
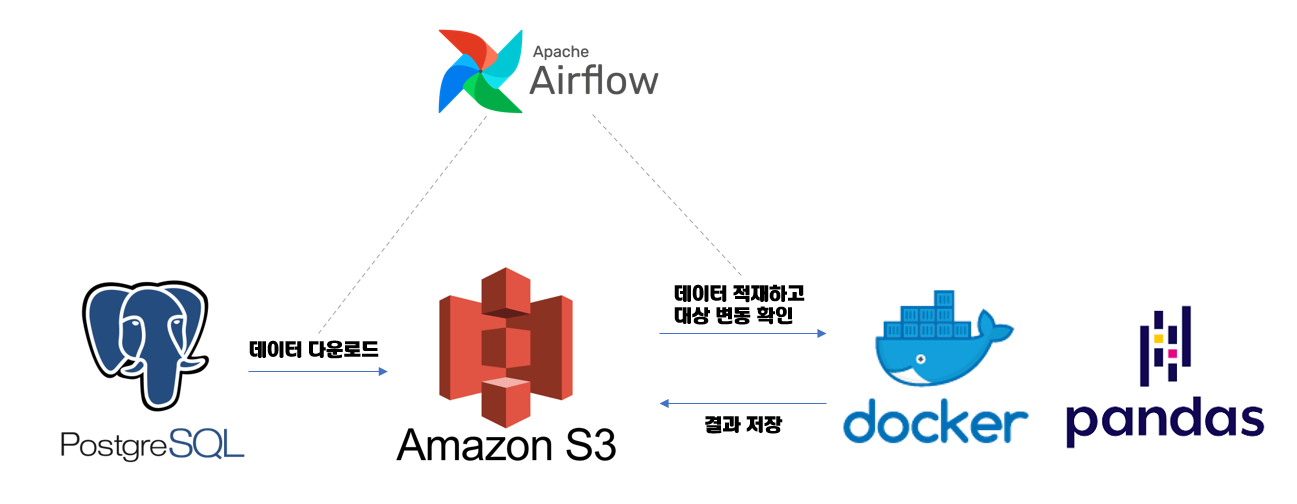
- 7-2의 목표는 Airflow를 통해 오케스트레이션하는 방법을 아는 것이다.
오케스트레이션은 여러 개의 컴퓨터 시스템, 애플리케이션 혹은 서비스를 조율하고 관리하는 것이며, 오케스트레이션의 목표는 빈도가 높고 반복할 수 있는 프로세스의 실행을 간소화, 최적화해 복잡한 작업과 워크플로를 간편하고 효율적으로 관리할 수 있도록 돕는 것이다.- 7-2 실습에서는 Airbnb의 암스테르담 리스트를 포함한 Postgres 데이터베이스 컨테이너에 있는 데이터를 S3와 호환되는 컨테이너로 로드해 주고, 도커 컨테이너에서 Pandas를 사용해 처리한다.
- Airflow: 모든 작업이 올바른 순서로 완료할 수 있도록 해 주는 중요한 역할.
- Postgres Container: Airbnb 데이터로 채워진 데이터베이스를 포함하는 Postgres 이미지. 🔗 insideairbnb
- S3: Data Lake, Postgres의 데이터를 Pandas로 읽고 처리 및 적재. 입출력 시스템 간 작업을 관리.
- Docker Container: 대규모 데이터 처리 작업에서 여러 시스템에 분산 처리를 하기 위해 사용. (스파크 작업으로 대체)
-- 실습을 위해 생성한 테이블 listings
CREATE TABLE IF NOT EXISTS listings(
id INTEGER,
name TEXT,
host_id INTEGER,
host_name VARCHAR(100),
neighbourhood_group VARCHAR(100),
neighbourhood VARCHAR(100),
latitude NUMERIC(18,16),
longitude NUMERIC(18,16),
room_type VARCHAR(100),
price INTEGER,
minimum_nights INTEGER,
number_of_reviews INTEGER,
last_review DATE,
reviews_per_month NUMERIC(5,2),
calculated_host_listings_count INTEGER,
availability_365 INTEGER,
download_date DATE NOT NULL
);1. PostgresToS3Operator 구현하기
- Airflow 에코 시스템에서는 A-to-B 오퍼레이터를 많이 개발했지만 PostgresToS3Operator는 존재하지 않는다.
- 다른 오퍼레이터 참고하여 구현해 보자.
