[개발] id(PK) 직접할당 전략 - Random, UUID, TSID 각각에 대한 비교분석

DB의 id(pk)를 자동생성 전략 말고, 직접할당 방식을 선택하고자 합니다.
왜 이런 생각을 했냐,
단일 시스템에서는 pk를 자동 생성 전략으로 해도 문제가 되지 않습니다.
하지만, 대규모 분산 처리 시스템에서 자동 증가 전략으로 pk를 생성한다고 했을 때에는 중복된 키가 생성될 수 있습니다.
여러 노드에서 동일한 시간에 데이터를 생성하게 되면, 각 노드가 독립적으로 기본 키를 생성하기 때문에 중복된 키를 생성할 수 있기 때문입니다.
Random과 UUID 그리고 TSID를 이용해 id(pk)를 직접 할당해보고 각각의 퍼포먼스와 동시성까지 측정하고자 합니다.
결론적으로는 TSID를 이용하는 방법을 채택했는데,
왜 TSID를 선택했으며, 그리고 이외에 나머지 Random과 UUID를 선택하지 않은 이유까지 모두 알아보려합니다.
1. Random() 을 이용한 id(pk) 할당
random() 을 이용하여 pk를 직접 할당했을때에 가장 치명적인 문제점은 바로 "중복 가능성" 입니다.
random()은 무작위 수를 생성하기 때문에, 이미 존재하는 ID와 같은 값을 생성할 수 있습니다.
기본 키는 유일해야 하므로, 중복 발생 시 오류가 발생하거나 덮어쓰기가 발생할 수 있습니다.
두 번째 문제점은 데이터베이스로 이용하는 MySQL과 같은 경우 PK가 클러스터드 인덱스로 되어 있어, 항상 정렬된 상태를 유지하며 순차적인 인덱스에 최적화되어 있기 때문에
random() 을 이용하여 id를 할당했을 경우 새로운 레코드를 삽입할 때마다 전체 테이블의 재정렬이 필요할 수도 있습니다.
이는 성능 저하를 초래하며, 특히 대용량의 데이터에 대해서는 매우 비효율적입니다.
즉, random() 을 이용하여 pk를 할당했을 때에 발생할 수 있는 문제는 다음과 같습니다.
- 중복 가능성의 문제 -> 분산 시스템 뿐만 아니라 단일 시스템에서도 문제
- 데이터 삽입과 조회 시 성능 문제
다음과 같은 이유들로, random() 은 pk 할당 방법으로 적합하지 않습니다.
2. UUID를 이용한 id(pk) 할당
먼저 UUID에 대해 먼저 간단히 알아보자면,
UUID란?
16바이트(128비트) 형태의 구조를 가지며,
하나의 UUID 길이는 36자리이며, "4개의 하이픈(-)"과 "32개의 16진수 문자열"로 구성이 되어있습니다UUID 예시:
5a39a369-7e22-4086-8452-ca7db41cb3ee
UUID는 강력한 고유성을 보장하기 때문에, 앞의 random() 에서 발생할 수 있는 중복 가능성의 문제는 해결할 수 있습니다.
(UUID의 중복이 아예 불가능은 아니지만, 0.00000000006%로 거의 불가능에 가깝다고 보면 됩니다)
UUID로는 임시 유저의 식별용으로 사용하거나, 파일 등을 업로드할때에 식별하는 용도로 사용한다고 합니다.
그러면 왜 UUID는 id(pk) 할당에 부적합한지 알아보면 다음과 같습니다.
첫째, 앞선 random() 에서와 마찬가지로 성능상의 문제 입니다.
UUID 또한 마찬가지로 랜덤하게 생성되므로, 새로운 값이 테이블의 어디에 위치할지 예측할 수 없습니다. 따라서 새로운 행을 삽입할 때마다 DB는 전체 테이블을 스캔해 적절한 위치를 찾아야 하며, 이로 인해 큰 성능 저하가 발생할 수 있습니다.
또한 UUID는 문자열로 구성이 되어있기 때문에 단순히 숫자로만 구성되었을 때보다 인덱스에서 삽입 위치를 찾는 것이 더 복잡해지고 비효율적일 수 있습니다.
(문자열 인덱스의 경우, 해당 문자열의 길이가 길어질수록 인덱스의 크기가 커지고, 검색 성능이 저하될 가능성이 높다고 합니다. UUID는 일반적으로 36자리의 문자열로 표현되므로, 이 문제를 고려해야 합니다.)
둘째, 공간 효율성의 문제가 발생할 수 있습니다
UUID는 16바이트를 차지하는데, 이는 일반적으로 사용되는 integer type(4바이트)나 long type(8바이트)에 비해 많은 공간을 차지합니다.
이로 인해 저장 공간이 더 많이 필요하며, 인덱스 크기가 커져서 인덱스 관련 작업의 성능이 저하될 수 있습니다.
정리해보자면,
- 데이터 삽입과 조회 시 성능 문제
- 공간 효율성의 문제
3. TSID를 이용한 id(pk) 할당
먼저, TSID를 얘기하기 전에 Twitter의 snowflake에 대해 먼저 소개하려고 합니다.
