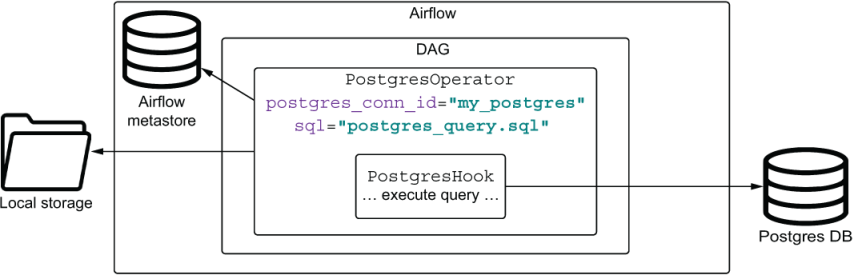
- 4 장은 다음의 DAG를 기준으로 진행된다.
- 위키피디아의 덤프 파일을
get_data를 통해 가지고 온 후extract_gz로 gz 파일의 압축을 풀어 준다. 이후fech_page_views를 통해 시간 단위의 페이지 뷰 수(조회 수)를 추출해 준다. - 외부 시스템인
postgres를 통해SQL 쿼리문으로 페이지별로 페이지 뷰 수를 INSERT 즉, 적재해 준다.
1. Airflow로 처리할 데이터 검사하기
1) 증분된 데이터 적재 방법 결정
-
어떤 종류의 데이터로 작업을 하든 다음 과정은 필수적이다.
-
파이프라인을 구축하기 전 접근 방식에 대한 기술적 계획을 세운다
- 이 데이터를 후에 다시 처리할지?
- 데이터를 어떻게 수신할지?
- 데이터로 무엇을 구축할지?
-
이 질문에 대한 답을 정하면 기술적 세부 사항에 대한 문제를 해결할 수 있다.
2) 위키미디어의 URL 형식
http://dumps.wikimedia.org/other/pageviews/{year}/{year}-{month}/pageviews-{year}{month}{day}{hour}0000.gz-
위키미디어의 덤프 url은 해당 링크에서 자세하게 확인할 수 있다. 🔗위키미디어 덤프
-
gz 압축 파일은 파일의 이름과 동일한 하나의 텍스트 파일을 포함하고 있다.
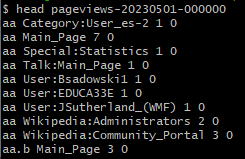
-
bash에 압축 파일의 내용을 확인하면 다음과 같은 목록이 추출된다.
-
gz 압축 파일 내부 텍스트 파일 구조
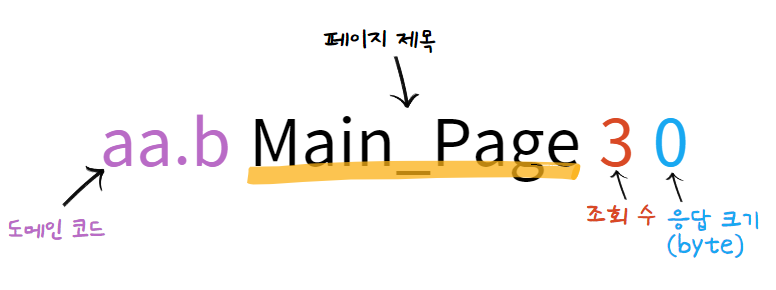
-
이렇게 직접 데이터를 분석해 보게 되면 우리가 사용하기 위해 가지고 와야 하는 데이터가 무엇인지를 파악할 수 있다.
-
페이지 제목별로 페이지의 조회 수를 데이터베이스에 저장해 주는 작업이기 때문에 날짜, 페이지 제목, 조회 수 정보가 필요한 것을 알 수 있다.
