
📚 오늘 공부한 내용
1. 트랜잭션이란?
Atomic하게 즉,여러 개의 쿼리이지만 동시에 성공하거나 실패하도록 실행되어야 하는 SQL들을 묶어서하나의 작업처럼 처리하는 방법이다.- 예를 들어 계좌 이체 과정을 생각해 보자. 인출과 입금이 동시에 일어나야 하는데 인출이 성공했는데 입금이 실패했다면? 인출이 실패했는데 입금이 성공했다면?
- 이런 과정과 같이 동시에 성공과 실패가 적용되어야 하는 케이스의 경우
트랜잭션을 통해 묶어 주어야 함.
- DDL이나 DML 중
레코드를 추가, 수정, 삭제한 것에만 의미가 있고SELECT에는 트랜잭션을 사용할 이유가 없다. BEGIN과 END혹은BEGIN과 COMMIT사이에 해당 SQL을 사용한다.- 실패한다면
ROLLBACK한다.
BEGIN;
A의 계좌로부터 인출;
B의 계좌로 입금;
END; -- 이 BEGIN-END 사이의 명령어들은 하나의 명령어처럼 다 성공하거나 실패하거나 둘 중의 하나가 된다.END와COMMIT은 동일.- 만일 BEGIN 전의 상태로 돌아가고 싶다면
ROLLBACK을 실행. COMMIT MODE에 따라서 달라짐.
2. 트랜잭션 COMMIT MODE: AUTOCOMMIT
-
AUTOCOMMIT = TRUE- 모든 레코드 수정, 삭제, 추가 작업이 기본적으로 바로 데이터베이스에 쓰여지고 이를 COMMIT이라고 한다.
- 특정 트랜잭션으로 묶고 싶다면
BEGIN과END(COMMIT),ROLLBACK으로 처리해야 한다.
-
AUTOCOMMIT = FALSE- 모든 레코드 수정, 삭제, 추가 작업이 COMMIT 호출될 때까지 커밋되지 않는다.
3. 트랜잭션 방식
- GOOLE COLAB
AUTOCOMMIT = TRUE- 기본적으로 모든 SQL statement가 바로 커밋된다.
- 이를 바꾸고 싶다면
BEGIN; END;혹은BEGIN; COMMIT;을 사용한다.
- psycopg2
-autocommit이라는 파라미터로 조절이 가능하다.- True가 되면 기본적으로
PostgreSQL의 COMMIT MODE와 동일하다. - False가 되면 커넥션 객체의
.commit()과.rollback()함수로 트랜잭션을 조절 가능하다.
- True가 되면 기본적으로
4. DELETE FROM vs TRUNCATE
DELETE FROM table_name- 테이블에서 모든 레코드를 삭제한다.
- 테이블을 전체 삭제하는
DROP과는 명확하게 다르다. - WHERE 절을 통해 특정 레코드만 삭제도 가능하다.
TRUNCATE table_nameDELETE FROM보다 속도가 빠름.- 전체 테이블 내용 삭제 시에는 유리하다.
- 하지만 트랜잭션 내에서 동작이 불가하기 때문에 삭제한 레코드들이
DELETE와 달리ROLLBACK이 되지 않는다. 즉, 절대ROLLBACK할 필요가 없는 데이터에만 사용해야 한다. - 또한
WHERE 조건 절을 통해 특정 레코드만 삭제하는 것 역시 불가능하다.
5. 고급 SQL 문법
1) UNION, EXCEPT, INTERSECT
UNION (합집합)- 여러 개의 SELECT 결과를 가지고 합쳐서 새로운 SELECT 결과를 만들어내는 것
UNION과UNION ALL이 존재하는데UNION은 중복을 제거하지만UNION ALL은 중복을 따로 제거하지 않음
-- union을 사용한 경우
SELECT 'keeyong' AS first_name
, 'han' AS last_name
UNION
SELECT 'elon', 'musk'
UNION
SELECT 'keeyong', 'han'- 결과

UNION을 사용하면 다음과 같이 중복된 데이터는 나오지 않으므로 총 두 개의 레코드를 볼 수 있다.
