
📚 오늘 공부한 내용
1. JOIN이란?
- 두 개 혹은 그 이상의 테이블을
공통 필드(특정 KEY)를 가지고MERGE할 때 사용된다. - 스타 스키마로
분산되어 있는 정보를 통합하는데 사용한다. - 조인 방식(INNER, LEFT, RIGHT 등)에 따라 달라지는 두 가지
- 어떤 레코드들이 선택되는지
- 어떤 필드들이 채워지는지
- JOIN 문법
SELECT A.*
, B.*
FROM TABLE1 A
_ JOIN TABLE2 B -- JOIN 앞의 _에 LEFT, INNER, RIGHT, CROSS, FULL이 들어가게 된다
ON A.KEY1 = B.KEY1
AND A.KEY2 = B.KEY2;📑[SQL] JOIN JOIN과 관련된 문법, 실습은 다 따로 포스팅을 통해 정리했다.
2. BOOLEAN 타입 처리
- True or False
flag = True와flag is True는 동일한 표현이다.- 그렇다면
flag is True와flag is not False는 동일한 표현인가?
- 수학적으로는 동일한 표현이지만SQL에서는 다르다.
- 아니다.SQL에서는NULL인 경우도flag is not False로 인식한다.
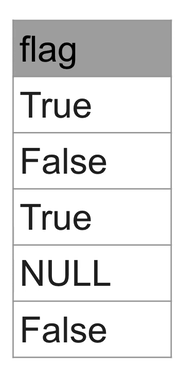
- 다음과 같은
raw_data.boolean_test라는 테이블이 있다.
SELECT COUNT(CASE WHEN FLAG = True THEN 1 END) TRUE_CNT1
, COUNT(CASE WHEN FLAG IS True THEN 1 END) TRUE_CNT2
, COUNT(CASE WHEN FLAG IS NOT False THEN 1 END) NOT_FALSE_CNT
FROM raw_data.boolean_test- 결과

- True 값은 두 개가 나오지만 다음과 같이
IS NOT NULL을 할 경우 NULL인 경우도 포함되어 세 개의 레코드 수가 나오게 된다.
3. NULL 비교
- NULL 비교는 항상
IS혹은IS NOT으로 수행한다. =나!=또는<>로 수행하면 잘못된 결과가 나오게 된다. 대부분은 그냥 0이 나오게 된다.
- 다음과 같은
raw_data.boolean_test라는 테이블이 있다. - 하나의 NULL이 존재하므로 WHERE 절에 NULL을 조회할 때 1 개가 나와야 한다.
SELECT COUNT(1)
FROM raw_data.boolean_test
WHERE FLAG IS NULL;- 결과

IS NULL을 사용할 때는 한 개가 잘 출력되는 것을 볼 수 있다. 하지만=를 사용한다면
SELECT COUNT(1)
FROM raw_data.boolean_test
WHERE FLAG = NULL;- 결과

