
📚 오늘 공부한 내용
1. RedShift 환경 세팅
- RedShift 역시 일주일 동안 사용할 서비스이기 때문에 Cluster 생성 과정만을 포스트 하려다가 따로 개념을 정리하여 포스트 하였다.
📑 RedShift 개념 정리 - Cluster 생성 과정을 따로 포스트로 정리하였다.
📑 [AWS RedShift] 2. AWS RedShift Cluster 생성
2. 관계형 데이터베이스 - 웹서비스 사용자/세션 정보
사용자 ID: 보통 웹서비스에서는 등록된 사용자마다 부여되는 유일하고 고유한 값의ID가 존재한다.세션 ID: 각 세션마다 부여되는ID이다.세션이란사용자의 방문을논리적인 단위로 나눈 것.- 외부 링크를 타고 오거나 직접 방문해서 올 경우 세션 생성
- 방문 후 30 분 동안 interaction 없다가 뭔가 하는 경우 세션 생성
- 하나의 사용자가
여러 개의 세션을 가질 수 있다. - 보통 세션은
세션을 만들어낸 접점을채널이란 이름으로 기록해 둔다.- 사용자가 어떻게 이 사이트에 방문하게 됐는지 트랙킹을 하고 싶기 때문이고, 이를 통해 마케팅 관련 기여도 분석이 가능하다.
- 세션이
생성된 시간도 같이 기록되어야 한다.
- 이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능해진다.
사용자 트래픽관련:DAU(Daily Active User),WAU(Weekly Active User),MAU(Monthly Active User)등의 일주월별 ACTIVE USER 차트마케팅관련:Marketing Channel Attribution분석 (어떤 채널에 광고하는 것이 효과적인가?)
- 이를 바탕으로 만들어진 데이터베이스와 테이블
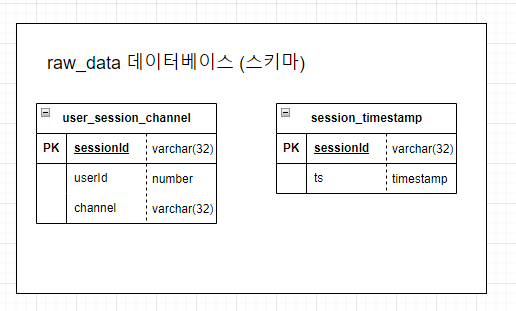
- 사용자에 따라 여러 세션이 주어지기 때문에
userId는 유일한 값이 될 수 없다. 그렇기 때문에sessionId가Primary Key가 된다.
3. SQL 기본
- 다수의 SQL문을 실행한다면 세미콜론 분리 필요
- SQL 주석
--: 인라인 한 줄 주석./*--*/: 여러 줄에 걸쳐 사용하는 주석.
- SQL 키워드는 대분자를 사용한다거나 나름대로의 포맷팅이 필요하며 팀 프로젝트라면 팀에서 사용하는 공통 포맷이 필요하다.
- 테이블/필드 이름의 명명 규칙을 정하는 게 중요하다.
단수형VS복수형_vsCamelCasing
ex)user_session_channelvsUserSessionChannel
4. SQL DDL
1) CREATE TABLE
Primary key속성을 지정할 수 있지만 무시 (Primary key uniqueness)
CREATE TABLE raw_data.user_session_channel(
userid int
, sessionid varchar(32) primary key
, channel varchar(32)
);CTAS (CREATE TABLE AS SELECT):CREATE TABLE table_name AS SELECT- 테이블을 만듦과 동시에 내용까지 채우는 것
- vs
CREATE TABLE and then INSERT
2) DROP TABLE
DROP TABLE table_name;- 없는 테이블을 지우려고 하는 경우 에러 발생
DROP TABLE IF EXISTS table_name;없는 테이블을 지울 때 오류가 발생하지 않게 하기 위해 다음과 같은 문법을 활용할 수 있음- vs
DELETE FROM테이블의 레코드를 지우는 것이지 테이블을 지우는 것은 아님
3) ALTER TABLE
- 새로운 컬럼 추가
-ALTER TABLE table_name ADD COLUMN field_name field_type; - 기존 컬럼 이름 변경
-ALTER TABLE table_name RENAME now_field_name TO new_field_name; - 기존 컬럼 제거
-ALTER TABLE table_name DROP COLUMN field_name; - 테이블 이름 변경
-ALTER TABLE now_table_name RENAME TO new_table_name;
5. SQL DML
1) SELECT
SELECT FROM: 테이블에서 레코드와 필드를 조회할 때 사용WHERE: 레코드 선택 조건 지정IN: OR 조건과 동일함.field_name IN (value1, value2)라면 field의 value1, value2인 레코드들이 모두 조회됨.LIKE: 뒤에 붙은 문자열과 일치하는 레코드들을 조회한다.ILIKE:LIKE와 동일하나 대소문자 구분을 두지 않고 조회된다.BETWEEN: 보통 날짜 사이의 일정 기간 데이터를 조회할 때 사용함.
