데이터를 해석하는 가장 간단한 방법은 선형모델이다. 하지만 선형 모델만으론 복잡한 데이터를 해석하기 어려운 경우가 많다.
따라서 비선형적인 방법을 이용해서, 더 다양하고 정교한 분석을 하곤 한다.
그 대표적인 방법이 신경망 이론이다. 이는 흔히 딥러닝이라고 불리는 가장 기본적인 방법이다.
신경망(neural network)
- 신경망 : 선형 모델과 활성함수(비선형 함수)를 합성한 함수
- 선형 수식에 비선형함수를 곱해서(행렬 곱셈), 비선형으로 바꿔주는 것
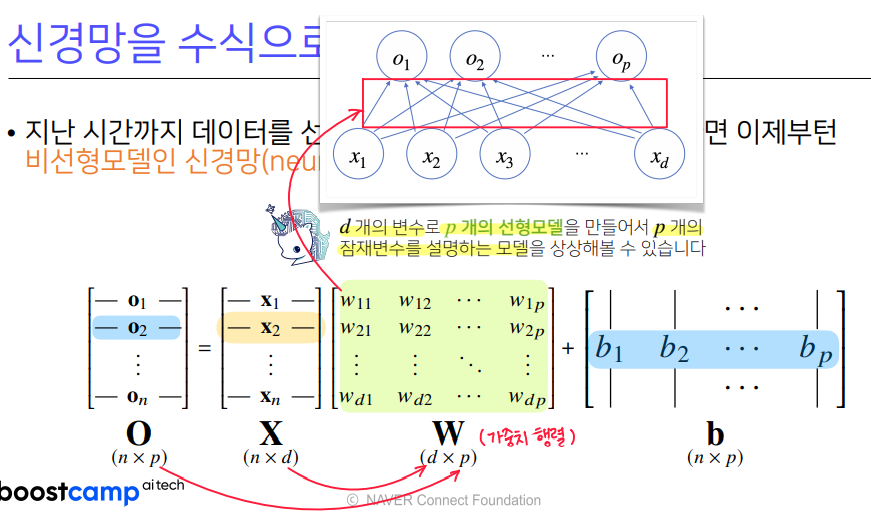
- 선형 모델 수식 :
- (n x d) : 입력 벡터 (수집한 데이터 그 자체)
- (d x p) : 가중치 행렬 (연산자 : 데이터를 다른 벡터 공간으로 보내줌. 결과로 바꿔줌)
- (n x p) : 편향
- (n x p) : 출력 벡터
- 입력 크기(n x d) != 출력 크기(n x p) - d개의 변수로 p개의 선형모델을 만들어 p개의 잠재변수를 설명하는 모델
- d가지 종류의 데이터로 p가지 종류의 정보를 얻을 수 있다.
활성함수
- 위에 정의된 비선형(nonlinear) 함수
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다.
- 딥러닝에서는 ReLU함수가 많이 쓰인다.
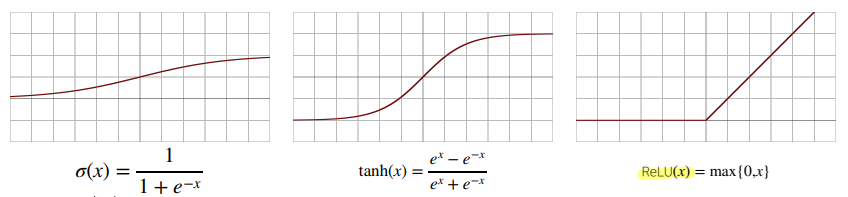 전통적으로 많이 사용하는 활성함수였던 Sigmoid와 tanh의 경우 -1~1의 값을 가지고 있다. 이로 인해 반복적으로 곱해줄 경우 값이 0에 수렴하게 된다. 즉 값이 너무 작아져서 제대로된 기능을 할 수 없게된다(기울기 소실). 이에 대안으로 고안된 함수가 ReLU이다.
전통적으로 많이 사용하는 활성함수였던 Sigmoid와 tanh의 경우 -1~1의 값을 가지고 있다. 이로 인해 반복적으로 곱해줄 경우 값이 0에 수렴하게 된다. 즉 값이 너무 작아져서 제대로된 기능을 할 수 없게된다(기울기 소실). 이에 대안으로 고안된 함수가 ReLU이다.
