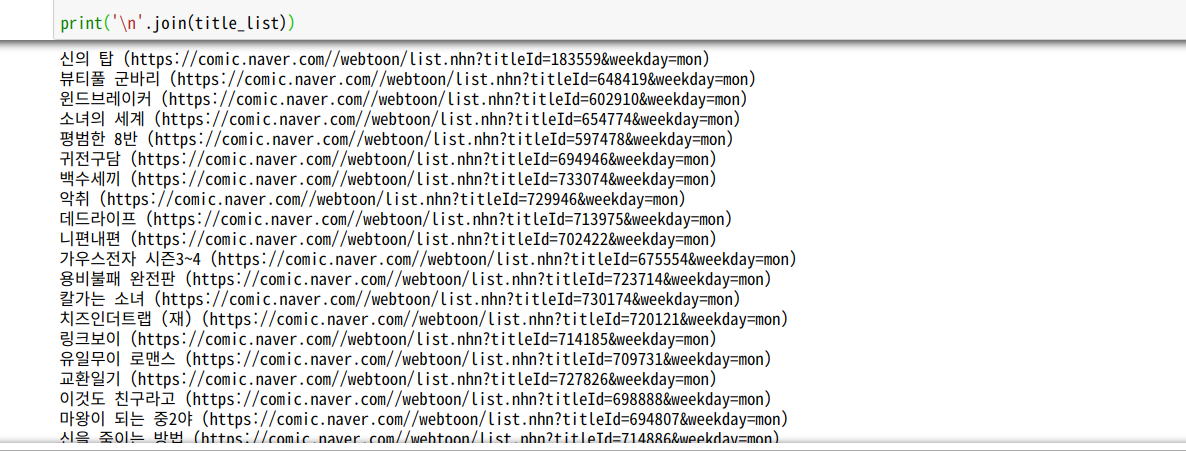
다음 두 가지를 이용해서 네이버 웹툰 메인 페이지의 모든 웹툰의 제목과 링크를 가져오는 파이썬 코드를 작성한다.
크롤링을 위한 개발 환경을 설정해 주자. 프로젝트 폴더를 생성하고 가상 환경을 만들도록 한다.
개별 환경 구성이 끝나면 requests와 BeautifulSoup를 사용할 수 있도록 설치해 준다. 프로젝트 폴더에서 가상환경이 적용된 것을 확인한 후 다음 명령을 입력한다.
pip install requests
pip install pip intall beautifulsoup4pycharm에서도 파이썬 파일을 만들어서 크롤링을 할 수 있지만 그때그때 진행 상황을 확인하기 편한 jupyter notebook을 이용하는 게 더 좋다. 터미널에서 아래의 명령을 입력해서 설치 후 jupyter notebook을 입력하면 된다.
pip install notebookjupyter notebook 사용법 참조(매우 간단)
그럼 이제 본격적으로 크롤링을 시작해 보자.
requests 모듈이 하는 일
requests는 파이썬 HTTP 라이브러리이다. 파이썬에서 HTTP 요청을 보낼 수 있다. 기본적인 사용 방법은 다음과 같다.
import requests
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
위의 코드는 네이버 웹툰 메인 페이지로 GET 요청을 보낸다. response 객체를 그대로 출력하면 요청 수행 후 상태 코드를 볼 수 있다.
참고: HTTP 상태 코드
import requests
from bs4 import BeautifulSoup
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
print(response) # prints <Response [200]>여기까지 완료하면 response를 통해서 네이버 웹툰 메인 페이지의 소스를 가져올 수 있다. 이제 여기서 제목과 링크를 추출해 오면 된다. 다음의 코드는 response가 가져온 네이버 웹툰 메인 페이지의 HTML 소스를 보여 준다.
import requests
from bs4 import BeautifulSoup
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
print(response.text)출력해 보면 알겠지만 혼란스럽게 생겼다. 이제 BeautifulSoup을 사용해서 response가 가져온 소스를 우리가 이해할 수 있는 구조로 바꿔 준다. BeautifulSoup은 HTML 코드에서 의미 있는 정보를 추출할 수 있게 해 주는 라이브러리이다.
import requests
from bs4 import BeautifulSoup
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
soup = BeautifulSoup(response.text, 'html.parser')soup를 출력해 보면 response.text보다 한결 나아졌음을 알 수 있다. 이제 이 HTML 코드에서 제목과 링크가 속한 곳을 찾아 내용을 출력해 주면 된다. 차근차근 단계적으로 진행해 보자.