Twitter 의 snowflake
이는 트위터에서 2010년에 고유한 ID를 생성하기 위해 고안해낸 방법으로, 대규모 분산 시스템에서 고유성과 정렬 가능성을 보장하기 위해 설계되었다고 합니다.
즉
- 분산 시스템에서 유일한 ID를 생성할 수 있는 방법으로 초당 중복 없는 수만 개의 ID 생성이 가능하며 -> (대규모 분산시스템에서의) 고유성 보장
- 순차적으로 증가하는 정렬 가능성의 조건까지 모두 갖춘 방법이다 -> 성능 보장
디스코드와 인스타그램을 포함한 다른 회사들도 이 방법을 채택했다고 합니다 😮
구조를 살펴보면 다음과 같습니다.
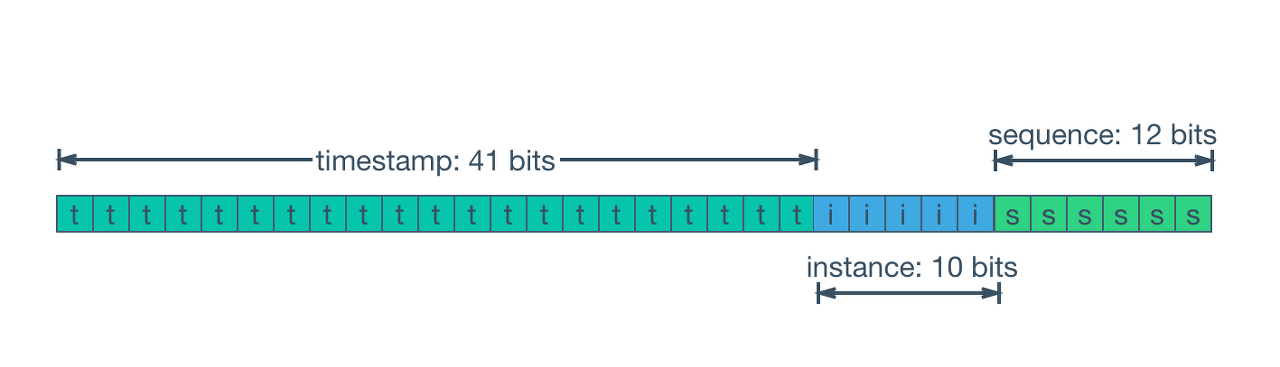
- 처음 1비트 - 양의 숫자 의미
- 41 비트 - 타임스탬프
- snowflake ID가 생성된 시간을 나타냄. 이는 밀리초 단위로 표현되며, 69년 동안 사용 가능
- 10 비트 - 머신 식별자
- 동일한 시스템에서 동시에 생성되는 snowflake ID의 충돌을 방지하기 위해 사용됨. 이는 최대 1024개의 머신을 구분할 수 있음
- 12 비트 - 시퀀스 번호
- 같은 머신에서 동일한 타임스탬프에 생성되는 snowflake ID의 중복을 방지하기 위해 사용된다. 이는 같은 시간에 동시에 생성되는 ID의 충돌을 방지하기 위해 사용됩니다. 이는 최대 4096개의 ID를 순차적으로 생성할 수 있음
따져봤다.
그럼 한 시스템에서 동시에 몇 개의 머신에서 각 머신 당 동시에 몇 개의 ID까지 생성 가능한 것일까?
- 2^10 개의 머신 구분 가능
- 같은 머신에서 동시에 생성되는 2^12 개의 id 구분 가능
=> 2^10 * 2^12 = 2^22 = 4,194,304
단일 시스템에서 최소 4백만 개의 동시 생성 id를 막을 수 있을 것 같습니다 (와... 엄청나다)
즉 이것도 최소 요건이니, 실제로는 동시에 같은 id 할당은 불가능하다고 보면 될 것 같습니다
TSID란
바로 이 TSID(Time-Sorted Unique Identifier)가 Twitter의 Snowflake와 ULID spec을 합쳐 만든 자바의 라이브러리입니다.
더 자세한 TSID 이용법과 설명은 https://github.com/f4b6a3/tsid-creator 를 참고하면 좋을 것 같습니다! (TSID 라이브러리 오픈소스 깃헙코드 입니다)
TSID를 정리해보면 다음과 같습니다.
- 대규모 분산 시스템에서의 병렬 처리 가능 및 고유성 보장
- 공간 효율성 O (통상 8바이트)
- (타임스탬프 값을 비트 앞 쪽에 배치하여) 시간이 지남에 따라 점점 커지는 값이기 때문에 정렬의 이점 모두 활용 가능 (앞의 두 random, UUID의 데이터 삽입, 검색 시의 성능 문제 해결)
다음은 각각을 이용하여 성능과 동시성 테스트를 해보려합니다
TSID는
TSID가 메인인 만큼, random과 uuid 방식도 이와 비슷한 환경으로 세팅하여 테스트를 진행하였습니다
TSID부터 테스트를 진행해보도록 하겠습니다
4. TSID 성능 및 동시성 테스트
TsidFactory에서 제가 성능에 대해서 테스트해보고 싶은 것은 다음과 같습니다.
