Section 01. 정적 라우팅 알고리즘
01. 라우팅 알고리즘의 개요
라우팅 알고리즘(routing algorithm): IP가 출발지에서 목적지까지 패킷을 전달하는 과정에서 라우터가 패킷을 어디로 보낼지 결정하는 알고리즘
- 정적 라우팅 알고리즘: 현재의 상태(실시간 상태 반영 X)에서 어떤 곳으로 패킷을 보내야 목적지에 도달하는지를 찾는 알고리즘
- 동적 라우팅 알고리즘: 실시간으로 라우터의 상태를 감지하여 경로를 변경하는 알고리즘

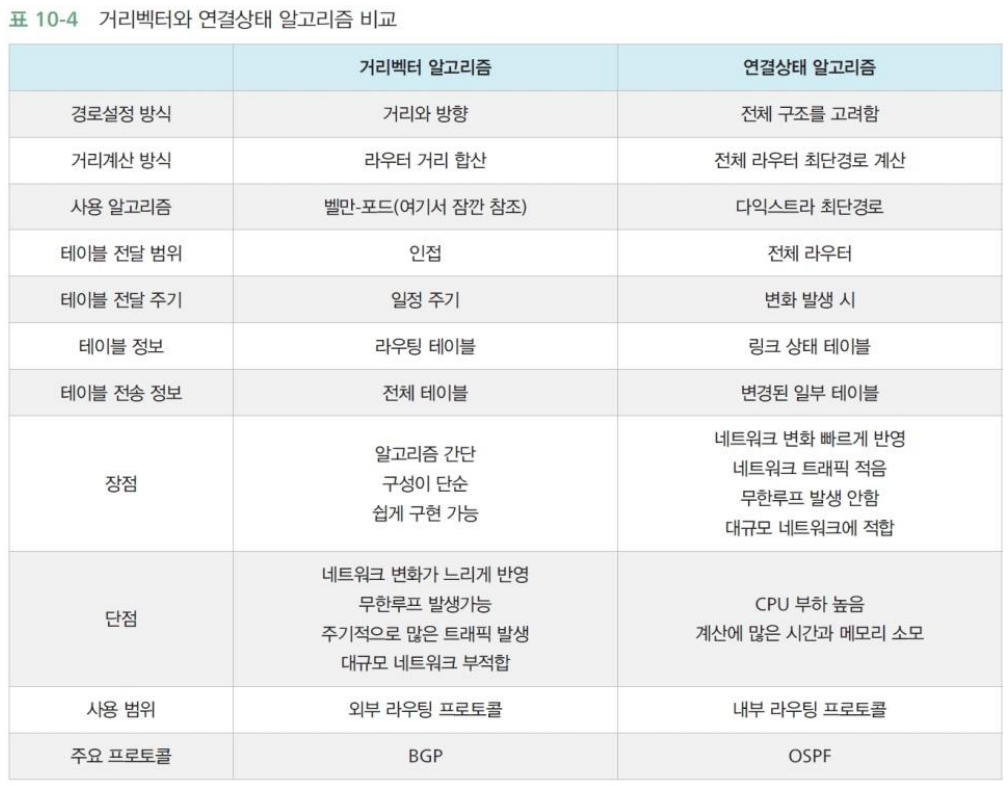
라우터들과 통신선의 연결을 그래프(graph)로 표현
- 그래프는 노드(node)와 선(edge)의 집합
- 노드: 라우터
- 선: 통신선
- 양방향 통신 → 방향 X
- 숫자는 전송하는데 걸리는 시간 혹은 거리(or 금액)을 의미 → 밀리초(msec)
라우팅 알고리즘의 가장 중요한 목적은 각 라우터로 가는 가장 빠른 경로를 찾는 것이다.
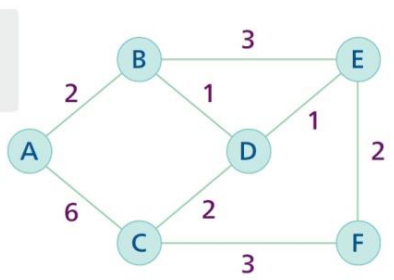
알고리즘이 최단 경로(최소 시간 경로)를 결정하면 결과는 트리(tree, 사이클이 없는 그래프)가 된다
02. 최단경로(shortest path) 알고리즘
최단경로(shortest path) 알고리즘: 대표적인 정적 라우팅 알고리즘으로 다익스트라 알고리즘이라고 한다.
