
📌 Linear Regression
MSE 식
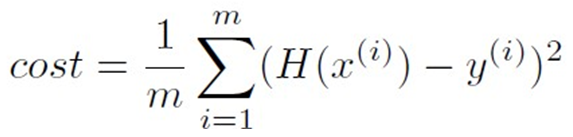
What is the goal of cost function?
Make the cost zero, when the hypothesis and y value are exactly the same.
Why do we use the squared loss?
Positive error and negative error can make the summation zero.
Gradient Descent 식
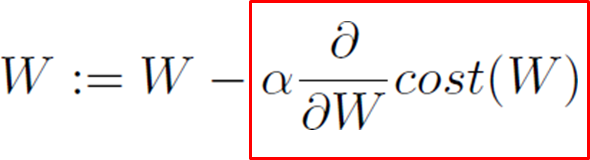
How did we solve the linear regression?
- Step 1: Define hypothesis
H(x) = Wx + b- Step 2: Define cost function
- Step 3: Find parameters that minimize the cost function using gradient descent method
📌 Logistic Regression
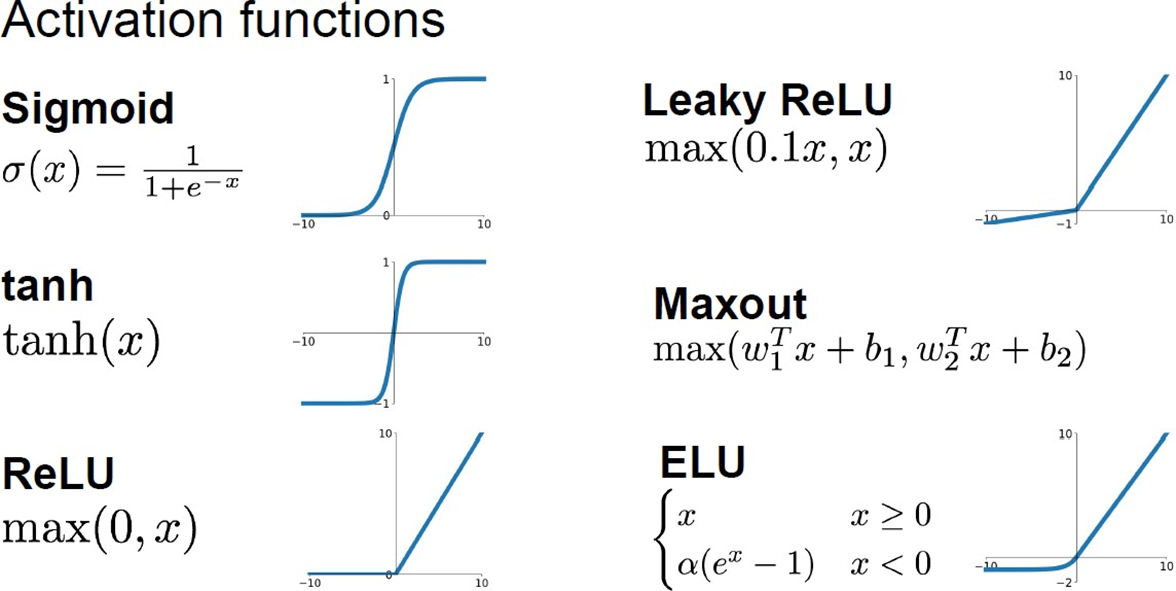
함수 별 shape, 식
- Logistic(Sigmoid) 범위는 0 ~ 1

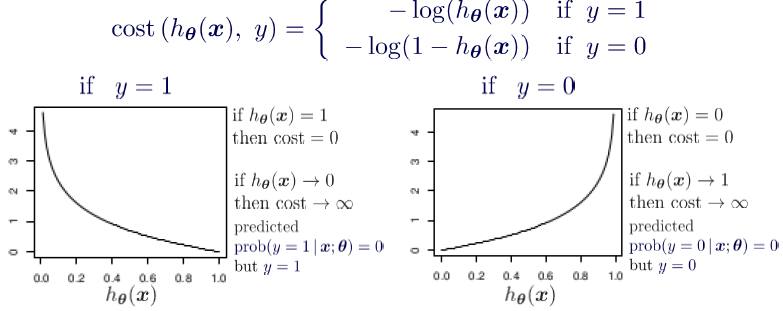
Logistic regression에 Linear regression처럼 Gradient descent를 적용할 수 없는 이유
To use gradient descent algorithm, a function should be convex. But the cost function of logistic regression using sigmoid is non convex, so there will be local minima.
