
📚 오늘 공부한 내용
1. 구글이 데이터 분야에 끼친 영향
1) 구글의 검색 엔진 변화
- 그 전까지의 검색 엔진은 기본적으로 웹 페이지 상의 텍스트를 보고 랭킹을 결정했다.
- 1998 년 구글은 웹 페이지들간의 링크를 기반으로 중요한 페이지를 찾아서 검색 순위를 결정한다.
- 이 알고리즘을 래리 페이지 이름을 따서
페이지 랭크라고 부른다. - 시작점을 만들고 그 웹 페이지에서 링크를 건 다른 웹 페이지에서 점수를 주고 이 방법을 반복하다 보면 어느 순간부터는 점수가 바뀌지 않게 된다.
- 2004 년 세계 최고의 검색 엔진으로 등장했다. 이 시점부터 검색 마케팅 플랫폼으로 확장하고, 안드로이드로 모바일 생태계를 지배하고 유튜브를 인수하면서 스트리밍 시장을 석권했다.
- 다양한 논문을 바탕으로 오픈 소스를 공유하며 개발자 생태계에도 영향을 미쳤다.
- 검색 엔진은 처음에는 배치 중심이었으나 사람들의 니즈에 따라 실시간 중심으로 바뀌게 되었다.
2) 페이지 랭크
- 두 가지 관찰을 기반으로 만들어진 알고리즘이다.
- 더 중요한 페이지일수록 더 많은 페이지로부터 링크를 받는다.
- 이 중요한 페이지가 링크를 건 다른 페이지들 역시 상대적으로 중요한 페이지이다.
- 분산 파일 시스템과 분산 처리 시스템이 존재하지 않으면 이 방식을 알아도 사용할 수 없다.
- 구글이 페이지 랭킹 이외에도 다른 검색 엔진 아키텍처 논문을 외부에 공개했다.
- 웹 페이지 본문 텍스트가 아닌 링크 텍스트도 중요
- 링크에 있는 원문 페이지의 중요도 역시 고려 필요
3) 빅데이터 시대 초래
- 빅데이터 처리를 구글이 어떻게 했는지 공개한 논문
- 2003 년 The Google File System
- 2004 년 MapReduce: Simplified Data Processing on Large Cluster
- 이를 바탕으로 하둡이라는 오픈 소스 프로젝트가 진행되었고, 이 기술이 빅데이터 처리를 가능하게 해 줌
- 또한 하둡을 시작으로 오픈 소스 활동이 활발해짐
- 머신러닝, 인공지능의 발전을 가속화함
4) 검색 기술, 마케팅 결합 - 구글 애드워즈
- 오버추어가 시작한 웹 검색 광고를 발전시켜 구글 애드워즈로 명명했다. -> 구글 애즈 (Ads)
- 구글과 오버추어의 검색 마케팅 방법의 차이
- 오버추어가 먼저 시작했지만 반드시 사람이 있어야만 했기 때문에 비효율적이었음 (검색어 경매 방식, 시간이 오래 걸림)
- 구글은 웹 기반 자동화를 염두에 두고 만들어 사람 개입 없이 검색어 경매와 광고 시스템을 구축함
- 검색어 광고의 성능에 따라 노출 빈도가 결정
2. 데이터 처리의 발전 단계
1) 데이터의 일반적 단계
- 데이터 수집 (Data Collection)
- 데이터 저장 (Data Storage)
- 데이터 처리 (Data Processing)
2) 데이터 저장 시스템의 변천
- 1980 년대 후반에는 데이터 웨어하우스가 주였고, 이 방식은 Top-down. 정말 필요한 것들만 저장하는 방식으로 데이터를 저장함.
- 2000 년대 후반에는 큰 데이터를 처리하고 이를 저장하는 스토리지는 비용이 많이 들지 않아 Data Lake 방식으로 바뀜. Bottom-up. 보통은 Data Lake와 Data Warehouse를 같이 사용함.
- 2010 년 중반부터는 Cloud Data Platform이 나오면서 이전에는 배치 중심이었지만 실시간 데이터 처리가 요구되면서 Kafka와 Kinesis 같은 Messaging Queue가 나오게 됨.
- 2021 년 이후 Data Mesh 형식으로 중앙 시스템 구조에서 분산 시스템으로 바뀌게 됨.
3) 데이터 처리의 고도화
- 처음에는 배치로 시작. 이 경우 처리할 수 있는 데이터의 양이 중요하다.
- 서비스가 고도화되며 점점 더 실시간 처리 요구가 생기기 시작했다.
- 배치이긴 한데 주기가 작거나 한 번에 처리하는 데이터의 양이 작은 배치 처리를 Near Realtime, Semi Realtime이라고 한다.
3. 실시간 데이터 처리
1) 처리량 (Throughput) vs 지연 시간 (Latency)
- 처리량은 주어진 단위 시간 동안 처리할 수 있는 데이터 양을 말한다. 이는 배치 시스템에서 중요하다.