1) MongoToS3Operator
MongoToS3Operator같은 경우 Airflow가 동작하는 시스템의 파일 시스템을 사용하지 않고 모든 결과를 메모리에 보관하고 있다.S3Hook,MongoHook을 인스턴스화하고MongoHook을 통해 데이터를 쿼리한다.MongoDB->Airflow의 오퍼레이터 메모리->AWS S3- 이 과정의 문제점: 쿼리 결과가 크면 Airflow 시스템에서 사용 가능한 메모리가 부족해질 수 있다.
2) S3ToSFTPOperator
SSHHook과S3Hook을 인스턴스화한다.- S3ToSFTOperator의 중간 결과를 local의 위치에 저장한다.
- 이 과정의 문제점: 디스크가 충분한 공간이 있는지를 확인해야 한다.
3) 두 Operator의 공통점과 차이점
- 공통점: 두 개의 훅을 가진다. A-to-B Operator라고 하면 A와 B의 훅을 모두 가진다.
- 차이점: A와 B의 데이터를 검색하고 전송하는 방법이 다르다.
4) 이 과정을 참고해서 PostgresToS3Operator를 어떻게 구현할 수 있을까?
S3Hook과PostgresHook을 인스턴스화해 주어야 한다.S3Hook은AWSHook의 서브클래스로 method와 attribute를 상속한다. 그래서s3_conn_id가 아닌aws_conn_id를 인수로 사용해야 한다. 🔗 S3HookPostgresHook은DbApiHook의 서브클래스이다. 🔗 PostgresHook은DbApiHook의 메소드 중에는get_records()라는 메소드가 있는데 이 메소드를 통해 결과 값을 반환 받을 수 있다. 이때 반환되는 결과의 유형은 튜플의 목록이 된다.- 이 튜플들의 목록을 문자열화하고 이를 AWS S3에 저장하는
load_string()을 호출하여 구현한다. - 이때 결과를
csv로 변환하면 Apache Pandas나 Spark 같은 데이터 처리 프레임워크가 출력 데이터를 쉽게 해석할 수 있다. csv로 메모리 내에서 변환한 데이터를 S3에 업로드를 해 준다.- 파일이 이미 있는 경우 멱등성을 보장하기 위해서 replace=True로 세팅해 주어야 한다. 이렇게 해 주면 이미 파일이 존재하더라도 기존 파일을 덮어쓰게 된다. False인 경우 같은 이름에 파일이 존재한다면 오류 발생.
import csv
import io
import os
from airflow.models import BaseOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.utils.decorators import apply_defaults
class PostgresToS3Operator(BaseOperator):
template_fields = ("_query", "_s3_key")
@apply_defaults
def __init__(
self, postgres_conn_id, query, s3_conn_id, s3_bucket, s3_key, **kwargs
):
super().__init__(**kwargs)
self._postgres_conn_id = postgres_conn_id
self._query = query
self._s3_conn_id = s3_conn_id
self._s3_bucket = s3_bucket
self._s3_key = s3_key
def execute(self, context):
postgres_hook = PostgresHook(postgres_conn_id=self._postgres_conn_id)
s3_hook = S3Hook(aws_conn_id=self._s3_conn_id) #aws_conn_id를 사용한다. s3_conn_id가 아니다.
results = postgres_hook.get_records(self.query) #결과 값을 PostgreSQL에서 가지고 오기
data_buffer = io.StringIO() #문자열 버퍼를 생성한 후 데이터 작성하고 바이너리로 변환
#csv 변환 과정
csv_writer = csv.writer(
data_buffer, quoting=csv.QUOTE_ALL, lineterminator=os.linesep
)
csv_writer.writerow(headers)
csv_writer.writerows(results)
data_buffer_binary = io.BytesIO(data_buffer.getvalue().encode()) #버퍼는 메모리에 있기 때문에 처리 후 파일 시스템에 남기지 않을 수 있다
s3_hook.load_file_obj(
file_obj=data_buffer_binary,
bucket_name=self._s3_bucket,
key=self._s3_key,
replace=True, #멱등성 보장
)5) PostgresToS3Operator 실행
download_from_postgres = PostgresToS3Operator(
task_id="download_from_postgres",
postgres_conn_id="inside_airbnb",
query="SELECT * FROM listings WHERE download_date BETWEEN '{{ prev_ds }}' AND '{{ ds }}'",
s3_conn_id="locals3",
s3_bucket="inside-airbnb",
s3_key="listing-{{ ds }}.csv",
dag=dag,
)2. 큰 작업을 외부에서 수행하기
1) Airflow에 대한 의견
- 오퍼레이터들이 Airflow 같은 파이썬 런타임에서 실행되기 때문에 Airflow를 태스크 오케스트레이션 시스템으로 볼 뿐 아니라 태스크 실행 시스템으로도 봐야 한다. vs Airflow는 태스크 트리거 시스템으로만 사용해야 하고 Airflow가 실제 작업을 수행해서는 안 되며 Apache Spark와 같은 데이터 처리 시스템이 수행해야 한다.