SELECT 'keeyong' AS first_name
, 'han' AS last_name
UNION ALL
SELECT 'elon', 'musk'
UNION ALL
SELECT 'keeyong', 'han'- 결과

UNION ALL을 사용하면 중복된 데이터도 모두 나와 총 세 개의 레코드가 있음을 알 수 있다. 필요에 따라 중복이 된 데이터도 조회해야 하는 경우는UNION ALL을, 중복 데이터가 필요하지 않은 경우는UNION을 사용해 주어야 한다.
EXCEPT (차집합)- SELECT 결과에서 공통으로 존재하는 레코드들은 빠짐
field 수가 동일하고, field의데이터 타입이 동일해야 함테스트용즉QA로 주로 사용하고,지금 사용하고 있는 SELECT statement와 새로 만든 SELECT statement의 차이를 보고 새로 만든 SELECT가 맞게 동작하는지 확인할 수 있음.
INTERSECT (교집합)- 여러 개의 SELECT 문에서 같은 레코드들만 찾아 줌
2) COALESCE, NULLIF
COALESCE (exp1, exp2, ...)- 첫 번째 exp1부터 값이 NULL이 아닌 것이 나오면 그 값을 RETURN, 모두 NULL이면 NULL을 RETURN
- NULL 값을 다른 값으로 바꾸고 싶을 때 사용
NULLIF (exp1, exp2)- exp1과 exp2의 값이 같으면 NULL을 RETURN
3) LISTAGG
GROUP BY에 사용되는Aggregate함수 중 하나- 어떤 그룹화된 레코드 안에서 지정한 field의 값을 리스트로 나열해 줌
- 예를 들어 사용자 ID 별로 채널을 시간 순으로 보여 주고 싶을 때,
- 기본적으로 사용자 ID별로 라는 조건에서 그룹핑이 필요하다는 것을 알 수 있기 때문에
WITHIN GROUP을 사용해 준다. - 또한 시간 순으로 나열하고 싶다라는 조건이 있기 때문에
(ORDER BY TS)를 사용해 준다. - 보통
LISTAGG(컬럼명)만 하면 컬럼에 속하는 데이터들이 구분자 없이 연속해 리스트로 보여진다. 즉, 그 사이에 특정 값을 넣어 구분을 해 주고 싶다면 두 번째 attribute를 통해 구분자를 설정해 준다.LISTAGG(컬럼명, 데이터 사이의 구분자 예를 들어 ','나 '->' 등)
- 기본적으로 사용자 ID별로 라는 조건에서 그룹핑이 필요하다는 것을 알 수 있기 때문에
SELECT A.USERID
, LISTAGG(A.CHANNEL, '->') WITHIN GROUP (ORDER BY B.TS) CHANNELS
FROM RAW_DATA.USER_SESSION_CHANNEL A
JOIN RAW_DATA.SESSION_TIMESTAMP B
ON A.SESSIONID = B.SESSIONID
GROUP BY 1
LIMIT 10;- 결과

- 다음과 같이 사용자별로 채널 방문을 시간 순으로 보여 준다.
4) LAG
WINDOW 함수중 한 종류LAG(lagging하려고 하는 field명, 몇 개 이전의 레코드를 읽을 것인지) OVER (PARTITION BY 그룹핑할 field명 ORDER BY 정렬 기준 필드명)형식으로 작성한다. 이때 바로 이전의 값을 읽으려면LAG(lagging하려고 하는 field명, 1)을 하면 된다. 만약 바로 이후의 값을 읽으려면 ORDER BY의 정렬 조건을DESC(내림차순)으로 수정해 준다.- 어떤 사용자 세션에서 시간 순으로 봤을 때,앞 세션의 채널이 무엇인지 알고 싶다면?