2. 태스크 콘텍스트와 Jinja 템플릿 작업
- 이 과정에서 DAG의 첫 번째 과정인
get_data를 진행해 준다. - 위키피디아의 페이지 뷰 수를 zip 파일로 다운로드 하는 것을 한 시간 주기마다 진행해 주는 것이다.
http://dumps.wikimedia.org/other/pageviews/{year}/{year}-{month}/pageviews-{year}{month}{day}{hour}0000.gz- 이때 다음과 같이 모든 주기의 URL에 날짜와 시간을 입력해야 하는데 이 과정에는 다양한 방법이 있지만
BashOperator와PythonOperator두 가지 방법으로 진행하였다. - Operator의 유형이 달라지더라도 런타임 시 변수를 삽입하여야 한다.
1) BashOperator
- 실행할 bash 명령을 제공하는 인수인
bash_command를 사용해 주어야 한다.
import airflow
from airflow import DAG
from airflow.operators.bash import BashOperator
dag = DAG(
dag_id="bash_test",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@hourly",
)
get_data = BashOperator(
task_id="get_data",
bash_command=(
"curl -o /tmp/wikipageviews.gz "
"https://dumps.wikimedia.org/other/pageviews/"
"{{ execution_date.year }}/"
"{{ execution_date.year }}-{{ '{:02}'.format(execution_date.month) }}/"
"pageviews-{{ execution_date.year }}"
"{{ '{:02}'.format(execution_date.month) }}"
"{{ '{:02}'.format(execution_date.day) }}-"
"{{ '{:02}'.format(execution_date.hour) }}0000.gz"
),
dag=dag,
)-
bash_command를 첫 번째 태스크인get_data에 넣어 준다. -
런타임 시작 시 변수를 삽입하고 이중 중괄호가 끝내야 한다. 이때 이중 중괄호는
Jinja 템플릿 문자열이고,Jinja는 런타임 시에 템플릿 문자열의 변수와 and, or 표현식을 대체하는 템플릿 엔진이다. -
프로그래밍 시에는 알 수 없는 사용자로부터 입력받은 값들을 런타임 시에 할당하고 삽입할 때 사용한다.
"{{ execution_date.year }}/"- 지금 코드를 보게 되면
execution_date는 실행한 날짜인데 이 값은 프로그래밍 시에는 알 수 없고 DAG의 태스크가 실행되면서 알 수 있게 된다. 이런 경우Jinja 템플릿을 써 준다고 생각하면 된다.
"{{ '{:02}'.format(execution_date.hour) }}0000.gz"-
이때 Airflow에서는 날짜 타입을 Datetime의 Datetime을 쓸까?
Airflow에서는Pendulum의datetime객체를 사용한다.- 값은
datetime을 썼을 때와 동일한 결과를 얻을 수 있다. Pendulum의datetime은 네이티브 파이썬의datetime의 호환 객체이기 때문에 네이티브 파이썬의datetime에서 사용하는 모든 메소드를 사용할 수 있다.
-
{{ '{:02}'.format(execution_date.hour) }}- 위키피디아의 페이지 뷰 URL은 빈 앞자리를 0으로 채우는 월, 일, 시간 값이 필요하다.
- 예를 들어, 오전 7 시는 07, 8 시는 08 이렇게 출력되어야 한다.
Jinja 템플릿 문자열내에서 이런 패딩 문자열 형식을 적용 가능하다.
✍ curl (Client URL)로 지원하는 프로토콜들을 이용해 서버에 데이터를 보내거나 가져올 때 사용하는 도구이다.
📌 어떤 인수가 템플릿으로 지정될까? 또 템플릿화를 위해 사용할 수 있는 변수는 무엇일까?
- 오퍼레이터의 인수 중 템플릿으로 만들 수 있는 인수가 정해져 있고, 템플릿으로 만들 수 있는 속성의 허용 리스트가 존재한다.
- 만약 속성 리스트에 포함되지 않는 인수라면 문자열 그대로 해석이 된다. 예를 들어
name이라는 속성이 템플릿으로 허용되지 않는 인수라면{{ name }}을 작성해도 입력 값이 들어가는 게 아닌 그대로{{ name }}으로 출력이 되는 것이다.
