
📚 오늘 공부한 내용
👊 팀 프로젝트 - TOUR API를 이용한 관광 인프라 및 추이 대시 보드
1. 데이터 모델링
- 내 담당인 각 코드들의 정보를 담고 있는
CODE_DETAIL테이블에 데이터를 적재하기 위해csv파일로 만드는 과정에서 이전 모델링에서 문제가 있다는 것을 발견했다. -
TOUR API를 직접 조회해 보기 전에는 알지 못했던 부분인데 고유의 값인 줄 알았던CITY_CODE즉, API에서는SIGUNGUCODE가 고유의 값이 아니라AREA_CODE와 연관되어 있었고, 중복이 발생할 수도 있다는 부분이었다. - 데이터로 설명을 해 보자면
AREA_CODE가 1이면 서울, 2면 인천인데CITY_CODE가AREA_CODE=1의 경우 1이 강남구였고,AREA_CODE=1의 경우 1이 강화군이었다.CITY_CODE는 고유의 값이 될 수 없었고, 테이블 구성 역시 바꿔야 했다.
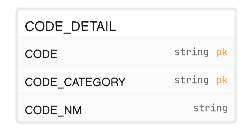
- 이전은
CITY_CODE에 서로 중복이 없을 거라 생각했기 때문에CODE_CATEGORY로 구분을 두면 되겠다고 생각했는데 만약 이 구조로 가게 된다면CODE = 1 AND CODE_CATEGORY = 1인 데이터가 특별시, 광역시, 특별자치시, 도마다 하나씩 존재하기 때문에 pk 오류가 발생할 수밖에 없어 다음과 같이 수정해 주었다.
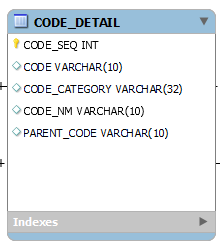
SEQ를 통해 중복이 발생하지 않고 각 CODE의 고유 값이 생기게 해 주었다.- 또한
CITY_CODE는 각각AREA_CODE에 종속돼 있기 때문에AREA_CODE가 일종의 부모 개념이라고 생각되어PARENT_CODE컬럼을 추가해 주었다. - 덕분에 다른 테이블에서
CITY_CODE와AREA_CODE가 같이 들어 있던 부분도CODE_SEQ라는 하나의 값으로 변경되게 되었다.
📌 최종 ERD

2. 공공 API를 통해 csv 파일 적재
1) 호출할 API 서비스 연결
- 나는
AREA_CODE에 속해 있는 각각 도시의CITY_CODE를 조회해야 했기 때문에 다음과 같은 URL을 사용해 주었다. - 개인적으로 조금 헷갈렸던 부분은 공공 API에서 제공하는
API_KEY가ENCODING과DECODING버전 두 개가 있는데 어떤 KEY를 주어야 할지가 헷갈렸다. - 결론은
DECODING버전을 파라미터로 넘겨 주면 된다.
import urllib
import json
from pprint import pprint
import requests
import pprint
key = '발급받은 api_key'
url = 'http://apis.data.go.kr/B551011/KorService1/areaCode1' #호출할 서비스의 url2) API 서비스 호출
- 파라미터의 경우 각 공공 API에서 제공하는 메뉴얼에 훨씬 상세하게 나와 있다. NULL을 입력할 수 없고 필수적으로 입력해야 하는 파라미터들도 정해져 있으니 꼭 확인하는 것을 추천한다.
- 해당 파라미터를
requests.get을 통해 url과 함께 넘겨 주었다.
params ={'serviceKey' : decoding ,
'pageNo' : '1',
'numOfRows' : '100',
'MobileOS' : 'ETC',
'MobileApp' : 'AppTest',
'areaCode' : 1
}
response = requests.get(url, params=params)
seoul_content = response.text
seoul = pprint.PrettyPrinter(indent=4)
print(seoul.pprint(seoul_content))- 이렇게 넘기면 다음과 같이
xml파일이 나오게 되고, 나는CITY_CODE를 쌓아 주어야 해서 모든AREA_CODE별로 추출해 주었다.

