
📚 오늘 공부한 내용
1. Next Feature Fallacy
- Product를 Reading하는 사람이 자신감이 떨어지는 경우 Product의 방향에 대해 고민하는 것이 아니라 새로운 기능을 추가하는 걸 생각한다거나 그런 식으로 숲 대신 나무를 보게 되는 현상을 말한다.
- 지표가 많아질수록 의사 결정을 잘할 수 있을 거라는 착각을 하게 된다. 하지만 지표의 수가 많아지면 지표들끼리 다른 결과를 도출할 수 있다. 그러므로 지표는 적을수록 좋다.
- 또한 지표가 많아지면 지표를 운영하기 위한 노력이 들어가게 된다.
- Primary Matrix, Secondary Matrix 정도만 정의해 두는 것이 좋다.
2. 추천 엔진
- Explore: 사용자가 어떻게 반응하는지 보기 위해 다양한 반응을 보는(탐색하는) 것. 만약 클릭을 했다면 긍정적인 반응, 하지 않았다면 부정적인 반응. 이를 통해서 그 사람이 관심 있는 부분이 무엇인지를 파악할 수 있음.
- Explode: explore한 내용을 기반으로 그 사람의 취향에 맞추어 추천해 주는 서비스.
✍️ Regression Toward the Mean
- 처음에는 불규칙적이어도 결국은 원래 성과가 나오게 된다. 즉, 평균으로 회귀한다.
- 극단적이거나 비정상적인 관측 값 뒤에 일반적이고 평균적인 관측 값이 뒤따를 가능성이 높다는 것을 시사하는 통계적 현상이다.
- 예를 들어 신인일 때 굉장히 잘하는 사람들이 있는데 그 사람이 우연히 잘하는 것이고 2, 3 년차가 쌓이면서 실력이 낮아지는 경우도 존재한다. 이를 소포모어 징크스라고 부르며 그것과 동일한 현상이다.
- 강의와 같은 개인별 관심 여부가 많이 달라지는 영역에서는 더 심해지는데 더 많이 노출될수록 관심이 없는 사람들에게 노출될 가능성이 높아지면서 평점이 내려간다.
- 데이터 일을 하게 되면 많이 듣게 되는 용어.
3. Nginx
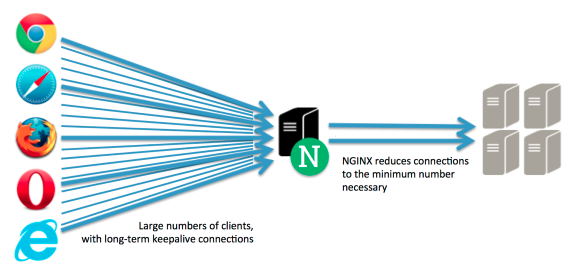
- 보통 웹 서버들의 앞단에
로드 밸런서(Load Balancer)로 사용한다. - 동시에 요청을 로그하는 데 사용한다.
- 이벤트 로그를 가장 쉽게 남기는 방법은
Nginx이다. 사용자가 어떤 행동을 했는지Nginx가로그 configuration으로 바꾸어 저장소에 저장한다. - HTTP 요청 헤더와 응답 헤더 내용을 기록한다. 보통 이 로그를
logtash등의 툴을 사용해서 HDFS나 Kafka로 푸시된다. Kafka관점에서는logtash가 Producer가 된다.
4. 클라우드를 사용하면 좋은 점
On-Prem에서 직접 운영하는 게 문제가 되는 이유는 서버 용량 확장에 걸리는 시간이 존재한다. 주문 -> 배달 -> 조립 -> 설치 과정을 다 거쳐야 하기 때문에 서버 몇 대를 추가하는 데도 몇 달이 걸리게 된다. -> 기회 비용이 많이 든다.클라우드를 사용하게 되면 서버 용량 확장 시 걸리는 시간이 감소하고, 클라우드에서 제공하는 서비스들이 존재하기 때문에 필요한 기능이 서비스로 존재한다면 그 서비스를 사용하면 된다. 그렇게 되면 비용적으로는 더 많은 비용이 들지 몰라도 기회 비용이 줄어들게 된다. 또한 S3와 같은 스토리지를 경제적으로 쓸 수 있기 때문에 데이터 시스템 발전에 큰 도움이 된다.
5. 실시간 추천 엔진 아키텍처