🔗 template_fields 목록
- 그렇다면 템플릿화를 위해 사용할 수 있는 변수는 무엇이 있을까. 이 변수들을
태스크 콘텍스크(Task context)라고 부르게 된다.- 다음과 같이
PythonOperater를 사용하면 전체태스크 콘텍스크(Task context)를 출력할 수 있다.import airflow.utils.dates from airflow import DAG from airflow.operators.python import PythonOperator dag = DAG( dag_id="print_task_context_test", start_date=airflow.utils.dates.days_ago(3), schedule_interval="@daily", ) def _print_context(**kwargs): print(kwargs) print_context = PythonOperator( task_id="print_context", python_callable=_print_context, dag=dag )
2) PythonOperator
PythonOperator는BashOperator와 달리pyhton_callable인수를 사용하게 된다.Python은 함수가 주요 요소이고,pyhton_callable인수에callable을 제공한다. 이때callable이란 대상이 호출 가능한 객체인지 아닌지 확인해 주는 함수이다.
① 태스크 콘텍스트 및 키워드 인수 처리
a. 태스크 컨텍스트 변수를 통해 execution_date 추출
from urllib import request
import airflow.utils.dates
from airflow import DAG
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="python_test",
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@hourly",
)
def _get_data(execution_date):
year, month, day, hour, *_ = execution_date.timetuple()
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
output_path = "/tmp/wikipageviews.gz"
request.urlretrieve(url, output_path)
get_data = PythonOperator(task_id="get_data", python_callable=_get_data, dag=dag)- 다만 문자열이 아니라 함수이기 때문에 함수 내의 코드를 자동으로 템플릿화할 수는 없지만 태스크 컨텍스트 변수를 제공하기 때문에 이를 이용할 수 있다.
b. 키워드 인수를 통해 execution_date 추출
- 파이썬에서는 키워드 인수를 받을 수 있는데 이 키워드 인수가 태스크 콘텍스트라는 것을 표현해 주기 위해
context라고 작성해 준다. 이렇게 작성을 해 주게 되면 모든 콘텍스트 변수가 키워드 인수로 들어가게 된다. - 이를 바탕으로
execution_date와next_execution_date를 출력하는 코드를 작성해 본다면 다음과 같다.
import airflow.utils.dates
from airflow import DAG
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="python_context_test",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
)
def _print_context(**context):
start = context["execution_date"]
end = context["next_execution_date"]
print(f"Start: {start}, end: {end}")
#Start: 2019-07-13T14:00:00+00:00, end: 2019-07-13T15:00:00+00:00
print_context = PythonOperator(
task_id="print_context", python_callable=_print_context, dag=dag
)c. 태스크 컨텍스트 변수와 키워드 인수를 통해 execution_date 추출
- 또 다른 방법은 인자에 키워드 인수와 함께 추출해야 할
execution_date변수를 알려 준다. 이때 키워드 인수보다 변수를 앞에 작성해야 하며execution_date변수에 값이 들어가게 되면 키워드 인수인context내부에는execution_date가 전달되지 않는다.
def _get_data(execution_date, **context):
year, month, day, hour, *_ = execution_date.timetuple()✍ 개인적으로 만약 두 개의 키워드 인수가 넘어간다면 어떻게 동작하게 될지 궁금했는데 다른 분이 해당 내용을 직접 airflow로 돌려 본 포스팅이 있었다. 만약 두 개의 키워드 인수 파라미터를 주게 되면 어떻게 될까?