- 사실 파라미터를 다중으로 넘길 수 있는 방법이 없나 찾았지만 다중 파라미터가 없어
AREA_CODE별로 리스트에 추가해 주어야 했다. - 적재한 데이터를
pandas를 통해DataFrame으로 만들어 준다.
from os import name
import xml.etree.ElementTree as et
import pandas as pd
import bs4
from lxml import html
from urllib.parse import urlencode, quote_plus, unquote
xml_obj = bs4.BeautifulSoup(seoul_content,'lxml-xml')
rows = xml_obj.findAll('item')
row_list = [] # 행값
name_list = ["CODE", "CODE_CATEGORY", "CODE_NM", "PARENT_CODE"] # 열이름값
value_list = [] #데이터값
# 서울
for i in range(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집
for j in range(0,len(name_list)):
if j == 0:
value_list.append(columns[1].text)
elif j == 1:
value_list.append("CITY")
elif j == 2:
value_list.append(columns[2].text)
else:
value_list.append("1")
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]
df = pd.DataFrame(row_list, columns=name_list)
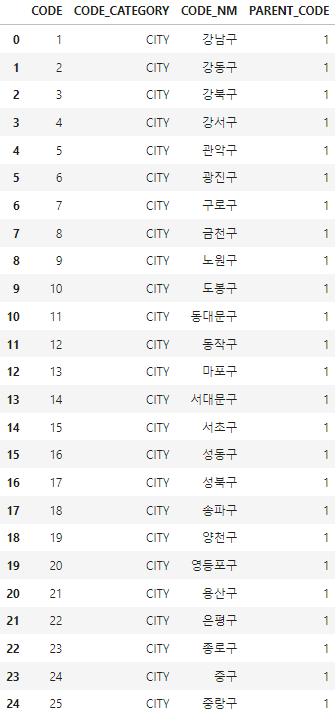
df - 이렇게 출력 값이 나오게 되며 이 값을
df.to_csv('city.csv', encoding='utf-8-sig')로 csv 파일로 추출해 주었다.
3. S3에 csv 넣어 Redshift 환경에 Bulk Update
- 추출된 csv를 넣어 Redshift 환경에 업데이트 해 주었다.
- 또한 벌크 업데이트 시 컬럼은 선택해 줄 수 있는데 각 컬럼들을 쿼리문을 통해 가공해 줄 수는 없었다.
✔ 특강 - 사용자 행동 데이터 수집과 분석
1. 사용자 행동 데이터 분석
- 사용자 행동 데이터 분석은 제품 분석, 디지털 분석을 말한다.
- 이를 가능하게 해 주는 툴을 제품 분석 플랫폼 (Product Analytics Platform)이라고 부른다.
- 제품/서비스에 대한 사용자 행동을 분석하고 이해하는 데 도움이 되는 툴이며 데이터 기반의 의사 결정을 내리고 제품 성능을 개선할 수 있는 귀중한 인사이트를 제공한다.
2. 제품 분석 플랫폼의 특징과 기능
-
사용자 행동 데이터 수집
- 웹사이트, 모바일 앱, 백엔드 시스템 등 다양한 소스에서 데이터를 수집해 사용자 행동에 대한 충분한 데이터를 마련한다.
-
사용자 세분화(User Segment)
- 특정 속성이나 행동에 따라 사용자 그룹을 세분화하고 분석 시 사용자 세분화에 따른 차이점과 인사이트를 제공한다.
-
퍼널 데이터
- 각 사용자별로 아래를 기록한다.
- 사용자의 행동은 여러 스테이지에 걸쳐 이루어진다.
- 최종적으로 원하는 행동이 있을 경우 처음 단계부터 최종 단계를 단계별로 기록하고 각 단계로 넘어갈 때마다 이탈율이 얼마나 발생하는지 기록한다.
- 예를 들어 회원 등록이나 상품 구매 등에서 사용된다.
-
코호트 분석
- 공통된 특성이나 행동에 따라 사용자를 그룹화해 시간 경과에 따라 사용자를 분석한다.
- 서로 다른 코호트를 비교한다.