아주 긴 HTML 코드에서 내가 원하는 부분을 나타내는 코드를 어떻게 하면 편리하게 알 수 있을까? 이는 크롬의 개발자 도구를 이용하면 된다. F12를 누르고 상단의 화살표 모양을 누른 뒤에 화면의 원하는 부분에 마우스를 가져다 대면 그 영역에 해당하는 HTML 코드를 알 수 있다.
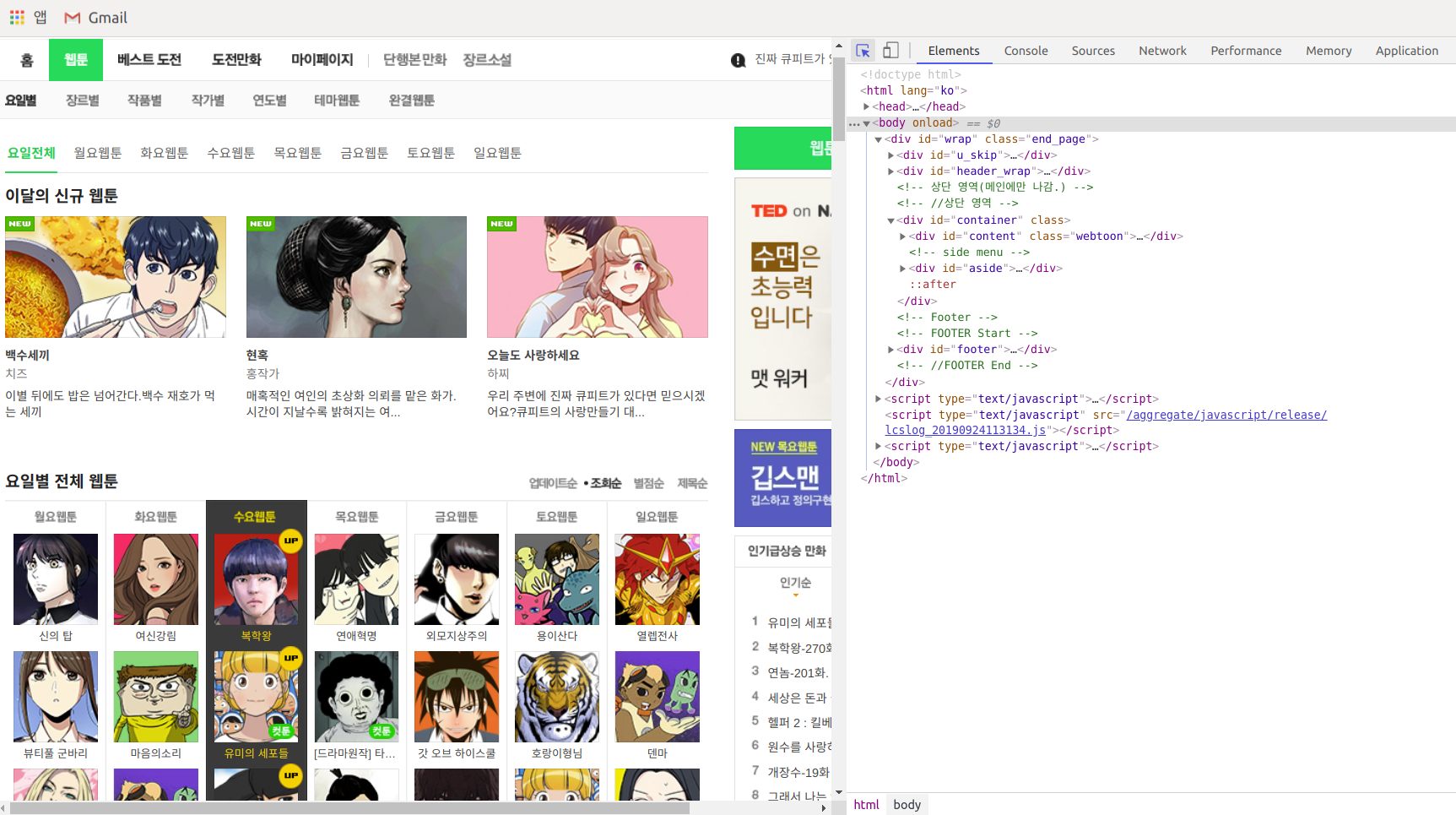
화면에 보이는 '연애혁명'에 마우스를 가져다 댄 후의 모습이다. 표시된 부분에 링크와 제목이 모두 있다. 이제 이걸 가져다 쓰면 제목과 링크를 모두 얻을 수 있을 것 같다.
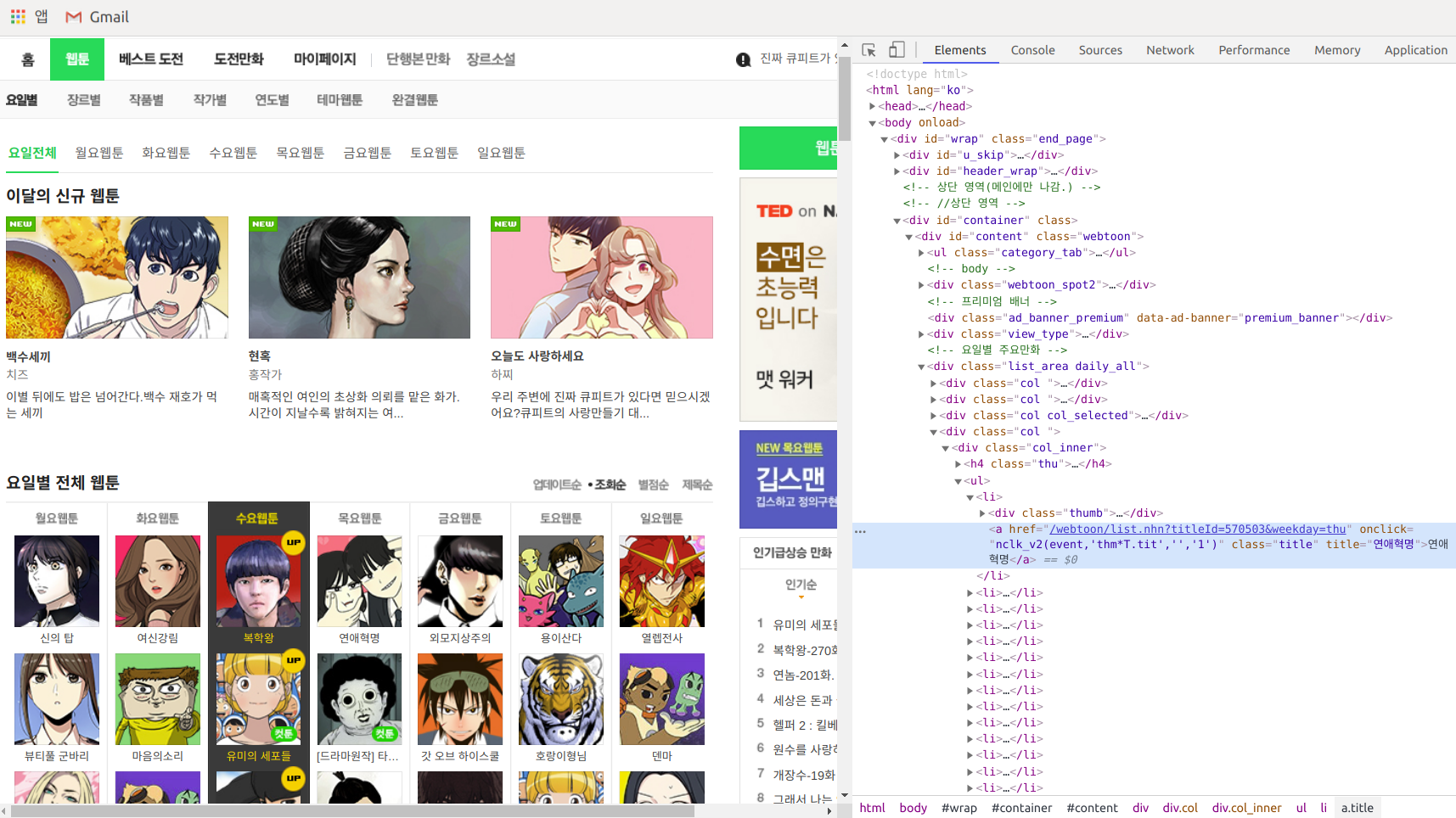
저 부분을 자세히 살펴보자.
<a href="/webtoon/list.nhn?titleId=570503&weekday=thu" onclick="nclk_v2(event,'thm*T.tit','','1')" class="title" title="연애혁명">연애혁명</a><a> 태그에 title이라는 클래스(참조)를 가진다. 