GROUP BY: 정보를 그룹 레벨로 조회도 가능 (DAU, WAU, MAU 계산은 GROUP BY를 필요로 함)ORDER BY: 레코드 순서를 결정 (default는 ASC)
SELECT field_name1
, field_name2
FROM table_name
WHERE 조건
GROUP BY field_name1, field_name2
ORDER BY field_name1 [ASC|DESC]
LIMIT N -- N 개까지의 데이터만 조회
; -- raw_data의 user_session_channel 10 개 데이터와 모든 컬럼을 보고 싶을 때
SELECT *
FROM raw_data.user_session_channel
LIMIT 10;
-- 유일한 채널명을 알고 싶을 때
SELECT DISTINCT channel -- DISTINCT는 중복 제거
FROM raw_data.user_session_channel;
-- 채널별 카운트를 하고 싶은 경우
SELECT channel, COUNT(1)
FROM raw_data.user_session_channel
GROUP BY channel;
-- FACEBOOK, INSTAGRAM이면 Social-Media
-- Google, Naver면 Search_Engine
-- 기타 등등이라면 Something-Else라는 새로운 컬럼을 만들면
SELECT CASE WHEN channel IN ('Facebook', 'Instagram')
THEN 'Social-Media'
WHEN channel IN ('Google', 'Naver')
THEN 'Search_Engine'
ELSE 'Something-Else' END AS channel_type
FROM raw_data.user_session_channel; NULL: 값이 존재하지 않음을 나타내는 상수로 0 혹은 ""와 다르다. 필드 지정 시 값이 없는 경우 NULL로 지정 가능하며 NULL인지 아닌지 확인하기 위해서는IS NULL혹은IS NOT NULL로 쓴다.- string Functions
- LEFT(str, N)
- REPLACE(str, exp1, exp2)
- UPPER(str)
- LOWER(str)
- LEN(str)
- LPAD, RPAD
- SUBSTRING
2) INSERT INTO
- 테이블 레코드를 추가
3) UPDATE FROM
- 테이블 레코드의 필드 값 수정
4) DELETE FROM
- 테이블에서 레코드를 삭제
TRUNCATE:WHERE절이 존재하지 않는DELETE FROM같이 조건 없이 모든 레코드를 날려 주는데DELETE FROM는트랜잭션을 사용하고,TRUNCATE는 사용 불가하다.
👊 실습에 들어가기 앞서 기억해야 할 것
- 현업에서는 깨끗한 데이터란 존재하지 않는다.
- 항상 데이터가 믿을 수 있는지 의심할 것.
- 레코더를 직접 살펴 보는 것보다 더 좋은 데이터 확인 방법은 없다.
- 데이터를 확인하는 방법
중복된 레코드들을 확인최근 데이터의 존재 여부를 확인 (freshness)Primary key uniqueness가 지켜지는지 확인값이 비어 있는 컬럼들이 있는지 확인- 위의 내용을
코딩 unit test 형태로 만들어 매번 쉽게 확인할 수 있음 -자동화- 어느 시점이 되면 너무 많은 테이블이 존재하게 되므로 중요한 테이블이 무엇이고 메타 정보를 잘 관리하는 게 중요하다.
