REDSHIFT
1.[AWS RedShift] 1. AWS RedShift 개념

RedShift 사용에 앞서 짧게 RedShift란 무엇인가에 대해 정리해 보았다.AWS에서 제공하는 클라우드 기반의 완전 관리형 데이터 웨어하우스 서비스이다. PetaByte 규모의 데이터까지 처리할 수 있다.PostgreSQL을 기반으로 두고 있어 표준 SQL을 이
2.[AWS RedShift] 2. AWS RedShift Cluster 생성

데이터 웨어하우스 실습을 위해 AWS RedShift를 사용하기로 하였다.AWS 홈페이지에 접속해 콘솔에 로그인을 해 준 후 Amazon RedShift 창으로 접속해 준다.이때 상단의 검색창을 이용해 ¹직접 RedShift를 검색하거나 다음과 같이 ²서비스 메뉴를 통
3.[AWS RedShift] 3. 구글 Colab을 통해 RedShift 데이터 조회 (SQL)

실습에서 사용하게 될 RedShift의 스키마이다. user_session_channel이라는 사용자의 세션 정보를 담고 있는 테이블과 session_timestamp라는 각 세션의 시간을 담고 있는 테이블로 이루어져 있다. SQL문을 통해 이 테이블에 저장되어 있는
4.[AWS RedShift] 4. AWS RedShift Serverless 생성

먼저 고정 비용 옵션인 Redshift 더 이상 프리 티어를 제공하지 않기 때문에 프리 티어를 원하면 가변 고정 옵션인 Redshift Serverless를 사용해야 한다.이때 프리 티어 대상인지 아닌지 확인해 주기 위해 Redshift Serverless 대시 보드를
5.[AWS RedShift] 5. SQL로 Redshift 초기 설정
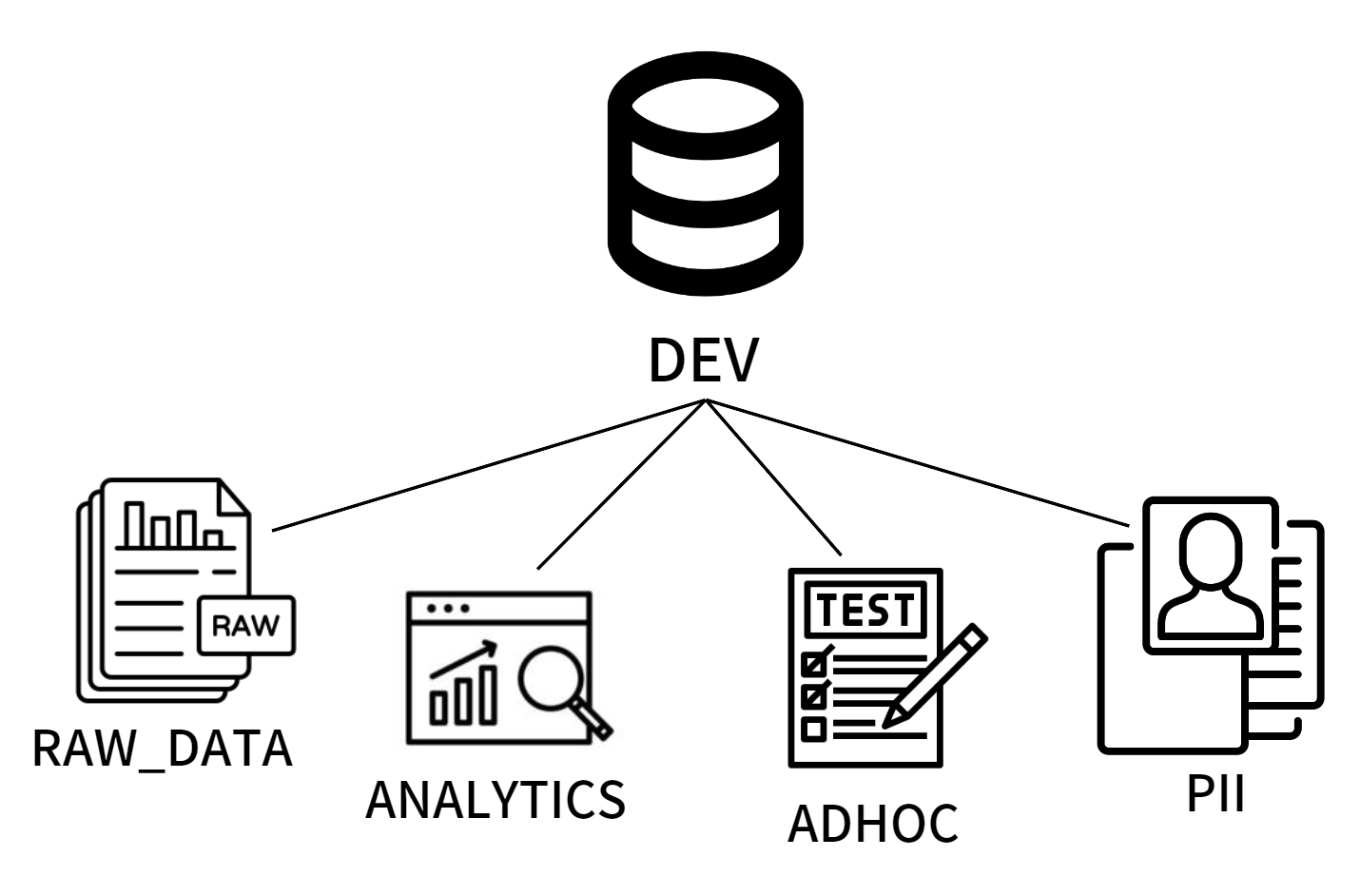
먼저 DEV라는 Redshift의 데이터베이스 안에 네 개의 스키마를 생성한다. (스키마의 목적은 내부에 있는 테이블의 목적이 무엇인지를 속한 스키마만 보고도 파악할 수 있도록 해 주는 것)RAW_DATA는 ETL의 결과가 들어가는 스키마 ANALYTICS는 ELT의
6.[AWS RedShift] 6. 벌크 업데이트 (Bulk Update) 구현

COPY 명령을 통해 raw_data 스키마 밑 3 개의 테이블에 레코드를 적재하자.이때 레코드는 각 테이블에 상응하는 csv 파일이다. 이 적재할 파일을 S3 bucket에 업로드해 주고 Redshift가 S3에 접근하여 COPY 명령을 통해 데이터를 적재하는 과정
7.[AWS RedShift] 7. 그룹(GROUP) 권한 부여

초기 설정에서 생성해 준 스키마와 역할을 활용해서 다음과 같이 역할에 스키마 읽기, 쓰기 권한을 부여해 보자.\[AWS RedShift] 5. SQL로 Redshift 초기 설정 - 이전 포스트 참고보통 권한을 부여할 때는 역할 혹은 그룹별 스키마별로 권한을 부여한다.
8.[AWS RedShift] 8. Redshift Spectrum으로 S3 외부 테이블 조작

먼저 이전 포스트에서 만든 redshift.read.s3 역할(role)에 추가적으로 AWSGlueConsoleFullAccess 권한을 주어야 한다.\[AWS RedShift] 6. 벌크 업데이트 (Bulk Update) 구현 - 이전 포스트 참고IAM 대시 보드에서