② PythonOperator에 변수 제공
- 이제
get_data에서execution_date를 따로 추출해 주지 않아도output_path를 구성할 수 있다. - 태스크 컨텍스트 변수로
output_path를 넣어 주는 것이다.
def _get_data(output_path, **context):
year, month, day, hour, *_ = context["execution_date"].timetuple()
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
request.urlretrieve(url, output_path)- 이렇게 구성된 output_path는 두 가지 방법으로 제공될 수 있는데
op_args를 사용하는 방법과op_kwargs를 사용하는 방법이다. 전자는 변수로 제공이 되고, 후자는 키워드 인수로 제공이 된다. - 비교하자면
op_args = ["/tmp/wikipageviews.gz"],op_kwargs = {"output_path": "/tmp/wikipageviews.gz"}다음과 같이 각각 콜러블 함수에서 전달된다. - 다음 코드와 같이
datetime구성 요소를 따로 추출하지 않고 넘겨 줄 수도 있다.
from urllib import request
import airflow.utils.dates
from airflow import DAG
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="output_path_test",
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@hourly",
)
def _get_data(year, month, day, hour, output_path, **_):
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
request.urlretrieve(url, output_path)
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
op_kwargs={
"year": "{{ execution_date.year }}",
"month": "{{ execution_date.month }}",
"day": "{{ execution_date.day }}",
"hour": "{{ execution_date.hour }}",
"output_path": "/tmp/wikipageviews.gz",
},
dag=dag,
)3. 다른 시스템과 연결하기
- 먼저 2의 과정에서 받은 zip 형식의 파일을 압축을 풀어 스캔하고, 지정한 페이지 이름에 대한 페이지 뷰 수를 선택해 처리해야 한다. 이 과정이
fetch_page_views태스크에 해당한다. - 이를 처리해 주기 위해 키워드 인수를 통해 추출할 페이지 이름을 설정해 준다. 예시에서는
GOOGLE, AMAZON, APPLE, MICROSOFT, FACEBOOK를 추출해 주었다.
from urllib import request
import airflow.utils.dates
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="fetch_test",
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@hourly",
max_active_runs=1,
)
def _get_data(year, month, day, hour, output_path, **_):
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
request.urlretrieve(url, output_path)
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
op_kwargs={
"year": "{{ execution_date.year }}",
"month": "{{ execution_date.month }}",
"day": "{{ execution_date.day }}",
"hour": "{{ execution_date.hour }}",
"output_path": "/tmp/wikipageviews.gz",
},
dag=dag,
)
extract_gz = BashOperator(
task_id="extract_gz", bash_command="gunzip --force /tmp/wikipageviews.gz", dag=dag
)
def _fetch_pageviews(pagenames):
result = dict.fromkeys(pagenames, 0)
with open("/tmp/wikipageviews", "r") as f: #이전 태스크에서 작성한 파일 열기
for line in f:
domain_code, page_title, view_counts, _ = line.split(" ") #줄에서 필요한 요소 추출
if domain_code == "en" and page_title in pagenames: #페이지명이 정해진 페이지 이름인지 확인하고 view_counts를 value로 설정
result[page_title] = view_counts
print(result)
#output: "{'Facebook': '778', 'Apple': '20', 'Google': '451', 'Amazon': '9', 'Microsoft': '119'}"
fetch_pageviews = PythonOperator(
task_id="fetch_pageviews",
python_callable=_fetch_pageviews,
op_kwargs={"pagenames": {"Google", "Amazon", "Apple", "Microsoft", "Facebook"}},
dag=dag,
)
get_data >> extract_gz >> fetch_pageviews - 우리는 이렇게 딕셔너리 구조로 출력한 값을 외부 데이터베이스 예를 들어
postgres DB에 넣어 주어야 된다라고 한다면 먼저 테이블을 생성해 주고, 해당 테이블에 추출한 값을 INSERT 쿼리를 통해 삽입해 주어야 한다. - 이때
INSERT구문 작성은PythonOperator가 제공해 주지만 결과를 데이터베이스에 입력하기 위해서는XCom을 사용해 주거나영구적인 위치(디스크 또는 데이터베이스)에 저장해 주어야 한다. (XCom에 대한 설명은 5 장에 나온다고 함.) - 태스크 간 데이터를 저장하기 위해서는 데이터가 다시 사용되는 위치와 방법을 알아야 한다.