Data Discovery문제들이 생겨난다.
- 무슨 테이블에 내가 원하고 신뢰할 수 있는 정보가 들어 있나?
- 테이블에 대해 질문을 하고 싶은데 누구한테 질문해야 하나?
- 이 문제를 해결하기 위해 다양한 오픈소스와 서비스들이 출현한다. DataHub, Amundsen, Select Star, DataFrame 등
5) 타입 변환
-
DATE Conversion:
- 타임존 관련 변환
- CONVERT_TIMEZONE('America/Los_Angeles', ts)
- DATE, TRUNCATE
- DATE_TRUNC
- EXTRACT, DATE_PART: 날짜에서 특정 부분의 값을 추출하는 것 (DATE, HOUR 등)
- DATEDIFF
- DATEADD
- GET_CURRENT
- 타임존 관련 변환
-
TO_CHAR, TO_TIMESTAMP, TO_NUMBER
6) Type Casting
-
::오퍼레이터를 사용
- category::float -
cast 함수사용
- cast(category as float)
6. RedShift 실습
📑 [AWS RedShift] 3. 구글 Colab을 통해 RedShift 데이터 조회 (SQL)
🔎 어려웠던 내용 & 새로 알게 된 내용
1.
구글 Colab에서 SQL Connect 오류
%sql postgresql://username:password@hostname/dbname
구글 Colab을 통해 실습에 들어가게 됐는데 다음과 같이 사용할 RedShift 클러스터를 호출하는 과정에서 다음과 같은 오류가 발생하였다.
SQLAlchemy는 잘 설치가 되었는데 Connection을 하려면SQLAlchemy이 필요하다는 것이었다.
Connection info needed in SQLAlchemy format, example: postgresql://username:password@hostname/dbname or an existing connection: dict_keys([]) Can't load plugin: sqlalchemy.dialects:postgresql Connection info needed in SQLAlchemy format, example: postgresql://username:password@hostname/dbname or an existing connection: dict_keys([])
결론적으로는 런타임을 재실행해 주지 않아 발생한 오류였다.
만약 구글 Colab에서 새로운 패키지를 설치하고 적용하기를 원할 때는 런타임을 재실행 해 주어야 한다.
해당 오류는 구글 Colab 런타임 재시작 코드를 사용해 주면 되는데 해당 코드를 기억해 두어 참고하기 위해 따로 포스트 해 두었다.
🔑 구글 Colab 런타임 오류
2. MySQL과 Oracle 날짜 포맷 차이
- Oracle 위주로 SQL을 사용했다 보니 아무 생각 없이 날짜 포맷이
YYYY-MM-DD 24HH:MI:SS형식으로 되어 있다고 생각했는데 MySQL에서는 포맷의 표기법이 조금 달랐다.- MySQL에서는 단순하게
%r (hh:mm:ss AM|PM),%R (hh:mm:ss)을 통해 시간을 표현해 줄 수도 있고 다음과 같이 시, 분, 초를 나눌 수도 있다.- Oracle과 MySQL 날짜 포맷 표기 차이
Oracle MySQL 설명 YYYY %Y 연도(2000, 2023) MM %c 월 (11, 12) DD %e 일 (0, 1, 2) 24HH %H 시 (하루를 24시간으로 두었을 때 오전, 오후를 구분하지 않은 시간) MI %i 분 SS %S 초
✍ 회고
- SQL마다 조금씩 다른 문법들이 존재하지만 Oracle은 특히 그런 것 같다는 생각을 했다. 그렇지만 크게 다른 부분은 없어 SQL 쿼리를 작성하는 데 어려움은 없었다. 오랜만에 데이터를 가지고 쿼리문을 작성해 보는 시간을 가져서인지 재미있었다.
- 보통 TIL을 작성하면서 새로 알게 되는 부분을 꼼꼼하게 공부하려고 하는 편인데 그렇다 보니 작성 시간이 오래 걸려 조금 더 효율적인 방법을 꾸준하게 생각하게 되는 것 같다.