- 집합 개념 사용
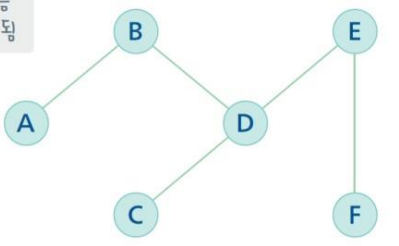
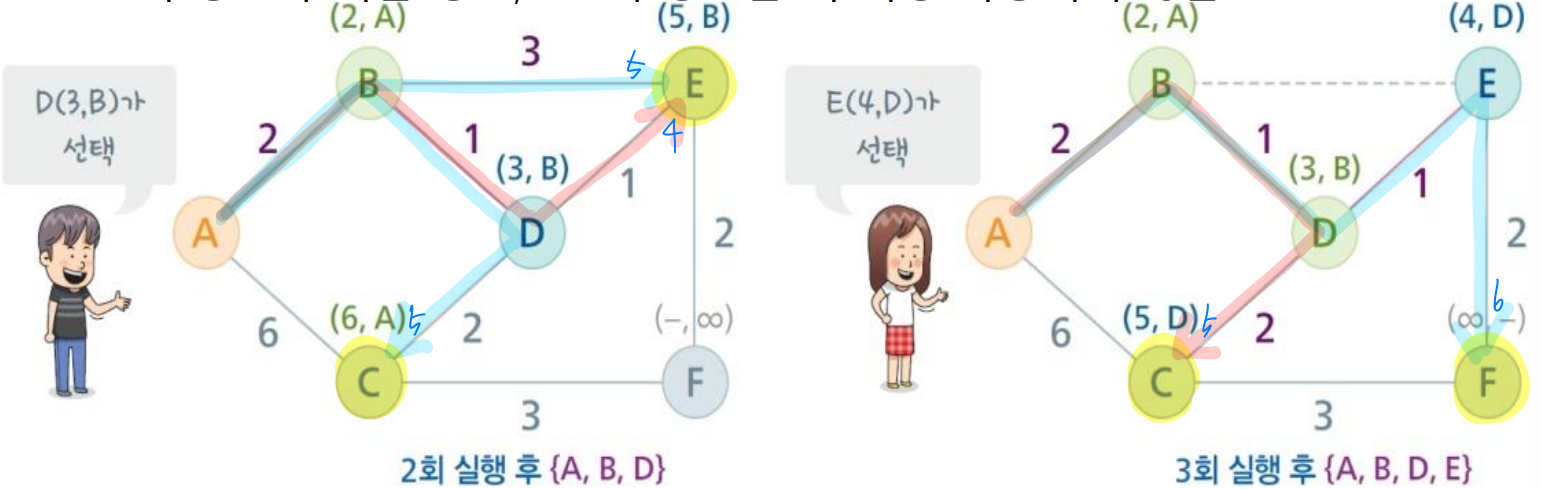
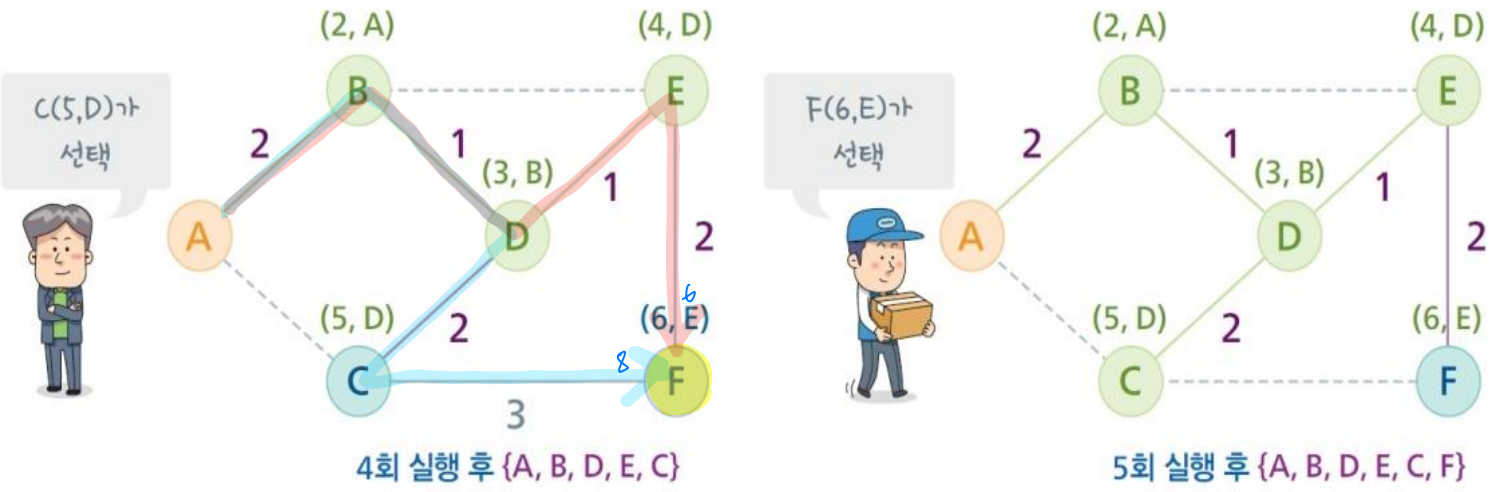
최단경로 알고리즘 기본 작동 방식
- 초기에 시작 노드(라우터)가 집합에 들어간다.
- 집합에 있는 모든 노드에서 바로 붙어있는 노드의 거리를 계산한다.
- 집합에 있는 노드를 제외하고 가장 작은 값을 가진(가까운) 노드를 선택하여 삽입한다.
- 모든 노드가 집합에 들어갈 때까지 반복한다.
-
