[개발] 비동기 대기 큐에 작업이 쌓여 제 시간에 수행되지 못하는 문제를 어떻게 해결할까?
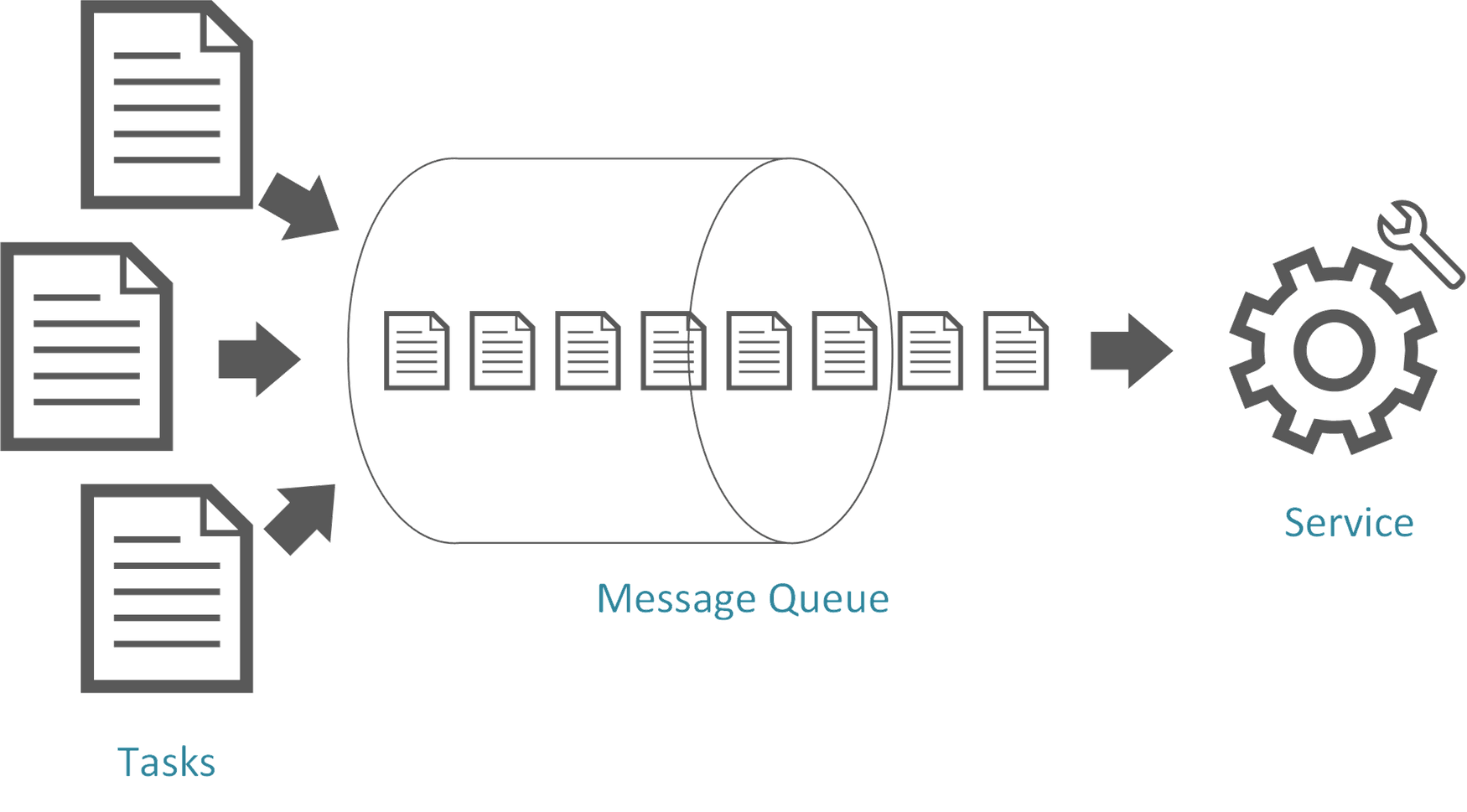
Django의 celery를 이용하여 주기적으로 매 작업을 비동기로 처리하는 작업을 처리하고 있었는데,
어느순간 확인해보니 작업이 원하는 시간에 수행되지 않고 밀려서 처리되고 있었습니다.
확인해보니 대기 큐에 많은 작업이 쌓여있었고, 그래서 제 시간에 worker가 해당 작업을 수행하지 못하고 있었습니다.
원인부터 파악해보면 다음과 같습니다.
저는 특정시간 간격으로 처리해야 할 11개의 작업(tasks)들이 있습니다.
확인해보니 celery에서 동시에 처리할 수 있는 concurrency pool이 default로 10으로 설정되어 있기 때문입니다.
터미널에서 celery -A {프로젝트 이름} worker -l info 를 입력해보면 처음에 다음과 같은 worker에 대한 정보를 확인할 수 있습니다.
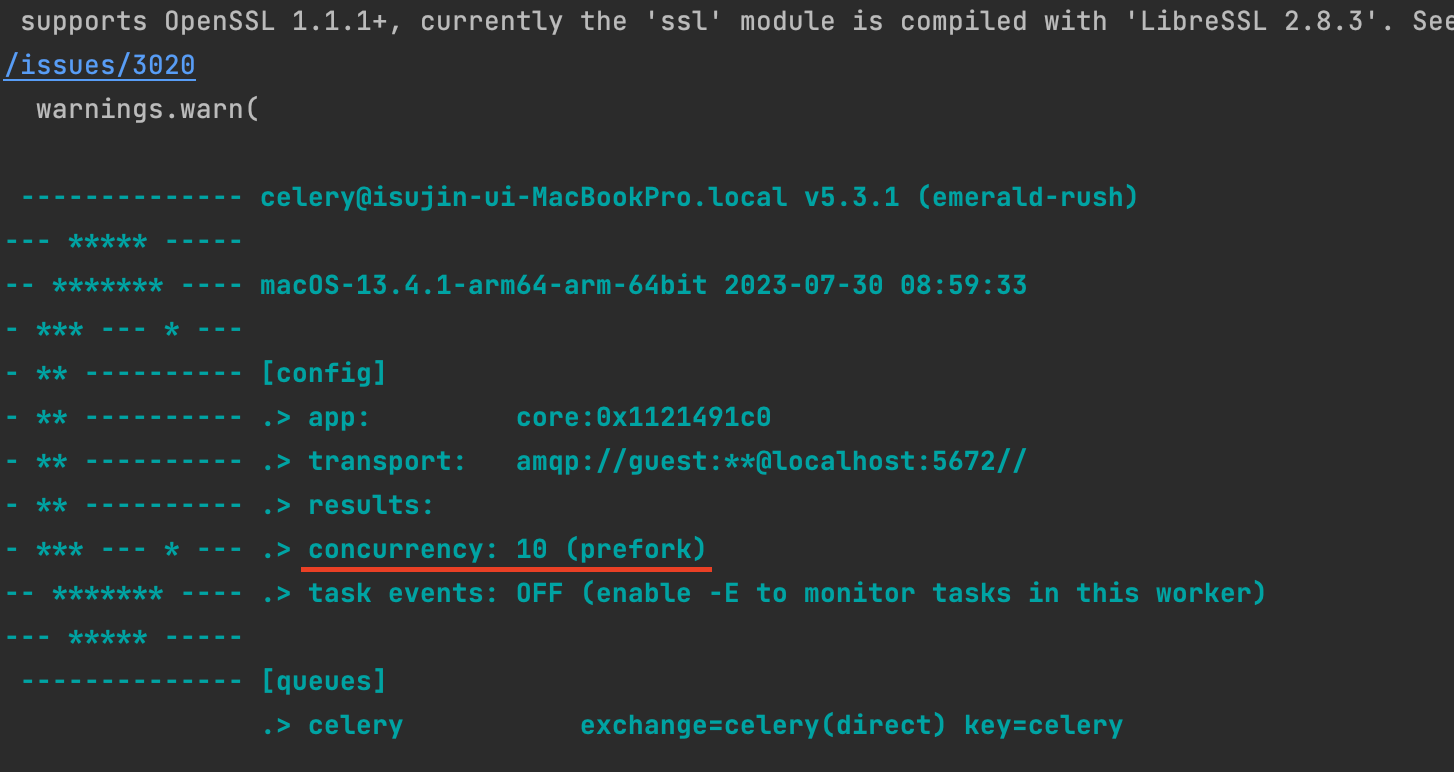
이렇게 default로 concurrency: 10 (prefork)라 되어있는데,
(해당 수는 따로 설정을 안하면 기본적으로 CPU 코어 개수만큼 디폴트로 설정됩니다.)
이는
처리할 수 있는 pool은 10인데, 저는 11개의 tasks를 수행하라고했으니 1개의 task가 계속 제 시간에 수행되지 못하기 때문입니다.
문제점은
밀리는 task가 처음엔 1개이지만, producer에서 발행되는 작업이 consumer가 소비되는 작업보다 커지게되면 이것이 누적되어 밀리기 때문입니다.
Problem: 비동기 큐에 작업이 쌓여 제 시간에 수행되지 못하는 문제를 어떻게 해결할까?
해당 문제점의 상황을 예시로 보여드리겠습니다.
처리해야 할 작업은 총 11개이며 매 분마다 실행되어야하며, 모든 작업이 걸리는 시간을 1분으로 설정하였습니다.
해당 상황의 가정을 예시로 보면, 처음엔 1개, 2분 뒤에는 2개, ... , n분 후에는 n개의 작업이 밀리게 됩니다.
먼저 celery.py에 다음과 같이 비동기로 처리해야 할 task들을 정의하였습니다.
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
from celery.schedules import crontab
# 기본 장고파일 설정
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'asynchronous-test.settings')
app = Celery('asynchronous-test')
app.config_from_object('django.conf:settings', namespace='CELERY')
#등록된 앱 설정에서 task 불러오기
app.autodiscover_tasks()
# task 함수 주기 설정
app.conf.beat_schedule = {
'api1': { # 스케쥴링 이름
'task': 'main.tasks.api1', # 수행할 task 설정
'schedule': crontab(minute='*')
},
'api2': {
'task': 'main.tasks.api2',
'schedule': crontab(minute='*')
},
'api3': {
'task': 'main.tasks.api3',
'schedule': crontab(minute='*')
},
'api4': {
'task': 'main.tasks.api4',
'schedule': crontab(minute='*')
},
'api5': {
'task': 'main.tasks.api5',
'schedule': crontab(minute='*')
},
'api6': {
'task': 'main.tasks.api6',
'schedule': crontab(minute='*')
},
'api7': {
'task': 'main.tasks.api7',
'schedule': crontab(minute='*')
},
'api8': {
'task': 'main.tasks.api8',
'schedule': crontab(minute='*')
},
'api9': {
'task': 'main.tasks.api9',
'schedule': crontab(minute='*')
},
'api10': {
'task': 'main.tasks.api10',
'schedule': crontab(minute='*')
},
'api11': {
'task': 'main.tasks.api11',
'schedule': crontab(minute='*')
},
...
} 이렇게 실행한뒤에
1분, 2분, 3분, 4분, 5분 후에는 어떻게 되는지 보여드리겠습니다
아까 디폴트로 실행시에 concurrency: 10(prefork) 라 했는데,
이는 celery worker가 동시에 처리할 수 있는 테스크는 최대 10개이고, 멀티프로세싱 방식을 사용하여 처리하는 옵션입니다.