다음과 같이 0이라는 잘못된 결과가 나오는 것을 알 수 있다.
4. COALESCE
- NULL 값을 다른 값으로 바꿔 주는 함수
- NULL 대신 다른 백업 값을 RETURN 해 준다
- COALESCE(exp1, exp2, exp3, ...)
- exp1 인자부터 살펴서 NULL이 아닌 값이 나오면 그걸 RETURN 해 준다. 끝까지 확인했는데 모두 NULL이면 NULL을 리턴한다.
SELECT VALUE
, COALESCE(VALUE, 0) -- 만약 value가 NULL이면 0을 RETURN
FROM raw_data.count_test;
- 결과를 비교해 보면 VALUE의 첫 번째는 NULL값인데 이를 COALESCE 하면 0으로 리턴되는 것을 볼 수 있다.
- NULL이 나올 때 다른 대체 값을 쓰고 싶은 경우가 정해져 있다면 유용하게 쓸 수 있다.
5. 공백 혹은 예약 키워드를 필드 이름으로 사용하려면?
- ""로 둘러싸서 사용할 수 있다.
🔎 어려웠던 내용 & 새로 알게 된 내용
1. NULLIF
NULLIF(A, B)
- A와 B가 같은 값이면 NULL을 반환
- 만약에 A와 B가 다른 값이면 A의 값이 반환
- NVL 함수는 NULL인 경우 다른 값으로 치환을 해 주는 역할을 한다고 하면 NULLIF 함수는 특정 값인 경우 NULL로 치환할 수 있는 함수이다.
📚 어제 과제 풀이
이 네 가지 테이블을 이용해서 채널별 월 매출액 테이블 만들기
Column
- month
- channel
- uniqueUsers (총 방문 사용자)
- paidUsers (구매 사용자: refund한 경우도 판매로 고려) - session_transaction에 존재하는 사용자
- conversionRate (구매 사용자/ 총 방문 사용자) - float 형식으로 소수점 단위가 나오도록 해야 함
- grossRevenue (Refund 포함) - amount 필드를 sum
- netRevenue (Refund 제외)
❓ 풀이
1. 복잡한 JOIN 시 먼저 JOIN 전략을 수립해야 한다.
- raw_data.user_session_channel
- raw_data.session_timestamp
- raw_data.session_transaction
- 먼저 OUTER JOIN이 필요한지 아닌지 테이블을 점검하여 확인한다
SELECT DISTINCT SESSIONID FROM RAW_DATA.SESSION_TIMESTAMP MINUS SELECT DISTINCT SESSIONID FROM RAW_DATA.USER_SESSION_CHANNEL
MINUS를 사용해 SESSION_TIMESTAMP와 USER_SESSION_CHANNEL의 SESSIONID를 뺐을 때 갭 차이를 확인한다. 둘은 완전한 ONE TO ONE 관계이기 때문에 0이라는 결과가 나오게 된다.- user_session_channel와 session_timestamp는 ONE TO ONE 관계이기 때문에 일대일로 JOIN이 가능하다. 나는 이것 역시 LEFT JOIN을 사용했는데 풀이에서는
INNER JOIN을 사용했다. 아마 두 경우 모두 동일한 결과가 나와 문제는 없을 것이다.- 하지만 session_transaction의 경우 모든 세션 정보가 존재하지 않는다. 매출이 생길 시에만 데이터가 발생하기 때문에
LEFT JOIN을 사용한다.SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID LEFT JOIN RAW_DATA.SESSION_TRANSACTION C ON A.SESSIONID = C.SESSIONID GROUP BY 1, 2 ORDER BY 1, 22. uniqueUsers와 paidUsers를 추가한다.
- 나는
DISTINCT의 경우NULL을 처리해 주지 않는다고 알고 있어 uniqueUsers와 paidUsers를 구할 때 CASE 문을 통해 NULL 여부 역시 체크해 주었는데 풀이 과정에서는 이 부분이 없었다. USERID가 NOT NULL 컬럼이었다면 불필요한 조건을 내가 추가한 것이기는 하다.- COUNT 함수 내부에도
CASE-WHEN 절을 사용할 수 있다.SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel , COUNT(DISTINCT USERID) AS uniqueUsers , COUNT(DISTINCT CASE WHEN C.AMOUNT > 0 THEN A.USERID END) AS paidUsers FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID LEFT JOIN RAW_DATA.SESSION_TRANSACTION C ON A.SESSIONID = C.SESSIONID GROUP BY 1, 2 ORDER BY 1, 23. conversionRate를 추가한다.
- 나 역시 여러 번 시도를 했는데 대부분 0.0이 나왔다. 각각 CONVERT를 통해 FLOAT 타입으로 캐스팅 후 계산해 주었을 때 적절한 결과 값이 나오게 됐는데 풀이 과정에서도 몇 가지 시도에 대해 보여 주었다.
- 첫 번째 시도
paidUsers/uniqueUsers AS conversionRate둘 다 정수형이기 때문에 0.0이 나오게 된다.- 두 번째 시도
paidUsers::float/uniqueUsers AS conversionRate:: 역시 Type Casting 방법 중 하나로 paidUsers를 float 함수로 변환한 것이다. 둘 중 하나만 float로 변환해 주어도 결과 값은 float로 나오게 된다.- 세 번째 시도
ROUND(paidUsers*100.0/uniqueUsers, 2) AS conversionRate이런 경우 분모가 0이 되는 경우가 발생하면 오류가 난다.- 네 번째 시도
ROUND(paidUsers*100.0/NULLIF(uniqueUsers, 0), 2) AS conversionRateNULLIF 함수를 사용해 준다. NULLIF(a, b)라고 했을 때 a와 b가 동일하면 NULL이 RETURN 되게 해 주는 함수이다. NULL과 특정 수를 연산하게 되면 모두 NULL이 최종 값이 된다.SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel , COUNT(DISTINCT USERID) AS uniqueUsers , COUNT(DISTINCT CASE WHEN C.AMOUNT > 0 THEN A.USERID END) AS paidUsers , ROUND(paidUsers*100.0/NULLIF(uniqueUsers, 0), 2) AS conversionRate FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID LEFT JOIN RAW_DATA.SESSION_TRANSACTION C ON A.SESSIONID = C.SESSIONID GROUP BY 1, 2 ORDER BY 1, 24.grossRevenue와 netRevenue를 구한다
- grossRevenue는 모든 amount를 더한 것이고, netRevenue는 환불되지 않은 amount들을 더한 값이다.
⭕ 최종 쿼리문
SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel , COUNT(DISTINCT USERID) AS uniqueUsers , COUNT(DISTINCT CASE WHEN C.AMOUNT > 0 THEN A.USERID END) AS paidUsers , ROUND(paidUsers*100.0/NULLIF(uniqueUsers, 0), 2) AS conversionRate , SUM(C.AMOUNT) AS grossRevenue , SUM(CASE WHEN C.REFUNDED THEN 0 ELSE C.AMOUNT END) AS netRevenue FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID LEFT JOIN RAW_DATA.SESSION_TRANSACTION C ON A.SESSIONID = C.SESSIONID GROUP BY 1, 2 ORDER BY 1, 2