각 노드들은 두 개의 초기값을 가진다. 출발 노드에서부터 해당 노트까지 도달하는데 걸리는 시간(msec)과 어디에서부터 오는 경로인지를 나타내는 경로정보가 저장된다.
→ (시간, 경로정보) → 초기값은 (∞, -)
-
모든 노드의 초기값이 만들어지면 출발 노드인 A를 집합에 넣고 최단경로 알고리즘을 반복한다.

03. 플러딩(flooding) 알고리즘
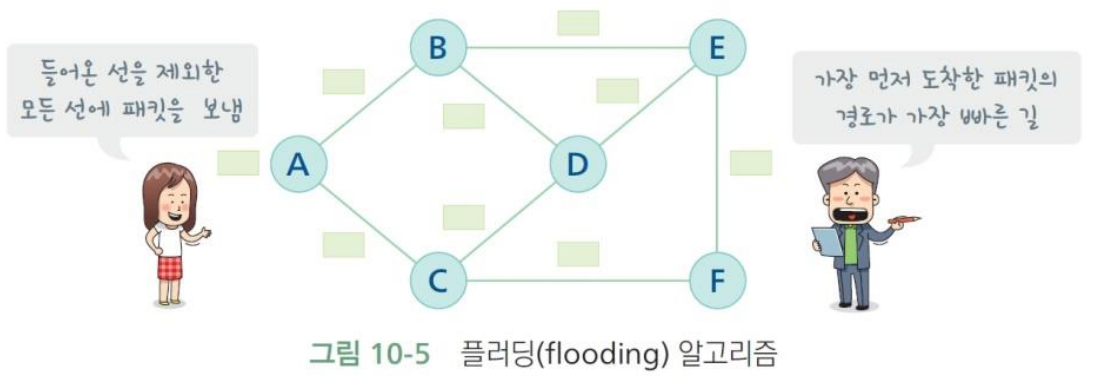
플러딩(flooding) 알고리즘: 네트워크에 홍수를 일으켜 가장 빠른 길을 찾는 정적 라우팅 방식
- 플러드(flood): 홍수
- 라우터들은 패킷에 들어온 선을 제외한 모든 선에 패킷을 복사하여 보낸다.
