 수 있다.
2. 적재할 S3 bucket 생성 및 csv 파일 S3로 복사
COPY SQL을 통해 데이터를 적재해 주기 위해서는 csv를 S3에 업로드 해 주는 과정이 필요하다.- 그러기 위해서는 먼저
AWS콘솔에서S3 bucket을 생성해 주어야 한다.
1) S3 콘솔로 이동
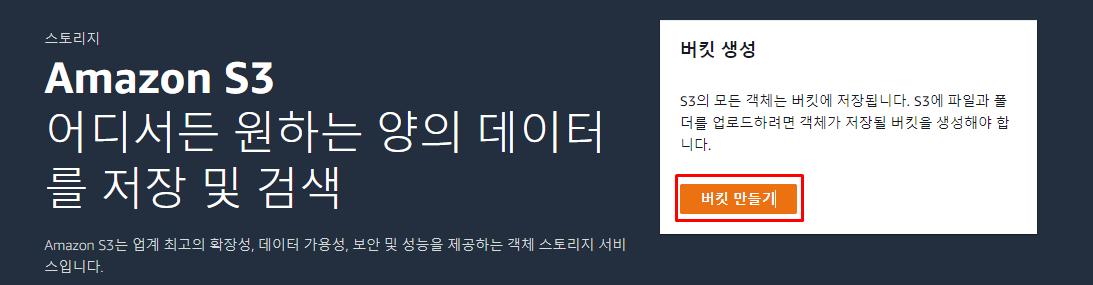
S3를 검색해서S3콘솔로 이동하면 다음과 같이버킷 만들기라는 버튼이 존재한다.- 이를 통해
버킷(bucket)을 생성해 주어야 한다.
2) 버킷 이름 설정

버킷(bucket)의 이름을 설정해 주어야 한다. 이때버킷(bucket)의 이름은 전역에서 고유한 값이어야 한다.
3) 기타 설정
- 그 외 설정인 객체 소유권, 이 버킷의 퍼블릭 액세스 차단 설정, 버킷 버전 관리, 기본 암호화는 모두 default로 설정해 주었다.
- 현재는 실습 단계이고, 단순하게 csv 파일 세 개만 업로드할 것이기 때문에 다음과 같이 진행한 것으로 보인다.
4) 버킷 생성