- 지연 시간은 데이터를 처리하는 데 걸리는 시간이 얼마나 되는가를 말한다. 작을수록 응답이 빠름을 의미하며 Production 프로그램과 같은 실시간 시스템에서 매우 중요해진다.
대역폭 (Bandwidth) = Throughput * Latency
2) SLA (Service Level Agreement)
- 서비스를 제공하는 업체와 고객 간의 계약 또는 합의를 말한다.
- 서비스 제공 업체가 제공하는 서비스 품질, 성능 및 가용성의 합의된 수준을 개괄적으로 기술한다.
- 사내 시스템들 간에도 SLA를 정의하기도 한다.
- 이 경우 지연 시간이나 업타임 등이 보통 SLA로 사용된다. (필요에 따라 구체적으로 정의되는 경우도 존재함)
- 예를 들어 업타임이 99.9 % = 8 시간 45.6 분
- API라면 평균 응답 시간 혹은 99 % 이상 0.5 초 전에 응답이 되어야 함
- 데이터 시스템이라면 데이터의 시의성(Freshness)도 중요한 포인트가 된다.
3) 배치 처리
- 주기적으로 데이터를 한 곳에서 다른 곳으로 이동하거나 처리하는 것을 말한다.
- 보통 여기서 말하는 주기는 daily, hourly가 일반적이며 더 짧아진다면 5 분, 10 분 역시 배치로 볼 수 있다.
- ETL로 관리되는 것이 일반적이다.
- 분 단위보다 짧아진다면 airflow로 돌리기 애매해지고 spark 등으로 프로세싱을 한다는 게 불가능하기 때문에 데이터 처리가 부적합해지기 때문에 실시간 프레임워크가 필요해진다.
- 처리량(Throughput)이 중요하다.
- 처리 시스템 구조
- 분산 파일 시스템 (HDFS, S3)
- 분산 처리 시스템 (MapReduce, Hive/Presto, Spark DataFrame, Spark SQL)
- 처리 작업 스케줄링에 보통 Airflow 사용
4) 실시간 처리

- 연속적인 데이터 처리를 말하며 배치 처리 다음의 고도화 단계이다.
- 시스템 관리의 복잡도가 증가한다. 데이터가 발생하는 족족 들어오는 것이기 때문에 발생하는 데이터가 유실될 가능성이 높아진다.
- 초 단위의 계속적인 데이터를 처리한다.
- 이때 계속적인 데이터를 Event라고 부르며 이 데이터는 한 번 생성되면 바뀌지 않는 데이터(Immutable) 데이터이다.
- 계속해서 발생하는 Event들을 저장하는 곳을 Event Stream 혹은 Message Queue이라고 부른다. (Kafka에서는 이를 Topic이라고 부름)
- 이 경우 다수의 Consumer가 있어서 Queue로부터 데이터를 읽어서 처리한다. 또한 Consumer마다 별도의 포인터를 유지하지만 다수의 Consumer(Consumer Group)가 데이터 읽기를 공동으로 수행하기도 한다.
- 실시간 처리만을 위한 다른 형태의 서비스들이 필요해지기 시작했다.
- 이벤트 데이터 저장하기 위한 메시지 큐: Kafka, Kinesis, Pub/Sub 등
- 이벤트 처리를 위한 처리 시스템: Spark Streaming, Samza, Flink 등
- 이런 형태의 데이터 분석을 위한 애널리틱스/대시보드: Druid 등
5) 람다 아키텍처 (Lambda Architecture)
- 배치 레이어와 실시간 레이어 두 개를 별도로 운영된다.

- 초기 람다 아키텍처이다.
- 데이터가 생성이 되면 분산 파일 시스템에 저장을 하고 주기적으로 Batch Layer에서 데이터를 업데이트하고 이 정리된 데이터를 어딘가에 저장해 둔다. Speed Layer에서는 실시간 데이터를 배치 데이터의 주기 사이 갭을 줄여 주는 용도로 최근 데이터만 빠르게 처리해 저장해 준다.