- 패킷에는 지나온 라우터들을 기록하고, 가장 먼저 도착한 패킷에 적혀 있는 경로를 가장 빠른 경로로 한다.
- 장점: 단순하여 구현하기 쉽다.
- 단점: 많은 패킷이 폭주하여 네트워크의 정체를 유발한다.
Section 02. 동적 라우팅 알고리즘
01. 거리벡터 라우팅(distance vector routing) 알고리즘
거리벡터 라우팅(distance vector routing) 알고리즘: 자신의 기준에서 다른 라우터까지 가는데 걸리는 시간이 명시된 라우팅 테이블을 주변 라우터와 공유하는 방식.
- 알파넷 개발 초기에 많이 사용하던 동적 알고리즘
- 라우터들은 주기적으로 라우팅 테이블을 주고 받는다.
- 자신만의 라우팅 테이블을 만들고, 이를 다시 주변 라우터에게 전송한다.
- 라우터까지의 거리에 대한 연속적인 값(벡터)
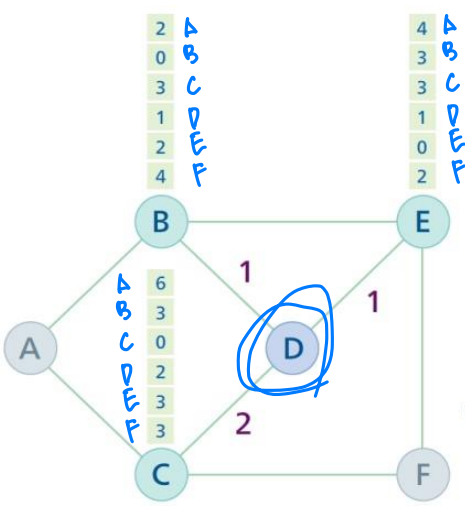
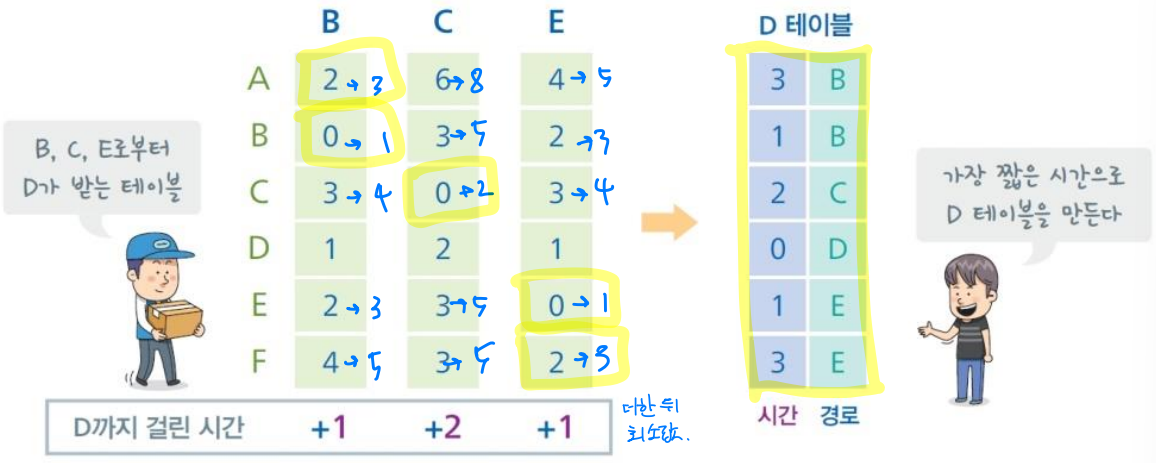
D의 라우팅 테이블 구성 과정 예시
- B, C, E는 주변 라우터까지 걸리는 시간을 명시한 라우팅 테이블을 갖고 있다. 이때 D는 인접한 B, C, E로부터 라우팅 테이블을 받아 자신만의 라우팅 테이블을 구성하게 된다.
