조건부 확률
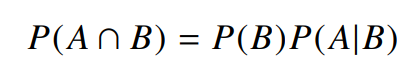
- 사건 가 일어난 상황에서 사건 가 발생할 확률
- = 조건, 상황
- = 영향을 미치는 새로운 사건
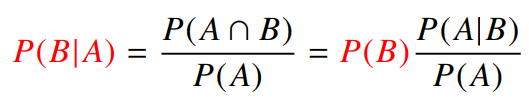
- 조건부확률을 통해 베이즈 정리는 정보를 갱신한다.
- 조건부 확률은 라는 새로운 정보가 주어졌을 때 로부터 를 계산하는 방법을 제공한다.
베이즈 정리

-
사전확률과 사후확률 사이의 관계를 나타내는 정리
-
새로운 정보를 토대로 어떤 사건이 발생했다는 주장에 대한 신뢰도(사전 확률)를 갱신해 나가는 방법(a method to update belief on the basis of new information)
-
용어 정리
-
사전 확률, 사후 확률
: evidence를 관측하여 갱신하기 전 후의 내 주장에 관한 신뢰도 -
- Hypothesis, 또는 모델링하는 이벤트, 또는 모델에서 계산하고 싶어하는 모수(parameter)
- 가설 혹은 어떤 사건이 발생했다는 주장
-
: 새로 관찰하는 데이터(즉, 새로운 정보) -
: Evidence -
- 사전확률(prior distribution)
- 모델링하고자 하는 타겟(모수 등)에 대해 데이터를 분석하기 전에 가정한 확률분포 (갱신하기 전의 신뢰도)
- 어떤 사건이 발생했다는 주장에 관한 신뢰도
-
- 사후확률(posterior probability)
- hypothesis가 성립할 확률
- 새로운 정보를 받은 후 갱신된 신뢰도
-
- 가능도(likelihood)
- 현재 주어진 [모수/가정]에서 데이터 가 관찰될 확률
-
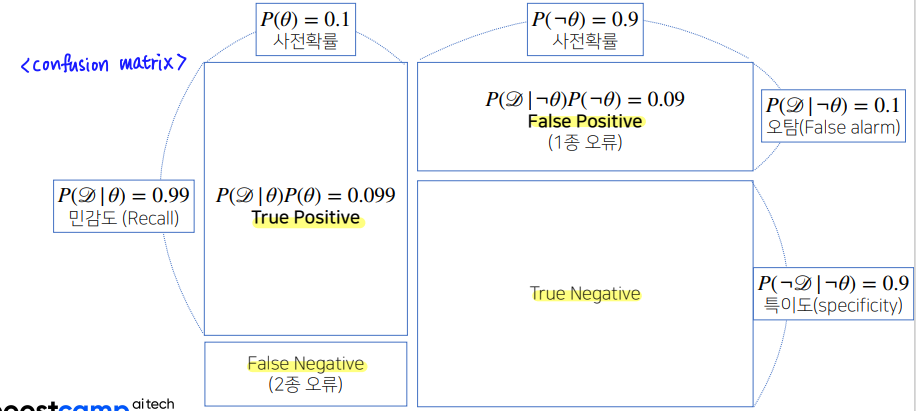
예제 : COVID-99




오탐율(False alarm)이 오르면 테스트의 정밀도(Precision)가 떨어진다.
- 오탐율 이 이 아닌 이라면, 정밀도는 이 아닌 가 된다.
이처럼 아무리 민감도()가 높더라도 오탐율이 높아지면 정밀도가 크게 떨어진다.

