[Python Basics for AI] Pandas I

Pandas

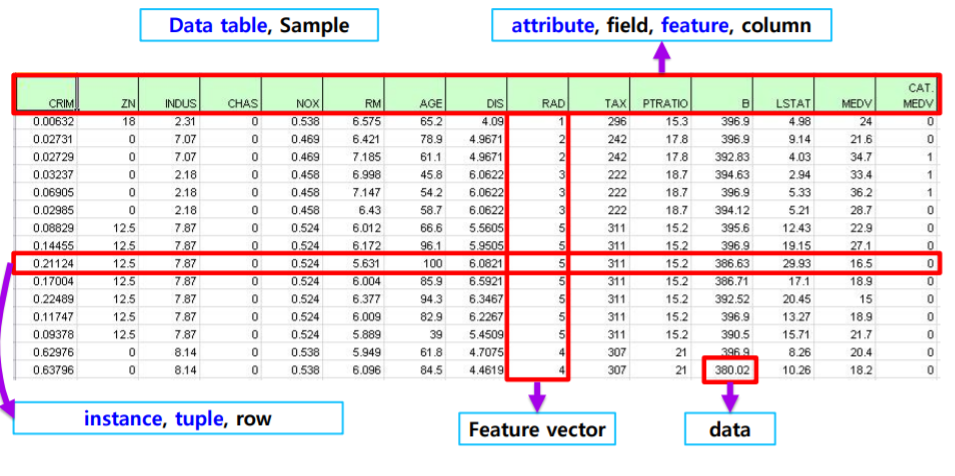

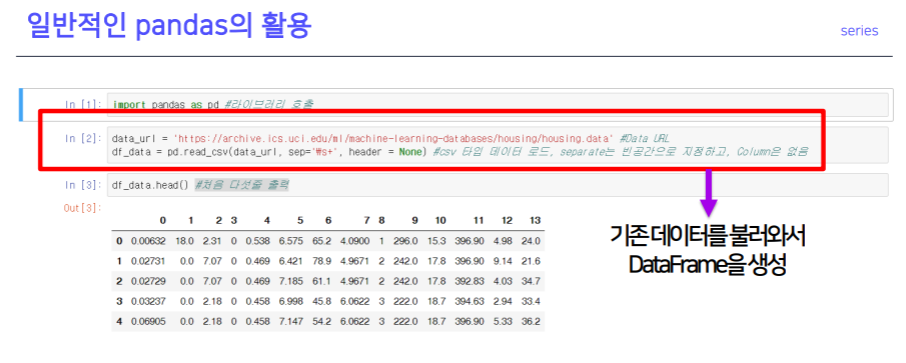
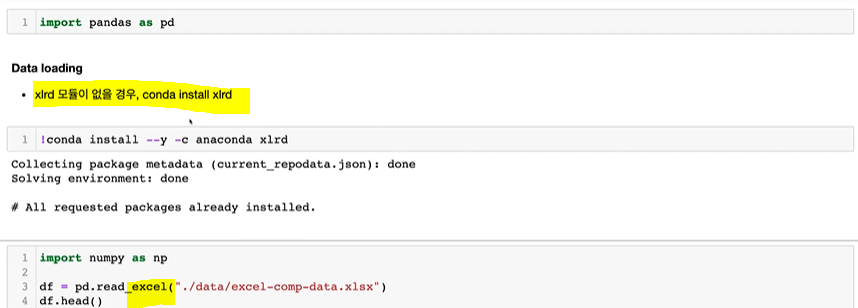
데이터 로딩