즉, 각 테스크는 별도의 프로세스에서 실행됩니다.
concurrency: 10(prefork)워커는 최대 10개의 프로세스를 동시에 처리할 수 있으며, 각 테스크는 별도의 프로세스에서 실행됩니다
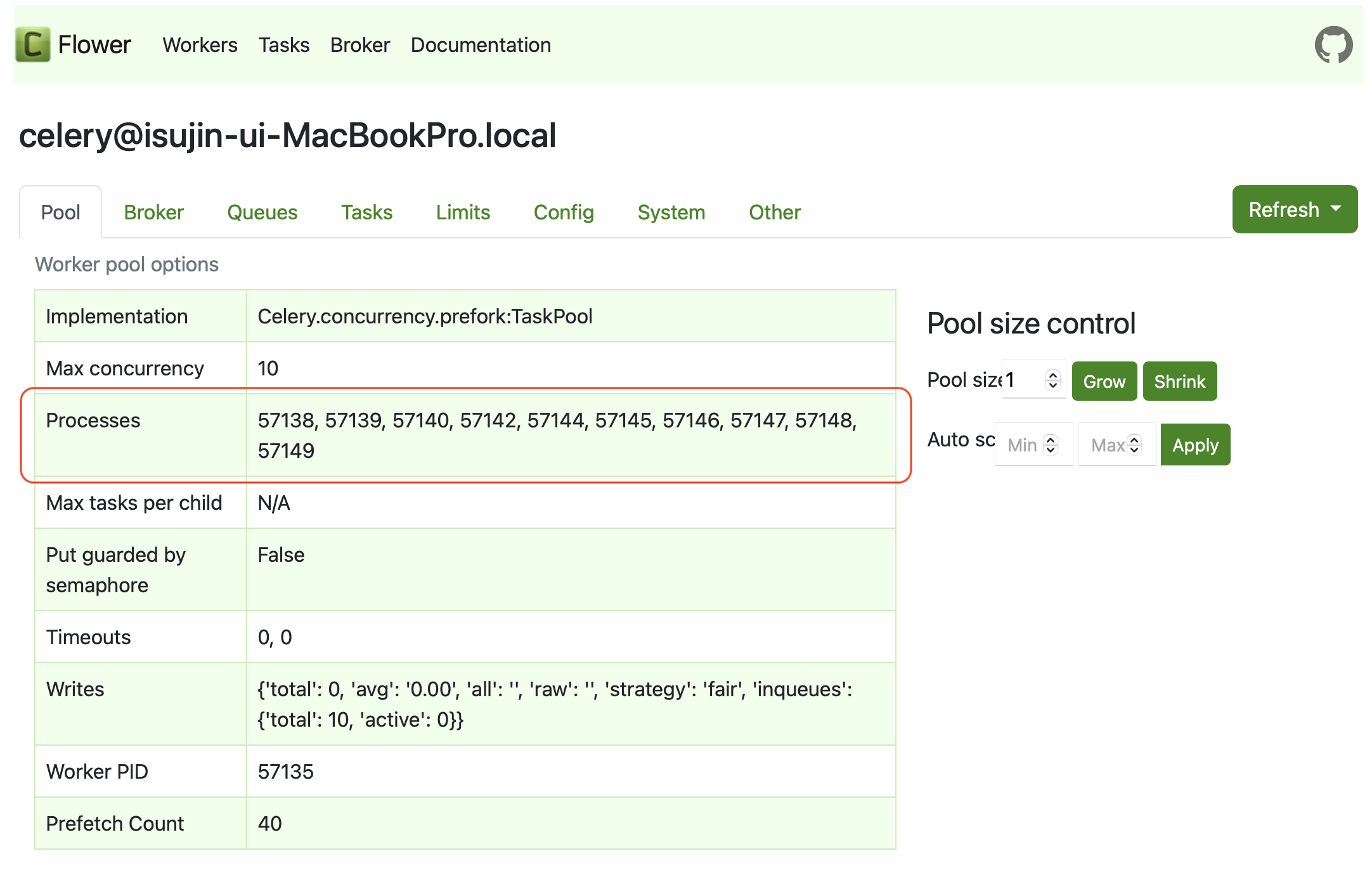
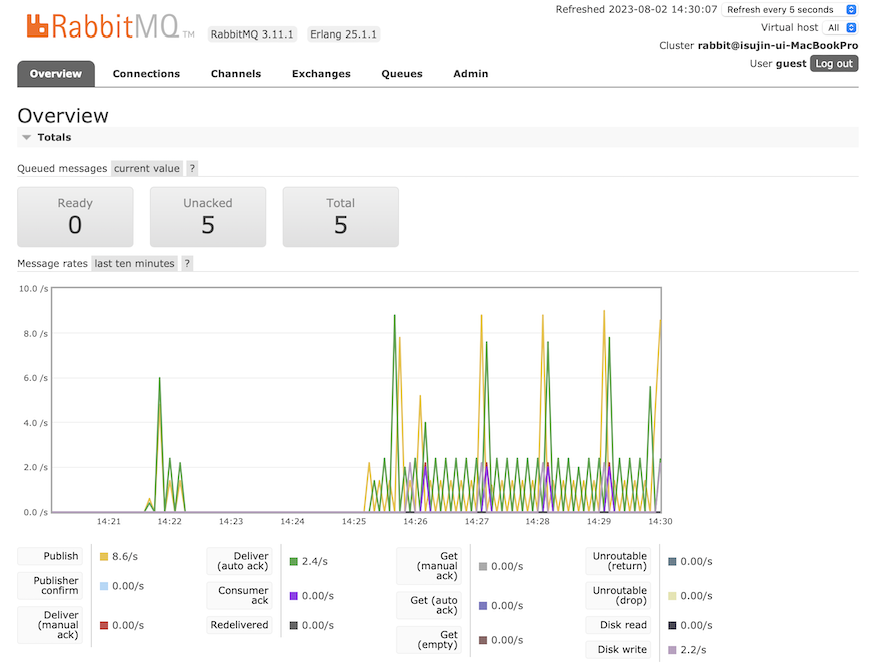
다음과 같이 celery 모니터링 툴인 flower로 확인해보면,
max concurrency 는 10이고,
processes 에는 PID가 표시되어 있는데, 구동되고 있는 process가 총 10개임을 알 수 있습니다.
처음 0분 경과 후
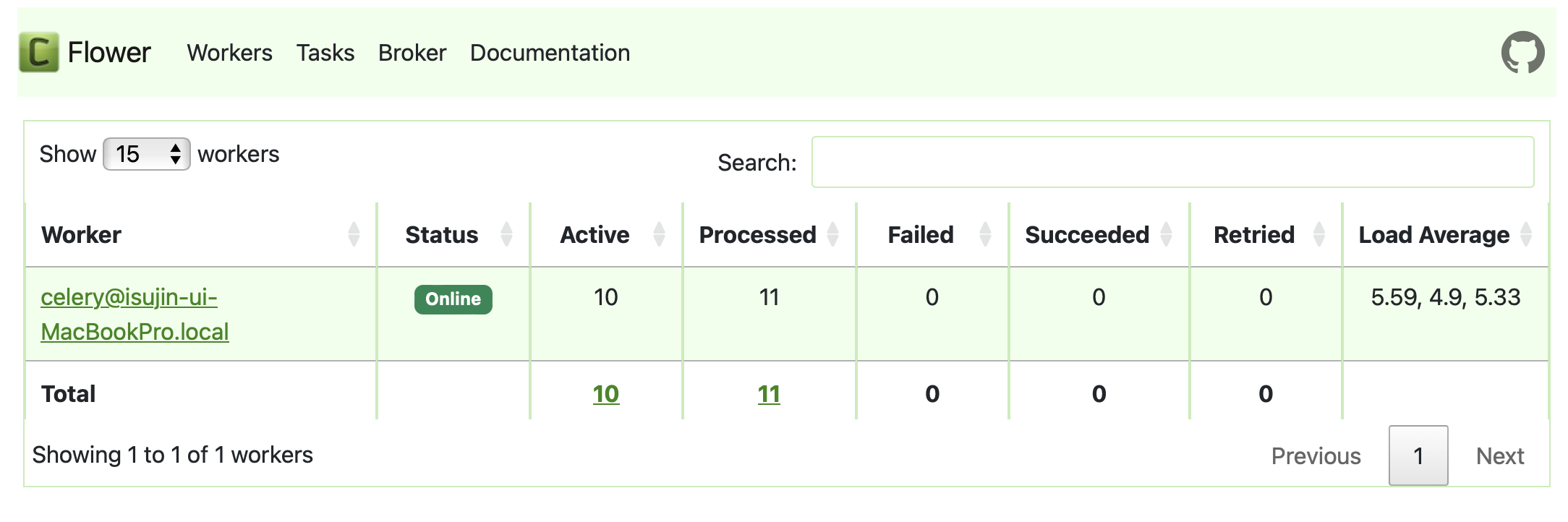
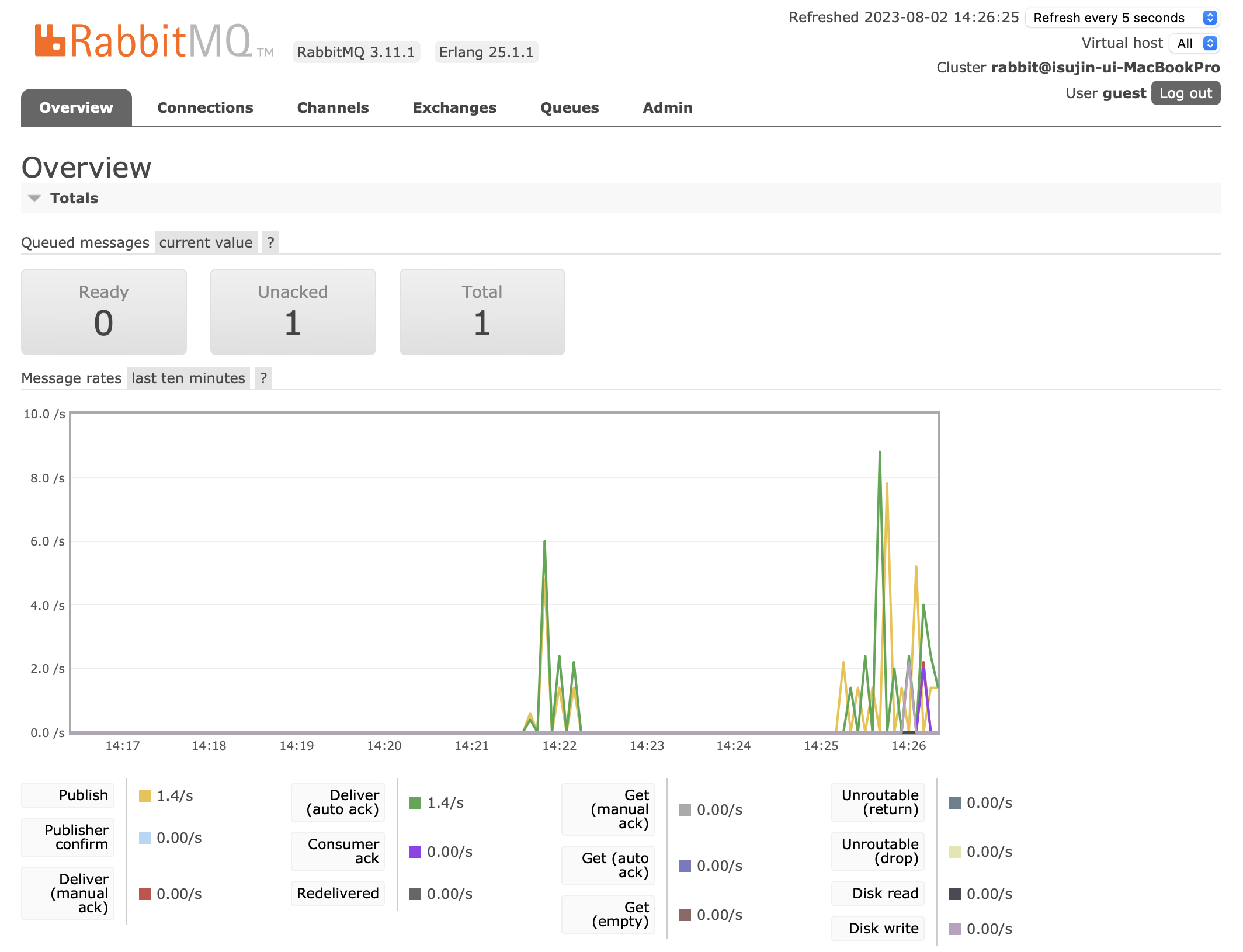
위 RabbitMQ 모니터링 툴을 보기 전에,
RabbitMQ가 Producer와 Consumer 사이에서 어떻게 Message 전달을 보장하는지 이 방법을 간단히 설명드리겠습니다.
Queue가 작업을 Consumer에게 전송하고, 전송이 완료되는 순간 Queue에게 Ack(승인)을 넘겨주게 됩니다.
현재 10개의 프로세스가 사용가능하니, 11개의 작업 중 10개가 할당되어 수행되고 있을거고
1개의 작업이 큐에 남아있는 상태입니다.
즉, 1개의 Ack이 아직 오지 않은 상태이며, Queue에는 1개의 작업이 남아있습니다.