- 받은 세 개의 라우팅 테이블의 값에 D까지 걸리는 시간을 더한 뒤, 라우터 별로 그 중 최소값을 가져와 D만의 라우팅 테이블을 구성한다.

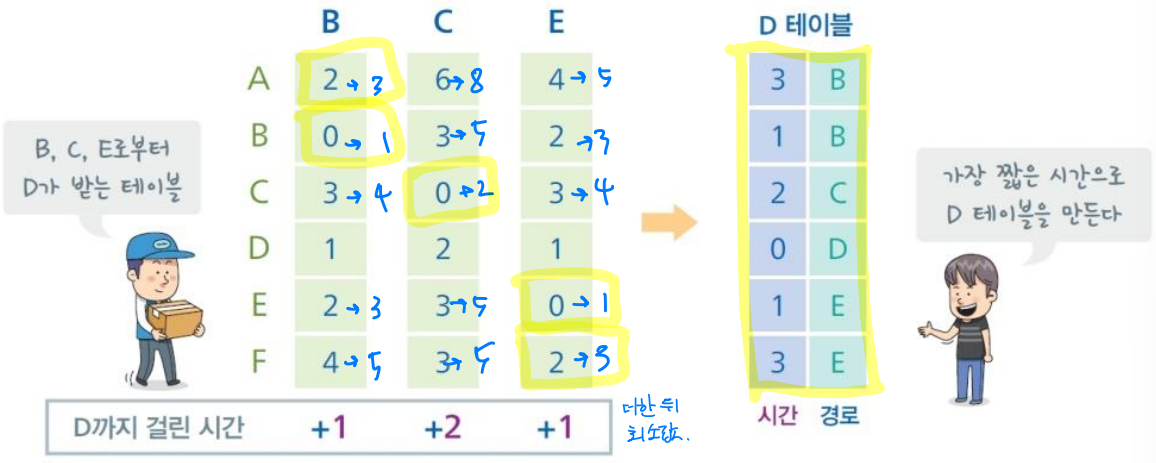
from A, to B, via C는 A에서 C를 거쳐 B까지 갈 때 걸리는 시간을 의미한다.
따라서 각 라우터는 인접한 라우터를 통한 다른 라우터까지의 거리를 파악하고, 그 중 가장 짧은 시간이 걸리는 경우를 라우팅 테이블로 기록한다.
02. 연결상태 라우팅(link state routing) 알고리즘
거리벡터 라우팅 알고리즘은 전체 라우터 구조를 알지 못하는 상태에서 모든 라우터에게 갈 수 있는 시간(거리벡터)을 주고받았기 때문에, 실시간으로 라우터의 상태를 반영하지 못한다는 문제가 발생한다.
→ 특정 라우터가 고장날 경우 무한루프, 무한 숫자세기 발생
연결상태 라우팅(link state routing) 알고리즘은 이러한 거리벡터 라우팅 알고리즘의 문제를 개선한다.
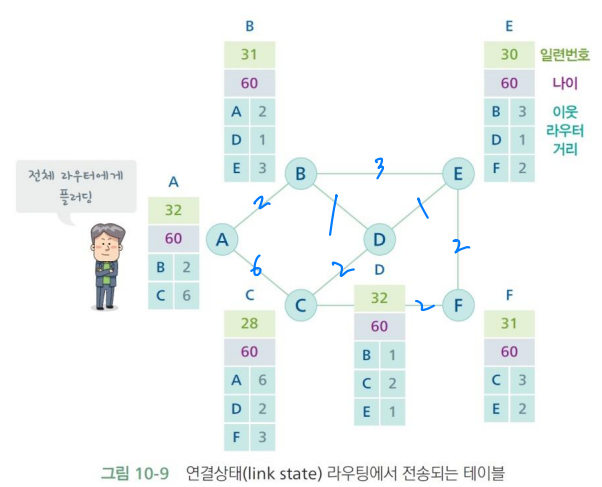
- 자신과 연결된 라우터 정보만을 보내고, 최단경로 알고리즘을 사용한다.