New cost function for logistic regression 이해하기
- Then, we can apply gradient descent as linear regression.
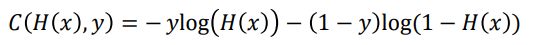
📌 Neural Network #1
ANN 방정식 & 행렬 & 그래프 변환
- Matrix에서
row == batch size,column == classifierInput layer->Hidden layer->Output layer

Cross Entropy 식
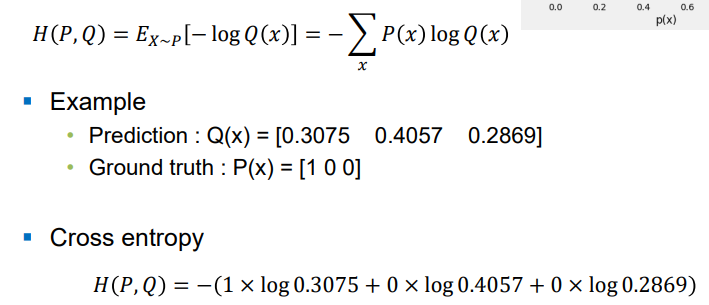
Why do we need Activation Functions?
- Activation functions allow Nonlinearities.
- To take benefits of using multiple layers, the function must be nonlinear.
- It can be transformed non-linearly through the activation function to increase the complexity of the model, so we can get better results.
📌 Backpropagation
Equation <-> Graph
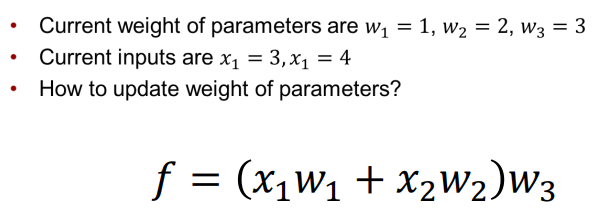
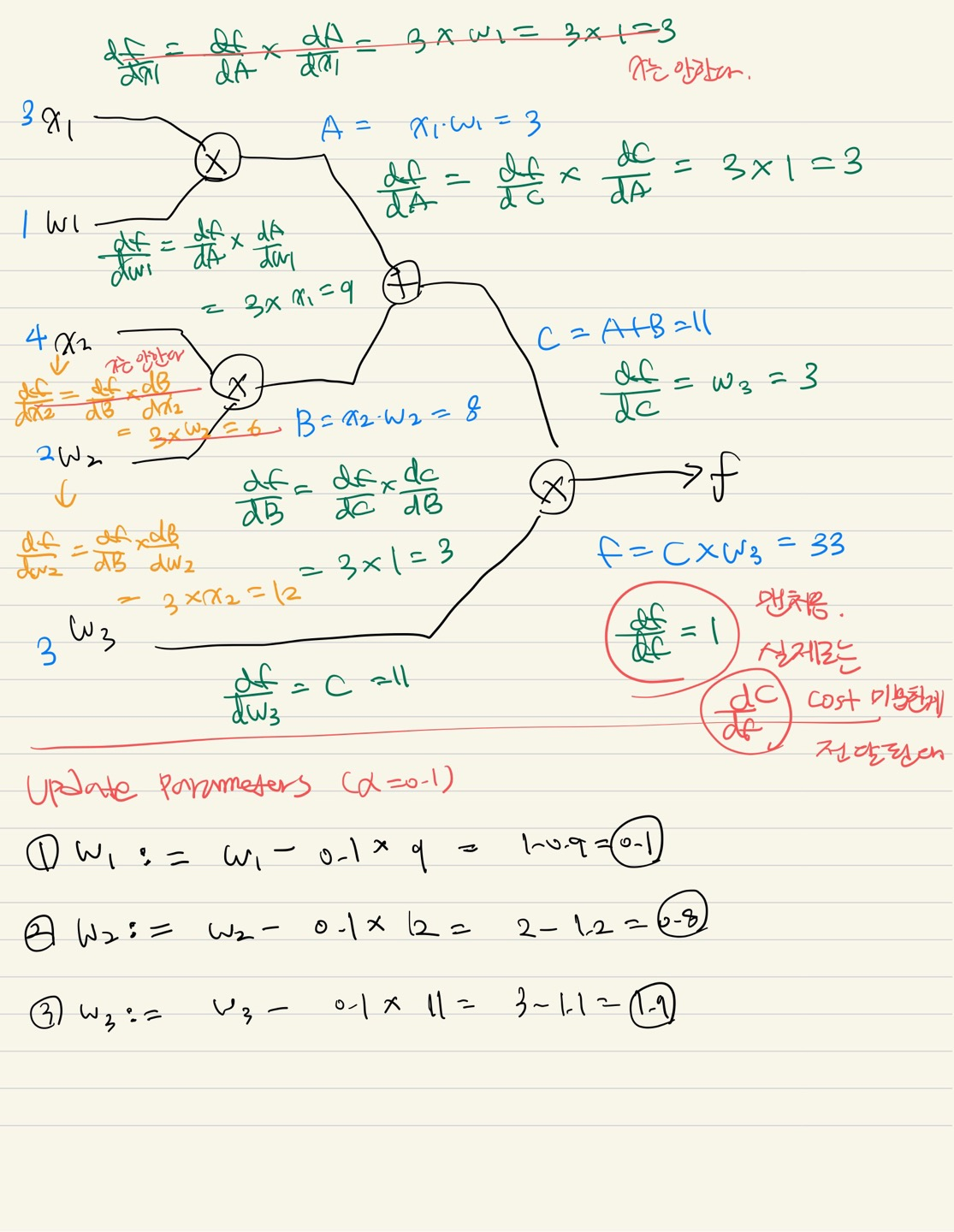
📌 Optimization
https://velog.io/@ssoyeong/%EB%94%A5%EB%9F%AC%EB%8B%9D-Optimization
📌 Neural Network #4
L1 vs L2 Regularization
- L1(Lasso, 절댓값) & L2(Ridge, 제곱)
- Lasso makes the less important feature's coefficient to zero, removing some features.
So, this works well for feature selection when we have a huge number of features.
Keywords
Regularization
- Regularization is any modification of learning algorithms to reduce its generalization error.
- Makes the weight smaller to prevent overfitting.
Dropout
- In each forward pass, randomly set some neurons to zero to prevent bias some nodes.
Internal Covariate Shift
- It means the change in the distribution skewed of the current layer due to the parameter updates of the previous layer.
Whitening
- To normalize the input of each layer to N(0, 1).
Batch Normalization
- The process of adjusting the mean and variance as N(0, 1) is not separate, but is included within the neural network and trained together.
📌 CNN
Parameter Sharing
- CNN requires far fewer parameters than FC by using Parameter Sharing.
- Parameter Sharing means that the same filter is applied only to a specific region of the image, and the output in each region is calculated while moving the filter. So we can only apply filter to the parameters we want to train, and all regions share only the filter.
Convolution Demo

CNN architecture is gradually increasing the receptive field. Why?
- Increasing receptive filed means the region is larger.
- The front layer extracts detailed features, and the later layer combines detailed features. The larger the region, the higher level information can be obtained.
Benefits of 1x1 convolution
- Reduced computation complexity
- Although the amount of computation is small, overall performance is improved by performing a lot of nonlinear computation.