다른 웹툰들도 마찬가지일 것이다. 우리가 원하는 건 모든 웹툰 제목과 링크이므로, 저런 형식으로 된 것들을 모조리 가져오면 된다. 이는 BeautifulSoup이 도와줄 것이다. 공식 문서를 잘 살펴보자. Searching by CSS Class라는 항목이 보인다.
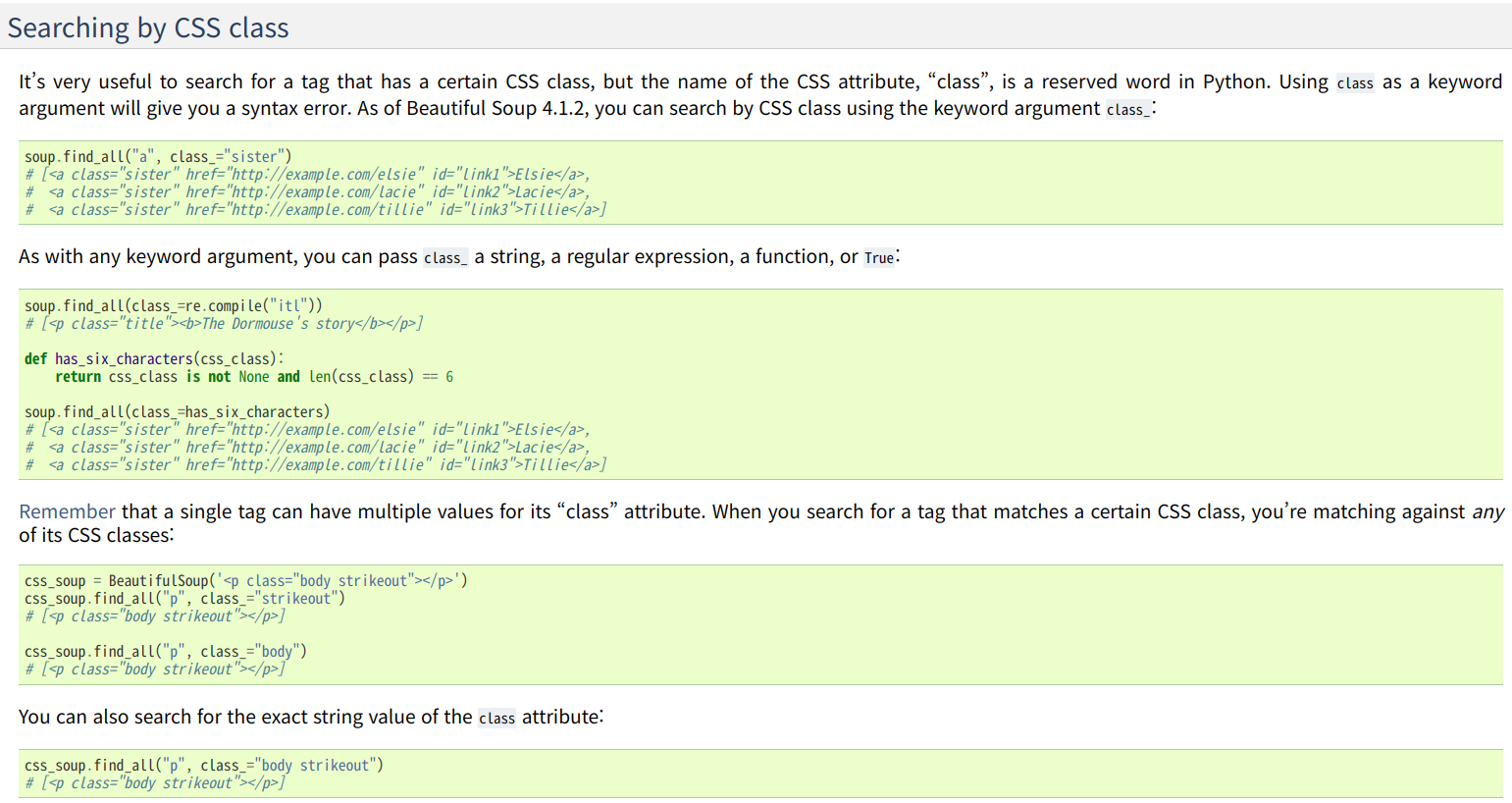
우리가 원하는 것과 완벽하게 일치한다. 이제 저 중에서 select를 이용해 우리가 원하는 부분을 가져와 보자.
import requests
from bs4 import BeautifulSoup
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
soup = BeautifulSoup(response.text, 'html.parser')