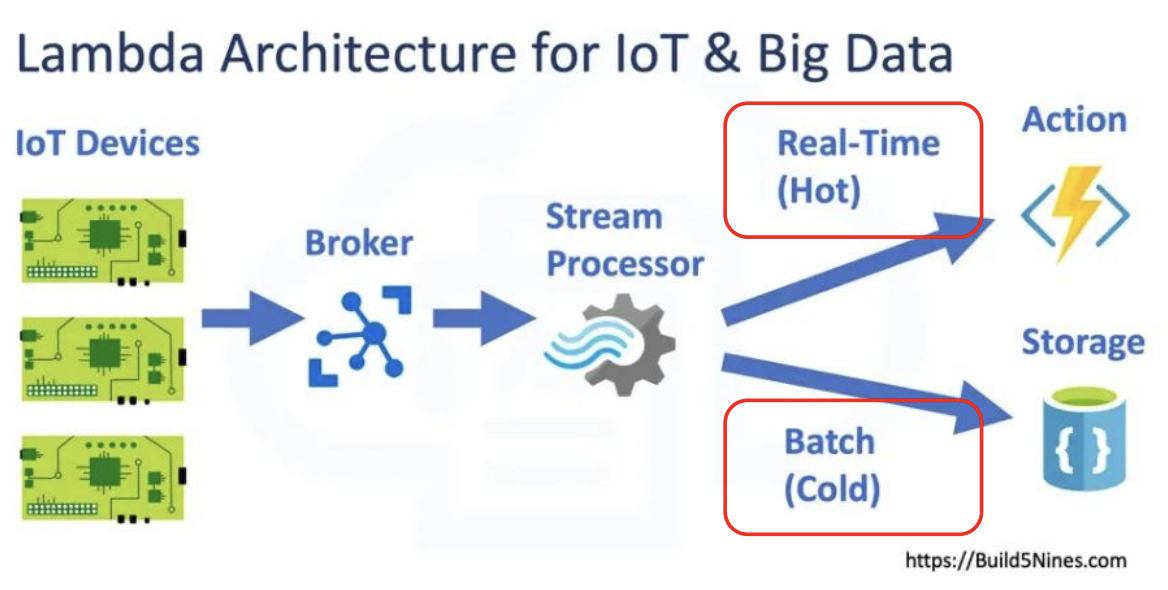
- 최근 더 많이 쓰이는 아키텍처이다.
- 데이터 수집 자체를 별도로 하지 않고 streaming message queue로 한 번에 처리한다.
- 저장된 데이터를 일부는 배치, 일부는 realtime으로 프로세싱 한다.
4. 실시간 데이터 처리 챌린지
1) 실시간 데이터 처리 단계
- 이벤트 데이터 모델을 어떻게 정의할 것인지에 대한 결정 (만약 문제가 생기면 alert을 보내고, 데이터가 제대로 원하는 방향으로 들어오는지도 확인 필요)
- 이벤트 모델에 맞추어 데이터를 생성한 뒤 이 데이터를 어떻게 잘 수집하고 저장할 것인가 (데이터 프로듀서가 작업)
- kafka를 누가 운영하고 관리할 것인가 (일반적으로 DevOps)
- 이벤트 데이터 처리
- 이벤트 데이터와 관련된 kafka 자체의 모니터링, 데이터 시의성이 깨지는지 아닌지 등의 데이터 이슈를 확인하는 모니터링 및 해결
2) 이벤트 데이터 모델 결정
- 최소 Primary Key와 Timestamp는 필요하다.
- 사용자 정보가 필요할 수 있다.
- 해당 이벤트 자체에 대한 세부 정보가 필요하다.
3) 이벤트 데이터 모델 전송 및 저장
- Point To Point
- Producer와 Consumer가 바로 연결된다.
- 즉, Latency가 존재하지 않는다.
- Producer가 데이터를 생성하는 비율보다 Consumer가 데이터를 소비하는 비율이 더 느리면 데이터가 쌓이게 되고, 데이터가 밀리고 유실될 가능성이 있다. -> Back pressure
- Messaging Queue
- 중간에 데이터 저장소를 두고 Producer가 만든 데이터가 Consumer에게 바로 가는 것이 아니라 필요할 때 데이터 저장소에서 데이터를 가지고 갈 수 있다.
- Consumer가 기간 내 데이터를 조회하지 않는 경우 기간이 지나 데이터가 사라질 수도 있지만 Back pressure를 완화할 수 있다.
- Producer와 Consumer가 일대일로 연결하지 않아도 돼서 더 scalable하다.
🔎 어려웠던 내용 & 새로 알게 된 내용
📌 Realtime vs Semi Realtime
- Realtime
- 짧은 Latency
- 연속적인 데이터 스트림
- 특정 event에 의해 데이터 처리가 트리거 되는 구조로 처리가 이루어진다. 즉, 이벤트 중심의 아키텍처이다.
- Semi Realtime
- 합리적인 Latency
- 배치와 유사한 처리
- 처리 용량과 리소스 활용도를 높이기 위해 일부 즉각성을 희생하기도 한다. 즉, 이벤트에 의해 반응하는 것이 아닌 주기적인 업데이트가 발생한다.
📌 Backpressure
- 스트리밍 시스템에서 데이터는 일반적으로 일정한 속도로 생성하게 되는데 가끔 트래픽이 몰리면 데이터 생성이 폭발적으로 일어날 수 있다. 그러면 훨씬 더 많은 데이터가 생성이 될 거고 그게 모두 소비가 되어야만 뒤에 있는 데이터들이 모두 처리가 될 수 있다.
- 그래서 데이터가 들어오는 속도를 따라잡지 못해 데이터가 쌓이면서 메모리 사용량이 증가하고 이로 인해 잠재적인 시스템 장애를 초래할 수 있다.
- Backpressure는 Point-to-Point 단계에서 심화되며 Messaging Queue로 완화할 수는 있지만 완전히 해결은 불가능하다.
✍ 회고

송의 개발 LOG

정말 좋은 정보 감사합니다!