SELECT A.*
, B.TS
, LAG(CHANNEL, 1) OVER (PARTITION BY USERID ORDER BY TS) PREV_CHANNEL
FROM RAW_DATA.USER_SESSION_CHANNEL A
JOIN RAW_DATA.SESSION_TIMESTAMP B
ON A.SESSIONID = B.SESSIONID
ORDER BY A.USERID, B.TS
LIMIT 100;- 결과
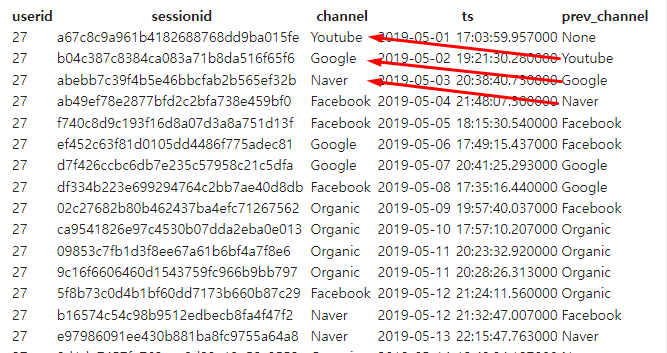
- 다음과 같이 이전 채널이 나오는 것을 알 수 있다.
- 그렇다면 다음 세션의 채널이 무엇인지 알고 싶다면?
ORDER BY조건을DESC(내림차순)으로 진행해 준다.
SELECT A.*
, B.TS
, LAG(CHANNEL, 1) OVER (PARTITION BY USERID ORDER BY TS DESC) NEXT_CHANNEL
FROM RAW_DATA.USER_SESSION_CHANNEL A
JOIN RAW_DATA.SESSION_TIMESTAMP B
ON A.SESSIONID = B.SESSIONID
ORDER BY A.USERID, B.TS
LIMIT 100;- 결과

- 다음과 같이 이후의 채널이 나옴을 알 수 있다.
5) WINDOW 함수
- ROW_NUMBER OVER
- FIRST_VALUE
- LAST_VALUE
- LAG
- Math functions: AVG, SUM, COUNT, MAX, MIN, MEDIAN, NTH_VALUE
6) JSON Parsing 함수
- JSON의 포맷을 이미 아는 상황에서만 사용이 가능한 함수이다.
- JSON string을 입력으로 받아 특정 필드의 값을 추출이 가능하다.
- 예를 들어, 이런 json 형식의 파일이 존재한다고 했을 때
f6의 값을 알고 싶다면 다음과 같은 함수를 써 주면 된다.
{
"f2": {
"f3": "1"
},
"f4": {
"f5": "99",
"f6": "star"
}
}SELECT JSON_EXTRACT_PATH_TEXT('{"f2":{"f3":"1"}, "f4":{"f5": "99", "f6": "star"}}', 'f4', 'f6');- 이런 형식이기 때문에 JSON 파일의 형식을 알고 있고, 어떤 것을 추출하고자 하는지 명확할 때는 유용하나 그렇지 않다면 UDT를 사용해 주어야 한다.
✔ [특강] 데이터 응용 유스 케이스
1. 요즈음 시대의 마케팅은?
- 마케팅 = 디지털 마케팅 = 데이터 기반 마케팅
- 디지털 마케팅이다 보니 사용자에 관한 다양하고 많은 정보들이 생긴다. (빅데이터)
- 데이터를 수집해 마케팅 성능을 측정하고 마케팅 방법을 개선하는 것이 가능해짐.
- 즉, 마케팅 데이터 수집과 분석이 중요해짐. 사이클이 짧아짐.
- 데이터 인프라 없이는 불가능.
2. 마케팅 분석 필수 데이터 - 접점 (Touch Point)
-
접점=채널=광고 미디어 - 어떤 접점을 통해서 사용자가 우리 사이트에 방문했는가에 대한 모든 기록을 해 두어야 한다.
- 이를 통해 가장 효율적인 마케팅을 알 수 있다.