/**
* Returns a new factory for up to 256 nodes and 16384 ID/ms.
*
* @param node the node identifier
* @return {@link TsidFactory}
*/
public static TsidFactory newInstance256(int node) {
return TsidFactory.builder().withNodeBits(NODE_BITS_256).withNode(node).build();
}
/**
* Returns a new factory for up to 1024 nodes and 4096 ID/ms.
*
* It is equivalent to {@code new TsidFactory(int)}.
*
* @param node the node identifier
* @return {@link TsidFactory}
*/
public static TsidFactory newInstance1024(int node) {
return TsidFactory.builder().withNodeBits(NODE_BITS_1024).withNode(node).build();
}
/**
* Returns a new factory for up to 4096 nodes and 1024 ID/ms.
*
* @param node the node identifier
* @return {@link TsidFactory}
*/
public static TsidFactory newInstance4096(int node) {
return TsidFactory.builder().withNodeBits(NODE_BITS_4096).withNode(node).build();
}뒤의 각 숫자는 지원하는 노드의 수입니다.
newInstance256() 은 최대 256(=2^8)개의 노드를 지원하며, 1밀리초에 최대 16384(=2^14) 개의 고유한 ID를 생성할 수 있습니다.
newInstance1024() 는 최대 1024(=2^10)개의 노드를 지원하며, 1밀리초에 최대 4096(=2^12) 개의 고유한 ID를 생성할 수 있습니다.
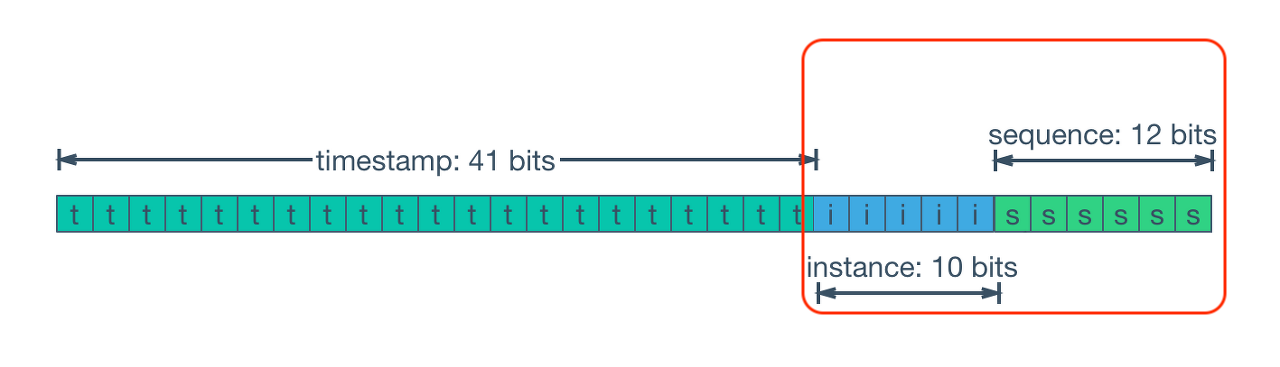
그림에서 해당 부분에서의 trade-off가 존재하는 것으로 볼 수 있을 것 같습니다.
즉, 노드 개수를 늘리면 여러 노드에서 동시에 고유한 ID를 생성할 수 있지만, 각 노드에서 1밀리초에 동시에 생성할 수 있는 ID 개수는 줄어듭니다.
반면, 노드의 개수를 줄이면 더 적은 수의 노드에서 동시에 고유 ID를 생성할 수 있지만, 1밀리초에 생성할 수 있는 ID의 개수는 늘어납니다.
이에 id를 할당하는 방법은 다음과 같습니다
각 엔진에서 최대로 생성할 수 있는 노드의 수를 기준으로(ex, 256)
현재 스레드 값 % 생성할 수 있는 최대 노드 수(ex, 256) 로 각 노드를 이용하도록 하고, 이를 위해 해시맵 자료구조를 이용하였습니다.
[ 현재 스레드 id 값 % 생성할 수 있는 최대 노드 수 ] 로 노드 엔진을 할당받고, 각 노드 엔진이 id값을 할당하게 됩니다.
저는 각각의 노드엔진 256, 1024, 4096 각각에 대한 성능과 동시성에 대해 테스트해보고자 합니다.
동시요청에 대한 테스트를 진행해야하므로,
멀티스레드 환경을 구성하여 테스트를 진행하였습니다.