처음 1분 경과 후
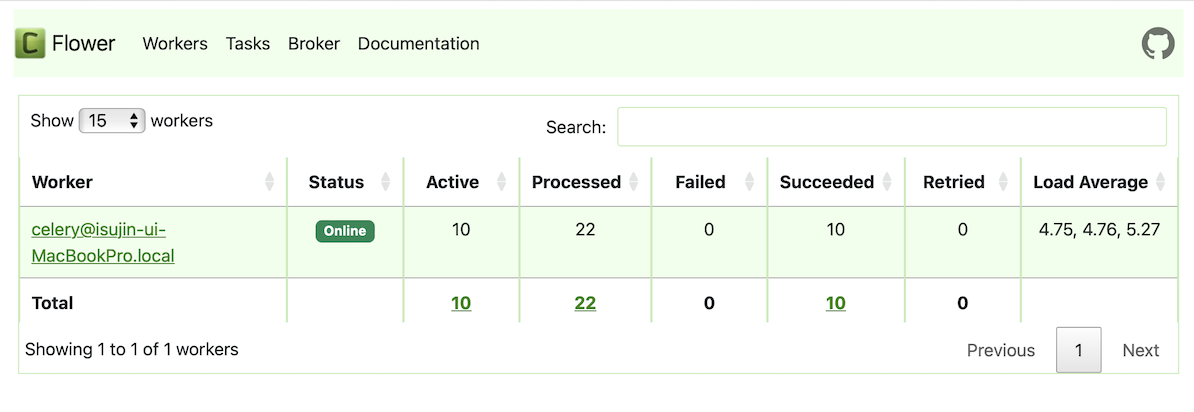
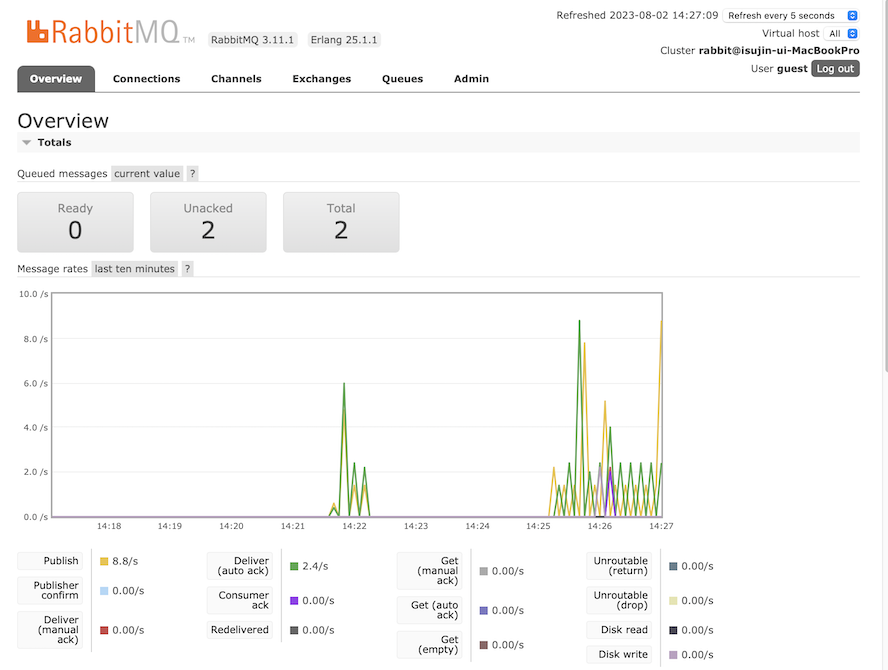
1분 경과 후 10개의 작업이 수행이 완료되었고,
다시 11개의 작업이 Producer로부터 들어옵니다.
Queue에는 2개의 작업이 쌓여있는걸 확인할 수 있습니다.
처음 2분 경과 후
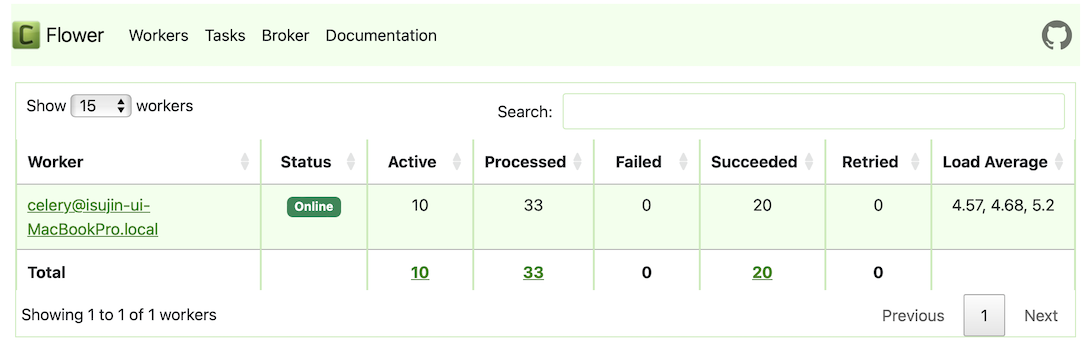
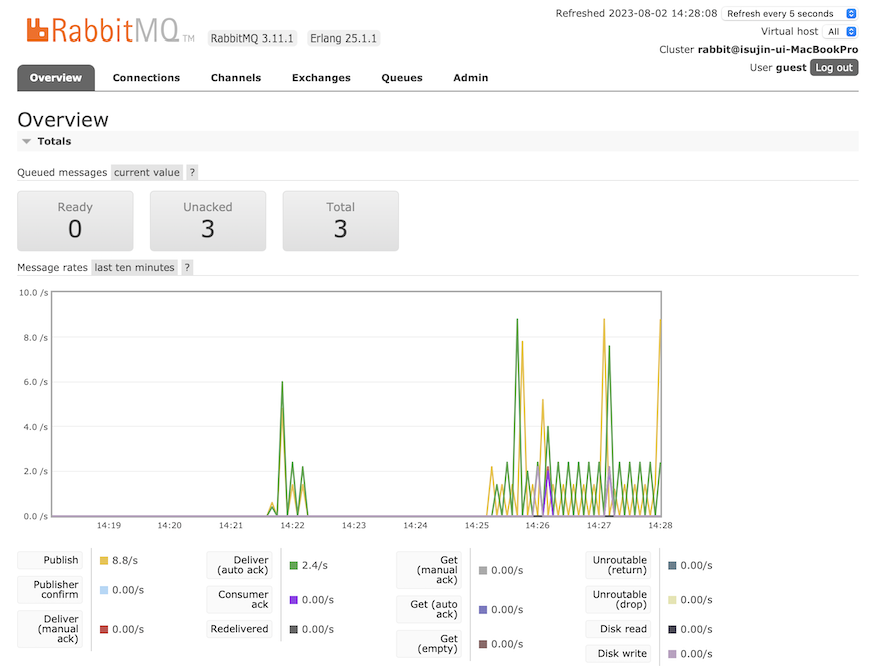
다시 10개의 작업이 수행이 완료되었고,
다시 11개의 작업이 Producer로부터 들어옵니다.
그래서 Queue에는 총 3개의 작업이 쌓여있는걸 확인할 수 있습니다.
처음 3분 경과 후
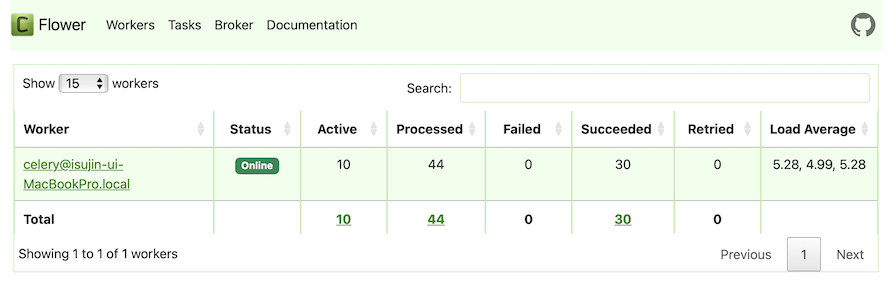
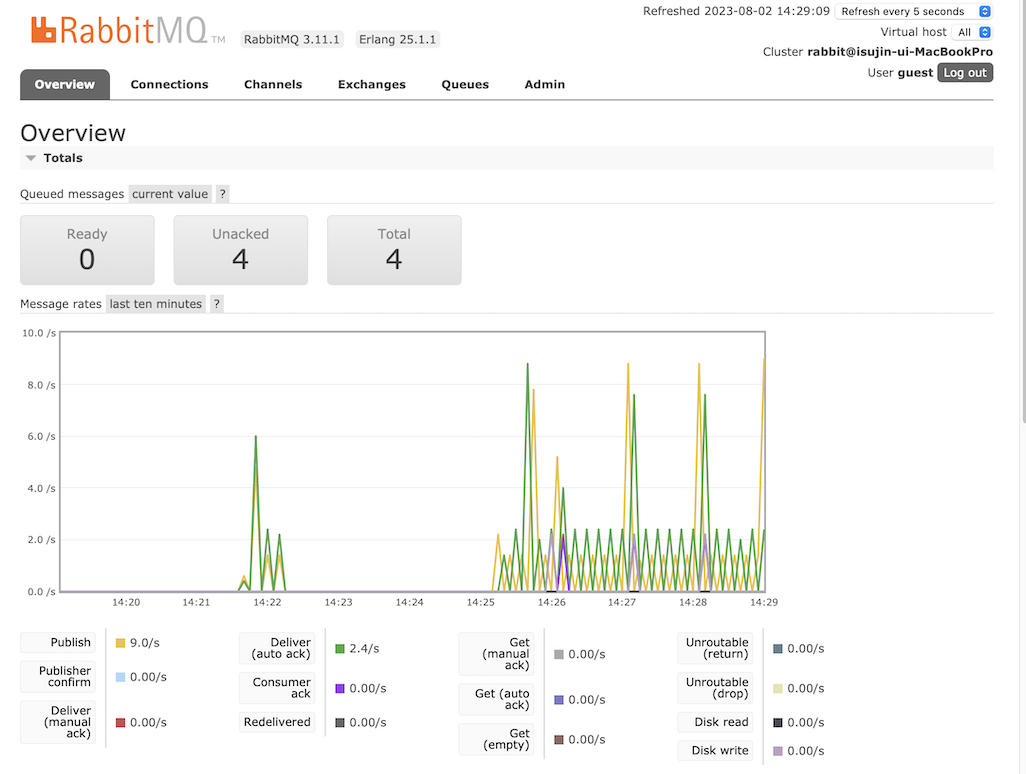
처음 4분 경과 후
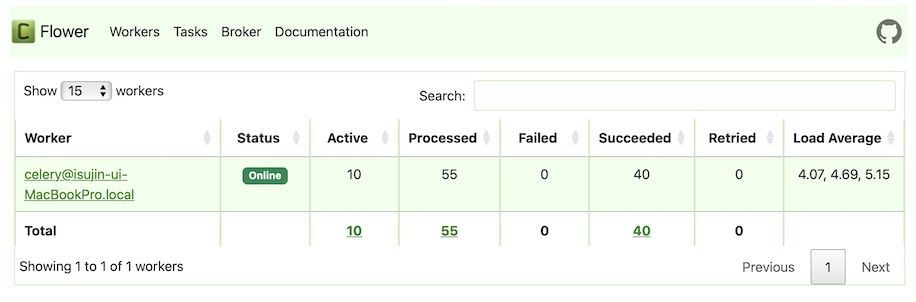
이렇게 시간이 지남에 따라 밀리는 작업이 누적으로 쌓이게 됨을 확인할 수 있습니다 🥲
작업의 요구사항이 단지 시간 관계없이 처리만 되면 상관이 없겠지만,
특정 시간에 맞게 처리가 되어야 하는 작업이면 (특정 시간에 알림 보내기) 이는 문제가 될 수 있습니다.
해당 문제는 모두 concurrency pool을 작업의 수 이상으로 늘려
다음은 제가 이를 해결하기 위해 써 본 세 가지 방법을 소개해드리려고 합니다.
Solution1 - 셀러리 서비스를 실행하는 프로세스의 수를 늘려 해결하기
첫 번째 방법은, 셀러리 서비스를 실행하는 프로세스의 수를 늘리는 방법입니다. 즉, 셀러리 워커가 멀티프로세싱 방식을 사용하여 테스크를 동시에 처리합니다.
각 프로세스는 독립적으로 작동하며, 메시지 큐에서 테스크를 가져와 처리하고 결과를 저장합니다.
위의 방법은 시스템의 처리 능력을 향상시키는 방법 중 하나입니다.
하지만, 해당 방법을 사용했을 시에 동시에 실행시키는 프로세스의 수가 많아지면 메모리 사용량도 증가하고, CPU 사용도 상대적으로 증가할 수 있으므로, 해당 애플리케이션의 요구사항을 고려하여 적절한 수의 동시성을 설정하는 것이 중요합니다.
해당 명령어는 다음과 같이 입력합니다.
celery -A {프로젝트 이름} worker -l info --pool=prefork --concurrency={숫자}
prefork 는 셀러리에서 기본으로 설정되는 동시성 옵션입니다. 이 옵션은 Python의 multiprocessing 라이브러리에 기반을 두고 있습니다. Python의 multiprocessing은 Python에서 여러 프로세스를 생성하고 관리하는 기능을 제공하며, 이를 통해 병렬 처리를 가능하게 합니다.