버킷(bucket)이 생성되면 다음과 같이 상단에 알림이 뜬다.
5) 폴더 만들기
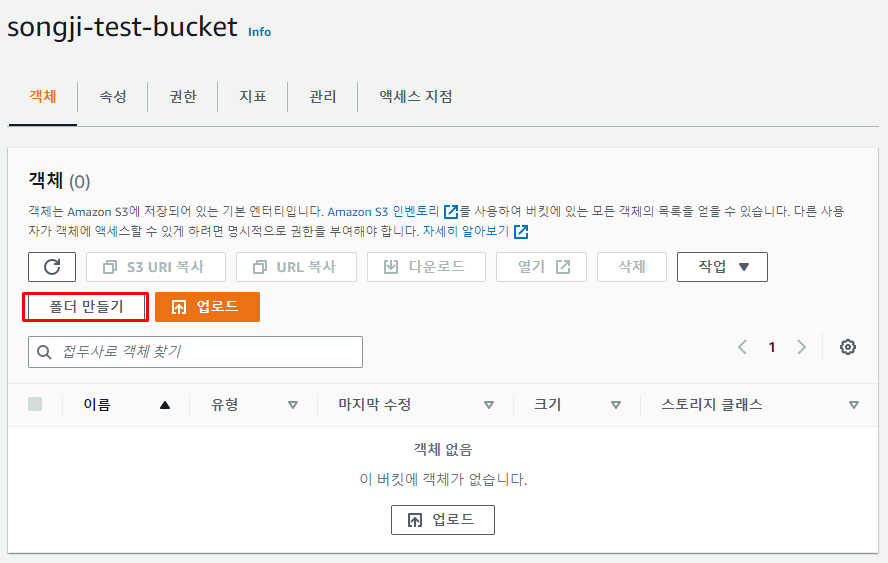
- 생성된
버킷(bucket)을 선택하고 내부로 들어가면 다음과 같은 상세 창이 뜬다. - 이때 csv 파일을 업로드 해 주기 위한
폴더를 생성해 보자.
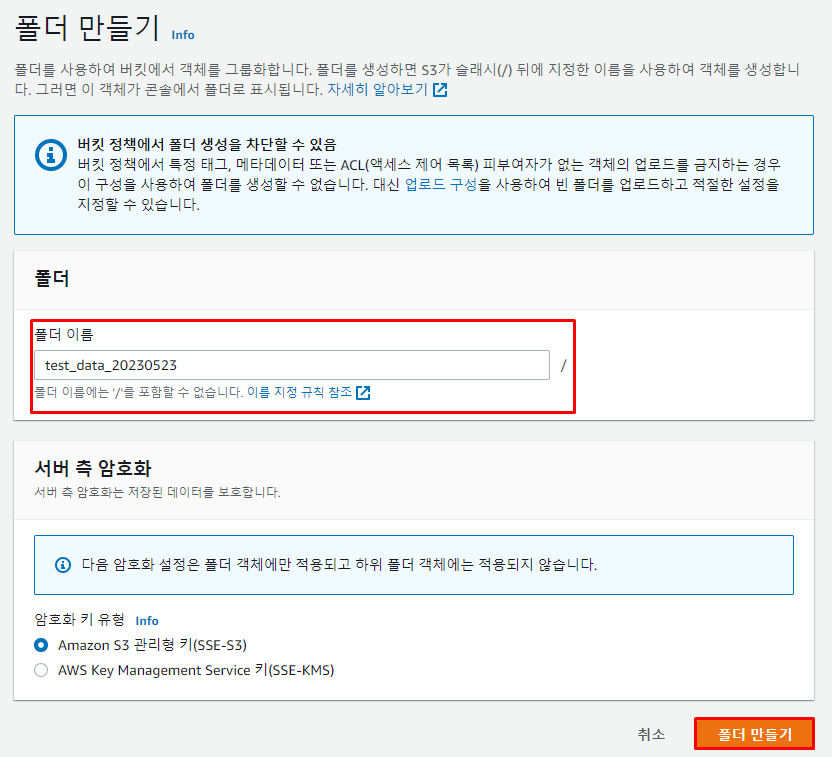
- 폴더명을 정해 주고, 다음과 같이
폴더 만들기버튼을 누른다.

- 이렇게 폴더가 생성된 것을 볼 수 있다.
6) 폴더에 csv 파일 업로드
- 해당 폴더에 들어와
업로드버튼을 눌러 준다.

- 파일 추가나 폴더 추가가 가능한데 드래그 앤 드롭으로도 파일 첨부가 가능하다.
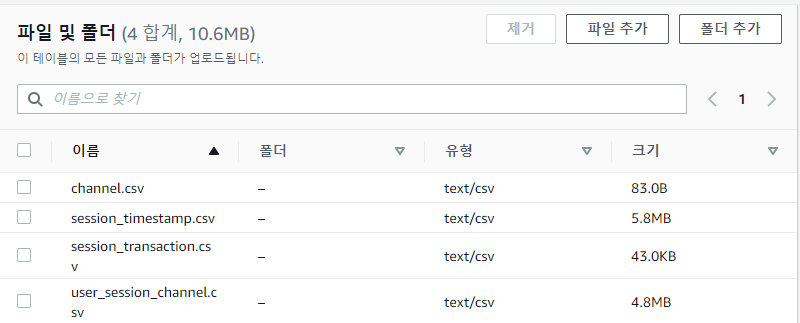
- 다음과 같이
csv 파일이 모두 올라갔다면 가장 하단에 있는업로드버튼을 눌러 업로드를 해 준다.