import pandas as pd : 라이브러리 호출pd.read_csv() : csv타입 데이터 로드df.head() : 처음 다섯줄 출력 (미리보기 느낌)df.columns = [~] : Column header 이름 지정
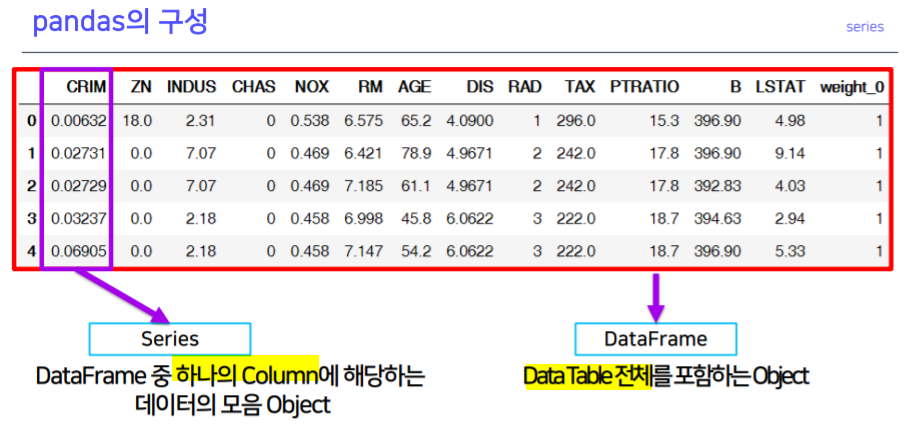
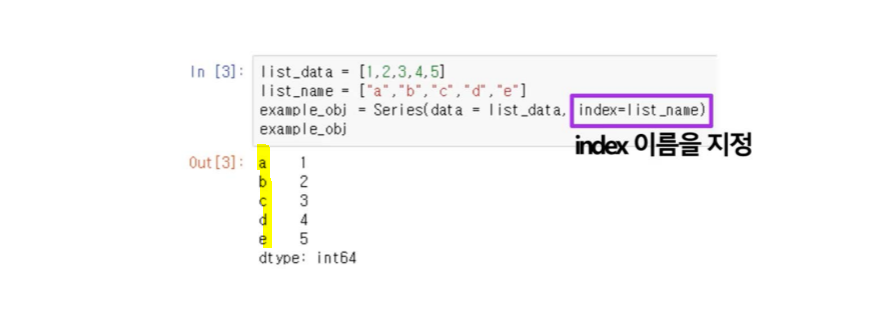