📚 과제 1
사용자별로 처음 채널과 마지막 채널이 무엇이었는지 찾기
- ROW_NUMBER VS FIRST_VALUE/LAST_VALUE
- ROW_NUMBER를 사용한다면?
- 특정 레코드에 일련 번호를 붙여 SELECT 하는 것 (새로운 field를 추가)
- 일련 번호를 붙일 때는 특정 값(field1)을 기준으로 그룹핑을 하고 ORDER BY를 기준으로 일련 번호를 붙인다.
-ROW_NUMBER() OVER(PARTITION BY field1 ORDER BY field2) NN- ORDER BY에서 TS(시간)을 오름차순으로 했을 때 첫 번째로 나오는 값이 처음 채널, 내림차순으로 했을 때 첫 번째로 나오는 값이 마지막 채널이 된다.
❗ 내 풀이
- 먼저 ROW_NUMBER을 통해 USERID를 기준으로 GROUP BY를 해 주고 최초의 채널과 마지막 채널을 찾기 위해 넘버링을 해 주었다.
- 이 넘버링을 해 준 쿼리를 WITH절 안에 넣어 하나의 테이블로 보고 LAST_CHANNEL이 1이라면 마지막 채널이 되는 것이고 FIRST_CHANNEL이 1이라면 첫 채널이 되는 것이므로 서브쿼리를 통해 각각 채널을 찾아 주었다.
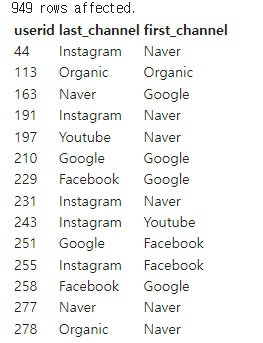
WITH TS_RANK AS ( SELECT A.USERID , A.SESSIONID , A.CHANNEL , ROW_NUMBER() OVER (PARTITION BY A.USERID ORDER BY B.TS DESC) LAST_CHANNEL , ROW_NUMBER() OVER (PARTITION BY A.USERID ORDER BY B.TS ASC) FIRST_CHANNEL FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID ) SELECT T.USERID , (SELECT CHANNEL FROM TS_RANK WHERE USERID = T.USERID AND FIRST_CHANNEL = 1) FIRST_CHANNEL , (SELECT CHANNEL FROM TS_RANK WHERE USERID = T.USERID AND LAST_CHANNEL = 1) LAST_CHANNEL FROM TS_RANK T GROUP BY 1
- 결과
📚 과제 2
Gross Revenue가 가장 큰 UserID 10 개 찾기
- gross revenue란 refunded를 포함한 매출액
❗ 내 풀이
- USERID를 가지고 있는 건
USER_SESSION_CHANNEL- 매출 정보를 가지고 있는 건
SESSION_TRANSACTION- 두 테이블의 조인만으로도 결과 값을 얻어올 수 있다.
- 그중 가장 큰 UserID 10 개를 찾아야 하기 때문에
ORDER BY를 통해 GROSS_REVENUE를 기준으로 내림차순 해 주고LIMIT 10을 통해 10 개의 데이터만 출력되게 하였다.SELECT A.USERID , SUM(B.AMOUNT) GROSS_REVENUE FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TRANSACTION B ON A.SESSIONID = B.SESSIONID GROUP BY A.USERID ORDER BY GROSS_REVENUE DESC LIMIT 10;
- 결과