-
A/B 테스트
- 기능 변경이 사용자 행동 및 주요 지표에 미치는 영향을 평가하기 위해 A/B 테스트를 한다.
-
사용자 리텐션 분석
- 주어진 달을 기준으로 많이 하게 되며 달에 처음 방문한 사람이 몇 명이고, 그 사람들 중 몇 명이 다음 달, 다다음 달에도 방문을 하는지 기록하며 잔존율을 분석한다.
- 이를 통해 사용자 유지에 영향을 미치는 요인을 파악한다.
-
데이터 시각화 및 리포트 생성
-
다른 툴과의 통합 기능 제공
3. 사용자 행동 이벤트 정의
- 사용자가 온라인 서비스 내에서 수행하는 특정 작업 또는 상호 작용한다.
- 이러한 이벤트는 사용자 행동을 포착해 다양한 분석을 가능하게 한다.
- 사용자 관점에서의 user와 사용자가 행동할 시 발생하는 이벤트 event 두 가지 포맷을 가지게 된다.
- user
- ID, Version
- Country, City, Region
- Carrier, Platfor
- event
- Name, Timestamp
- Session ID, Referrer
- Custom properties
- user
- 사용자 수가 많아질수록 정보의 양이 방대해지기 때문에 보통은 바로
데이터 웨어하우스에 적재하는 것이 아닌데이터 레이크에 저장해 두고 필요 시 가공하여 데이터 웨어하우스에 적재한다.
4. 사용자 행동 분석 플랫폼
- 앰플리튜드 (Amplitude)
- 구글 애널리틱스 (GA, Google Analytics)
- 믹스 패널 (Mixpanel)
- 힙 애널리틱스 (Heap Analytics)
- 키스메트릭스 (Kissmetrics)
- 스노우플로우 애널리틱스 (Snowplow Analytics)
5. 구글 애널리틱스 (GA, Google Analytics)
1) 구글 애널리틱스(GA, Google Analytics)란?
- 인력이 없을 경우 가장 처음 시작할 수 있는 프로덕트, 마케팅 분석 툴이다.
- 무료 버전으로 시작할 수 있지만 사용자별 데이터 덤프는 불가하다.
- 사이트 트래픽 분석 기능을 제공한다.
- 마케팅 채널/캠페인 기여도 분석 기능을 제공한다.
2) 구글 애널리틱스로 할 수 있는 일
- 몇 명의 방문자가 있고 몇 개의 세션이 있는지
- 어디서 방문하는지 (터치 포인트)
- 얼마나 오래 머무르는지 (총 세션의 길이)
- 어느 페이지들을 방문하는지
- 어느 페이지에서 가장 많은 사이트를 나가는지 (이탈율)
- 방문자들의 인구 통계 정보
3) 구글 애널리틱스의 방문자 (User)
- 쿠키를 이용해 방문자별로 유일한 식별자를 부여한다.
- 이 식별자는 디바이스마다 부여가 되며 사이트에 로그인한 사람을 기준으로 카운트를 하는 것이 아니다.
4) 구글 애널리틱스의 세션 (Session)
- 사용자는 하루에도 한 사이트를 다른 목적을 가지고 여러 번 방문할 수 있는데 이 방문을 세션이라고 한다.
- 총 방문자보다 총 세션의 수가 더 많다.
- 정의
- 시간 기반
- 30 분 이상 아무 행동도 취하지 않으면 세션 종료
- 구글 애널리틱스에 정한 시간대로 자정이 넘어가는 순간 세션 종료
- 캠페인 기반
- 세션이 끝나기 전이라도 새로운 캠페인을 타고 다시 방문하면 기존 세션 종료 후 새 세션 시작
- 세션에는 세션을 시작하게 한 캠페인 정보(접점 정보)가 태그
- 시간 기반
5) 리퍼럴 (referral)
- 웹에서 리퍼럴이란 링크를 타고 한 페이지에서 다른 페이지로 넘어가는 것을 말한다.
- 예를 들어 A에 있는 링크를 클릭해 B 페이지로 넘어가는 경우 페이지 B의 리퍼럴 페이지는 A가 된다.
