JosePhus Problem
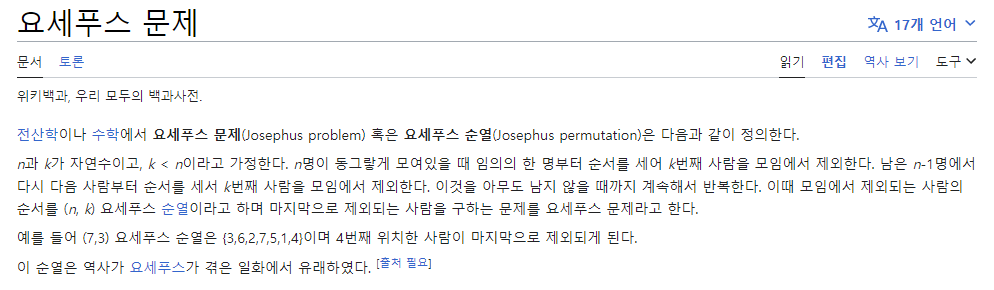
출처: https://en.wikipedia.org/wiki/Josephus_problem
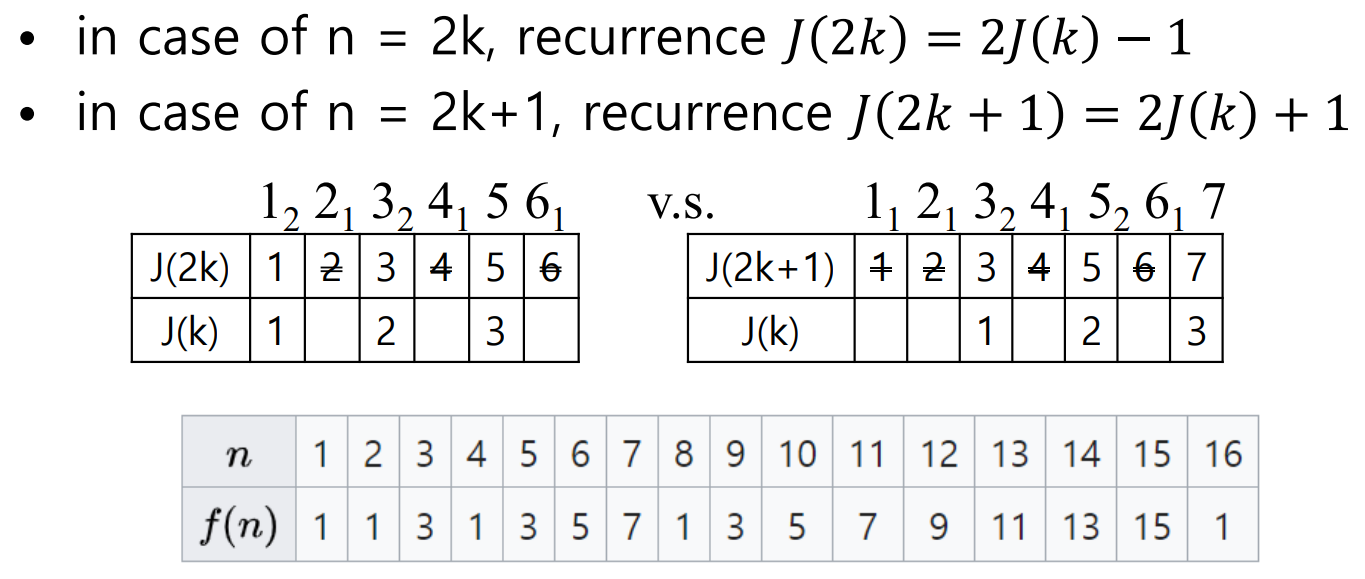
- ex) J(6) = J(110) = 101 = 5
J(7) = J(111) = 111 = 7
Variable Size Decrease
- 감소 패턴은 알고리즘의 반복마다 다름
- ex) 유클리드 호제법
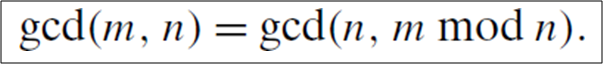
Orger Statistics (순서 통계량)

평균 선형시간 Selection Algorithm
- ex)
- 첫번째 값이 pivot이며 이 값이 배열의 3번째 값이라고 밝혀졌을 때
- case1) 두번째 원소를 찾아야 한다면, 앞쪽에서 두번째 값을 다시 찾기
- case2) 일곱번째 원소를 찾아야 한다면, 뒤쪽에서 7 – 1 – 3 = 세번째 값 다시 찾기
Lomuto Partition
- 초기상태
- Pivot : 가장 마지막 element
- i : 맨 왼쪽 element의 index 값 -1
- j : 맨 왼쪽 element의 index 값
while( j =초기값 until 피봇 index ){
if( j 값이 피봇보다 작거나 같다면 ) {
i ++
i가 가르키는 값과 j가 가르키는 값 swap
j ++
}
}
i + 1 값과 피봇값을 swapHoarse partition
- 초기상태
- Pivot : 맨 왼쪽 값
- i : Pivot의 바로 다음 값
- j : 맨 오른쪽 값