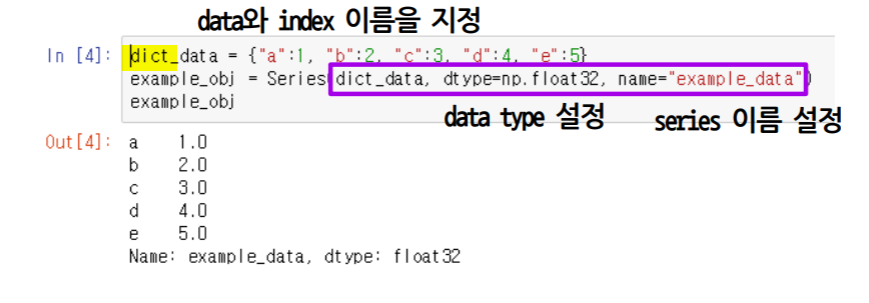
series
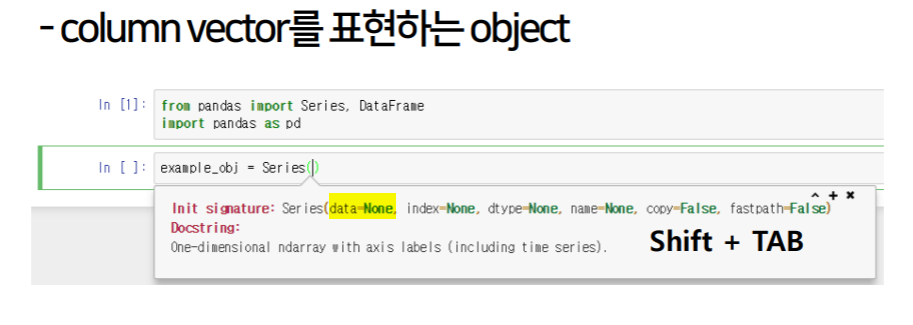
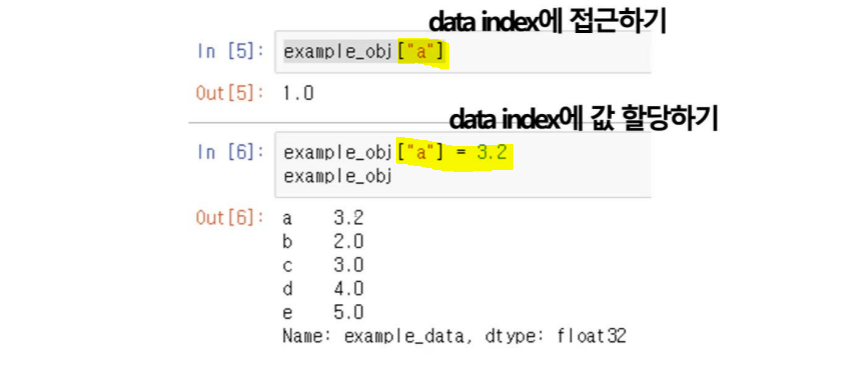
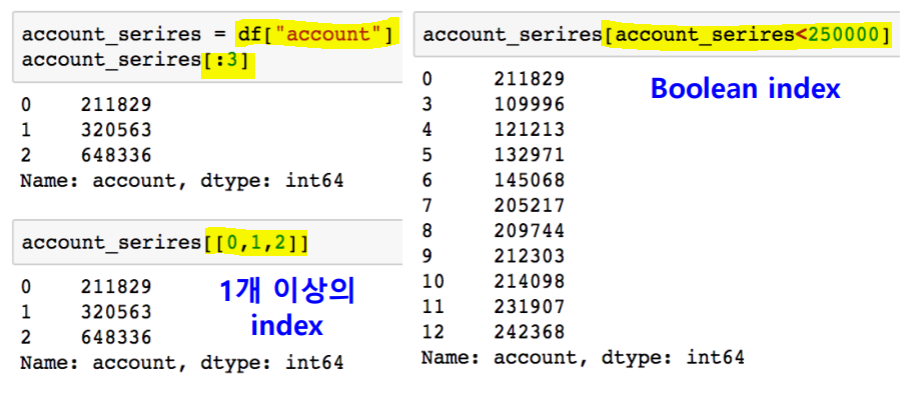
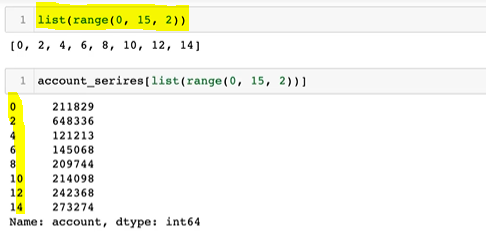