class_title_a_list = soup.select('a.title')출력해 보면 위의 <a href~와 같은 형식을 가진 것들을 모두 가져왔음을 알 수 있다. 이제 제목과 링크를 모두 가져왔다. 그런데 HTML 소스를 그대로 가져왔기 때문에 제목과 링크 외에 군더더기들이 너무 많다. 여기서 링크와 제목만 뽑아내 보자.
이것 역시 BeautifulSoup 공식 문서를 찾아보면 찾을 수 있다. get()과 get_text()를 이용하면 된다. class_title_a_list는 모든 웹툰 제목 부분의 HTML 소스 리스트이므로, 리스트를 순회하면서 제목과 링크만 추출한다.
import requests
from bs4 import BeautifulSoup
URL_TOTAL_LIST = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(URL_TOTAL_LIST)
soup = BeautifulSoup(response.text, 'html.parser')
class_title_a_list = soup.select('a.title')
title_list = []
for a in class_title_a_list:
a_href = a.get('href') # a['href']
a_text = a.get_text()
result = f'{a_text} (https://comic.naver.com/{a_href})'
title_list.append(result)참고로 get_text()는 태그 안의 내용을 가져온다. get()은 속성을 인자로 해서 해당 속성의 속성값을 가져온다. 출력을 편하게 하기 위해 제목과 링크를 가져와 문자열로 만들어 새 리스트에 추가해 줬다.
새 리스트를 출력해 주면 다음과 같이 모든 웹툰의 제목과 링크를 볼 수 있다. 일주일에 2회 이상 연재하는 웹툰의 경우 중복되어서 리스트에 들어가므로, set을 사용해서 간단하게 중복을 없애 주면 더 보기 좋을 것이다.