- 이 부분에 대한 해답은 나와 있지 않지만 사용자의 요구 사항과 상황에 따라 달라질 수 있는 사항이다.
- 이는 Airflow가 유연하게 사용될 수 있는 도구이기 때문.
- Airflow가 구동 중인 시스템의 모든 리소스를 사용하는 매우 큰 작업을 하고 있다면 오케스트레이션과 실행이 완벽하게 분리되어 있어야 한다.
- Airflow가 작업을 실행하지만 Spark 같은 데이터 처리 프레임워크가 이 작업을 수행하고 완료할 때까지 기다려야 한다.
2) Pandas를 이용한 Inside Airbnb 데이터 처리를 위해 도커 컨테이너를 어떻게 사용할 수 있을까?
Python Docker Client로 인수 리스트를 입력해 도커 컨테이너 실행을 시작할 수 있다.DockerOperator에서network_mode는Docker Container의 네트워크 모드를 설정하는 데 사용된다.- docker run 명령어의 --network 옵션과 동일한 역할을 한다.
- 나올 수 있는 파라미터는
bridge(default),host,container:container_name_or_id,none,사용자 정의 네트워크가 올 수 있다. bridge는 독립적인 네트워크로 실행되는 것이고,host는 컨테이너를 호스트의 네트워크에 직접 연결하는 것이다.- 해당 코드에서는 host를 사용해 주었다. 왜 host로 사용했을까?
- localhost를 통해 호스트 컴퓨터의 다른 서비스에 연결하기 위해서.
auto_remove를 True로 설정해 주면DockerOperator의 작업이 끝나면 컨테이너를 삭제해 준다.docker_url은Airflow가Docker 데몬과 통신하기 위해 필요한 정보를 제공하며TCP 소켓이나UNIX 소켓이 오게 된다.Docker 데몬은Docker 엔진이 실행되는 백그라운드 프로세스이다.Docker Container의 생성, 실행, 관리를 담당하며Docker CLI와 상호작용한다.
- 🔗 Docker Operator
crunch_numbers = DockerOperator(
task_id="crunch_numbers",
image="numbercruncher",
api_version="auto",
auto_remove=True, #완료 후 컨테이너를 삭제해 준다
docker_url="unix://var/run/docker.sock",
network_mode="host",
environment={
"S3_ENDPOINT": "localhost:9000",
"S3_ACCESS_KEY": "secretaccess",
"S3_SECRET_KEY": "secretkey",
},
dag=dag,
)3) DAG
- 이렇게 DAG를 거치게 되면 S3에서 Inside Airbnb 데이터를 읽고 처리 후 Pandas 스크립트를 포함해 결과를 다시 S3에 저장하는 airflowbook/numbercruncher 도커 이미지가 시작된다.
download_from_postgres >> crunch_numbers✍ Spark 작업
- SparkSubmitOperator 사용
- Airflow에서 제공하는 연산자 중 하나이다.
- Airflow 머신에서 Spark 인스턴스를 찾기 위해 spark-submit 파일과 YARN 클라이언트 구성이 필요하다.
- 일반적으로 Spark이 설치된 디렉토리에 위치하며, 일반적으로
$SPARK_HOME/bin/spark-submit경로에 있는데 이 부분을 Airflow에서 확인해 주는 것이다.- spark-submit 파일과 YARN 클라이언트가 존재한다면 Airflow에서
SparkSubmitOperator를 통해 Spark 애플리케이션을 실행할 수 있다.
- SSHOperator 사용
- Spark 인스턴스에 대한 SSH 액세스가 필요하지만 Airflow 인스턴스에 대한 Spark 클라이언트 구성이 별도로 필요하지 않다.
- 왜 클라이언트 구성이 별도로 필요하지 않은가?
- SSHOperator를 사용하여 Spark 인스턴스에 SSH 연결을 설정하고 명령을 실행할 수 있다. 이는 Spark 클라이언트 구성 없이 SSH를 통해 Spark 인스턴스에 직접 액세스할 수 있다는 것을 의미한다.
- SimpleHTTPOperator 사용
- Apache Spark용 REST API인
Livy를 통해 실행해야 한다.

송의 개발 LOG