while( i 가 j보다 작거나 같을때까지){
i 위치 값이 Pivot 값보다 같거나 큰값인지 확인
j 위치 값이 Pivot 값보다 같거나 작은값인지 확인
if( i , j 모두 찾는 값을 찾았다면)
두 값을 서로 swap
i++, j++
else if( i 만 원하는 값을 찾았다면)
j--
else if( j 만 원하는 값을 찾았다면)
i++
}
피봇값과 j가 가르키는 값을 swap참고: 그림으로 이해하는 과정
https://ldgeao99.tistory.com/376
Selection Algorithm 평균 수행시간

∴ T(n) = O(n)
T(n) = Ω(n)임은 자명하므로 T(n) = Θ(n)
Selection Algorithm 최악의 경우 수행시간
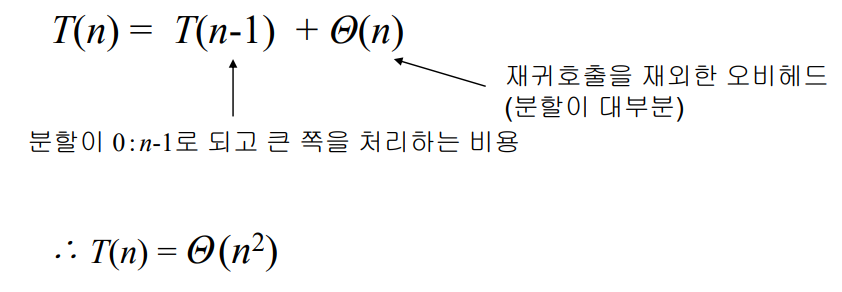
- 수행시간은 분할의 균형에 영향을 받음
- 최악의 경우 분할의 균형이 어느정도 보장되도록 함으로써 수행시간이 Θ(n)이 되도록 함
- 분할의 균형을 유지하기 위한 오버헤드가 지나치게 크면 안됨
Linear Selection
linearSelect (A, p, r, i)
▷ 배열 A[p ... r]에서 i번째 작은 원소를 찾는다
{
① 원소의 총 수가 5개 이하이면 원하는 원소를 찾고 알고리즘을 끝낸다.
② 전체 원소들을 5개씩의 원소를 가진 ⌈n/5⌉ 개의 그룹으로 나눈다.
(원소의 총수가 5의 배수가 아니면 이중 한 그룹은 5개 미만이 된다.)
③ 각 그룹에서 중앙값을 (원소가 5개이면 3번째 원소) 찾는다.
이렇게 찾은 중앙값들을 m1, m2, …, m⌈n/5⌉ 이라 하자.