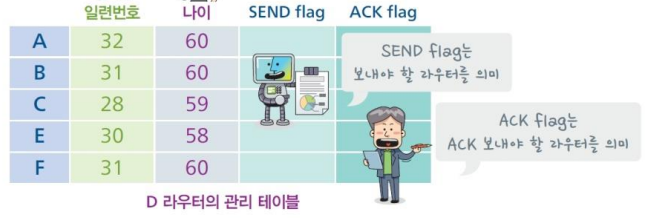
- 라우팅 테이블에 대한 일련번호(sequence number), 나이(age)를 추가하여 잘못된 정보가 도착하는 것을 막고, 특정 라우터가 고장나는 것을 확인할 수 있다.
- 일련번호는 최근에 받은 테이블의 일련번호를 의미하여 늦게 도착한 일련번호 테이블은 폐기한다.
- 나이는 일종의 타이머로, 다음 테이블의 도착 예정 시간이다. 패킷이 도착한 후 나이가 계속 줄어들고 0이 될 때까지 다음 테이블이 도착하지 않으면 라우터가 고장난 것으로 판단하고, 일련번호도 0으로 만든다.
연결상태 라우팅(link state routing) 알고리즘 기본 작동 방식
인접한 라우터(이웃 라우터)들을 파악한다.
라우팅 테이블을 주기적으로 모든 라우터에게 보낸다. → 플러딩
최단경로 알고리즘을 사용하여 라우팅 테이블을 만든다.
- 모든 라우터들에 대한 정보가 모이면 각 라우터에 대한 최단경로를 구한다.
라우터 구조와 라우팅 테이블 값을 지속적으로 업데이트한다.
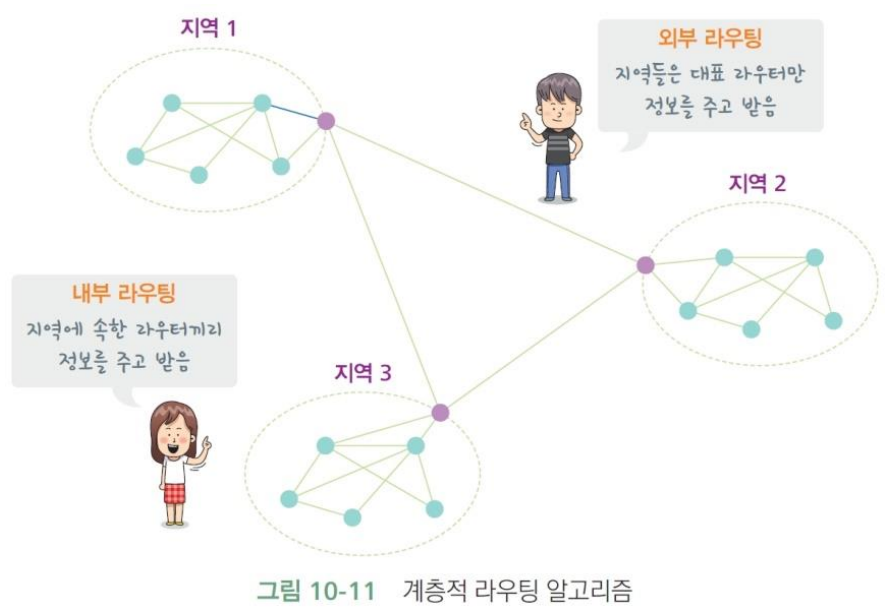
03. 계층적 라우팅(hierarchical routing)
계층적 라우팅(hierarchical routing): 라우터는 계층 구조를 갖는다는 점을 통해 일정한 지역을 하나씩 묶어 대표 라우터를 선정하고, 지역끼리 패킷을 주고 받을 때는 대표 라우터끼리 통신한다.
지역 안에 속한 라우터들은 내부 라우터라고 부르고, 지역끼리 통신하는 라우터를 외부 라우터라고 부른다.
내부 라우터는 목적지까지 가장 빠르게 패킷을 전송할 수 있도록 라우팅 테이블을 유지하고, 외부 라우터는 도달 가능성을 확인하는 것이 가장 중요한 목표이다.
04. 거리벡터와 연결상태 라우팅 알고리즘 비교