정보의 갱신


[ update ]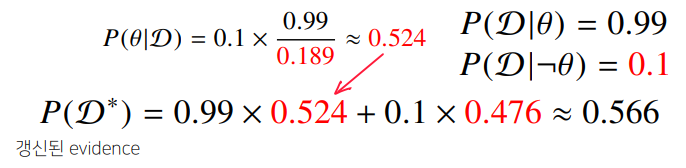
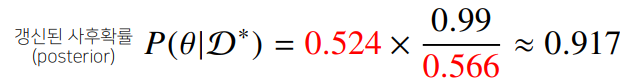
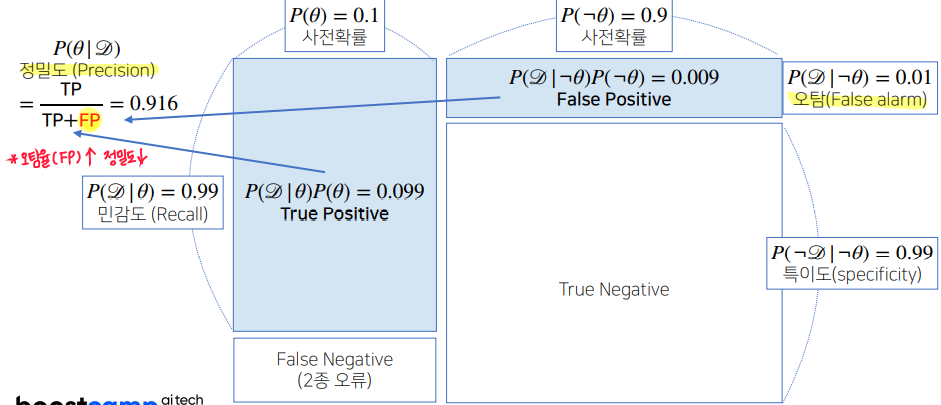
- 새로운 데이터에 의해 사후확률(COVID-99에 걸렸을 확률) 갱신 : ->
- 세번째 검사해도 양성이 나오면 정밀도가 까지 갱신된다.
- 정밀도()는 오탐율()과 민감도()에 영향을 받는다.
- 베이즈 정리는 데이터를 추가할 때마다 업데이트된 신뢰성을 얻을 수 있으므로 아주 유효한 방식이다.
이처럼 조건부 확률은 유용한 통계적 해석을 제공한다.
조건부 확률을 사용할 때 범하기 쉬운 오류가 있다. 조건부 확률이 인과관계로 이어진다고 생각하는 오류이다.
조건부 확률은 유용한 통계적 해석을 제공하지만, 인과관계(Causality)를 추론할 때 함부로 사용해서는 안된다. 데이터가 아무리 많아져도 조건부 확률만을 가지고 인과관계를 추론하는 것은 불가능하다.
인과 관계(casuality)