(동시요청에 대한 테스트에 대한 글은 저의 이전 글을 참고하시면 좋을 것 같습니다! https://velog.io/@ssssujini99/Java-Callable-Executors-ExecutorService-의-이해-및-사용법 )
예시로 newInstance256() 에 대한 테스트입니다.
class Tsid256GeneratorTest {
@Autowired
private Tsid256Generator tsid256Generator;
private static final Logger LOGGER = Logger.getLogger("Tsid256GeneratorTest");
@ParameterizedTest
@ValueSource(ints = {256, 256, 1024, 4096, 100000, 500000})
@DisplayName("Tsid 256 Generator 테스트 - 동시요청자 수: 256, 1024, 4096, 100000, 500000 일 때")
void tsid_256_engine_test(int numberOfUsers) throws InterruptedException, ExecutionException {
// given
ExecutorService executorService = Executors.newCachedThreadPool();
List<Callable<Long>> ans = getCallables(numberOfUsers);
// when
long startTime = System.currentTimeMillis();
Awaitility.waitAtMost(Duration.ofMillis(10000)).
until(() -> getCallableExSet(executorService, ans).size(),
Matchers.equalTo(numberOfUsers));
long endTime = System.currentTimeMillis();
// then
LOGGER.info(() -> "[동시요청자 수: " + numberOfUsers + "명] " + (endTime-startTime));
executorService.shutdownNow();