- 사용자들의 방문 경로(접점)을 알 수 있다.
- 마케팅 분석의 경우 리퍼럴에 대한 더 자세한 정보가 필요하다.
- 그렇기 때문에 UTM 파라미터가 사용된다.
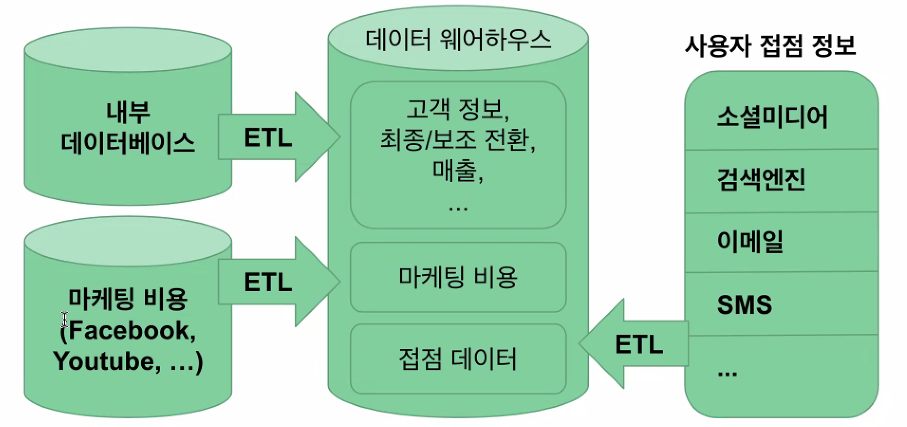
📌 마케팅 접점 데이터 레이어
- 마케팅 접점 데이터 수집 레이어
- 마케팅 접점 데이터와 고객/전환 데이터 저장 레이어
- 마케팅 접점 데이터 분석/시각화 레이어
- 채널별 마케팅 비용
ROAS(Return On Advertising Spend) 시 필요
두 가지 방법으로 다음과 같이 마케팅 접점 데이터 저장 (ETL)을 해 줌
- SaaS (FiveTran, Stitch Data, Segment 등의 툴)을 사용하는 방법
- 직접 ETL을 구현하는 방법
🔎 어려웠던 내용 & 새로 알게 된 내용
📌 SEQ를 지원하지 않는 REDSHIFT
- Redshift는
SEQ기능을 지원하지 않았다. 사실SEQ를 사용하는 게 중복이 발생하지 않게 하는 데 좋을 것이라는 생각에 CREATE를 할 때 컬럼에 default 속성으로NEXTVAL를 부여하려고 했는데 REDSHIFT에는 지원하지 않는 기능이라고 했다.- 물론
PostgreSQL에서 지원하지 않는 기능은 아니다.SEQ기능은PostgreSQL에서는 지원하지만REDSHIFT에서 지원하지 않을 뿐이다.- 그래서 csv 자체에서 SEQ를 추가해 주어야만 했다.
📌 Bulk Update 시 unsupported UTF8 오류 발생
- 처음 알게 된
SQL옵션이 있어서 따로 포스팅 해 두었다.- 🔑 csv 파일 벌크 업데이트 시 invaild or unsupported UTF8 오류 발생
✍ 회고
- 새로운 프로젝트가 시작되었다. 매번 실습 시에 메모를 해 둔 게 큰 도움이 되었다. Redshift에 벌크 업데이트를 할 때 오류가 발생하기는 했지만 그 과정이 그렇게 어렵지는 않았다. 다만 가공해서 csv 파일로 생성하는 게 조금 어려웠다. API가 다중 파라미터를 넘길 수 없기도 했고, 하나의 코드가 아닌 여러 서비스에서 다양한 코드를 가지고 오는 코드 마스터다 보니까 추출 과정이 일일이 값을 넣어 주어야 해 이게 맞나 싶긴 했었다. 그래도 적재는 잘 되어서 다행이다.
- 별개의 이야기지만 airflow 북 스터디를 시작하였다. 데이터 파이프라인에 대해 겪어 보고 싶었는데 큰 도움이 될 것 같다.

송의 개발 LOG