📚 과제 3
raw_data.nps 테이블을 바탕으로 월별 NPS 계산
- 고객들이 0 (의향 없음)에서 10 (의향 아주 높음)으로 준 평점을 저장해 둔 테이블
- detractor(비추전자): 0에서 6
- passive (소극자): 7에서 8
- promoter (홍보자): 9나 10
NPS = promoter 비율 - detractor 비율- NPS는 계산을 보수적으로 해서 소극자들의 점수는 제외한다.
❗ 내 풀이
- 일단 raw_data.nps 테이블의 구조를 알아야 한다고 생각했다.
SELECT * FROM raw_data.nps LIMIT 10;
- 조회해 본 결과 테이블은 id(NUMBER), created_at(TIMESTAMP), score(NUMBER)로 이루어져 있었다.
- NPS를 구하기 위해서는 score 9에서 10을 준 promoter의 비율과 0에서 6을 준 detractor의 비율을 구하여야 한다. 그 전에 ID 값이 PK의 유일성을 만족하고 있는지 확인해 보자.
SELECT ID , COUNT(1) ID_CNT FROM RAW_DATA.NPS GROUP BY 1 ORDER BY ID_CNT DESC LIMIT 1;
- 해당 테이블은 Primary Key의 Uniqueness를 만족하고 있다.
- 각각의 detractor과 promoter의 비율을 더해서 빼기 위해 전체 수와 detractor, promoter의 수를 구해 주었다.
SELECT TO_CHAR(CREATED_AT, 'YYYY-MM') "MONTH" , COUNT(*) TOTAL_CNT , COUNT(CASE WHEN SCORE >= 0 AND SCORE < 7 THEN ID END) DETRACTOR_CNT , COUNT(CASE WHEN SCORE >= 9 THEN ID END) PROMOTER_CNT FROM RAW_DATA.NPS GROUP BY 1; -- sum을 사용한다면 다음과 같이 쓸 수 있고 두 개의 결과 값은 같게 나온다. SELECT TO_CHAR(CREATED_AT, 'YYYY-MM') "MONTH" , COUNT(*) TOTAL_CNT , SUM(CASE WHEN SCORE >= 0 AND SCORE < 7 THEN 1 ELSE 0 END) DETRACTOR_CNT , SUM(CASE WHEN SCORE >= 9 THEN 1 ELSE 0 END) PROMOTER_CNT FROM RAW_DATA.NPS GROUP BY 1;
- WITH 절을 통해 위의 쿼리 결과를 하나의 테이블로 만들어 주고 이를 이용해 각각 detractor 비율과 promoter의 비율을 구한 뒤 해당 비율은 소수점을 반올림 하지 않아야 더 확실한 NPS를 구할 수 있을 것 같아 NPS를 계산해 준 후에 반올림을 해 주었다.
- 그 결과 최종적으로 다음과 같은 쿼리를 작성했다.
WITH MAU AS ( SELECT TO_CHAR(CREATED_AT, 'YYYY-MM') "MONTH" , COUNT(*) TOTAL_CNT , COUNT(CASE WHEN SCORE >= 0 AND SCORE < 7 THEN ID END) DETRACTOR_CNT , COUNT(CASE WHEN SCORE >= 9 THEN ID END) PROMOTER_CNT FROM RAW_DATA.NPS GROUP BY 1 ) SELECT MONTH , DETRACTOR_CNT::FLOAT/NULLIF(TOTAL_CNT, 0) * 100 DETRACTOR_PERCENT , PROMOTER_CNT::FLOAT/NULLIF(TOTAL_CNT, 0) * 100 PROMOTER_PERCENT , ROUND(PROMOTER_PERCENT - DETRACTOR_PERCENT, 2) NPS FROM MAU ORDER BY MONTH;
- 결과



✍ 회고
- SQL을 통해서 쌓인 데이터를 조회해서 분석하고 이를 어떻게 조회하는 것이 더 올바른 데이터를 얻을 수 있을지 고민하는 과정은 늘 흥미로운 것 같다. SQL에 대해 꽤 많이 써 봤다고 생각했는데 아직까지 모르는 함수들이 있는 걸 보니 공부를 더 많이 해야 되겠다 생각했다.

송의 개발 LOG