3. Redshift에 S3 접근 권한 부여
- Redshift가 S3에 접근할 수 있는 역할을
IAM (Identity and Access Management)을 통해 생성해 주어야 한다.
1) IAM 콘솔 접속
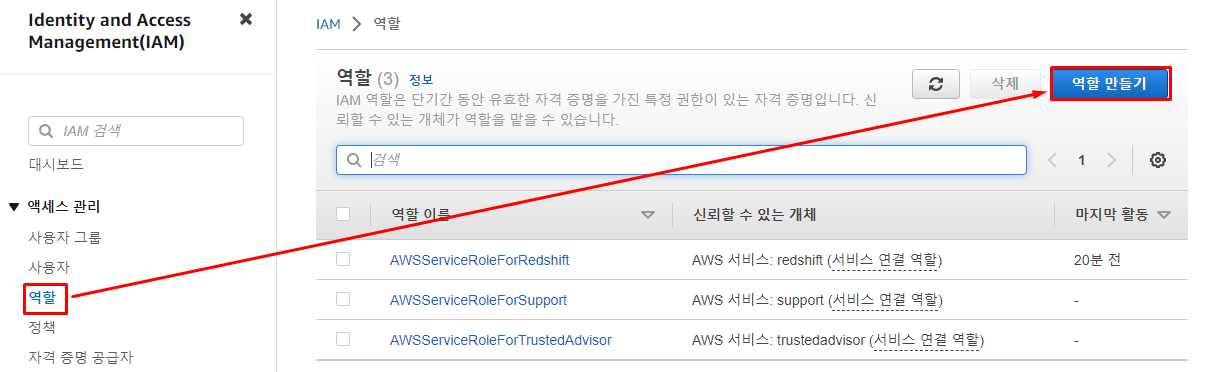
IAM 대시 보드에서역할을 선택해 주면 다음과 같이역할의 목록이 뜨게 된다.- 이때 우리는
S3에 대한 신규 역할을 생성해 줄 것이기 때문에역할 만들기버튼을 눌러 역할을 생성한다.
2) 신뢰할 수 있는 엔터티 선택