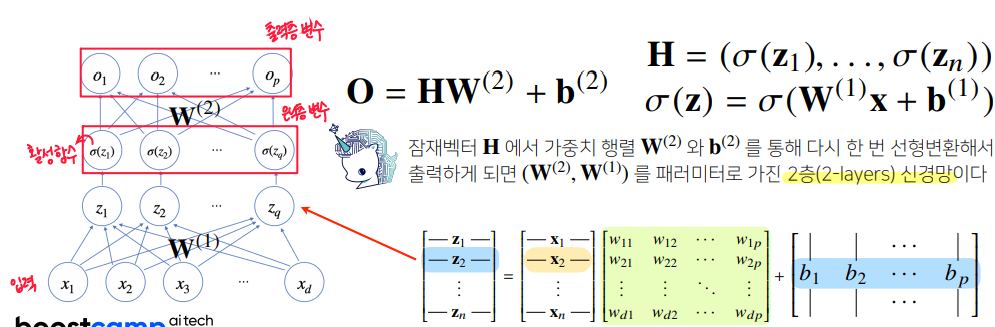
- 활성함수()는 비선형 함수로 선형모델로 계산한 결과인 잠재벡터()의 각 노드에 개별적으로 적용하여 새로운 잠재벡터()를 만든다.

- 신경망은 선형모델과 활성함수(activation function)를 합성한 함수이다.
softmax
- 위 수식들을 통해 구한 결과를 해석할 때,모델의 출력을 확률로 해석할 수 있게 변환해주는 함수
- 분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합해 예측한다.
- 벡터가 특정 클래스에 속할 가능성을 계산하는데 사용

- 그러나 추론을 할 때는 원-핫(one-hot) 벡터 사용

❓ 분류 문제에서 softmax 함수가 사용되는 이유
- 분류 모델에서 라벨은 one-hot encoding 형태로 [0, 1, 0, 0]으로 표현된다.
- 이는 단순히 1번째 라벨값이다가 아닌 "이 데이터의 라벨은 1번째 라벨일 확률이 1이다"라고 해석할 수 있는 것
- 이것과 비교를 하려면 예측값도 확률로 해석이 되어야하기 때문에 softmax를 써서 확률로 바꿔줘야 한다
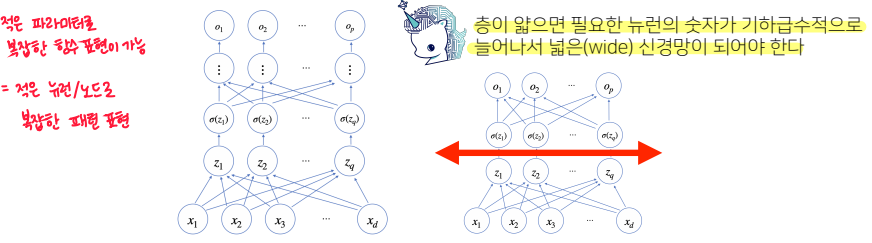
다층 퍼셉트론(MLP, Multi-Layter Perceptron)
- 신경망이 여러층 합성된 함수
- 신경망을 계산한 결과(선형분석 -> 활성함수)에 다시 선형함수를 적용하고, 활성함수를 적용하는 것
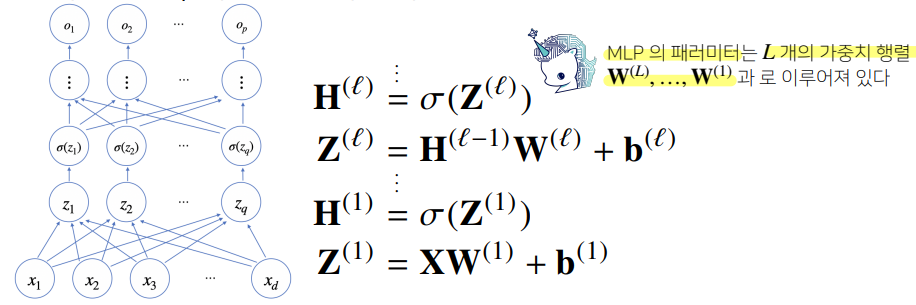
- 신경망을 계산한 결과(선형분석 -> 활성함수)에 다시 선형함수를 적용하고, 활성함수를 적용하는 것
- 층을 여러개 쌓는 이유
- 목적 함수()를 근사할 땐 노드가 많아야 정확한 결과가 나오지만 만약 이 노드들을 2층으로만 모두 구현할 경우(universal approximation theorem), 속도가 느리고 효율이 떨어지게 된다.