데이터 분포의 상황이 바뀌는 경우(새로운 정책 및 치료법등을 도입)가 있다.
이 경우 조건부 확률만을 가지고 예측 모형을 만들었을 때, 시나리오에 따라 예측정확도의 변동성이 크다. 이에 비해 인과관계 기반 예측모형은 시나리오가 변한다고 하더라도 정확도가 크게 변하지 않는다. 다만, 인과관계만 고려해서는 높은 예측 정확도를 담보하기 어렵다.
중첩 요인 제거
인과관계를 알아내기 위해서는, 중첩요인(confounding factor) 의 효과를 제거하고 원인에 해당하는 변수 만의 인과관계를 계산해야 한다.
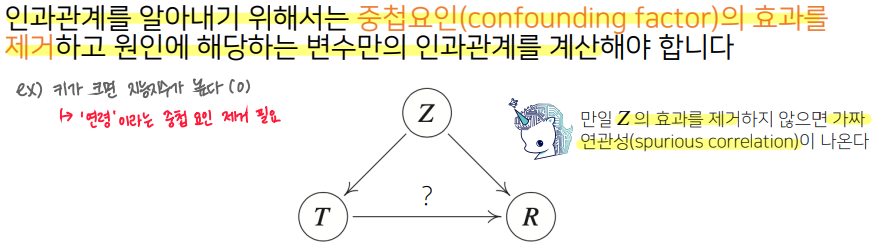
예제 : 치료법에 따른 완치율
신장결석에 대한 치료법이 a와 b가 있다. 두 치료법을 따랐을 때, 신장결석 크기에 따른 완치율 통계 결과가 다음과 같이 나와있다면, 어떤 치료법을 고르는 것이 더 나을까?
 전체적인 치료법의 성공률(overall)을 보면 b가 더 나아 보인다.
전체적인 치료법의 성공률(overall)을 보면 b가 더 나아 보인다.
그러나 실제로는 신장결석 여부와 관계없이 각각의 환자군에서 a가 모두 성공률이 더 높다.
이러한 결과가 나온 것은 신장 결석 크기에 따른 중첩효과를 제거하지 않았기 때문이다.
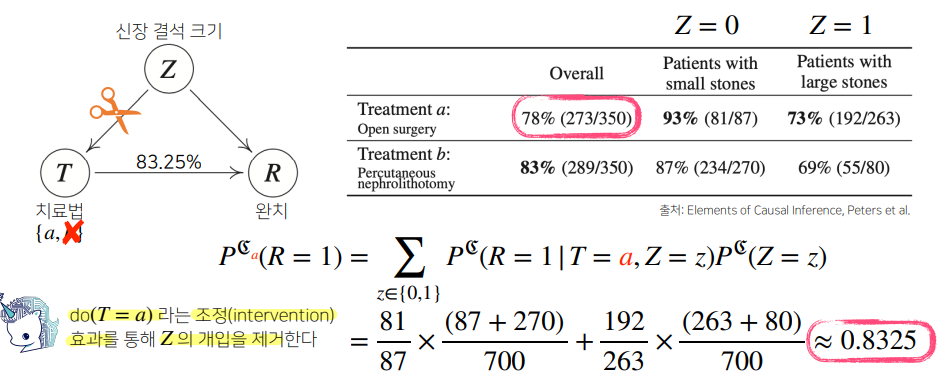
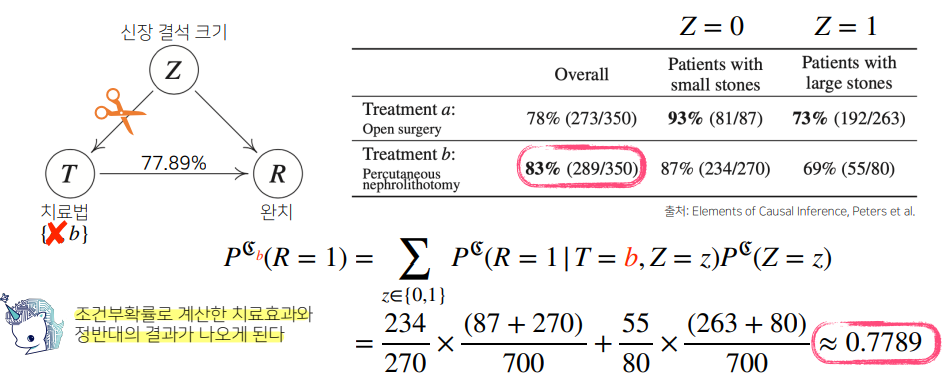
조정(intervention)과정을 통해 중첩효과 의 개입을 제거하여, 신장결석 크기와 관계없이 치료법 a와 b를 선택했을때의 완치율을 알 수 있다. 이는 조건부 확률을 사용하는 베이즈 정리와는 달리, 인과관계로 예측하는 것이다.
제거하고 나면, 치료법 a는 약 0.83, 치료법 b는 약 0.78로 치료법 a를 선택하는 것이 더 나은 방법이라는 것을 확인할 수 있다.
이처럼 중첩효과를 제거함으로써 데이터 분석 시에 좀 더 안정적인 정책 분석이나 예측모형의 설계가 가능하다.
따라서 단순히 조건부확률만으로 데이터 분석을 하는 것은 위험하고, 데이터에서 추론할 수 있는 사실 관계들이나 변수들끼리의 관계, 도메인 지식 등을 활용함으로써 강건한 데이터모형을 만들 수 있다.
