Apache Kafka
Linkedin에서 만든 고성능 분산메세징용 오픈소스로, 안정적인 버퍼링(큐잉)을 제공한다.
인스타그램을 예시로 들면, 한 인플루언서가 게시글을 올렸을 때 realtime에 가깝게 5억명에게 알람을 띄우기 어렵다.
Kafka는 이러한 대용량 알림을 안정적으로 띄워줄 수 있도록 한다.
- 버퍼링을 사용해서 realtime에 가깝게 처리한다.
- 대용량 처리 도중 서버가 죽지/뻗지 않아야한다.
- 병렬처리
-> 이를 위해 모든 요청 사이에 kafka를 두는 추세이다.
+) 비슷한 기술로 RabbitMQ, ActiveMQ가 존재하지만 kafka의 성능이 압도적으로 좋다.
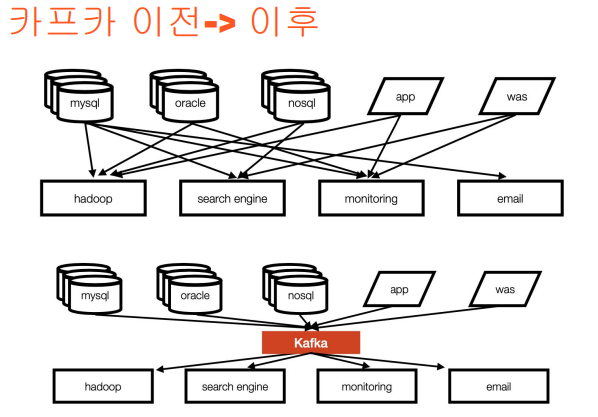
기본 개념
큐를 토픽으로 정의한다.
토픽 기준으로 메세지(데이터)를 관리한다.
Producer: 토픽 write
Consumer: 토픽 read
빠른 write 성능이 필요하다면 토픽을 쪼개서(파티셔닝 해서) write를 진행한다.
빠른 read 성능이 필요하다면 같은 토픽에 접근하는 Consumer끼리 그룹으로 묶어서 토픽(파티션)을 읽는다.
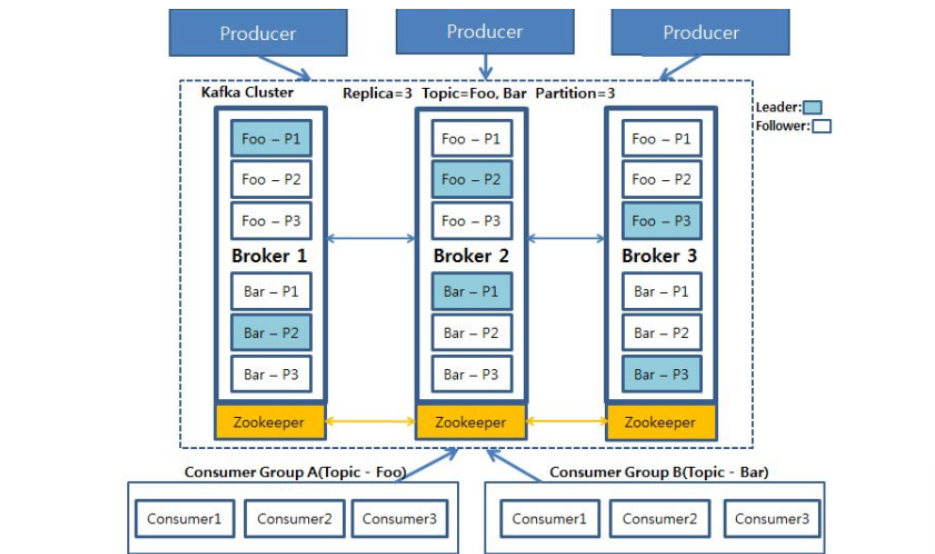
토픽: Foo, Bar (3개로 파티셔닝된 형태)
브로커: 하나의 브로커 안에 여러 토픽 가능 (위 그림은 3중화된 형태이다)
주키퍼: 브로커 당 하나씩 존재하며, 브로커의 상태를 관리한다.
Apache Zookeper
브로커를 어떤 형태로 구성할건지 설정하는 역할이다.
카프카 설정시 주키퍼를 필수로 추가해야한다.
클러스터에서 어떤 노드가 리더(마스터)가 될지 결정하며, 여러 알고리즘으로 동작한다.
Master = Leader, Slave = Follower이다.
Master-Slave
슬레이브가 죽는다면 다른 슬레이브를 사용하거나 재생성한다.
마스터가 죽는다면 슬레이브 중 하나가 마스터가 되어 마스터 역할을 수행한다.
마스터 동작 확인 - heartbeat
Active-Standby
활성 마스터(Active Master)가 응답이 없다면 대기 마스터(Standy Master)를 활성 마스터로 변경한다.
하지만 대기 -> 활성으로 전환시 딜레이가 발생한다는 단점이 존재한다.
Active-Active
두개 이상의 활성 마스터를 구성한다.
하나의 활성 마스터 장애 발생시 지연 없이 다른 활성 마스터를 사용하면 된다.
하지만 활성 마스터끼리 의견이 다르다면? (데이터나 결괏값) 합의가 필요하기 때문에 활성 마스터는 홀수 개로 구성해야한다.
이러한 알고리즘은 카프카의 성능 및 고가용성을 높인다.
고가용성: 노드장애가 발생하더라도 서비스를 계속 운영할 수 있도록 하는 것.