- MLP로 층을 깊게해서, 층별 노드의 숫자를 크게 줄이면 속도가 훨씬 빨라진다. 같은 기능을 구현할 때의 노드 숫자도 크게 줄어든다. 따라서 일반적으로 2층 신경망보다 효율적이다.
딥러닝 학습원리 : 역전파(Backpropagation) 알고리즘
지금까지의 내용은 입력으로부터 출력을 계산하는 과정으로 순전파이다.
순전파 (Forward Propagation)
- 뉴럴 네트워크 모델의 입력층부터 출력층까지 순서대로 변수들을 계산하고 저장하는 것
- 뉴럴 네트워크의 그래프를 계산하기 위해서 중간 변수들을 순서대로 계산하고 저장한다. 즉, 입력층부터 시작해서 출력층까지 처리한다.
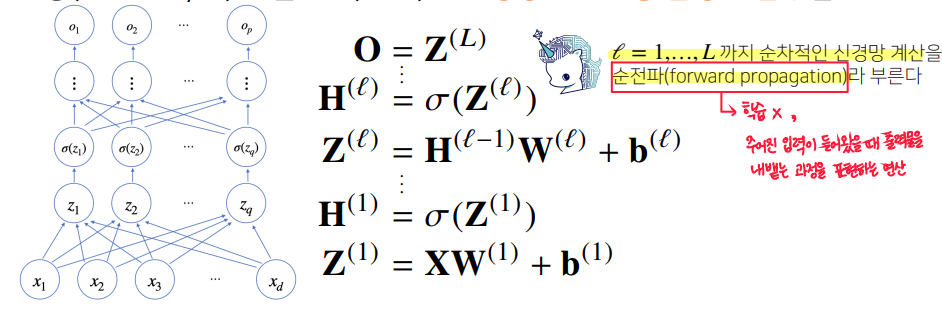
- 순전파의 연산 그래프
이제 이 식을 개선시키기 위해선, 이 식으로 계산한 결과와 실제 데이터의 차이를 줄여야 한다. 즉, 손실함수(loss function)를 최소화하는 가중치행렬을 찾아야 한다.
손실함수(L)를 최소화하기 위해선 경사하강법을 사용할 수 있고 이를 이용하기 위해선 손실함수에 대한 미분값()을 계산해야 한다.
이때 여러 층으로 구성된 복잡한 신경망을 미분하기 위해서, chain rule을 적용한 학습 방법 알고리즘인 역전파(Backpropagation) 알고리즘을 사용한다.
역전파(Backpropagation)


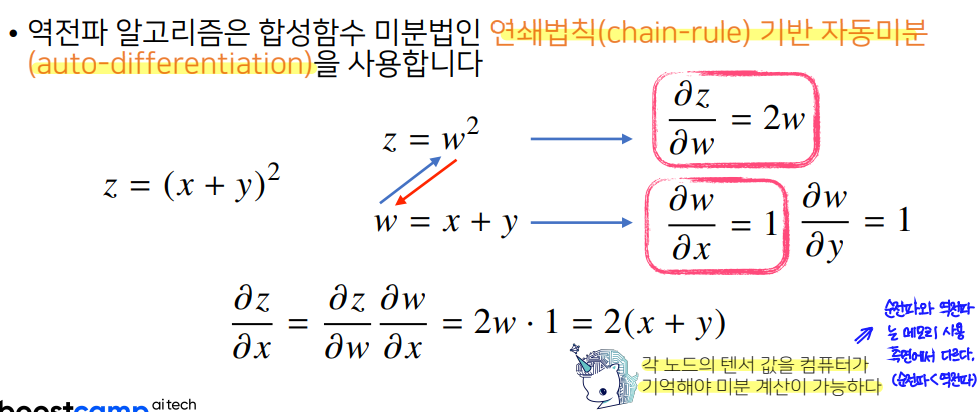

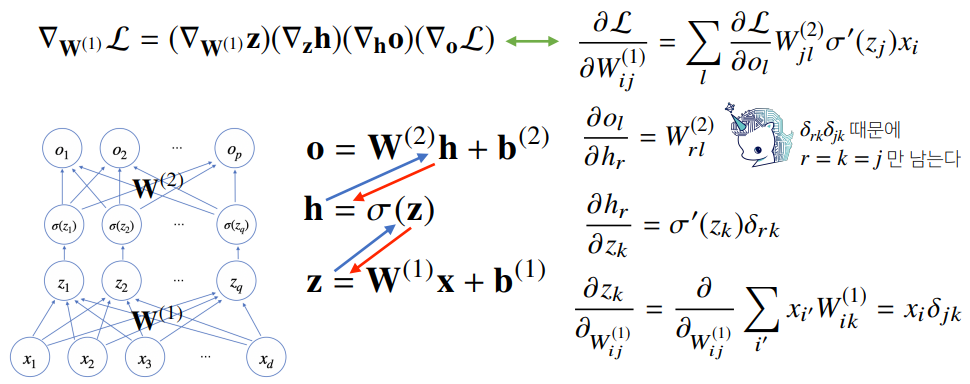
-
MLP는 일종의 합성함수로 합성함수 미분법인 연쇄법칙(chain rule)을 통해 미분할 수 있다.