S3는AWS 서비스이기 때문에AWS 서비스를 선택해 준다.
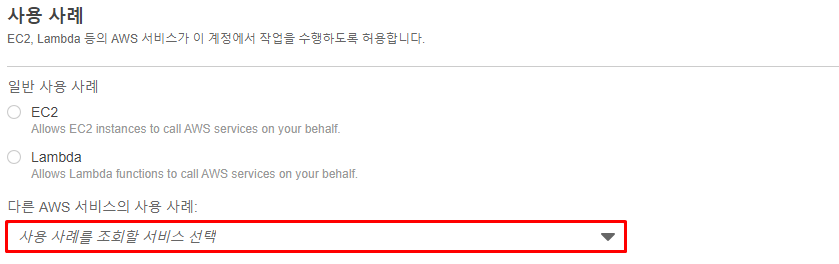
- 이후 하단의 사용 사례를 선택해 주어야 하는데 일반 사용 사례에
EC2와Lambda가 있는 것을 볼 수 있다.
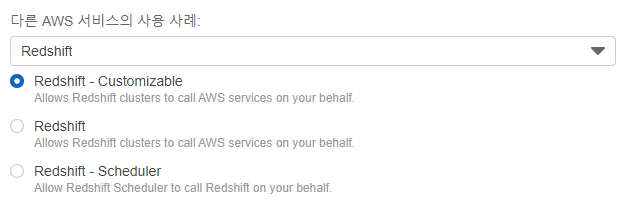
Redshift에서 사용할역할(Role)을 지정해 주는 것이므로 다른 AWS 서비스 사용 사례를Redshift로 지정해 준다.- 그러면 각각 선택한 서비스에 해당하는 사례가 추가적으로 뜨게 되는데
Customizable을 선택해 주었다.
3) 권한 추가
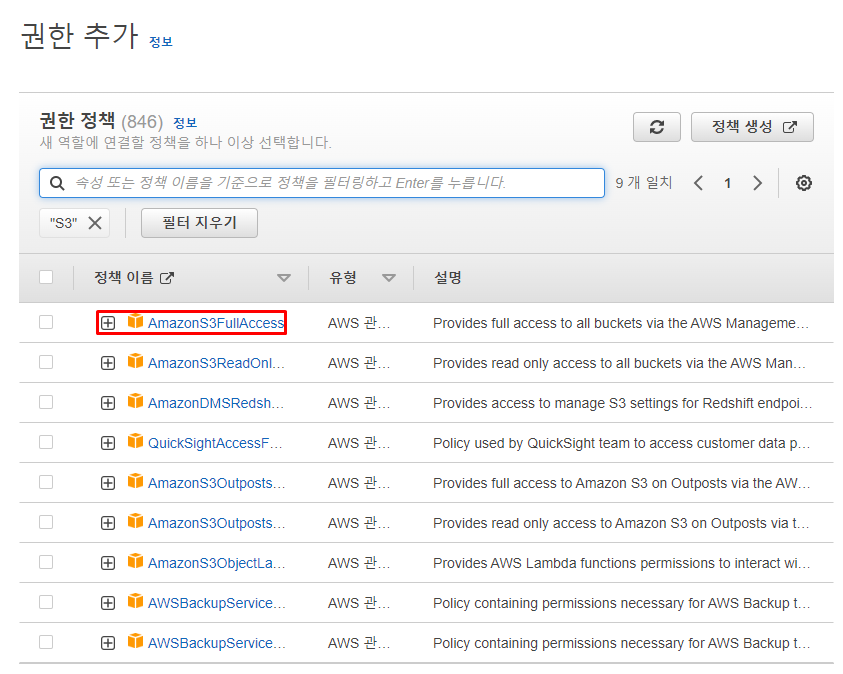
- 다음과 같이
IAM 역할(Role)에 부여할 수 있는 다양한 권한 정책이 나오게 된다. - 지금 필요한 것은
Redshift가S3에 대한 접근 권한을 갖는 것이므로S3를 검색해 주고 그와 관련된 정책을 찾아 준다. AmazonS3FullAccess는 S3의 모든 접근 권한을 주는 것인데 이를 선택하고 다음을 눌러 준다.
4) 이름 지정
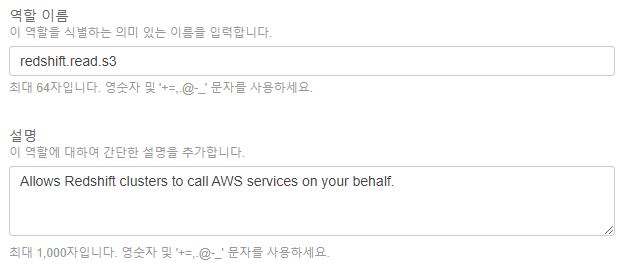
- 다음과 같이 새로 생성할
역할(Role)의 이름을 지정해 준다.
5) 엔터티 및 권한 검토 및 추가
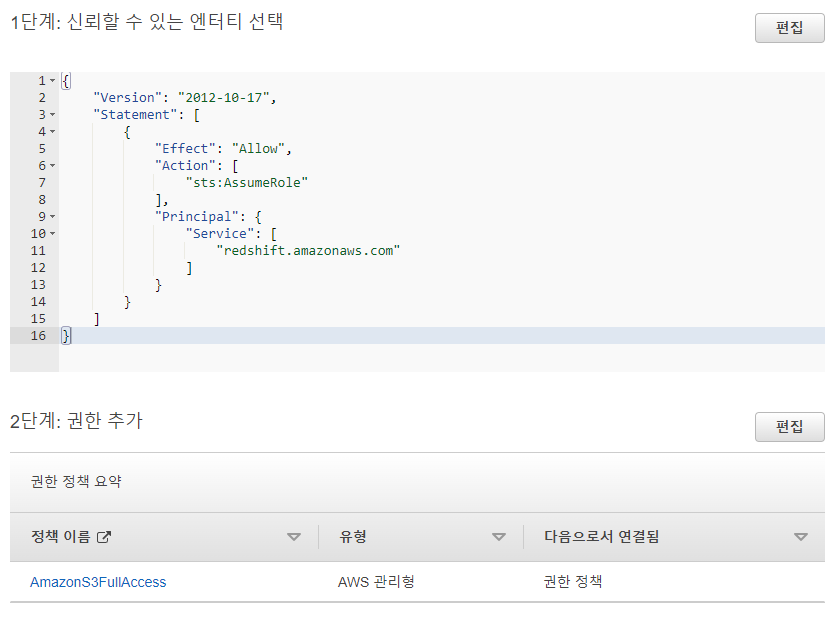
- 마지막으로 엔터티와 권한을 한 번 더 확인하고, 더 이상 추가할 것이 없다면
역할 생성버튼을 눌러 준다.
6) ARN 확인
- 다음과 같이 생성된
IAM Role을 클릭하면 상세 창이 뜨게 된다.
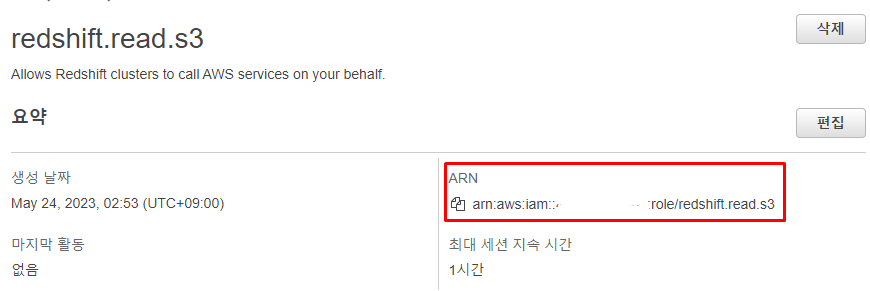
ARN의 위치는 다음과 같다.- 이후 필요하기 때문에 위치를 기억해 두는 것이 좋다.
7) Redshift에서 IAM role 부여
Redshift 대시 보드로 돌아가IAM 역할(Role)을 부여해 줄네임 스페이스를 선택해 준다.