④ m1, m2, …, mn/5 들의 중앙값 M을 재귀적으로 구한다. 원소의 총수가 홀수면 중앙값이 하나이므로 문제가 없고, 원소의 총수가 짝수일 경우는 두 중앙값 중 아무거나 임의로 선택한다. ▷ call linearSelect( )
⑤ M을 기준원소로 삼아 전체 원소를 분할한다. (M보다 작거나 같은 것은 M의 왼쪽에, M보다 큰 것은 M의 오른쪽에 오도록)
⑥ 분할된 두 그룹 중 적합한 쪽을 선택하여 단계 1~6을 재귀적으로 반복한다. ▷ call linearSelect( )
}
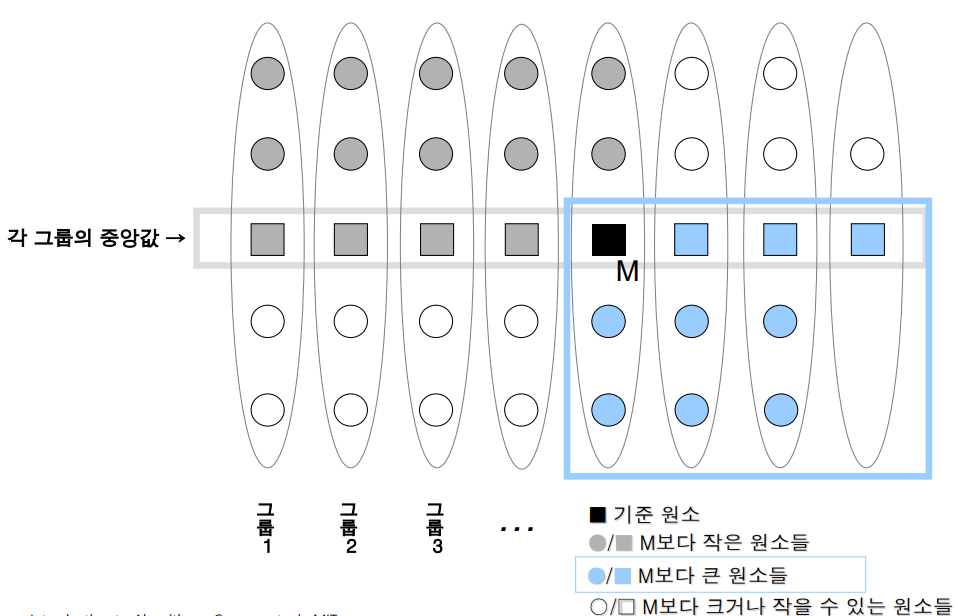
- 최악의 경우 수행시간

∴ T(n) = O(n)
T(n) = Ω(n)임은 자명하므로 T(n) = Θ(n)
Interpolation search (보간 탐색)
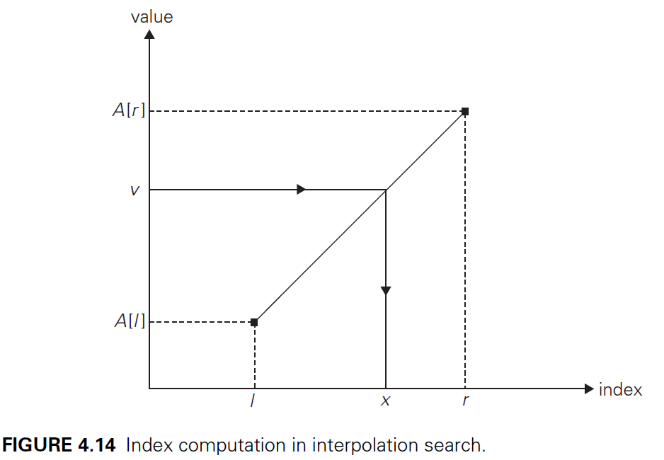
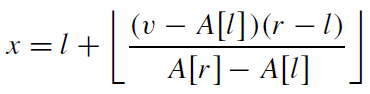
if v == A[x] then return x ;
elif v < A[x] then r = x-1 ;
elif v > A[x] then l = x+1 ;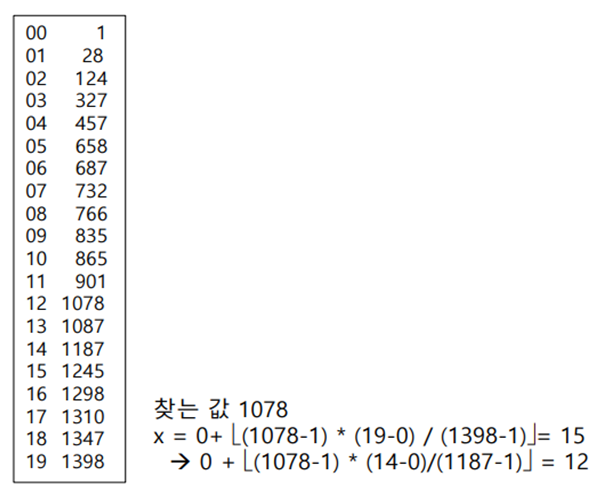
결론
-
매우 효율적인 솔루션
-
알고리즘은 문제의 인스턴스와 동일한 문제의 작은 인스턴스 사이의 관계를 이용함

-
본질적으로 재귀적이다
-
구현: 재귀 또는 반복