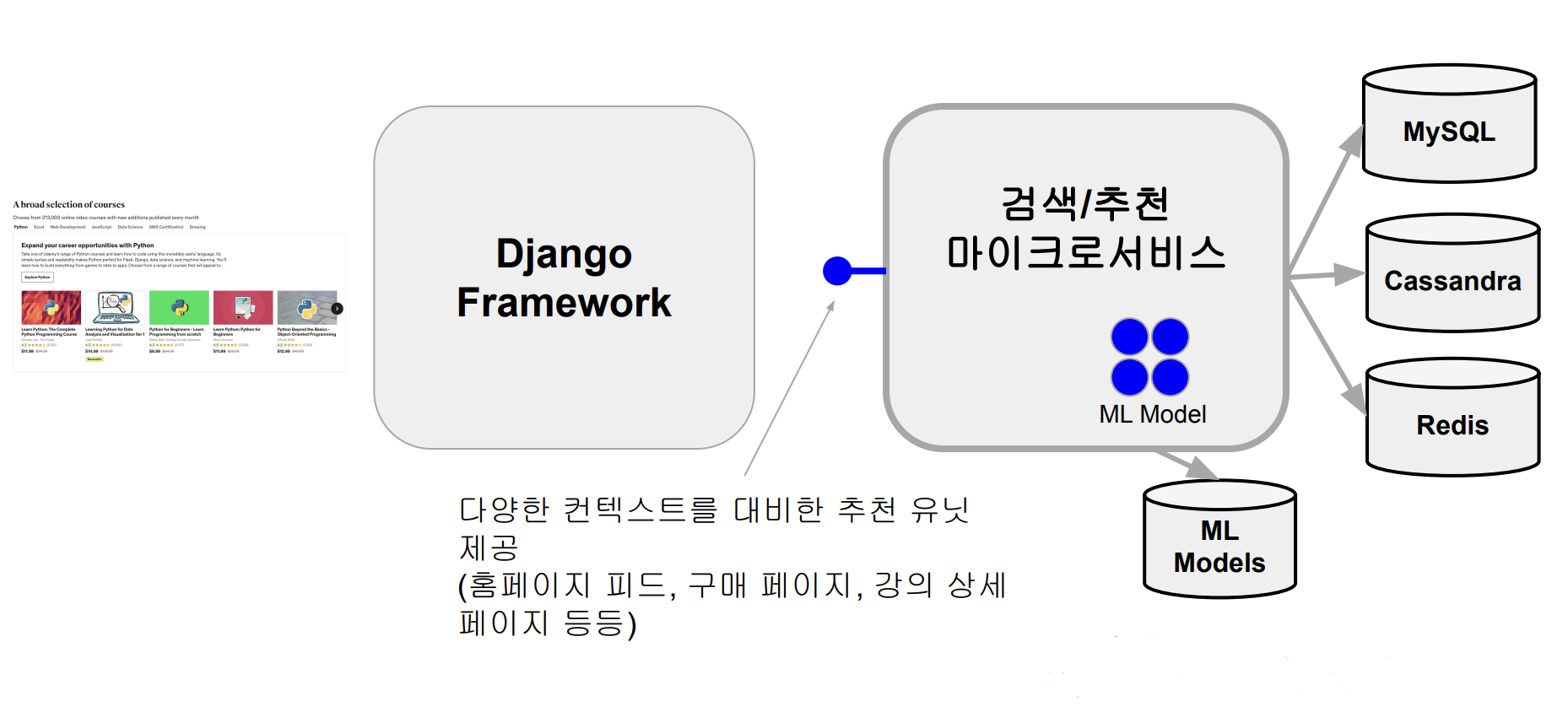
- 어떤 사용자가 나타났다는 이벤트가 kafka Topic에 기록이 되고, 이걸 바탕으로 Spark Streaming 코드가 트리거 되면서 사용자에게 추천될 내용들을 계산하기 시작한다.
- 그와 동시에 Django Framework에서 사용자에 대한 추천 내용을 불러 주기 위한 검색/추천 마이크로 서비스를 호출해 주고, ML Models들 안에 있는 데이터들을 호출해 어떤 데이터들을 어떤 포맷으로 보여 주게 될 것인지 JSON 형태로 리턴하게 되는데 이 과정에서 다양한 백엔드 서비스(MySQL, Cassandra, Redis)를 Look up한다.
- 최대한 빨리 Return을 해 주어야 홈페이지 피드에 보이게 된다. 그렇기 때문에 검색/추천 마이크로 서비스는 Latency가 중요하다.
🔎 어려웠던 내용 & 새로 알게 된 내용
Avro vs Parquet
- 컬럼 기반은 Throughput이 매우 중요한 데이터를 분석할 때, 하지만 실시간처럼 Latency가 중요한 경우에는 로우 기반이 더 선호된다.
- Avro는 Row-based 데이터 포맷이며 Binary 포맷이다.
- Column-based인 PARQUET의 경우 대용량 데이터에서 많이 선호되어 DW 등 데이터 분석용으로 배치 쿼리 수행 시 더 적합하다.
- Avro의 경우 데이터 송수신이나 스키마 변경 감지 등 실시간 처리 데이터 포맷에 최적화되어 있다.

✍ 회고
- 이번 회차는 강사님이 Udemy에 있을 때 추천화 서비스를 어떻게 구현했고 데이터 팀이 어떻게 변화해 왔는지에 대해 설명해 주었다. 개인적으로 데이터 팀이 구축되어 가는 과정은 특강 때도 들었는데 다시 들으면서 뭔가 데이터 팀 변화의 흐름을 경험해 보고 싶다라는 생각이 들었다. 또 실제 추천화 서비스가 어떻게 아키텍처가 형성이 되고 구현이 되었는지 알게 되어 좋았다. 언젠간 사이드 프로젝트로 해 보고 싶었던 주제가 개인화 기반 추천화 서비스였는데 nginx를 알게 돼서 이를 활용해 보면 어떨까라는 생각을 하게 됐다.
- 이번 건 기억하고 싶은 개념적인 것 위주로만 TIL에 작성했다.

송의 개발 LOG


정말 좋은 정보 감사합니다!