}
private List<Callable<Long>> getCallables(int numberOfUsers) {
List<Callable<Long>> ans = new ArrayList<>();
for(int i = 0; i< numberOfUsers; i++) {
ans.add(tsid256Generator::generate);
}
return ans;
}
private static Set<Long> getCallableExSet(ExecutorService executorService, List<Callable<Long>> ans) throws
InterruptedException,
ExecutionException {
List<Future<Long>> futures = executorService.invokeAll(ans);
Set<Long> callableExSet = new HashSet<>();
for (Future<Long> future : futures) {
callableExSet.add(future.get());
}
return callableExSet;
}
}
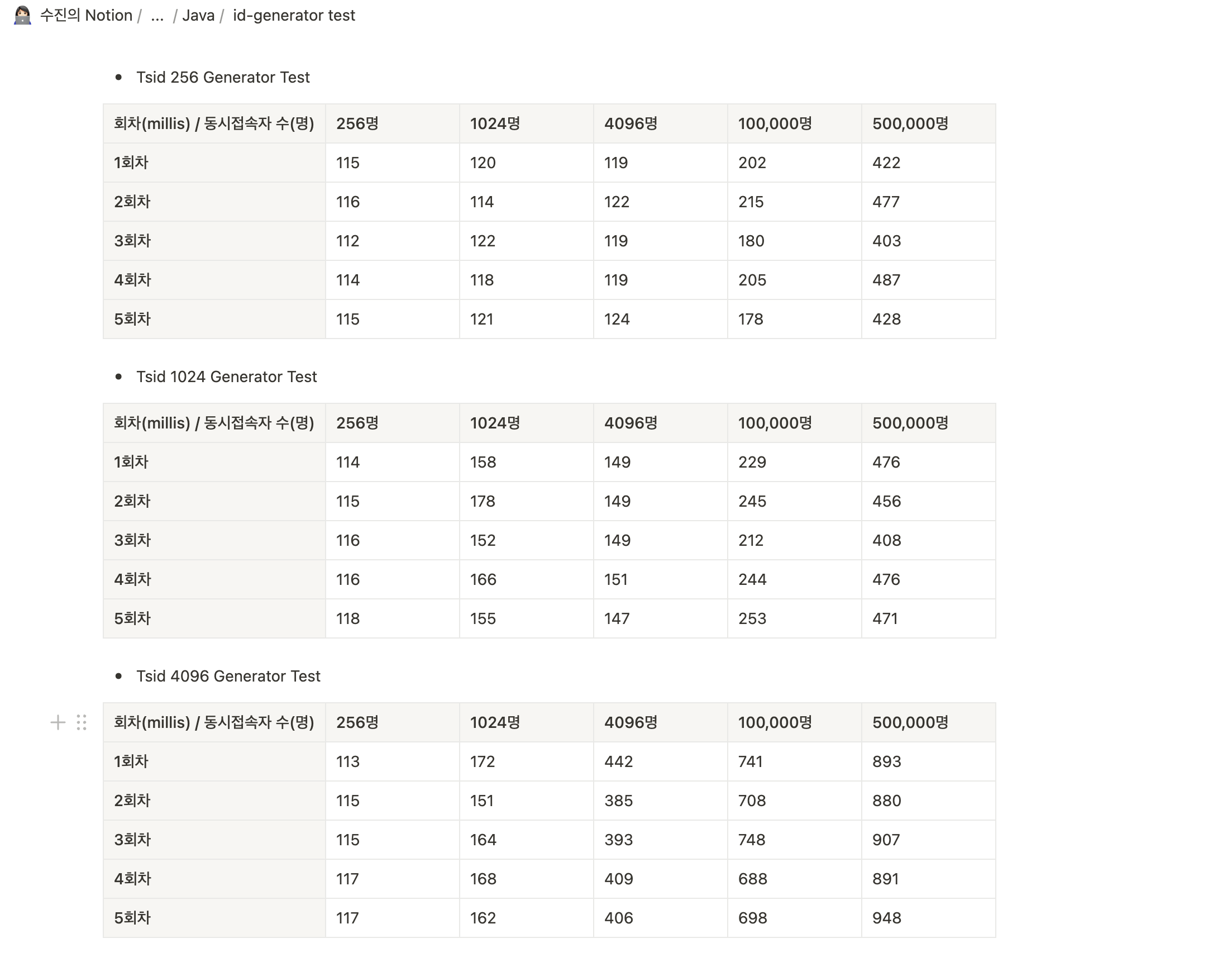
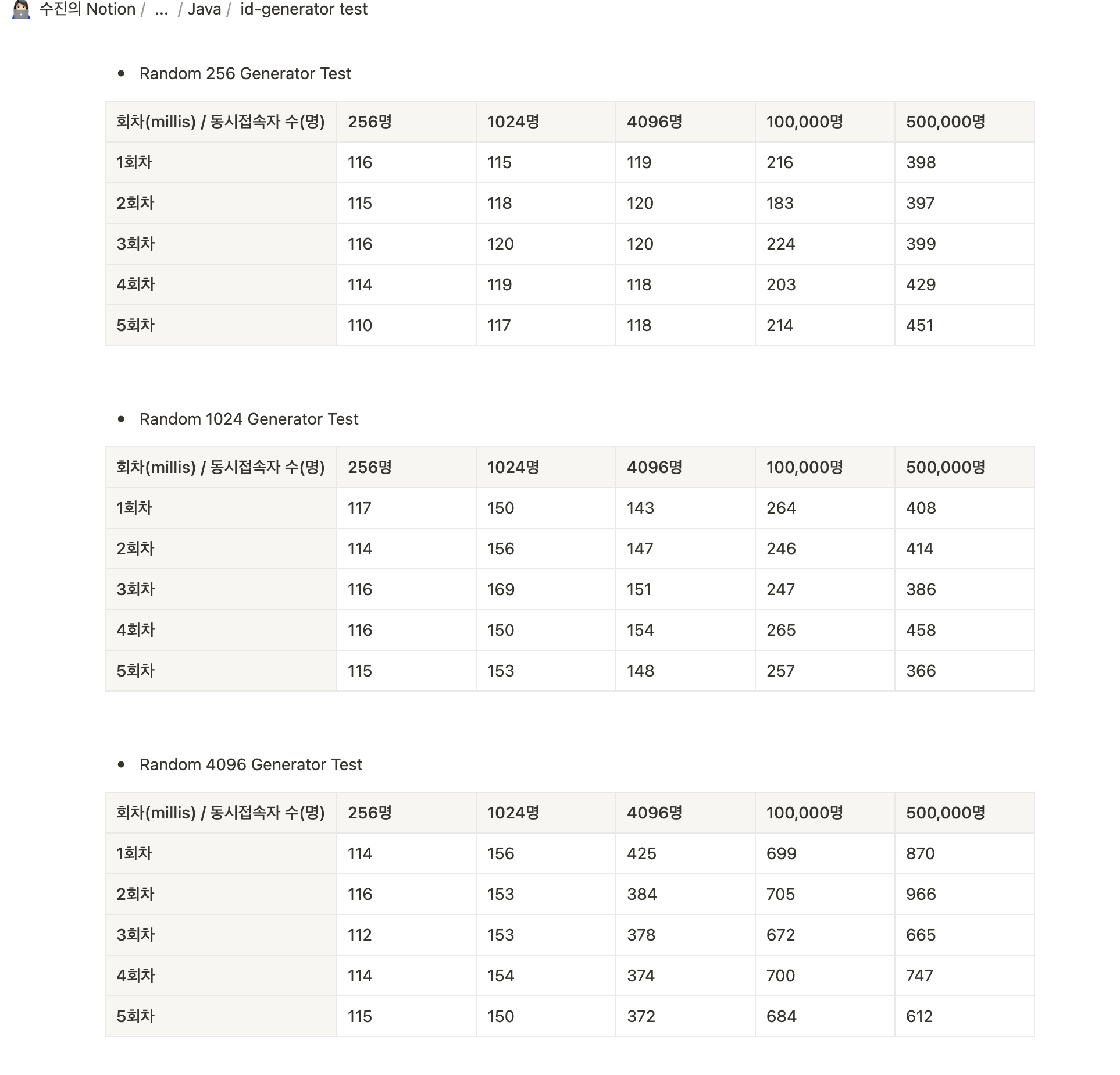
다음과 같이 각 노드엔진 256, 1024, 4096 각각에 대해 동시요청이 256, 1024,4096 그리고 극단적으로 10만명, 50만일때에 대해 테스트를 진행하보았습니다.
각 노드엔진에 대해 5번씩 진행하였으며, 각 결과를 표로 분석해 본 결과는 다음과 같습니다.
(벨로그 표 작성하기 너무 빡세네요.. 노션 표를 이용하여 작성하고 캡쳐해서 가져왔습니다)
단순히 생각해 보았을때는,
4096 엔진을 쓰면, 동시에 4096개의 서로 다른 노드 엔진을 이용할 수 있으니니 더 효율적으로 보입니다. (같은 엔진을 이용하여 id를 생성할 확률이 낮으므로)
결과는 어떨까요?
아까 이론적으로 확인했듯이 동시에 4백만개의 id를 생성할 수 있다고 했는데,
50만의 동시요청을 몇 번이나 테스트했을때에도 중복 문제는 일어나지 않았습니다.