최종 전환 (Macro-conversion)기록- 이는 물건 구매나 회원 가입 혹은 앱 설치처럼 마케팅의 목표
보조 전환 (Micro-conversion)기록- 방문 시 했던 행동들을 자세하게 기록하는 것이 도움됨
- 그런 기록들이 모여 최종 전환이 발생 (보조 전환이 최종 전환의 징조가 된다)
3. 마케팅 필수 측정 데이터
1) 채널 기여도 (Attribution)
- 어떤 마케팅 채널 혹은 플랫폼이 가장 효과적인가?
- 사용자별로 접점과 최종 이벤트 (구매, 가입, 설치) 등을 기록한다면 마케팅 채널별 기여도 계산이 가능- 마케팅 실험이 가능해짐
- 데이터 인프라는 바로 이 부분에서 큰 차이를 가지고 오게 됨
- 정해진 규칙이 있는 건 아니고 목표로 하고 있는 행동이나 일에 따라 어떤 채널에 기여도를 줄 것인지 모델을 정해 측정한다. (마지막 터치 모델, 마지막 비직접방문 터치 모델, 첫 터치 모델 등)
2) 고객 가치
- 고객의 평생 가치 (Lift Time Value)
- 사용자 초기 행동을 보고 이 사용자가 미래에 가져다 줄 수 있는 평생 가치를 측정하는 것이다.
- 이 예측이 맞기 시작하면 우리 서비스에 적합한 고객을 알 수 있음.
- 고객 이탈률 (Customer Churn)
- 어떤 고객이 서비스를 그만 사용할지도 예측 가능하다.
- 이게 가능하려면 고객의 여러 가지 행동을 모두 기록해야 한다.
- 이 모든 예측은 양질의 데이터 수집 및 저장 없이는 불가능하다.
4. 사용자 경로 데이터 수집의 어려움
- 앞서 접점과 최종 전환/ 보조 전환의 기록에 대해 이야기했지만 더 다양한 경로들이 존재함
- 로그인한 사용자에게만 방문을 허용하느냐에 따라 고객 정보 수집에 제약이 있음
- 정부 기관들이 온라인 개인 정보와 관련된 법률을 도입하기 시작함
- 애플과 같이 영향력이 큰 회사가 개인 정보 수집과 관련된 정책을 변경하기 시작함
-> 개인 정보를 트랙킹할 수 없게 하는 게 요즈음 추세
5. UTM - 마케팅 채널 기여도 계산 표준
Urchin Tracking Module- 기본적으로 사용자가 어떤 사이트를 방문하게 해 준 채널이 무엇인지 알려 주는 목적을 가짐
- UTM과는 별개로 구글과 페이스북은 별도의 파라미터를 유지
6. 디지털 마케팅 데이터 인프라란?
- 접점과 보조 전환/ 최종 전환 데이터의 수집이 필요
- 데이터 수집 활동 (ETL)이 있어야 하고 이를 저장해 주는 데이터베이스 (데이터 웨어하우스)가 필요 - 데이터 웨어하우스 (Data Warehouse)
- 마케팅 데이터뿐만 아니라 회사에 필요한 데이터의 중앙 창고에 해당 - 데이터 수집 활동 (ETL)
- ETL(Extract, Transform, Load) 혹은 파이프라인이라고 지칭. - 채널 기여도 계산 자동화
- 데이터 엔지니어와 분석가와 마케팅 팀 사람들이 같이 협업함- ROAS(Return On Advertising Spend)가 보통 최종 지표가 된다. 광고비 지출에 대한 수익을 의미한다.
🔎 어려웠던 내용 & 새로 알게 된 내용
- 먼저 어제 과제 풀이와 관련하여 어제자 내 풀이는 [github] 4일자 실습에 올려 두었다.
- 오늘 진행하는 것은 강사님의 풀이이다.