-
역전파는 체인룰(chain rule)을 적용해 뉴럴 네트워크의 각 층과 관련된 목적 함수()의 중간 변수와 파라미터에 대한 그래디언트(gradient)를 출력층에서 입력층 순으로 계산하고 저장하는 방법이다.
- 함수 와 를 정의했다고 가정하고, 체인룰(chain rule)을 사용하면, X 에 대한 Z 의 미분은 다음과 같이 정의됩니다.
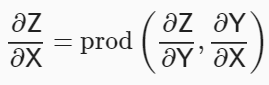
- prod 연산은 전치(transposotion)나 입력 위치 변경과 같이 필요한 연산을 수항한 후 곱을 수행하는 것을 의미
- 함수 와 를 정의했다고 가정하고, 체인룰(chain rule)을 사용하면, X 에 대한 Z 의 미분은 다음과 같이 정의됩니다.
-
하나의 은닉층(hidden layer)를 갖는 간단한 네트워크의 파라미터는 와 이고, 역전파(back propagation)는 미분값 와 를 계산하는 것
-
요약 과정
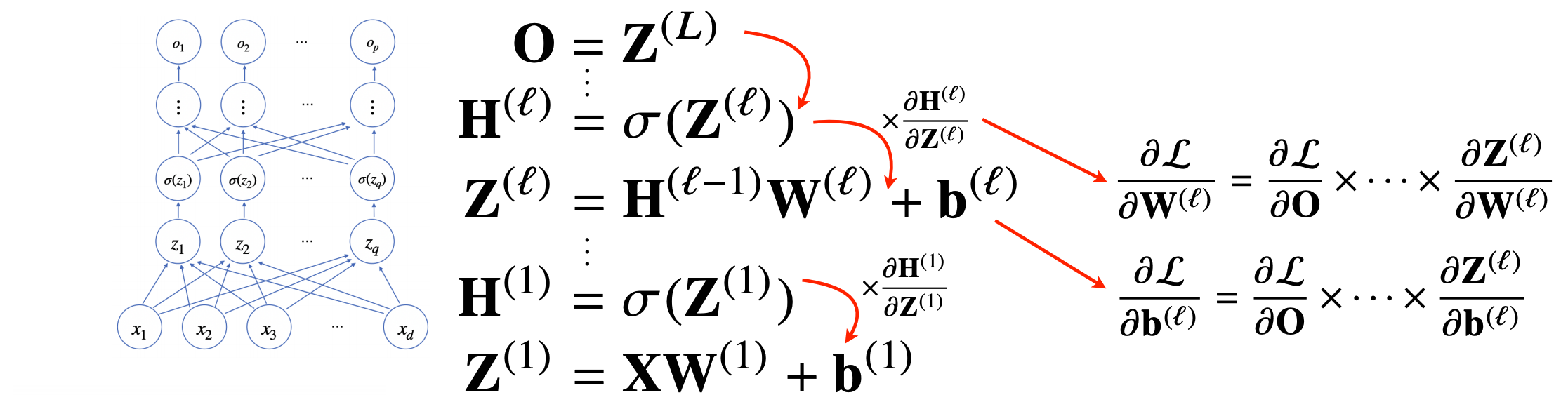
- 최종 결과물 (n층)을 그 아래층(n-1)으로 미분해서, n-1층의 가중치(W)를 업데이트한다. 그리고 해당 미분한 값은 아래 층으로 전달한다.
- 최종 결과물(n)을 n-2층으로 미분한 결과물은, (n-1층에서 전달받은 미분 값) * (n-1 층을 n-2로 미분한 값)으로 계산할 수 있다. 이를 통해 n-2층의 가중치를 업데이트 한다.