이러한 prefork 옵션은 CPU-bound 작업, 즉, CPU 자원을 많이 사용하는 작업에 특히 유용합니다. 그러나 해당 옵션을 사용할 때 주의할 점은, 프로세스 생성과 관리에는 상당한 비용이 들 수 있으므로, 작업의 병렬화 가능성과 시스템의 리소스 등을 고려하여 적절한 수의 프로세스를 생성해야 합니다. 그렇지 않으면, 너무 많은 프로세스를 생성하면 시스템의 리소스를 과도하게 소모하게 될 수 있으며, 프로세스의 수가 많아지다보면 어느 순간부터 프로세스를 더 생성하면 프로세스를 관리하는 오버헤드가 더 커져서 성능에 안좋아지는 지점이 있습니다
(하지만, 해당 방법은 process pool을 크게 설정해도 최대로 설정 가능한 process pool은 내 CPU 코어에 맞게 제한이 된다는 점입니다.)
추가)
그럼 내 CPU 코어보다 더 많은 process pool을 할당하면 어떻게 될까? 🧐
실제로 CPU 코어 수보다 더 많은 프로세스가 생성될 수 있지만, 한 번에 실행될 수 있는 작업의 수는 시스템 CPU 코어 수에 의해 제한이 됩니다.
가용 가능한 CPU 코어 수에서 할당된 프로세스 수 만큼 컨텍스트 스위칭으로 작업이 수행됩니다
Solution2 - 스레드의 수를 늘려 해결하기
셀러리는 2개의 스레드 기반 셀러리 풀을 제공합니다 - eventlet / gevent
둘 다 실행 풀이 worker랑 같은 프로세스에 있으며, 둘 다 greenlet을 이용하고 스레드를 생성해서 각 스레드가 작업을 처리하게 됩니다.
좀 더 자세한 설명을 추가하자면,
Eventlet/Gevent 는 Green Thread 기반의 동시성 옵션으로, Green Thread란, 운영체제가 아닌 어플리케이션 레벨에서 스케줄링하는 가벼운 스레드를 의미합니다.(즉, 내 CPU코어랑은 상관이 없음) 이런 방식은 I/O bound 작업, 특히 network I/O bound 작업에 적합합니다. 이 옵션을 이용하면, 한 워커 프로세스 내에서 수백, 수천개의 작업을 동시에 처리할 수 있습니다. (수백개까지 적당히 많이 써도 상관이 없다고 합니다)
스레드 수를 늘려 작업을 처리하려면, 명령어를 다음과 같이 입력합니다.
(다음은 gevent를 사용한 예시입니다.)
celery -A {프로젝트 이름} worker -l info --pool=gevent --concurrency={숫자}
해당 명령을 실행하면, 셀러리 워커는 하나의 프로세스를 생성하고, 그 안에서 그린 스레드를 {숫자}만큼 생성하여 동시에 여러 작업을 처리하게 됩니다.
Solution3 - 내 CPU 코어에 맞게 프로세스 수 할당하고 나머지는 스레드의 수를 늘려 이를 처리
위의 방법 1과 2를 합친 방법입니다.
즉, 가용가능한 CPU만큼 프로세스 풀을 할당하고, 그리고 각 프로세스 내부에서 스레드 풀을 할당하는 방법입니다.
celery multi start {프로세스 수} -A {프로젝트 이름} --pool=gevent --concurrency={스레드 수}
다음과 같이 celery multi 라는 명령을 사용하면 여러 워커 프로세스를 동시에 생성하고, 각 워커 프로세스는 --concurrency={스레드 수} 옵션에 따라 최대 {스레드 수} 개의 작업을 동시에 처리할 수 있습니다. 이는 각 워커 프로세스 내에서 gevent를 사용해 처리됩니다.
따라서 시스템 전체에서 동시에 처리할 수 있는 작업의 최대 수는 워커 프로세스의 수와 --concurrency={스레드 수} 옵션에 따라 결정됩니다.
예를 들어,
celery multi start 2 -A {프로젝트 이름} --pool=gevent --concurrency=10
이라 했을때
총 2개의 워커 프로세스를 생성하고, 각 워커 프로세스는 동시에 최대 10개의 작업을 처리할 수 있으므로 최대 2*10 = 20 개의 작업을 동시에 처리할 수 있습니다.
이젠 각각의 방법에 대해서 테스트를 해보고, 성능을 비교해보려고 합니다.
실제로 제가 비동기로 처리해야하는 작업은 외부 공공 api를 호출하고, 해당 json파일을 가져오고, 가공 및 파싱 그리고 계산 작업을 수행하고, 해당 정보를 db에 업데이트 시켜주어야 합니다.
외부 api 호출, 그리고 db에 데이터를 업데이트 시켜주는 작업은 모두 네트워크 I/O 가 드는 작업이고,
해당 json파일의 정보들을 가공, 파싱 및 계산하는 작업은 CPU 연산이 많이 드는 작업이라고 판단했습니다.
방법1은 멀티프로세싱에 적합한 방법이고,
방법2는 멀티스레딩에 적합한 방법이라고 생각했는데
멀티 프로세싱(Multi-processing)
멀티 프로세싱은 각 프로세스가 독립적인 메모리 공간을 가지며, 이로 인해 데이터를 공유하거나 통신하는 것이 상대적으로 느리지만, 각 프로세스가 별도의 CPU 코어에서 동시에 실행될 수 있으므로 CPU를 많이 사용하는 작업에 효율적입니다.
멀티 스레딩(Multi-threading)
멀티 스레딩은 한 프로세스 내에서 여러 스레드가 메모리를 공유하므로 데이터를 공유하거나 통신하는 것이 빠릅니다. I/O작업 (네트워크 요청, 디스크 I/O)와 같이 대기 시간이 많은 작업에서는 한 스레드가 대기하는 동안 다른 스레드가 작업을 계속할 수 있으므로 효율적입니다.
제가 처리해야하는 작업은 CPU연산에 적합한 작업이다, I/O 작업에 적합한 작업이다 라고 단정짓기가 어려워서
각각의 성능을 비교해보고 테스트해봄으로써 결정하게 되었습니다.
celery 모니터링 툴인 flower, 그리고 RabbitMQ management 툴을 이용하여 이를 확인해보았습니다.
그리고 좀 더 수치를 극대화해서 비교해보기 위해 11개의 동시요청이 아닌 100개의 동시요청을 테스트해보려합니다.
✔️ 테스트1 - 프로세스 풀을 100으로 할당하고, 100개의 동시요청 작업 수행하기
✔️ 테스트2 - 스레드 풀을 100으로 할당하고, 100개의 동시요청 작업 수행하기
✔️ 테스트3 - 프로세스 풀을 10, 각 프로세스 당 스레드 풀을 10 할당하고, 100개의 동시요청 작업 수행하기
Solution1~3 성능 테스트해보기
Test1 - 프로세스 풀을 100으로 할당하고, 100개의 동시요청 작업 수행하기
다음과 같은 명령어를 통해
celery -A {프로젝트 이름} worker -l info --pool=prefork --concurrency=100
100개의 프로세스를 생성하여, 이를 동시에 처리하도록 하였습니다.
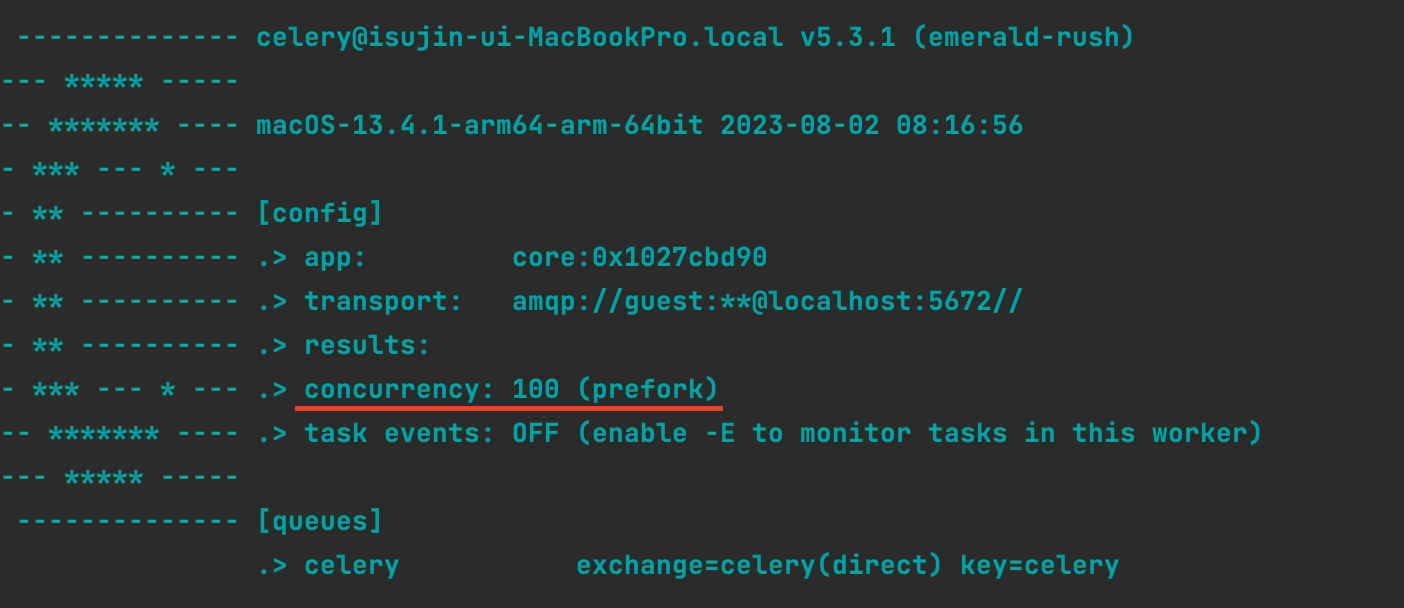
한 개의 워커에
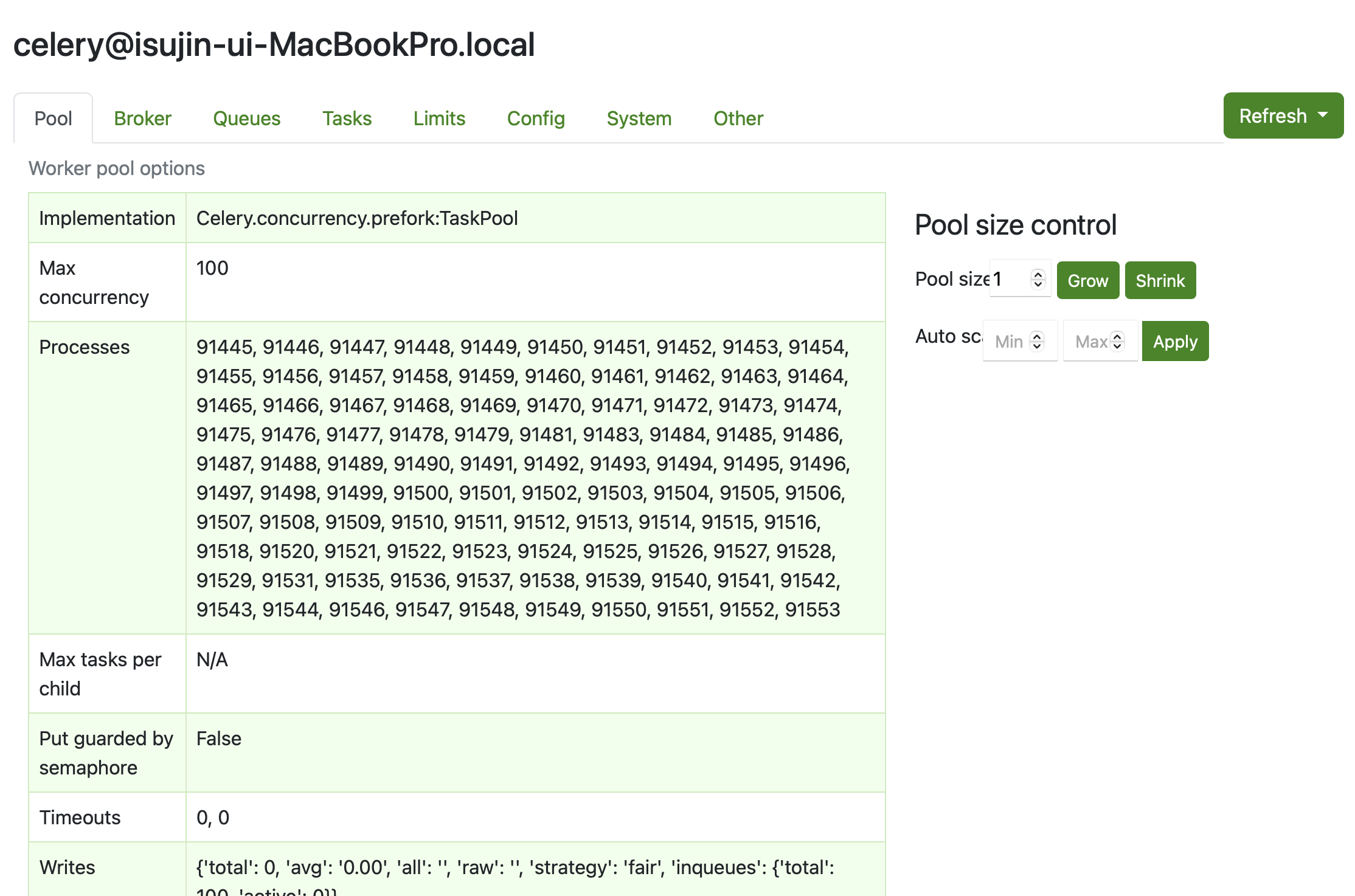
다음과 같이 100개의 프로세스가 할당되어 있습니다.