📚 어제 과제 풀이 1
사용자별로 처음 채널과 마지막 채널이 무엇이었는지 찾기
1) CTE 빌딩 블록을 사용
- 바로 FROM 절의 하나의 테이블 블록으로 바로
RAW_DATA.USER_SESSION_CHANNEL의JOIN 테이블로 사용해도 되지만 동일하게WITH 절을 사용하였다. 성능적인 차이보다는 쿼리 스타일의 차이라고 하셨는데 나는WITH 절을 사용하는 게 더 깔끔해서 쿼리를 보기에 이해가 빠르다고 생각되어 애용하는 것 같다.- 다른 점은 나는 하나의 쿼리에서
FIRST와LAST를 모두 넘버링하고 이 데이터를 다시 한 번 더 USERID로GROUP BY를 사용하였는데 여기는 각각FIRST와LAST의 쿼리를 생성하였다는 점이었다.WITH FIRST AS ( SELECT USERID , TS , CHANNEL , ROW_NUMBER() OVER (PARTITION BY USERID ORDER BY TS) SEQ FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID ), LAST AS ( SELECT USERID , TS , CHANNEL , ROW_NUMBER() OVER (PARTITION BY USERID ORDER BY TS DESC) SEQ FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID ) SELECT FIRST.USERID , FIRST.CHANNEL AS FIRST_CHANNEL , LAST.CHANNEL AS LAST_CHANNEL FROM FIRST JOIN LAST ON FIRST.USERID = LAST.USERID AND LAST.SEQ = 1 WHERE FIRST.SEQ = 1;2) GROUP BY 방식
- 내가 푼 풀이 방식과 가장 흡사했다. 내 풀이에서는
서브 쿼리를 사용해서 사용자별 최초 채널과 최종 채널을 조회했는데CASE-WHEN 절을 사용할 수도 있었다.SELECT USERID , MAX(CASE WHEN RN1 = 1 THEN CHANNEL END) LAST_TOUCH , MAX(CASE WHEN RN2 = 1 THEN CHANNEL END) FIRST_TOUCH FROM ( SELECT A.USERID , A.SESSIONID , A.CHANNEL , ROW_NUMBER() OVER (PARTITION BY A.USERID ORDER BY B.TS DESC) RN1 , ROW_NUMBER() OVER (PARTITION BY A.USERID ORDER BY B.TS ASC) RN2 FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID ) GROUP BY 1;3) FIRST_VALUE/LAST_VALUE
서브 쿼리나WITH 절없이FIRST_VALUE와LAST_VALUE라는 윈도우 함수를 사용하면 하나의 쿼리로 출력할 수 있다.- 단 윈도우 함수로 조회하기 위해서는 뒤에 덧붙는 것들이 있는데
ROWS와BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING이다. 이것은 창의 첫 행부터 마지막 행을 기준으로 행 집합을 지정한다는 뜻이다.SQL에서는WINDOW 함수가 유용하게 쓰이고 사용량이 많아 이는 포스팅으로 따로 작성해 보려고 한다.SELECT DISTINCT A.USERID , FIRST_VALUE(A.CHANNEL) OVER(PARTITION BY A.USERID ORDER BY B.TS ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS FIRST_CHANNEL , LAST_VALUE(A.CHANNEL) OVER(PARTITION BY A.USERID ORDER BY B.TS ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS LAST_CHANNEL FROM RAW_DATA.USER_SESSION_CHANNEL A LEFT JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID ;
📚 어제 과제 풀이 2
Gross Revenue가 가장 큰 UserID 10 개 찾기
1. GROUP BY 사용하기
- 나는 이 방법을 사용했다. 내 풀이와의 차이점은 결론적으로 이 경우 ROW_DATA.SESSION_TRANSACTION에 있는 경우만 합산이 되면 되기 때문에
INNER JOIN을 써 두 데이터의 교집합으로 계산하여도 무관하다 생각했다. 풀이에서는LEFT JOIN을 사용하였다.SELECT A.USERID , SUM(B.AMOUNT) GROSS_REVENUE FROM RAW_DATA.USER_SESSION_CHANNEL A LEFT JOIN RAW_DATA.SESSION_TRANSACTION B ON A.SESSIONID = B.SESSIONID GROUP BY A.USERID ORDER BY GROSS_REVENUE DESC LIMIT 10;2. SUM OVER 사용하기
SUM OVER라는 윈도우 함수를 사용하는 것이다.- 다만 SUM OVER를 사용할 경우 그룹핑이 되는 것이 아니기 때문에 존재하는 USERID만큼의 데이터가 나오게 되어 중복이 발생한다.