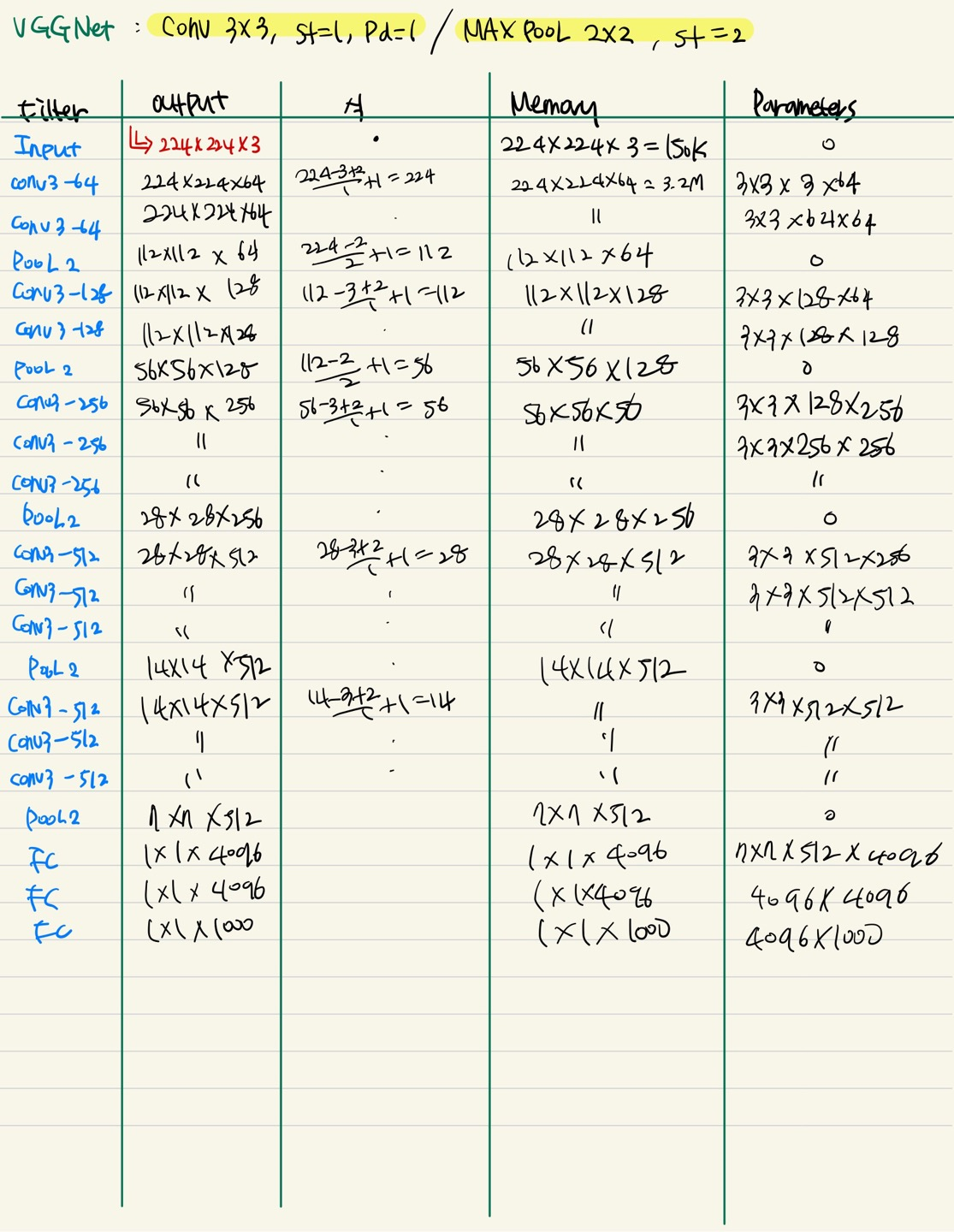
📌 CNN Architectures
Output, memory, parameters Calculation
📌 CNN Training
Transfer Learning & Fine Tuning
- Training my model by using a model trained with large dataset that is similar to the problem I want to solve.
- Fine Tuning refers to this process.

Übermensch