256과 1024를 먼저 살펴보면, 정말 거의 유사합니다
동시요청자 수의 증가에 따른 걸리는 시간의 추세도 비슷했지만
그래도 1024가 256보다 미묘한 차이지만 시간이 더 걸리는 것을 확인할 수 있었습니다.
256, 1024 이 두개와 4096을 비교하면 좀 다릅니다.
동시요청 수가 256, 1024 까지는 거의 유사한 시간이 걸렸지만,
동시요청 수가 4096일때는 보면 한번 크게 뛰었음을 확인할 수 있었습니다. 1xx- > 4xx (millis)
그리고 이는 동시요청 수가 폭발적으로 증가한 10만, 50만일때에 더 확연히 확인할 수 있었습니다.
256과 1024 엔진에서는 10만일때에 평균적으로 2xx (millis) 였지만, 4096 엔진에서는 평균 7xx (millis) 였습니다.
또한 동시요청이 50만일때는 한번 더 뛰어서, 256과 1024 엔진에서는 4xx (miilis) 였지만, 4096 엔진에서는 평균 9xx (millis) 임을 확인할 수 있었습니다.
" 노드 개수를 늘리면 여러 노드에서 동시에 고유한 ID를 생성할 수 있지만, 각 노드에서 1밀리초에 동시에 생성할 수 있는 ID 개수는 줄어듭니다 "
에서 다음을 확인할 수 있었습니다.
엔진은 4096개 이니까, 동시요청이 4096까지는 거의 유사한 흐름을 보이지만,
이보다 더 큰 동시요청이 들어왔을 경우에는 한 엔진에서 동시에 생성할 수 있는 id 개수가 다른 두 엔진(256, 1024) 보다 log 값으로 줄어들기 때문에,
10만, 50만의 요청에서는 더 많은 시간이 걸렸음을 확인해볼 수 있었습니다.
사실 random과 UUID도 궁금해서 TSID와 비슷한 환경으로 세팅을 해서 진행해보았습니다.
5. Random 성능 및 동시성 테스트
TSID의 노드 개수 256, 1024, 4096 을 random에도 맞춰주고 싶어서
Random의 객체를 256, 1024, 4096개 위와 같이 맞춰서 세팅하고 테스트를 진행하였습니다.
(사실 그냥 어떤 객체든 무작위의 난수를 발생시키기 때문에
그렇게 큰 의미가 있지는 않습니다)
다음과 같이 세팅하였으며,
class Random256GeneratorTest {
@Autowired
private Random256Actor random256Actor;
private static final Logger LOGGER = Logger.getLogger("Random256GeneratorTest");
@ParameterizedTest
@ValueSource(ints = {256, 256, 1024, 4096, 100000, 500000})
@DisplayName("Random 256 Generator 테스트 - 동시요청자 수: 256, 1024, 4096, 100000, 500000 일 때")
void random_256_engine_test(int numberOfUsers) throws InterruptedException, ExecutionException {
// given
ExecutorService executorService = Executors.newCachedThreadPool();
List<Callable<Long>> ans = getCallables(numberOfUsers);
// when
long startTime = System.currentTimeMillis();
Awaitility.waitAtMost(Duration.ofMillis(10000)).
until(() -> getCallableExSet(executorService, ans).size(),
Matchers.equalTo(numberOfUsers));
long endTime = System.currentTimeMillis();
// then
LOGGER.info(() -> "[동시요청자 수: " + (endTime-startTime));
executorService.shutdown();
}
private List<Callable<Long>> getCallables(int numberOfUsers) {
List<Callable<Long>> ans = new ArrayList<>();
for(int i = 0; i< numberOfUsers; i++) {
ans.add(random256Actor::act);
}
return ans;
}
private static Set<Long> getCallableExSet(ExecutorService executorService, List<Callable<Long>> ans) throws
InterruptedException,
ExecutionException {
List<Future<Long>> futures = executorService.invokeAll(ans);
Set<Long> callableExSet = new HashSet<>();
for (Future<Long> future : futures) {
callableExSet.add(future.get());
}
return callableExSet;
}
}결과는 다음과 같습니다.
6. UUID 성능 및 동시성 테스트
UUID는 static 함수를 이용하여 id값을 생성하므로,
동시요청 수에 대해서만 테스트를 진행하였습니다.
class UuidGeneratorTest {
@Autowired
private UuidActor uuidActor;
private static final Logger LOGGER = Logger.getLogger("UuidGeneratorTest");
@ParameterizedTest
@ValueSource(ints = {256, 256, 256, 1024, 4096, 100000, 500000})
@DisplayName("Uuid Generator 테스트 - 동시요청자 수: 256, 1024, 4096, 100000, 500000 일 때")
void uuid_engine_test_1(int numberOfUsers) throws InterruptedException, ExecutionException {
// given
ExecutorService executorService = Executors.newCachedThreadPool();
List<Callable<String>> ans = getCallables(numberOfUsers);
// when
long startTime = System.currentTimeMillis();
Awaitility.waitAtMost(Duration.ofMillis(10000)).
