.png)
서론
방학이 시작되고 슬슬 한이음 프로젝트에 불을 붙이는 중이다.ㅋㅋㅋㅋ🔥 한이음에서 블렌디드러닝으로 스파르타코딩클럽 무료 수강권을 제공해줘서 가장 쉽게 배우는 머신러닝 이라는 강의를 신청해보았다.
머신러닝은 학교 수업이 아니라 개인적으로 공부를 해온 부분이기 때문에 사실 아주아주 기초적인 부분만 알고 있는 상태이다. 1주차 수업을 들어보니 내 수준보다는 조~금 쉬운 느낌이지만 복습하기에 딱 좋은 것 같다. 강사님께서도 어렵지 않게 잘 설명해주신다.

친구 쥬이는 4주차 듣고있다고 한다. 나 오티하고있다고 하니까 놀러왔다🤣 이시국 찜질방;;
근데 오티때 좀 충격먹었다. 기가 엄청 빨렸다고 해야하나.. 그냥 가볍게 매주 강의 들으면 되겠지 했는데 뭔가 압박감이 주어지는ㅋㅋㅋㅋ 진짜 내스타일 아니다. 이건 개인적인 취향일뿐.. 이런 빡세고 의쌰의쌰 하는거 좋아하는 사람들은 엄청 좋아할 것 같다. 난 이런 분위기 힘들어
선형 회귀 (Linear Regression)
가설과 손실함수
예를 들면 커피 잔 수에 따른 당신의 시험 점수가 있다. 임의의 직선 1개 (1차함수)로 이 모델을 표현할 수 있다는 가설을 세울 수 있다. 이 가설의 식은 다음과 같다.
우리는 정확한 시험 점수를 예측하기 위해 우리가 만든 임의의 직선(가설)과 점(정답)의 거리가 가까워지도록 해야한다. (=mean squared error)
여기서 H(x)는 우리가 가정한 직선이고 y 는 정답 포인트라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 학습되었다고 말할 수 있을 것이다.
여기서 우리가 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cost를 손실 함수(Cost or Loss function)라고 한다.
다중 선형 회귀
입력 변수가 여러개일 때의 가설과 손실함수는 다음과 같다.
경사 하강법 (Gradient Descent Method)
손실함수가 아래와 같은 모양을 갖고 있다고 가정한다.
출처: https://towardsdatascience.com/using-machine-learning-to-predict-fitbit-sleep-scores-496a7d9ec48
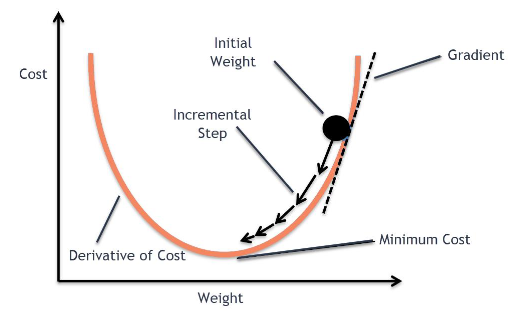
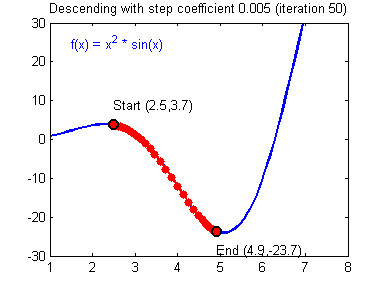
우리의 목표는 손실 함수를 최소화 (Optimize) 하는 것이다. 손실함수를 최소화 하기 위해서는 이 그래프를 따라 점점 아래로 내려가야 한다. 이 때 컴퓨터는 경사 하강법이라는 방법을 사용한다.
처음에 랜덤 위치에서 시작하고, 좌우로 조금씩 움직이면서 이전 값보다 작아지는지 관찰한다. 한칸씩 전진하는 단위를 learning rate 라고 부른다. 그리고 그래프의 최소점에 도달하게 되면 학습을 종료한다.
출처: https://medium.com/hackernoon/life-is-gradient-descent-880c60ac1be8
Learning Rate
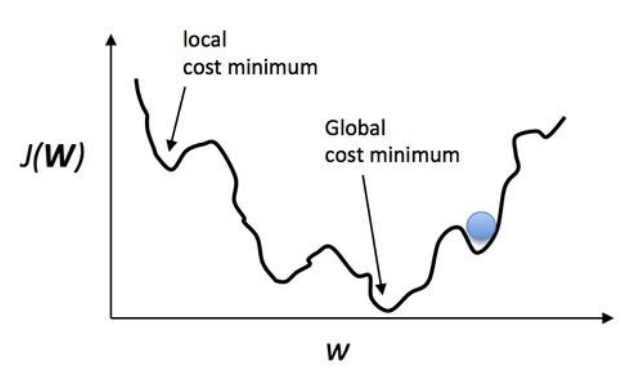
Learning rate가 지나치게 크거나 작으면 문제가 발생한다. 적절한 lr을 찾는 노가다가 필요하다. 또한, 아래 그림처럼 local cost minimum에 빠지지 않도록 lr을 잘 설정해야 한다.
 출처: https://regenerativetoday.com/logistic-regression-with-python-and-scikit-learn/
출처: https://regenerativetoday.com/logistic-regression-with-python-and-scikit-learn/
좋은 가설과 좋은 손실 함수를 만들어서 기계가 잘 학습할 수 있도록 만들기!
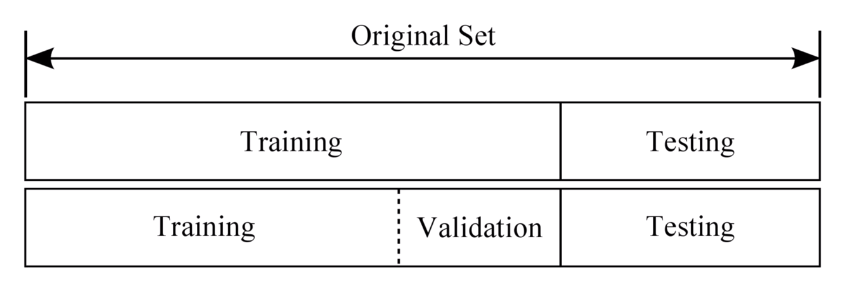
데이터셋 분할
 출처: https://3months.tistory.com/118
출처: https://3months.tistory.com/118
1. Training set
머신러닝 모델을 학습시키는 용도
2. Validation set
머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도.
정답 라벨이 있지만 모델의 성능에 영향을 미치지 않는다. 손실함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도이다.
3. Test set
정답 라벨이 없는 실제 환경에서의 평가 데이터셋
1주차 숙제
🔗 제출한 숙제
구글 코랩을 처음 써보았다! 주피터노트북을 쓸 줄 알아서 금방 적응할 수 있었다.
2주차도 화이팅🤗
