파이썬에서 MySQL 실행하기
실습 환경 만들기: police_station 백업 파일 만들어놓기
# zerobase 데이터베이스의 police_station 테이블을 backup_police.sql로 백업
mysqldump --set-gtid-purged=OFF -h "database-1.cpys04aeky7e.ap-northeast-2.rds.amazonaws.com" -P 3306 -u admin -p zerobase police_station > backup_police.sql
# 내 AWS RDS 접속
mysqldump -h "database-1.cpys04aeky7e.ap-northeast-2.rds.amazonaws.com" -P 3306 -u admin -p zerobase
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| zerobase |
+--------------------+
5 rows in set (0.01 sec)
# zerobase 데이터베이스 선택
mysql> use zerobase
mysql> show tables;
+--------------------+
| Tables_in_zerobase |
+--------------------+
| celeb |
| crime_status |
| police_station |
| snl_show |
+--------------------+
4 rows in set (0.01 sec)
# 저장되어있는 police_station의 데이터 삭제
mysql> delete from police_station;
Query OK, 0 rows affected (0.06 sec)
mysql> show tables;
+--------------------+
| Tables_in_zerobase |
+--------------------+
| celeb |
| crime_status |
| police_station |
| snl_show |
+--------------------+
4 rows in set (0.01 sec)
mysql> select * from police_station;
Empty set (0.01 sec) 1. Python에서 MySQL을 사용하기 위해 MySQL Driver 설치
pip install mysql-connector-python
import mysql.connector- MySQLCursor.execute() 공식문서: https://dev.mysql.com/doc/connector-python/en/connector-python-api-mysqlcursor-execute.html
2. mysql.connector 사용하여 데이터베이스 연결하기
#Local Database 연결
mydb = mysql.connector.connect(
host = "localhost",
user = "root",
password = "<password>"
#데이터베이스 지정해서 접근하려면, database="<databasename>"
)
# 종료 필수! 연결이 너무 많아지면 안됨!
mydb.close()
# AWS RDS(database-1) 연결
remote = mysql.connector.connect(
host = "database-1.cpys04aeky7e.ap-northeast-2.rds.amazonaws.com",
port= 3306, #원격이니까
user = "admin",
password = "<password>"
#데이터베이스 지정해서 접근하려면, database="<databasename>"
)3. 데이터베이스 테이블 작업하기
1) CREATE TABLE 테이블 생성
cur = remote.cursor()
cur.execute("CREATE TABLE sql_file (id int, filename varchar(16))")=> 터미널에서 desc sql_file로 확인해보면, 생성되어 있음
mysql> desc sql_file;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| filename | varchar(16) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
2 rows in set (0.02 sec)2) DROP TABLE 테이블 삭제
cur = remote.cursor()
cur.execute("DROP TABLE sql_file")=> 터미널에서 desc sql_file로 확인해보면, 존재하지 않아 오류 발생
mysql> desc sql_file;
ERROR 1146 (42S02): Table 'zerobase.sql_file' doesn't exist3) SQL File 실행
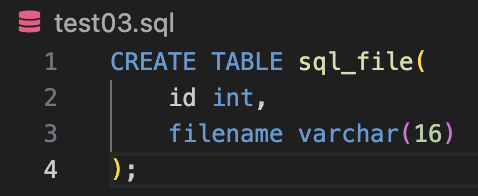
cur = remote.cursor()
sql = open("test03.sql").read()
cur.execute(sql)cursor 생성 -> sql파일을 open 및 read 한 후 -> cursor에서 sql을 실행
mysql> desc sql_file;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| filename | varchar(16) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
2 rows in set (0.01 sec)=> 테이블이 잘 생성되어 있음을 확인
4) 여러 Query가 담긴 SQL File 실행
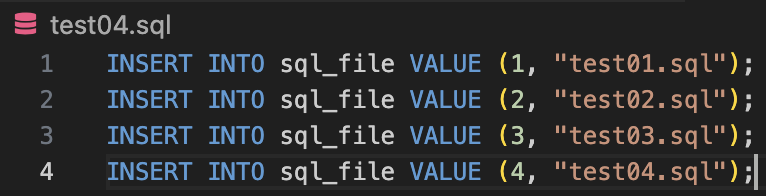
cur = remote.cursor()
sql = open("test04.sql").read()
#multi=True 옵션을 주면 sql에 담긴 것을 여러 번 실행하게 됨.
for result_iterator in cur.execute(sql, multi=True): #여러번 실행하는 것을 result_iterator로 받아옴
if result_iterator.with_rows: #결과값이 여러 개인 경우에는
print(result_iterator.fetchall()) #fetchall: 결과를 모두 받아와서 찍음
else:
print(result_iterator.statement)
remote.commit() #database에 적용하기 위한 명령
remote.close()
....
INSERT INTO sql_file VALUE (1, "test01.sql")
INSERT INTO sql_file VALUE (2, "test02.sql")
INSERT INTO sql_file VALUE (3, "test03.sql")
INSERT INTO sql_file VALUE (4, "test04.sql")잘 생성되어있는지 확인해보자!
mysql> select * from sql_file;
+------+------------+
| id | filename |
+------+------------+
| 1 | test01.sql |
| 2 | test02.sql |
| 3 | test03.sql |
| 4 | test04.sql |
+------+------------+
4 rows in set (0.02 sec)=> 테이블이 안에 값이 잘 들어가졌음을 확인
5) Fetch All로 Select 조회한 데이터 python에서 담기
- 참고) cursor.execute를 통해 데이터를 가져올 때, 읽어올 데이터 양이 많은 경우 buffered=True 옵션을 줘야 함
cur = remote.cursor(buffered=True)
# buffered=True: 읽어올 데이터 양이 많은 경우
cur.execute("SELECT * FROM sql_file")
result = cur.fetchall()
print("1) print(result):", result) # 한번에 다 출력되어서 나옴
print("------2) 한줄씩 출력해보기------")
#한줄씩 출력해보기
for result_iterator in result:
print(result_iterator)
remote.close()
...
1) print(result): [(1, 'test01.sql'), (2, 'test02.sql'), (3, 'test03.sql'), (4, 'test04.sql')]
------2) 한줄씩 출력해보기------
(1, 'test01.sql')
(2, 'test02.sql')
(3, 'test03.sql')
(4, 'test04.sql')6) Select 조회하여 검색한 결과를 Pandas로 읽기
import pandas as pd
df = pd.DataFrame(result)
df.head()
...
0 1
0 1 test01.sql
1 2 test02.sql
2 3 test03.sql
3 4 test04.sql테이블에 데이터 입력: commit()
- commit(): database에 적용하기 위한 명령. 즉, commit()하는 순간 데이터에 적용됨.
- for문이 모두 종료되고 나서 commit을 하게 될 경우, for문 중간에 오류가 났을 때 모두 적용되지 않을 수 있음.
- for문 중간에 한줄씩 완성될 때마다 commit을 하게 될 경우, 오류가 발생하기 전까지는 모두 적용시킬 수 있음.
cur = remote.cursor(buffered=True)
cur.execute()
sql = "INSERT INTO police_station VALUES (%s, %s)"
# %s: string으로 받겠다는 뜻
for i, row in df.iterrows():
cur.execute(sql, tuple(row))
#df 한줄씩 담긴 string 값 두개를 sql에 담아서 실행
# => 즉 df의 값을 police_station 테이블에 넣음
print(tuple(row))
remote.commit()
# 데이터 잘 들어갔는지 확인해보기
cur.execute("SELECT * FROM police_station")
result = cur.fetchall()
for row in result:
print(row)