보안 및 암호화에 권한을 보면IAM권한이 지정된 것이 없어 빈 목록임을 확인할 수 있다.
-IAM 역할 관리를 눌러 준다.
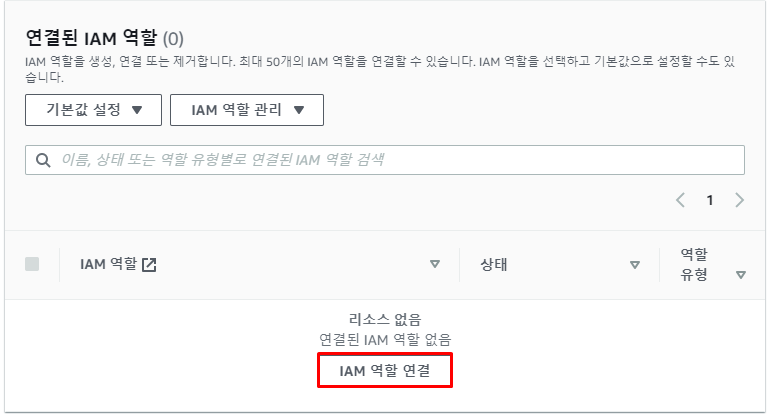
- 그러면 다음과 같이
IAM 역할 관리화면으로 넘어가게 되는데 이때IAM 역할 연결을 선택해 준다.

- 아까 만든
IAM 역할(Role)을 연결해 준 휘 변경 사항을 저장해 주면 이제Redshift는S3 bucket에 원하는 대로 접근 가능한 상태가 된 것이다.
4. COPY 명령을 사용해 CSV 파일을 테이블로 복사
COPY SQL사용한다. 📑 COPY 레퍼런스- csv 파일이기 때문에
delimiter(구분 문자)로는 콤마(,)를 사용해 준다. - 문자열이 따옴표로 둘러싸인 경우 제거하기 위해
removequotes를 지정해 준다. csv 파일의 헤더를 무시하기 위해IGNOREHEADER 1을 지정해 준다.CREDENTIALS에 앞서Redshift에서 지정한역할(Role)을 사용해 주는데 이때 역할의ARN을 읽어와야 한다.
COPY raw_data.user_session_channel
FROM 's3://s3의 csv 위치'
CREDENTIALS 'aws_iam_role=arn:aws:iam:xxxxxx:role/redshift.read.s3'
DELIMITER ','
DATEFORMAT 'auto'
TIMEFORMAT 'auto'
IGNOREHEADER 1
REMOVEQUOTES;- 제대로 COPY가 되었는지 데이터를 보기 위해
raw_data.user_session_channel의 데이터 값을 조회해 본다.
SELECT *
FROM raw_data.user_session_channel
LIMIT 10;
- 다음과 같이 데이터가 잘 저장된 것을 볼 수 있다.

송의 개발 LOG