until(() -> getCallableExSet(executorService, ans).size(),
Matchers.equalTo(numberOfUsers));
long endTime = System.currentTimeMillis();
// then
LOGGER.info(() -> "[Test 1 ] : " + (endTime-startTime));
executorService.shutdown();
}
private List<Callable<String>> getCallables(int numberOfUsers) {
List<Callable<String>> ans = new ArrayList<>();
for(int i = 0; i< numberOfUsers; i++) {
ans.add(uuidActor::act);
}
return ans;
}
private static Set<String> getCallableExSet(ExecutorService executorService, List<Callable<String>> ans) throws
InterruptedException,
ExecutionException {
List<Future<String>> futures = executorService.invokeAll(ans);
Set<String> callableExSet = new HashSet<>();
for (Future<String> future : futures) {
callableExSet.add(future.get());
}
return callableExSet;
}
}
결과는 다음과 같습니다.
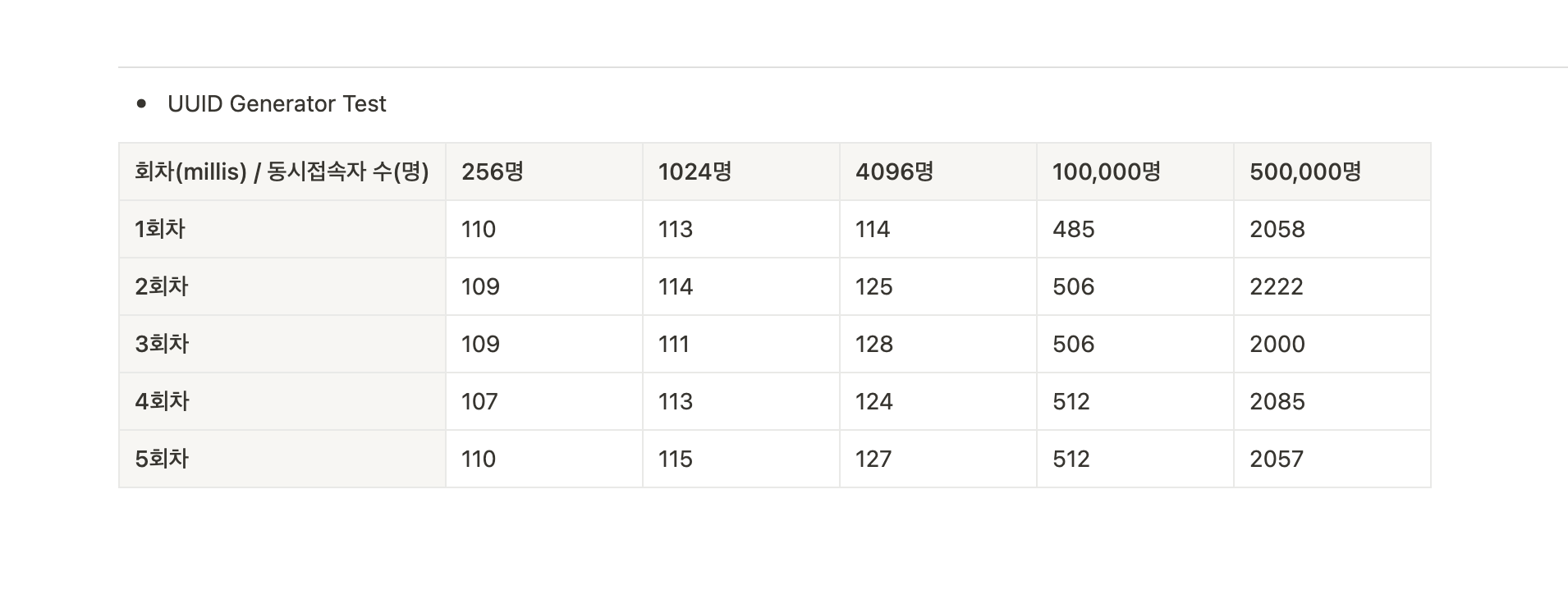
살펴볼만한 지점은 50만일때에, UUID생성 시 엄청난 시간이 걸린다는 것을 확인할 수 있었습니다.
TSID와 random은 모두 1000(miliis)가 넘지 않았지만, UUID에서는 50만 동시요청이 들어왔을 때에 평균 2000 (millis)임을 확인할 수 있었습니다.
멀티환경에서도 병렬로 동작하기 때문에 고유값을 생성할 수는 있지만, 너무 용량을 많이 차지하며 요청 수가 극단적으로 클 때에는 처리 시간도 오래 걸림을 확인할 수 있었습니다.