... - 최종 결과물(n)을 입력(1층)으로 미분한 결과물은, (2층에서 전달받은 미분 값) * (2층을 1층(입력)으로 미분한 값)으로 계산할 수 있다. 이를 통해 1층(입력)의 가중치를 업데이트 한다.
- 자세한 과정
- 손실(loss) 항목 과 정규화(regularization) 항목 에 대해서
목적 함수(objective function) 의 그래디언트(gradient)를 계산
- 출력층 의 변수들에 대한 목적 함수()의 그래디언트(gradient)를
체인룰(chain rule)을 적용해서 구합니다.- 두 파라미터에 대해서 정규화(regularization) 항목의 그래디언트(gradient)를 계산
- 출력층과 가장 가까운 모델 파라미터들에 대해서
목적 함수()의 그래디언트(gradient) 계산- 출력층-은닉층 : 은닉층(hidden layer) 변수()에 대한 그래디언트(gradient)
- 활성화 함수(activation function) 는 각 요소별로 적용되기 때문에,
중간 변수 에 대한 그래디언트(gradient)를 계산하기 위해서는
요소별 곱하기(element-wise multiplication) 연산자()를 사용- 입력층과 가장 가까운 모델 파라미터에 대한 그래디언트(gradient) 계산
- 모델 학습
- 순전파와 역전파는 서로 의존하는 관계
- 순전파 : 연관되는 관계를 따라서 그래프를 계산하고, 그 경로의 모든 변수를 계산
- 역전파 : 순전파에서 계산한 모든 변수는 역전파에서 다시 사용되는데 역전파는 완료할 때까지 중간 값들을 모두 가지고 있어야 하며 이 때문에 역전파가 단순 예측을 수행할 때보다 훨씬 더 많은 메모리를 사용하는 이유들 중 하나이다.
- 즉, 체인룰(chain rule)을 적용하기 위해서 모든 중간 변수를 저장하고 있어야, 그래디언트(gradient)인 텐서(tensor)들을 계산할 수 있다.
- 메모리를 더 많이 사용하는 다른 이유는 모델을 학습 시킬 때 미니 배치 형태로 하기 때문에, 더 많은 중간 활성화(activation)들을 저장해야하는 것이 있다.
- => 딥러닝 모델을 학습시킬 때, 순전파(forward propagation)와 역전파(back propagation)는 상호 의존적이며
=> 학습은 상당히 많은 메모리와 저장 공간을 요구한다.
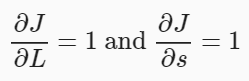
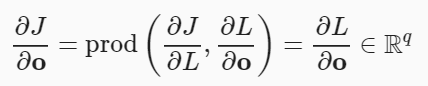
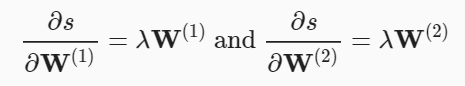
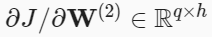
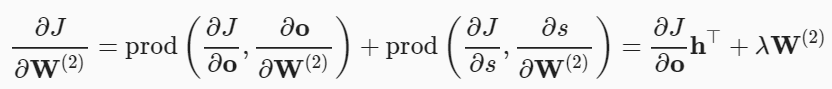
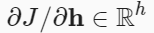
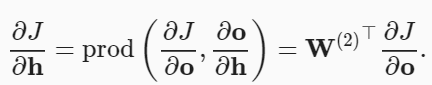
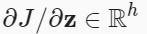
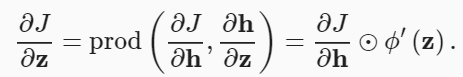
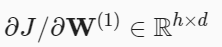
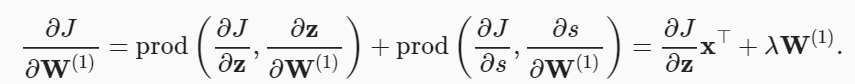
-
딥러닝 학습 : 계산한 각각의 가중치 벡터를 sgd와 같은 옵티마이저를 통해 미니배치로 학습을 진행하고 여러번의 학습을 통해 주어진 목적식을 최소화하는 파라미터들을 찾을 수 있고 그 원리가 오늘날 사용하는 딥러닝의 학습원리이다.
-
역전파의 핵심 원리 : 연쇄법칙의 활성원리
-
딥러닝 = 선형모델 + 활성함수의 여러층에 대한 합성함수
- 합성함수이므로 gradient를 계산하기 위해서는 연쇄법칙 chain rule이 필요
- chain rule을 적용한 학습 방법 알고리즘 = 역전파
📚 reference