- 그래야 어떤 오퍼레이터를 사용할지 정할 수 있다. 현재는
postgres DB를 사용할 것이므로PostgresOperator를 이용해 데이터를 입력해 준다. PostgresOperator클래스를 가지고 오기 위해서는 다음 공급자 패키지를 설치해 주어야 한다.
pip install apache-airflow-providers-postgres✍ 왜 공급자 패키지를 설치해야 하는가?
- Airflow는 Airflow 생태계를 위해 다양한 오퍼레이터를 통해 광범위한 외부 시스템 연결을 지원한다.
- 외부 시스템과 연결하기 위해서는 종종 부가적인 구성 요소를 설치해야 연결 후 통신할 수 있다.
- 그래서 postgres의 경우 추가적인 의존성 해결을 위해 앞서 말한 공급자 패키지를 설치해 주어야 하고, 다른 외부 시스템 역시 연계하기 위해서 여러 의존성 패키지를 설치해야 한다.
- 오케스트레이션 시스템의 특성 중 하나이다.
- 이후 다음과 같이
PostgreOperator에 공급할 INSERT문을 작성한다.
def _fetch_pageviews(pagenames, execution_date, **_):
result = dict.fromkeys(pagenames, 0) #페이지 뷰에 대한 결과를 0으로 초기화
with open("/tmp/wikipageviews", "r") as f:
for line in f:
domain_code, page_title, view_counts, _ = line.split(" ")
if domain_code == "en" and page_title in pagenames:
result[page_title] = view_counts #페이지 뷰 저장
with open("/tmp/postgres_query.sql", "w") as f:
for pagename, pageviewcount in result.items(): #각 결과에 대한 SQL 쿼리 작성
f.write(
"INSERT INTO pageview_counts VALUES ("
f"'{pagename}', {pageviewcount}, '{execution_date}'"
");\n"
)
fetch_pageviews = PythonOperator(
task_id="fetch_pageviews",
python_callable=_fetch_pageviews,
op_kwargs={"pagenames": {"Google", "Amazon", "Apple", "Microsoft", "Facebook"}},
dag=dag,
)
get_data >> extract_gz >> fetch_pageviews- 이 작업을 실행하면 SQL 쿼리를 포함한 파일이 지정된 스케줄 간격으로 생성된다.
- 조금 헷갈렸던 부분인데 이 과정은
SQL 쿼리를 생성하는 부분이지 데이터를 직접적으로INSERT해 주는 부분이 아니다.
from airflow.providers.postgres.operators.postgres import PostgresOperator
write_to_postgres = PostgresOperator(
task_id="write_to_postgres",
postgres_conn_id="my_postgres",
sql="postgres_query.sql",
dag=dag,
) - template_searchpath란
Jinja를 사용할 때는 템플릿화할 수 있는 파일을 검색할 경로를 제공해야 하는데/tmp에 저장되면Jinja가 스스로 파일을 찾을 수 없다. 그래서 검색 경로를 추가하기 위해DAG에서template_searchpath의 인수를 주어 기본 경로와 추가 경로를 같이 탐색할 수 있게 해 준다. - 이렇게
PostgresOperator을 호출해 주어야 하고, 두 개의 인수를 넘겨 주어야 한다. postgres_conn_id는 Postgres 데이터베이스에 대한 자격 증명 식별자이고,sql은 실행할 sql 쿼리의 경로를 넣어 주면 된다.- 이 과정만 진행해 주면 데이터베이스 연결 설정, 완료 후 연결 끊기 등의 작업은 내부에서 자체적으로 처리해 준다.
✍ 내부에서는 어떻게 자체적으로 처리해 주게 될까?
PostgresOperator은 Postgres와 통신하기 위해훅(hook)을 인스턴스화한다.- 이
훅(hook)이 연결 생성, Postgres에 쿼리 전송 및 연결에 대한 종료 작업을 처리한다.- 오퍼레이터는 훅으로 사용자 요청을 전달하는 일만 한다.
- 오퍼레이터는 무엇을 해야 할지 결정하고 정한 무엇을 어떻게 해야 할지 결정한다.
- 그림에서 보는 것과 같이 훅은 Operator 내부에서 동작한다.