해당 작업 수 만큼 프로세스를 할당했으므로
queue에 밀림 현상이 없는 것을 확인했으며
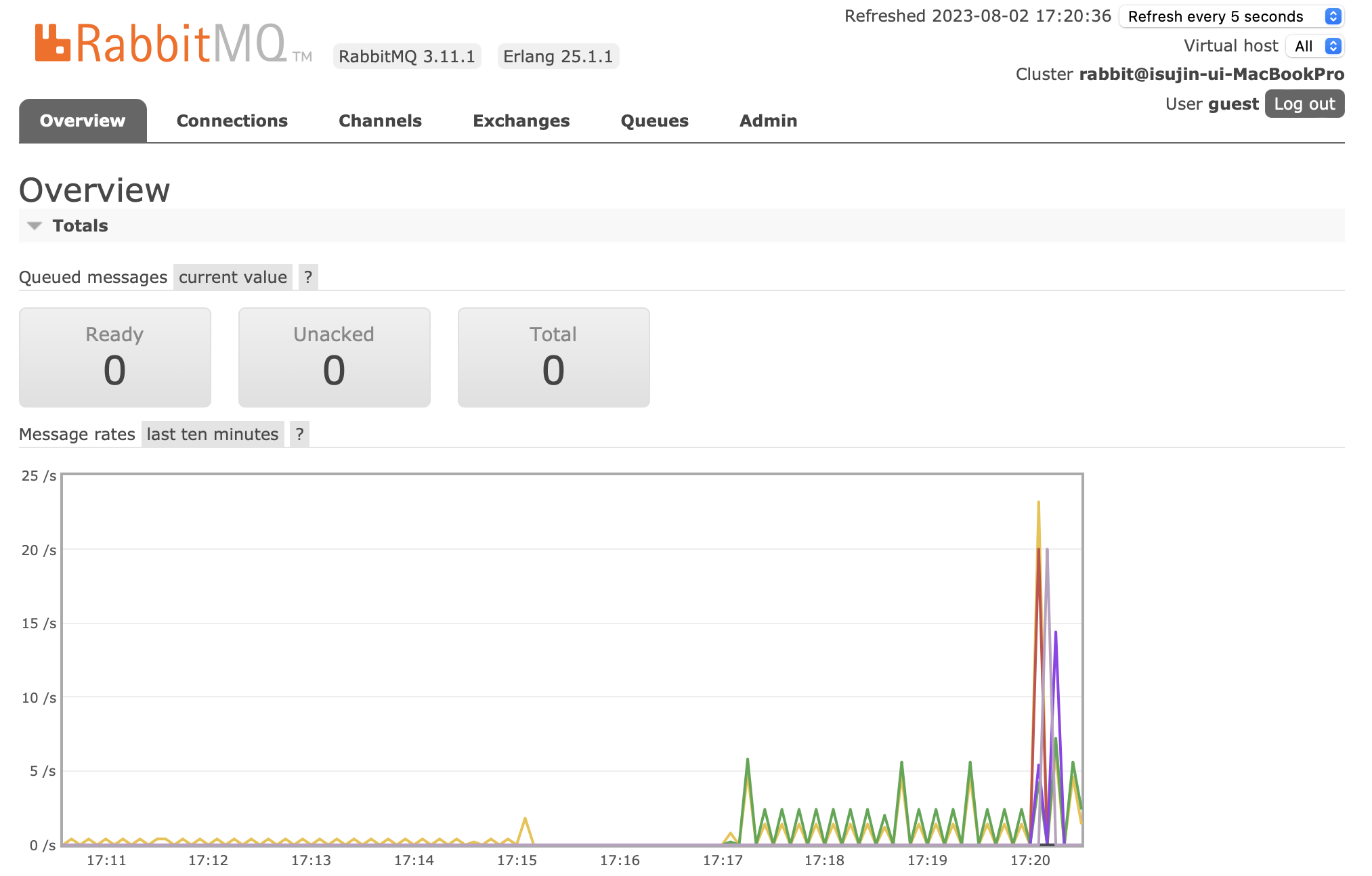

(제가 Task하나를 잘못 입력하여 실패로 떴습니다.🥲)
이렇게 총 해당 작업에 대한 정보를 확인할 수 있습니다!
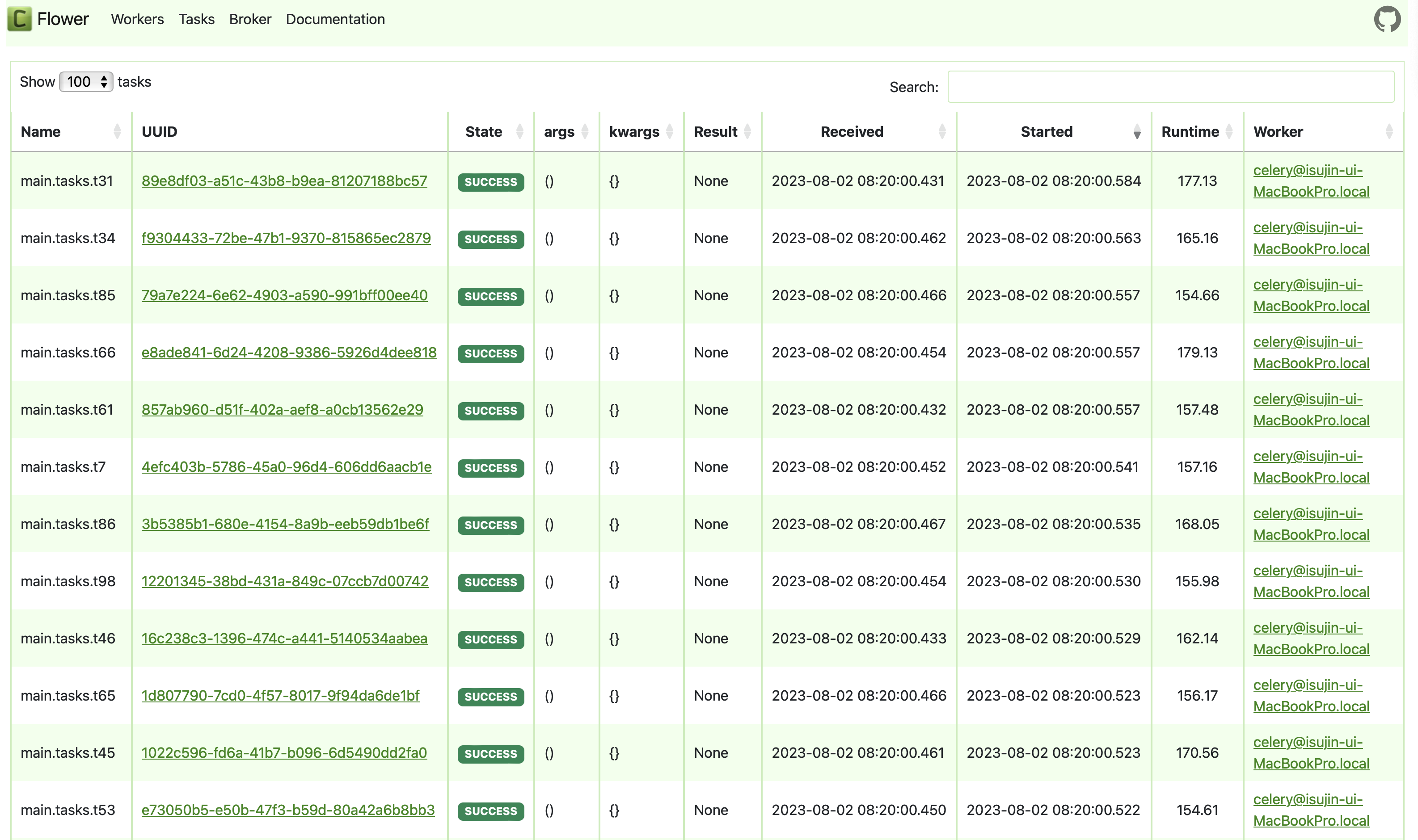
성능은 100개의 작업에 대해 각각의 runtime의 평균값으로 계산했습니다.
Test1의 runtime = (성공한 99개의 작업의 runtime 시간들의 합) / (99개의 task)
= 18001.170000000002 / 99
= 181.83
Test2 - 스레드 풀을 100으로 할당하고, 100개의 동시요청 작업 수행하기
명령어를 다음과 같이 입력했고,
celery -A {프로젝트 이름} worker -l info --pool=gevent --concurrency=100
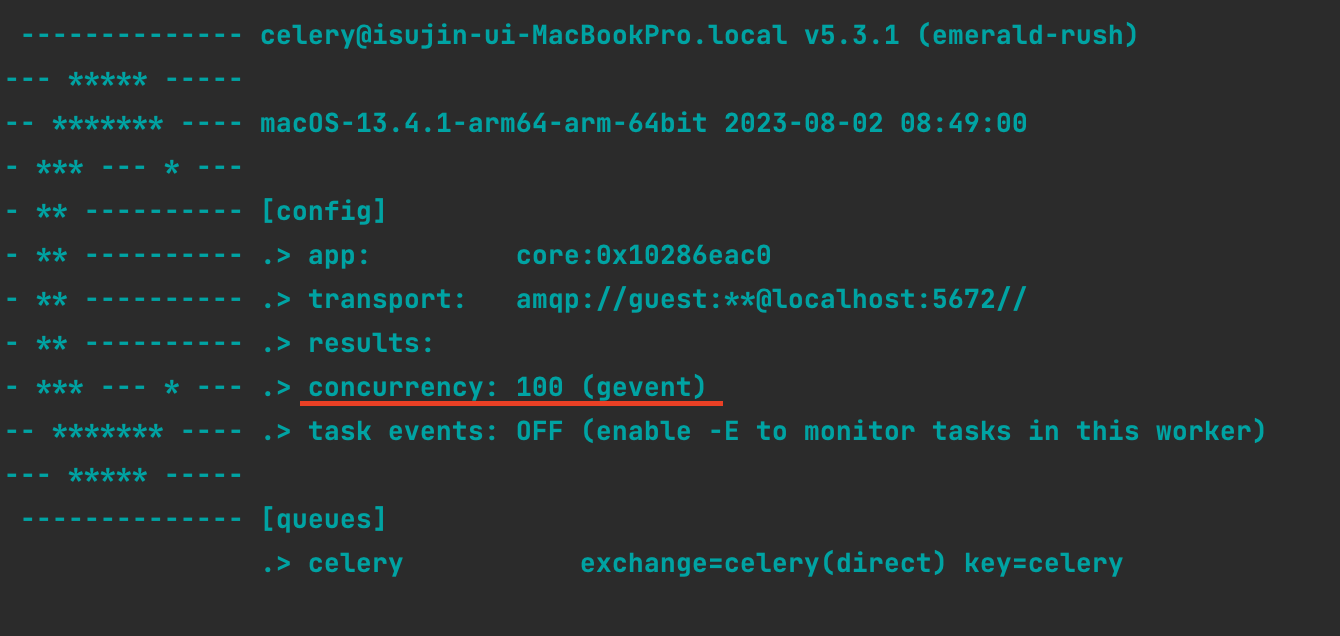
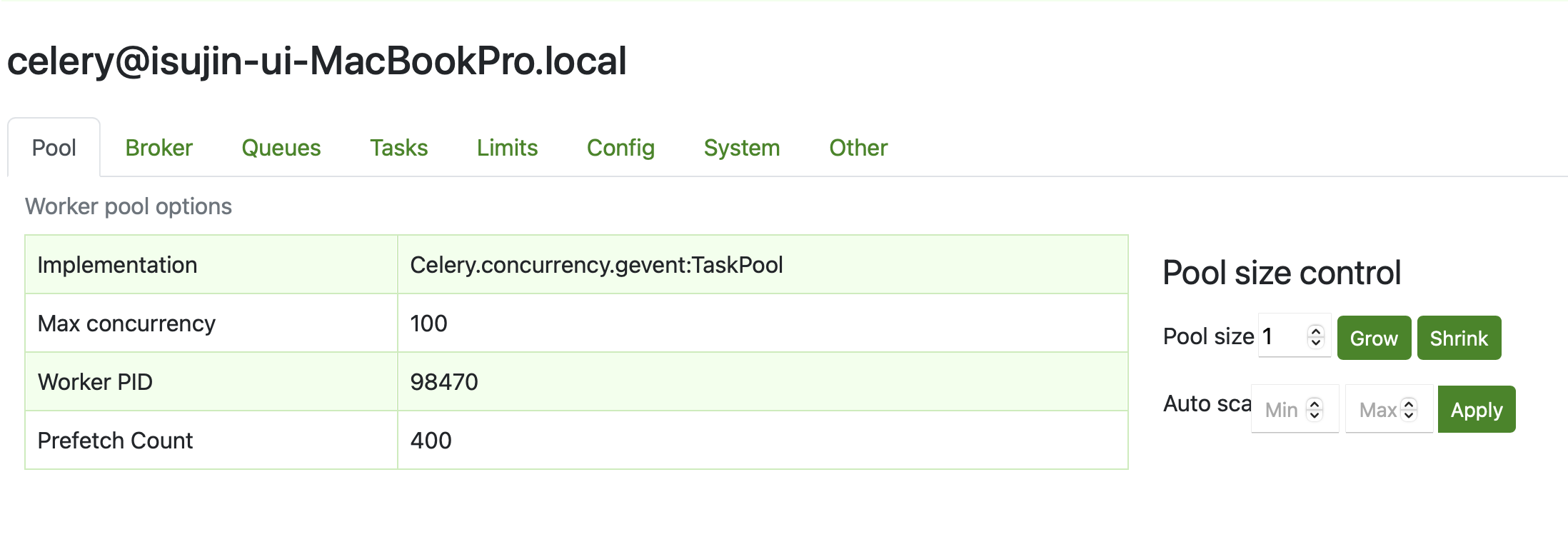
다음과 같이 하나의 프로세스 (PID 98479)에서 스레드 풀을 100개까지 생성할 수 있도로 하고 작업을 수행하도록 하였습니다.