- 이 중복을 방지하기 위해
DISTINCT를 통해 중복을 막아 준다.- 이 경우보다는 그룹핑을 하는 경우가 선호된다.
SELECT DISTINCT A.USERID , SUM(AMOUNT) OVER(PARTITION BY A.USERID) FROM RAW_DATA.USER_SESSION_CHANNEL A JOIN RAW_DATA.SESSION_TRANSACTION B ON A.SESSIONID = B.SESSIONID ORDER BY 2 DESC LIMIT 10;
📚 어제 과제 풀이 3
raw_data.nps 테이블을 바탕으로 월별 NPS 계산
1) FROM 절에 서브 쿼리 사용
- 전체적인 로직은 비슷하나 나는 WITH 절을 사용했고, 풀이에서는 FROM 절에 서브 쿼리를 사용했다. 결과 값은 동일하다.
SELECT MONTH , ROUND((PROMOTERS-DETRACTORS)::FLOAT/NULLIF(TOTAL_COUNT, 0)*100, 2) NPS FROM ( SELECT LEFT(CREATED_AT, 7) "MONTH" , COUNT(CASE WHEN SCORE >= 9 THEN 1 END) PROMOTERS , COUNT(CASE WHEN SCORE <= 6 THEN 1 END) DETRACTORS , COUNT(CASE WHEN SCORE > 6 AND SCORE < 9 THEN 1 END) PASSIVES , COUNT(1) TOTAL_COUNT FROM RAW_DATA.NPS GROUP BY 1 ORDER BY 1 )2) 하나의 SELECT문 안에 SUM() 함수를 이용해서 계산하기
- 서브 쿼리나 WITH 절의 사용 없이 전체를 합산할 때 PROMOTER의 값을 1로 두고 빼야 하는 PASSIVES의 값을 -1로 둬 계산한 후에 전체 수로 나누어 계산하는 다음과 같은 방법도 있었다.
SELECT LEFT(CREATED_AT, 7) AS "MONTH" , ROUND(SUM(CASE WHEN SCORE >= 9 THEN 1 WHEN SCORE <= 6 THEN -1 END)::FLOAT*100/COUNT(1), 2) NPS FROM RAW_DATA.NPS GROUP BY 1 ORDER BY 1;
✍ 회고
- SQL은 모든 데이터 직군에서 필요한 기술이라는 걸 강조하셨다. 데이터를 다루기 위해서는 SQL이 쓰이지 않는 곳이 거의 없기 때문에 이 부분에 대해 공감했고, SQL 공부 소홀히 하지 말아야 되겠다 생각했다.
- 트랜잭션의 경우 배치를 돌릴 때 주로 사용했던 기억이 있는데 그 당시에는 PL/SQL을 사용했어서 BEGIN END;를 사용했는데 이번 실습에서는 BEGIN; END;로 BEGIN 문 뒤에도 세미콜론(;)이 붙는 게 문법의 차이인가 궁금했다.
- WINDOW 함수는 많이 쓰이는 함수 같아서 꼭 따로 공부하고 포스팅을 해 두어야 되겠다 생각했다.
- 오늘 특강에서는 데이터 엔지니어들이 실제로 어떤 데이터를 어떻게 사용하는지를 설명해 주셨는데 디지털 마케팅과 헬스 케어를 중점으로 설명해 주셨다. 의료 IT 분야에서 일한 경험을 바탕으로 헬스 케어에서 데이터가 쓰이는 부분의 강의를 들을 때 공감 가는 부분이 많았다. 개인적으로는 디지털 마케팅 분야에 대해서 데이터가 얼마나 중요한지는 알고 있었지만 처음 현업의 입장으로 자세하게 듣게 된 강의라 흥미로워서 TIL에 작성을 해 두었다.

송의 개발 LOG