7. 최종 정리
- Random
- 멀티 시스템은 물론 단일 시스템에도 부적합
- 이유
- 중복 가능성 문제
- (무작위로 생성되므로) 정렬 이점을 쓸 수 X, 성능 저하 문제
- UUID
- 단일시스템, 멀티시스템에 쓸 수는 있음
- 고유성은 보장함
- 권장하지는 않음
- (무작위 + 문자열로 생성되므로) 정렬 이점을 쓸 수 X, 성능 저하 문제
- (16바이트로) 공간 효율성 문제
- 단일시스템, 멀티시스템에 쓸 수는 있음
- TSID
- 단일 시스템 및 분산 시스템 모두 쓸 수 있음
- 병렬 처리 가능 및 동시성 보장
- 통상 숫자로 이루어진 8바이트로, 공간 효율성 O
- (무작위가 아닌 점점 커지는 값으로) 정렬 이점 모두 활용 가능 O, 성능 문제 해결 O
- 단일 시스템 및 분산 시스템 모두 쓸 수 있음
8. 기타
8.1 PK를 숫자로 생성해야 하는 이유와 그 이점
Primary key(PK)를 문자열이 아닌 숫자로 사용하면 다양한 이점이 있습니다. 몇 가지 주요한 이유는 다음과 같습니다.
- 성능
숫자는 문자열보다 작은 크기를 가지므로, 저장 및 검색 속도에서 이점을 가질 수 있습니다. 데이터베이스에서 숫자 기반의 PK를 사용하면 인덱싱 및 조인 작업에서 효율적인 처리가 가능합니다. - 정렬 및 비교
숫자는 자연스럽게 정렬되고 비교되기 때문에 숫자 기반의 PK를 사용하면 데이터의 순서를 보다 간편하게 유지할 수 있습니다. 문자열 기반의 PK는 문자열의 비교 규칙에 따라 정렬 및 비교 작업이 더 복잡해질 수 있습니다. - 저장 공간
숫자는 문자열보다 작은 저장 공간을 차지합니다. (ex, random으로 생성한 long 타입은 8 byte이지만, uuid로 생성한 string 타입의 pk는 16byte 였음) 따라서 대량의 데이터를 다루는 시스템에서는 저장 공간의 효율성을 높일 수 있습니다. - 일련 번호
숫자 기반의 PK는 자동 증가하는 일련번호로 사용하기에 편리합니다. 데이터베이스 시퀀스나 자동 증가를 사용하여 숫자 기반의 PK를 생성하면 중복을 방지하면서 쉽게 고유한 값들을 생성할 수 있습니다. (임의의 무작위 값으로 PK를 생성하면 안되는 이유)
8.2 TSID 이용시에 발생한 기억에 남았던 이슈
보통 데이터베이스에 id 값을 long 타입(16 byte)로 설정합니다.
근데, auto increment로 설정한 경우 자동 0 또는 1부터 순차적으로 커지기 때문에 웬만한 아주 큰 값에 도달하기에는 어렵습니다 (데이터가 많이 쌓여있지 않은 경우에는)
TSID를 이용시에는 이 16바이트를 모두 이용하기 때문에,
자바스크립트 언어에서 정수는 53비트로 제한되어 있어서 이를 조심해야합니다!
즉 53비트보다 큰 수일 경우에 뒷 숫자의 정확도를 잃어 자바스크립트로 변환했을 때에 중복된 값을 얻을 수도 있습니다.
브라우저 API에서 반환되는 값은 대부분 JSON(JSON.stringify) 형태로 전달됩니다. JSON은 문자열로만 구성되어 있기 때문에 53비트 정밀도를 넘어서는 크기의 정수는 정확하게 전달되지 않으면서 값이 변경되어 반환될 수 있습니다. 이때, 값의 변형이 발생할 경우 맨 앞의 0들이 생략되는 현상이 발생하여 00으로 변경될 수 있습니다.
이러한 경우, 서버에서 전달되는 값을 자르거나 문자열로 형변환하여 해결할 수 있습니다.
실제 마주했던 이슈였으며, 그래서 프론트에 id 값을 반환 시에 response 부분에서 long type -> string type 으로 변환해서 주었습니다.
그래서 실제로 TSID를 이용하여 id를 할당 시에 이러한 부분들을 미리 캐치해놓고 이용하면 좋을 것 같습니다!

3개의 댓글


제네레이터가 1개(즉 1개노드=1개머신)일때 노드 비트를 늘림으로써 카운터 비트가 줄어들어 성능에 변화가 있다는 좋은 테스트 결과네요.
아쉬운점은 성능의 하락 부분이 온전히 언급하신 노드 비트때문이 아니것 같습니다. 물론 카운터비트의 감소도 문제겠지요.
노드 4096은 2^12bits 니까 2^10=1024 카운터로 밀리초당 1024개, 논리적으로 1초당 겹치지 않는 백만개 정도의 키 생산이 가능합니다.(키 발급 시간이 0 이라고 가정했을 때겠죠)
하지만 현실에서는 시간이 소요되고, 기본 팩토리가 키 발급시 카운터를 공유성으로 증가 할 수 없으니 배타적으로 lock 을 사용하기에 동시 요청이 많아 질수록 경쟁중 슬립 시간이 길어진게 아닐까 생각됩니다.
팩토리를 커스텀해서 락을 제거하고 동시성스레드랜덤을 사용해서 각 스레드에서 고유 랜덤을 뽑아낸다면 단조성을 해치지 않으면서도 성능이 좀 올라가지 않을까요?
좋은 글이네요. 공유해주셔서 감사합니다.