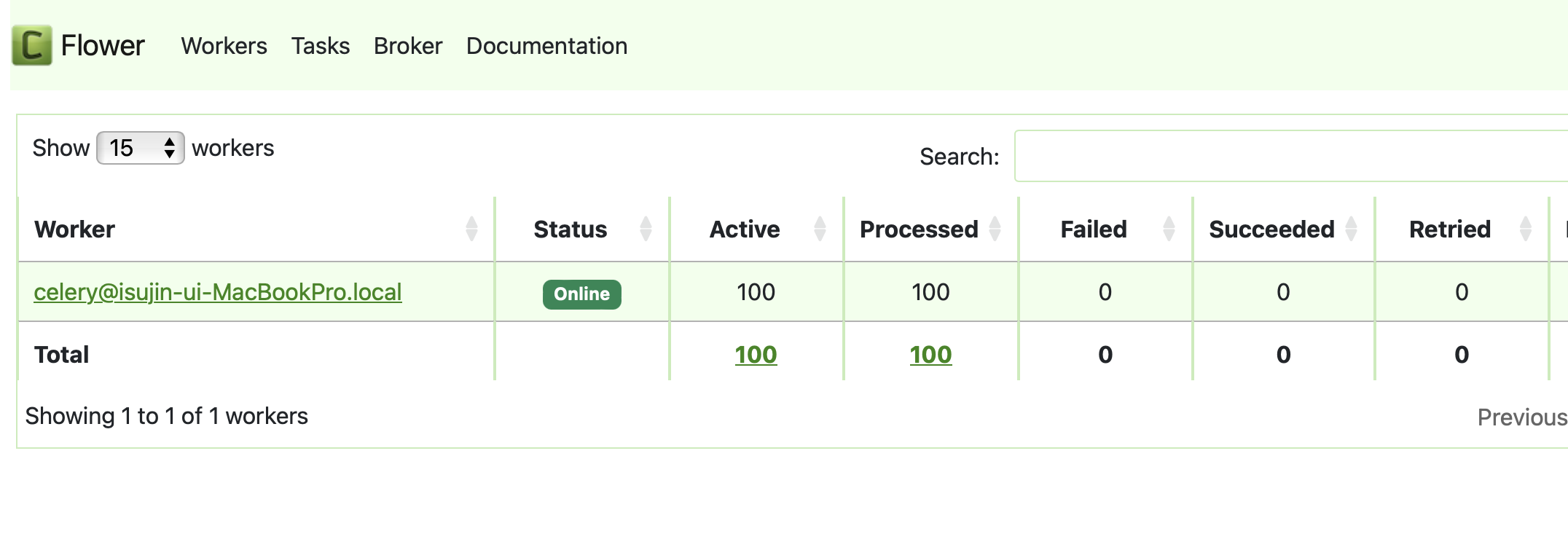
작업 100개를 동시에 받았을 때에 이렇게 가용영역 쓰레드를 100개를 생성하여,
각 모든 작업이 해당 쓰레드에서 수행되고 있는 것을 확인할 수 있었으며
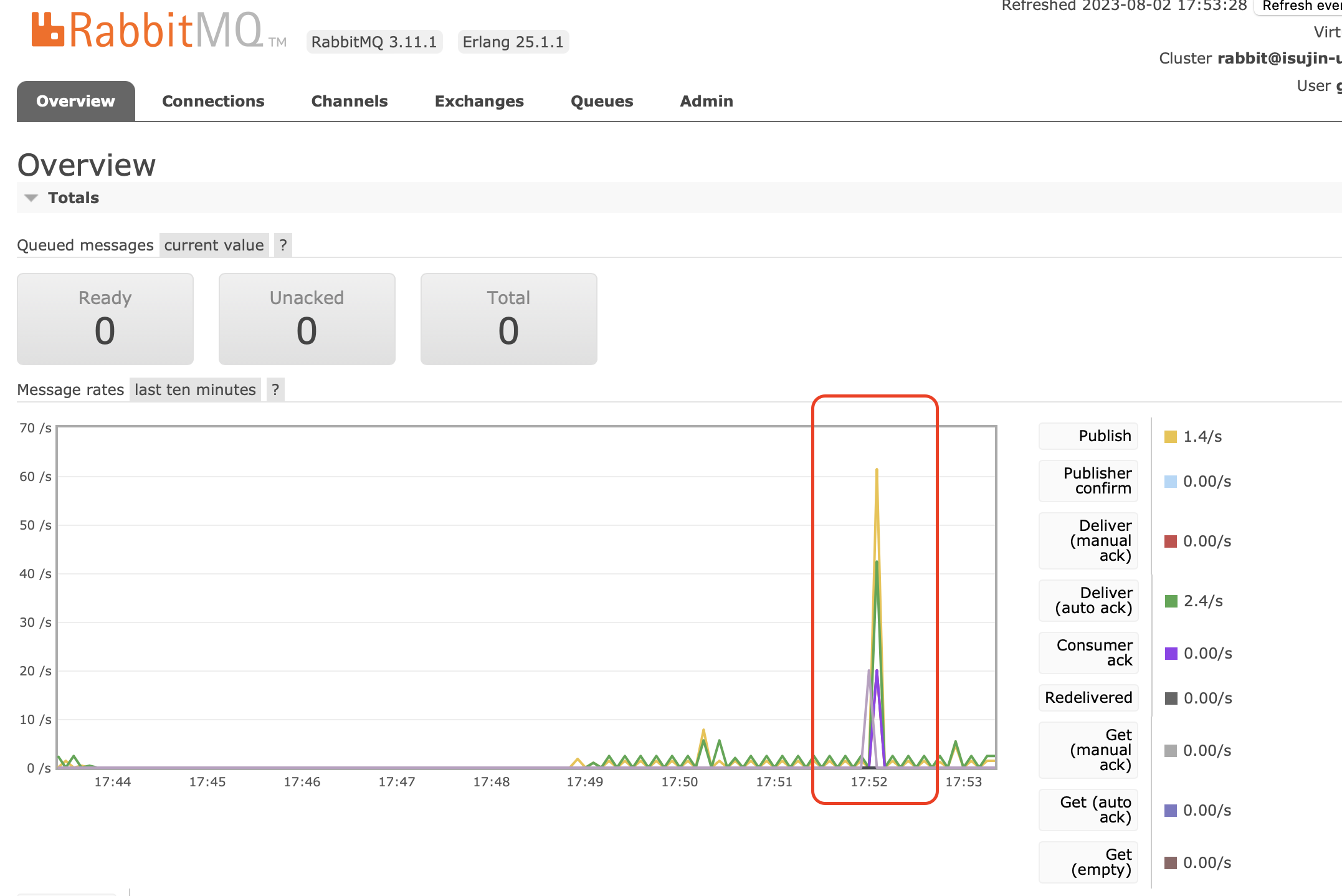
52분에 작업이 producer가 작업을 publish 한 뒤에 큐에 밀린 작업이 없는 것도 확인하였습니다
Test2의 runtime = (성공한 100개의 작업의 runtime 시간들의 합) / (100개의 task)
= 15955.029999999997 / 100
= 159.55
멀티프로세스보다 멀티스레드의 성능이 좀 더 높음을 확인할 수 있었습니다.(걸린 시간)

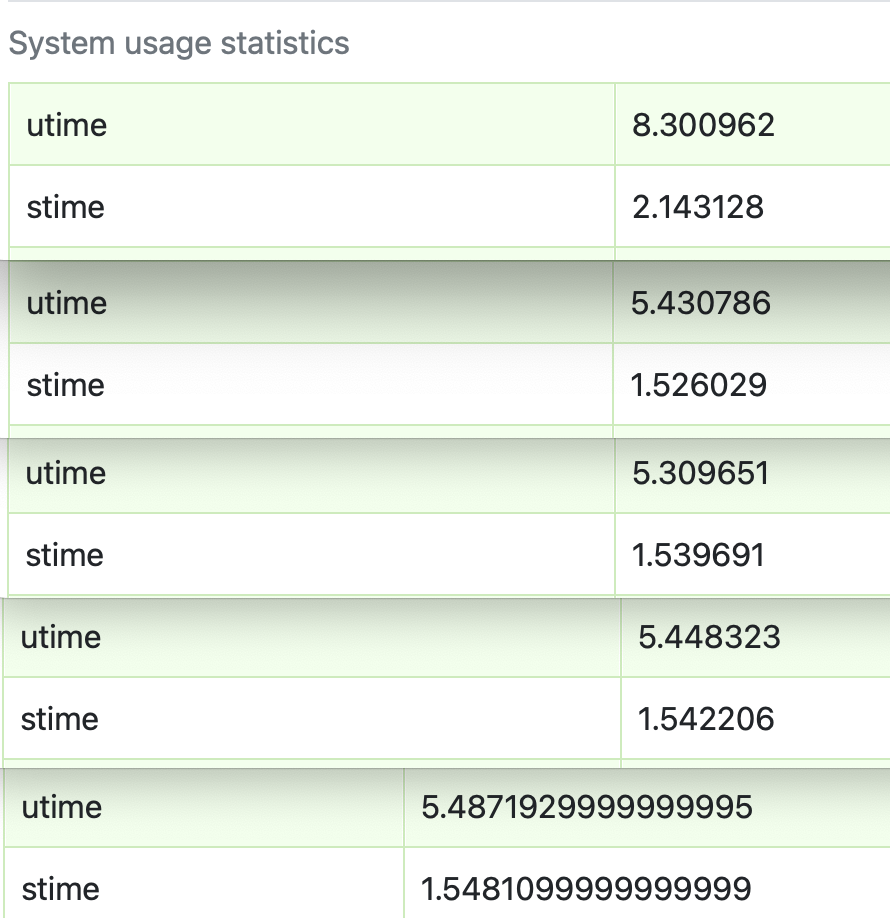
왼쪽이 한 프로세스에 스레드 풀을 100 할당한 해당 프로세스에 대한 통계이고(Test2), 오른쪽이 프로세스만을 할당한 것 중 하나의 통계(Test1)입니다
utime(user CPU time)과 stime(system CPU time)을 모두 확인해보았을 때에 프로세스 내 다중 쓰레드를 형성한 (한 프로세스에서 멀티쓰레딩으로 처리된) 두 번째 케이스의 CPU 사용률이 훨씬 더 높음을 확인할 수 있습니다.
즉, 처리 시간도 스레드 풀을 할당한 케이스가 더 적게 걸렸고, 해당 프로세스 내 한 CPU 당 CPU 이용률도 더 높음을 확인할 수 있었습니다.
그래서 멀티쓰레딩 방법을 이용하여 처리하는 것이 좀 더 효율적이라고 생각했습니다.
참고)
- utime(user CPU time): 프로세스가 직접 제어하는 작업에 소비된 CPU 시간을 나타냄, 이 시간은 어플리케이션 코드 실행에 사용된 시간을 의미
- stime(system CPU time): 운영체제가 프로세스를 위해 수행한 작업에 소비된 CPU 시간을 나타냄
Test3 - 프로세스 풀을 5, 각 프로세스 당 스레드 풀을 20개 할당하고, 100개의 동시요청 작업 수행하기
명령어를 다음과 같이 입력했고,
celery multi start 5 -A {프로젝트 이름} --concurrency=20 -l info
그럼 다음과 같이 5개의 worker가 각각 하나당 프로세스 하나씩 할당하여 생성됩니다.
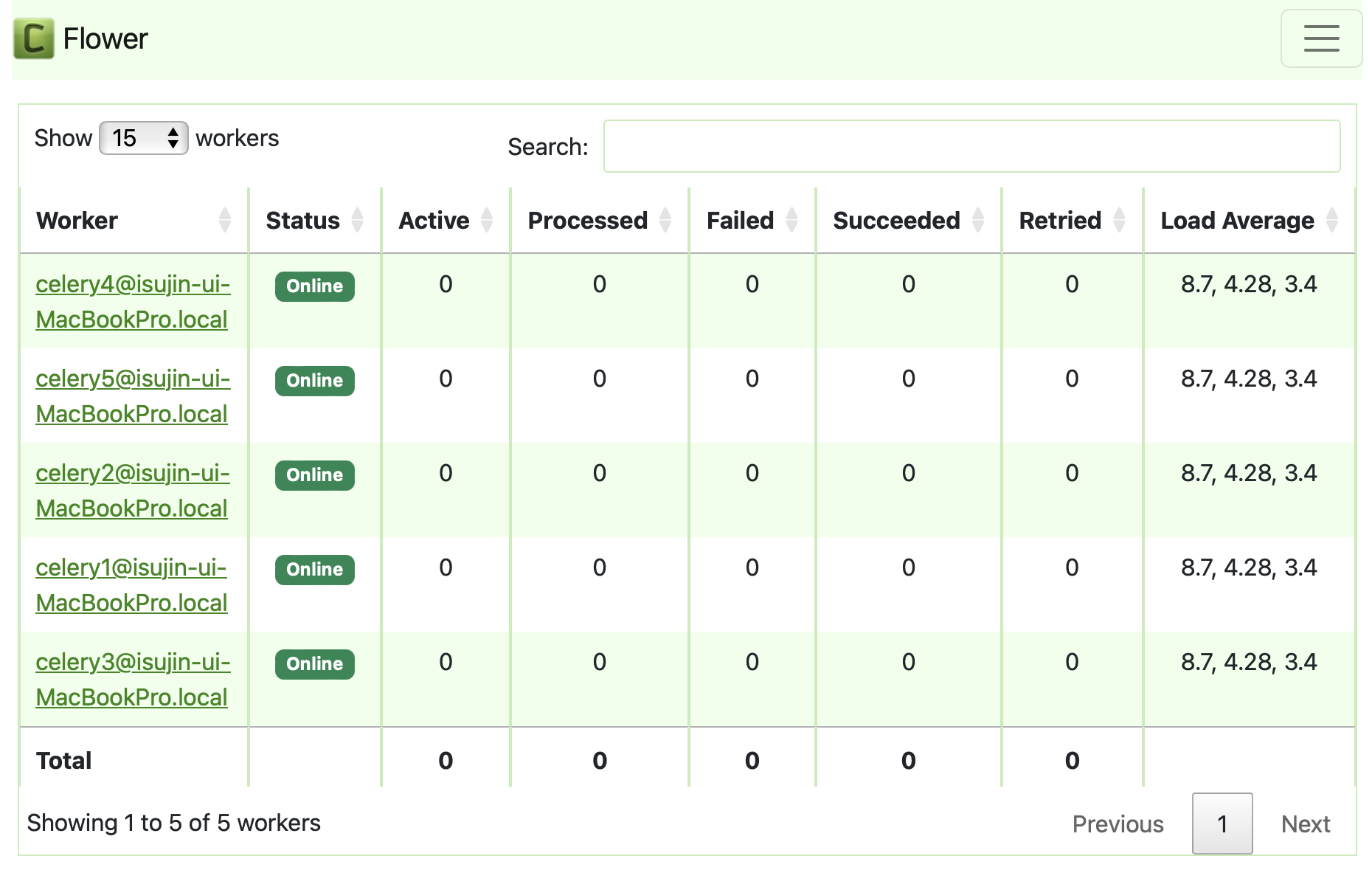
이렇게 총 5개의 worker가 생성되었고
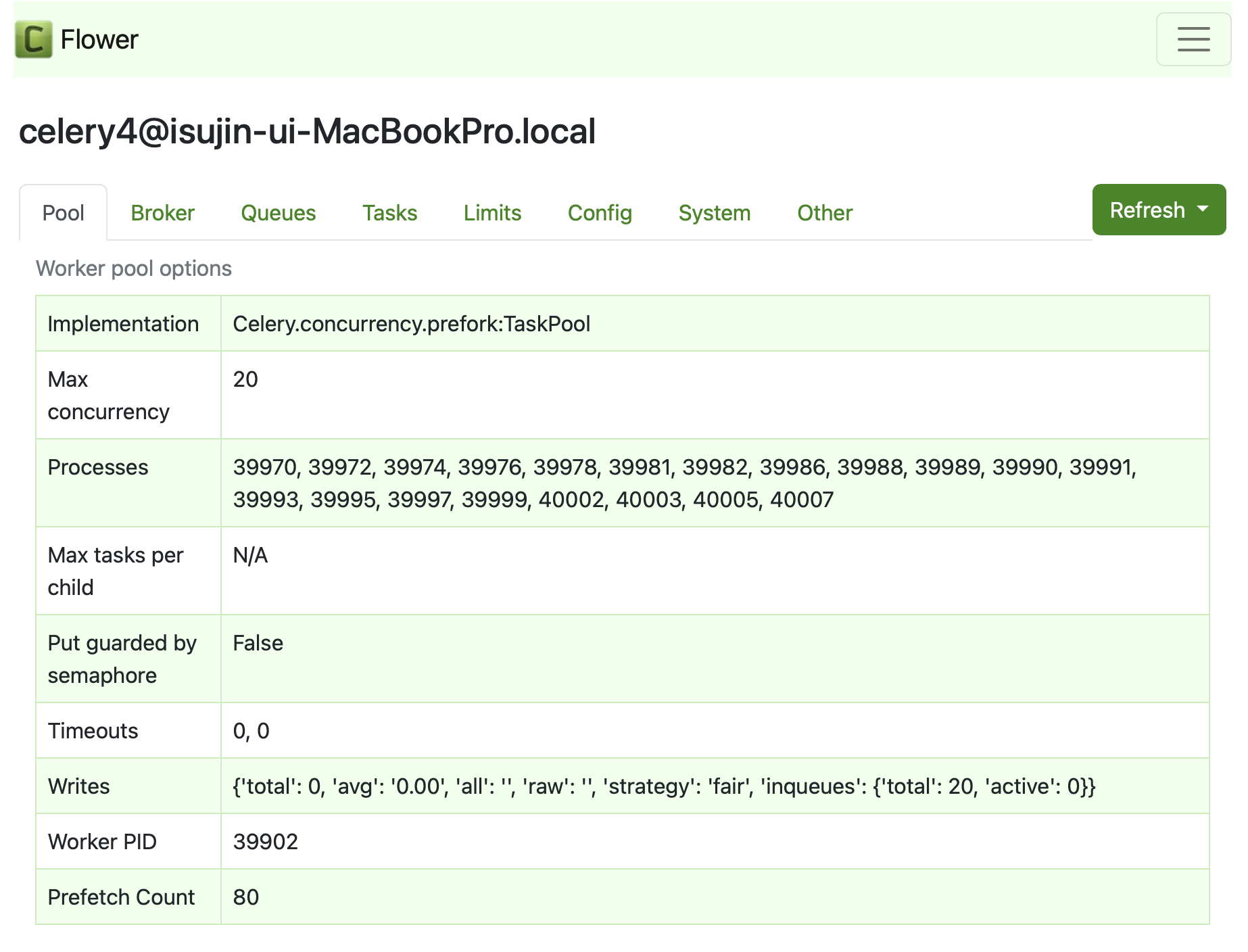
각 워커는 max concurrency=20개를 가지고 있습니다
(maximum 20개의 스레드가 생성가능합니다)
작업이 할당되면
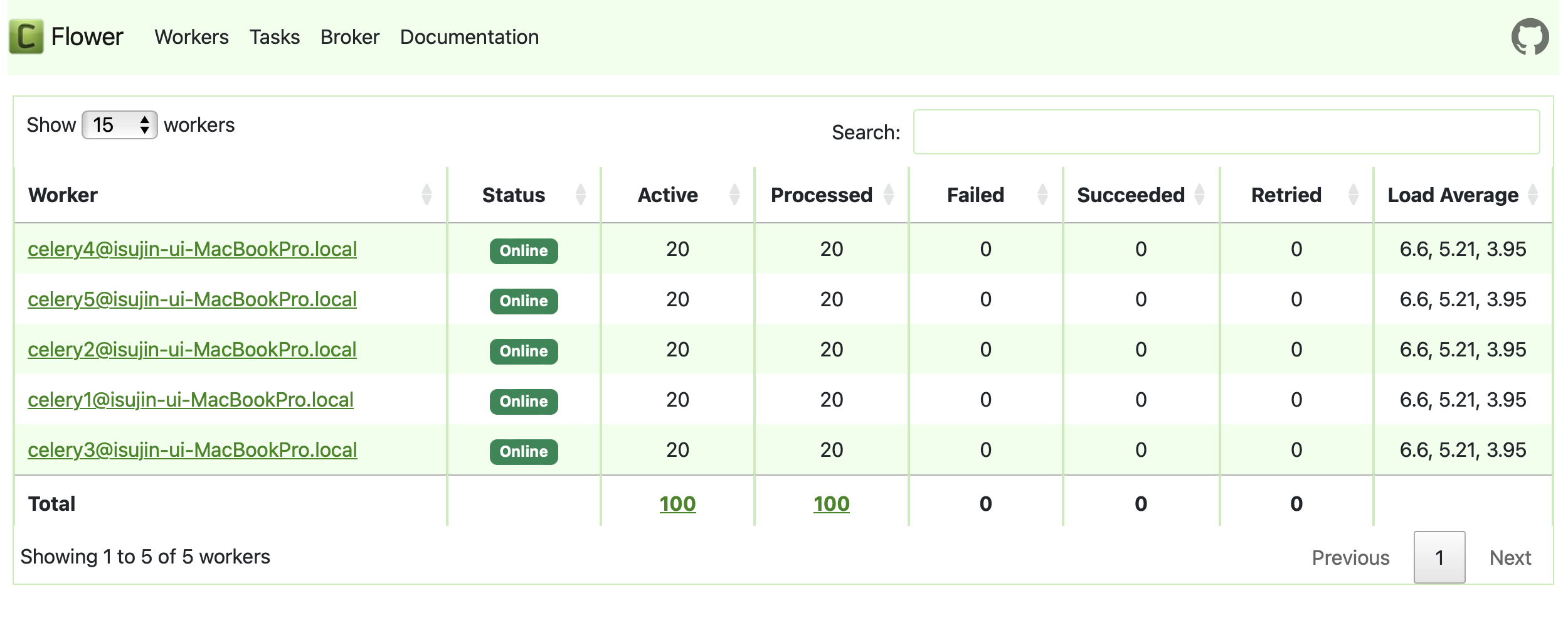
다음과 같이 모든 worker의 프로세스가 가용 최대영역인 스레드 20개 풀을 모두 사용하여 task를 수행함을 알 수 있습니다
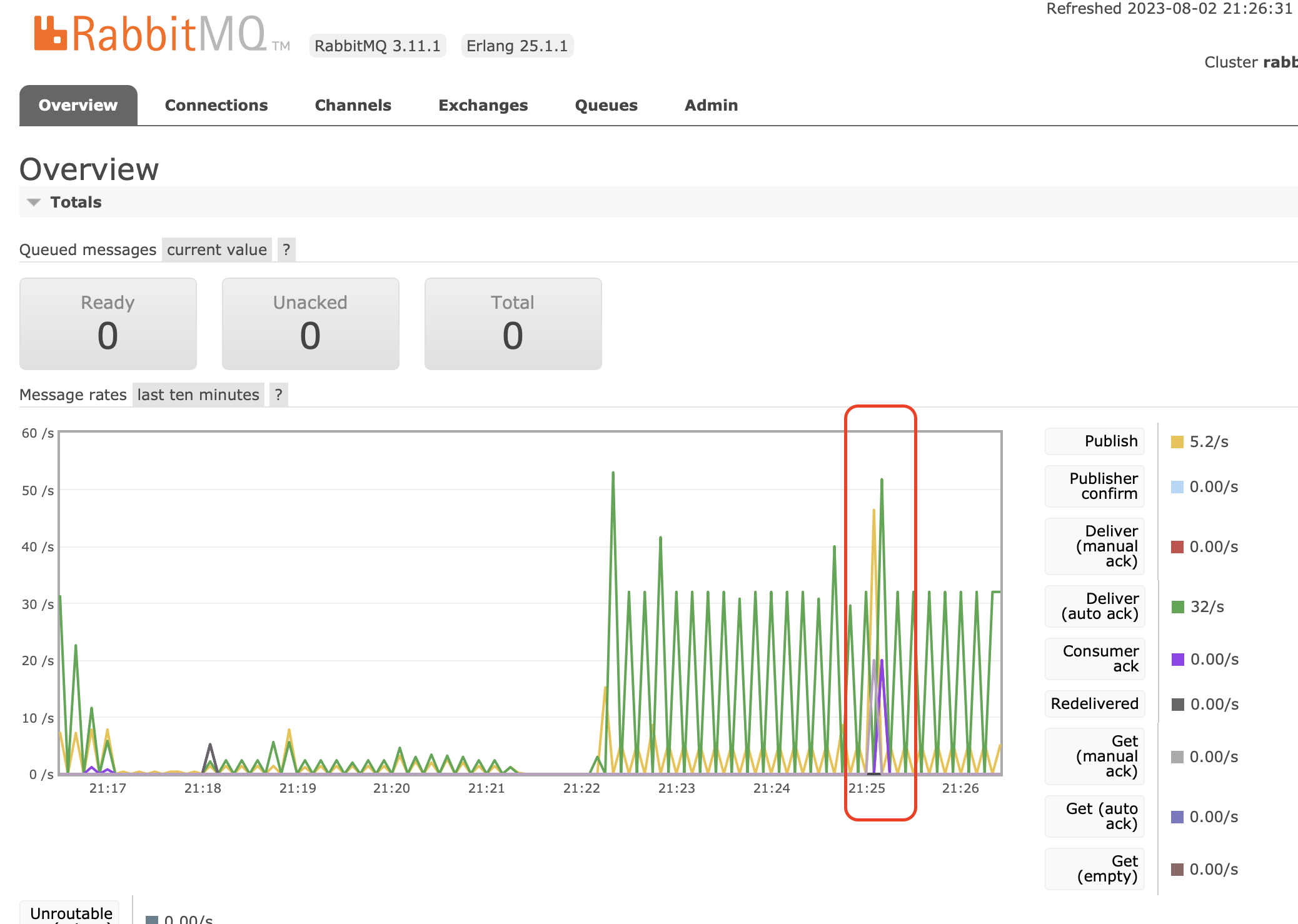
모든 작업을 할당받아 수행중이니, Queue에도 밀린 작업이 없음을 확인할 수 있습니다 (25분에 100개의 task를 publish 했음)
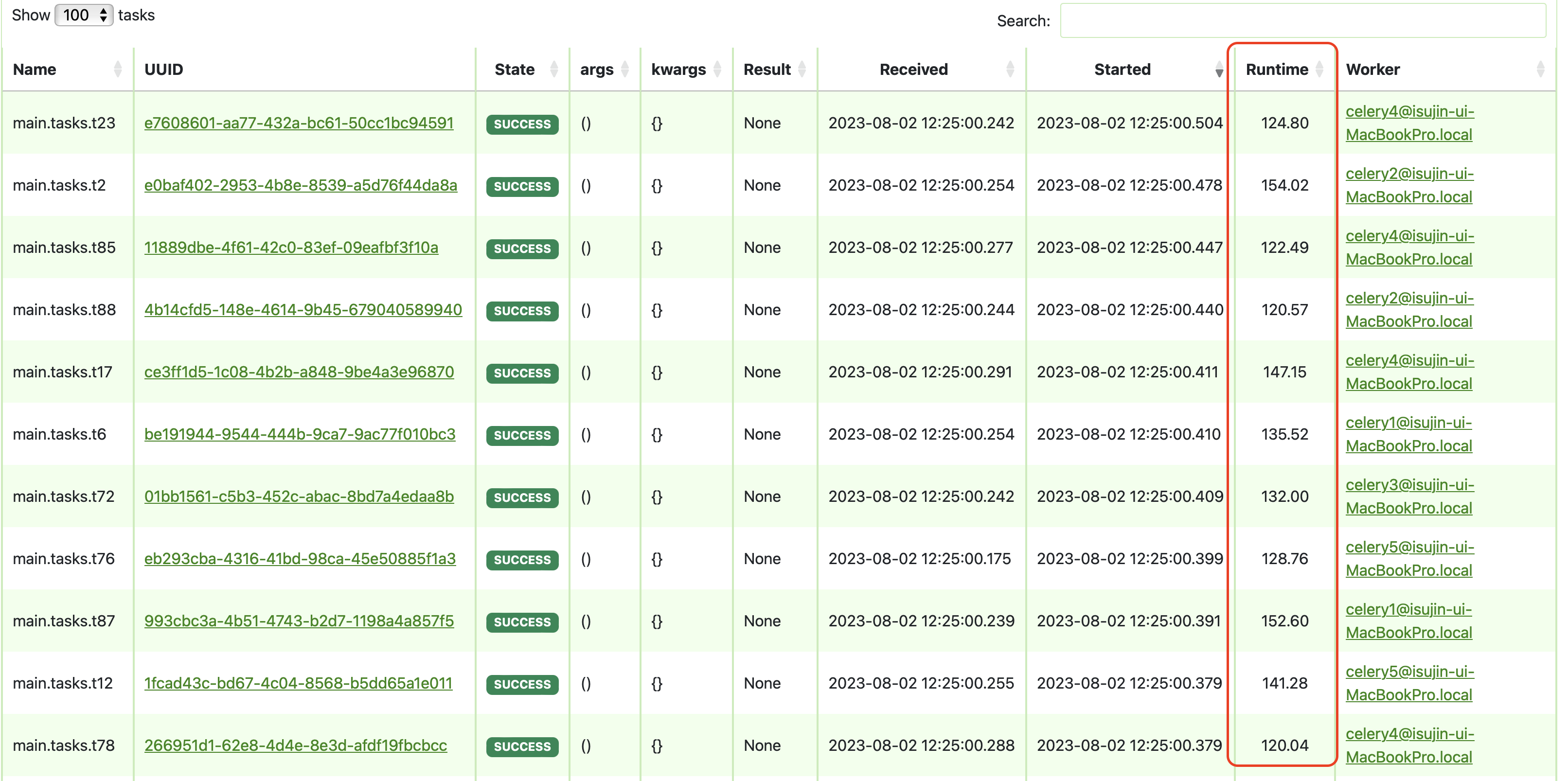
위에 방법 1,2 보다 훨씬 더 빠른 시간으로 수행을 마침을 확인할 수도 있었습니다.
Test3의 runtime = (성공한 100개의 작업의 runtime 시간들의 합) / (100개의 task)
= 13441.740000000005 / 100
= 134.42
그리고 각 프로세스 당 CPU 사용률도 확인해보았을 때에
(한 번에 캡쳐하려고 ^^,,)
프로세스 각각을 할당했을때보다는 이용률이 높지만,
프로세스 하나에 스레드 모두를 할당했을 때 보다는 낮음을 확인할 수 있었습니다
테스트 통계를 보면 다음과 같습니다
각각의 [걸린 시간] 과 [CPU 이용률]
- sol1: 프로세스 풀을 100 할당 - 181.83 / 2.589436
- sol2: 프로세스 1, 스레드 풀 100 할당 - 159.55 / 21.305896
- sol3: 프로세스 풀 5, 스레드 풀 20 할당 - 134.42 / 5.9953828
| 평균 걸린 시간(response time) | 각 프로세스 하나 당 CPU 사용률 | |
|---|---|---|
| 멀티 프로세스 | 181.83 | 2.589436 |
| 멀티 스레드 | 159.55 | 21.305896 |
| 멀티 프로세스 + 멀티 스레드 | 134.42 | 5.9953828 |
방법1이 가장 좋지 않은 방법이라고 생각했고 (시간도 가장 많이 걸리고, CPU 이용 효율이 높지 않기 때문),
방법2, 3이 1보다는 좋은 방법이라고 생각했습니다.
그리고 시간상 성능이 엄청 크지 않은 이상, 방법 3은 CPU 이용률이 2보다는 많이 낮아 낭비가 있다고 생각을 했습니다.
그래서 지금과 같은 상황에서는 시간상의 성능차가 그렇게까지 크지 않은 이상, CPU 이용률이 더 높아 이용 효율이 높은 방법 2(멀티 스레딩)가 최선이라고 생각했습니다.
그리고 비동기 작업의 프로세스를 따로 할당하기 위해 (CPU코어만큼의 자원을 따로 할당받기 위해)
비동기 서버만 따로 돌리는 배치 서버를 따로 분리하였고
거기서 스레드 풀을 늘리는 방법을 택했습니다
여러가지 방법들을 고안해보고, 직접 실행시간도 측정해보며 CS지식과 여러가지를 접목해보며 생각해 볼 수 있었던 재밌는 주제였던 것 같습니다.
(참고로 제가 할당받은 aws ec2 우분투 서버의 실질적으로 이용가능한 CPU 수는 1개더라구요.. t2 micro 기준 CPU core수는 1개입니다 (역시 무료는.. 1개였군요.. 제 mac은 10개인데 ㅎㅎ..)
그래서 어쩔 수 없이 프로세스 1개에 동시 작업해야 할 동시작업 수만큼 스레드의 concurrency pool을 설정을 했고, 해당 동시 작업들이 제 시간에 수행되도록 하였습니다!)
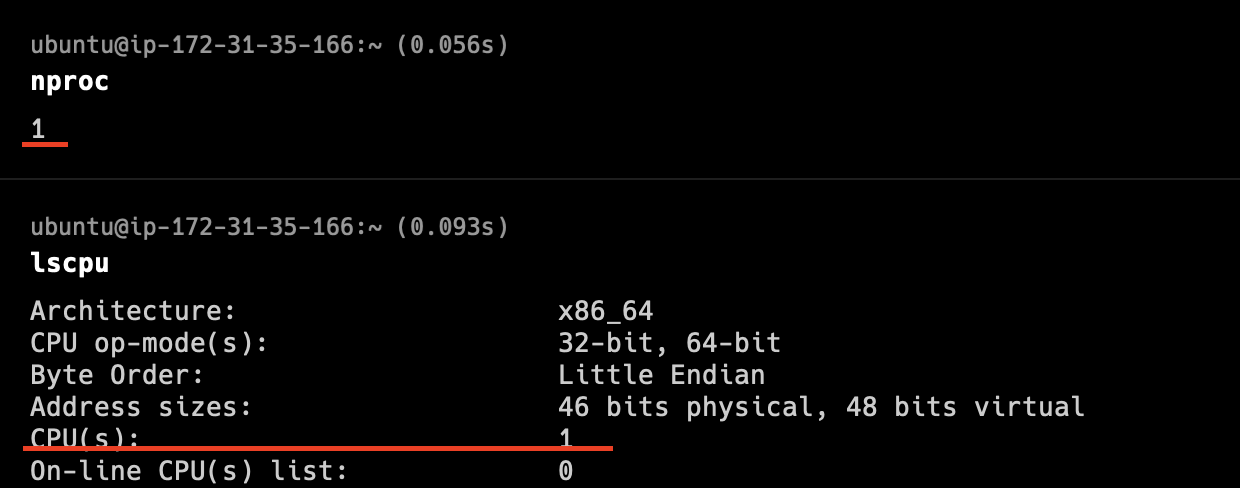
서버에서 nproc 명령어를 통해 실제 물리적인 CPU core의 개수를 확인할 수 있습니다
참고로 제 mac은 10개입니다 ㅎㅎ

그래서 처음에 default process concurrency 도 CPU core의 수=10 으로 할당된 것입니다

멋진 글 감사합니다!!