indexing





dataframe
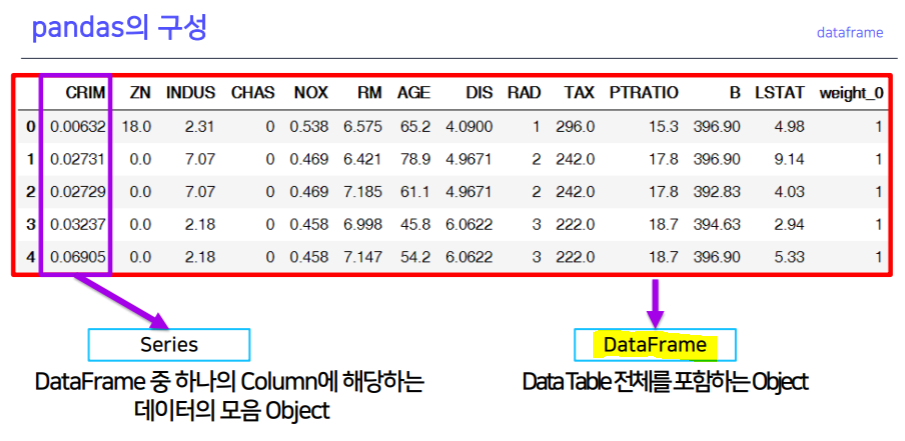


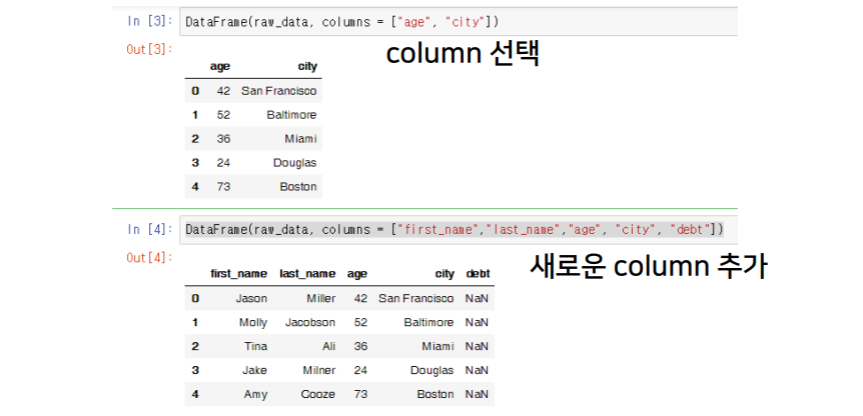
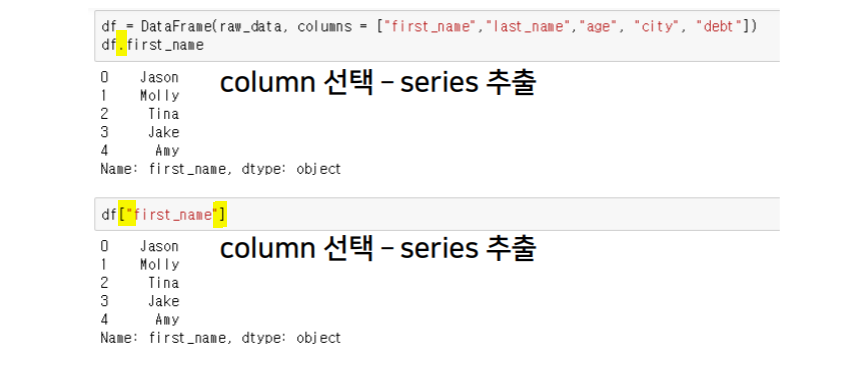
dataframe 생성

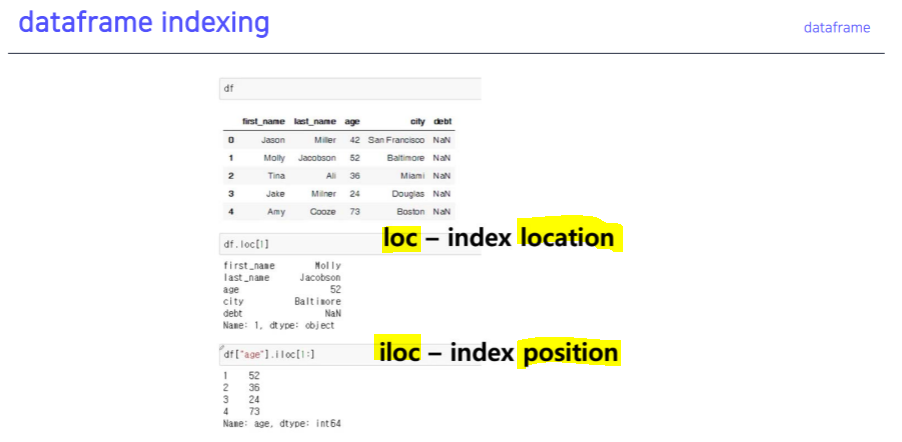
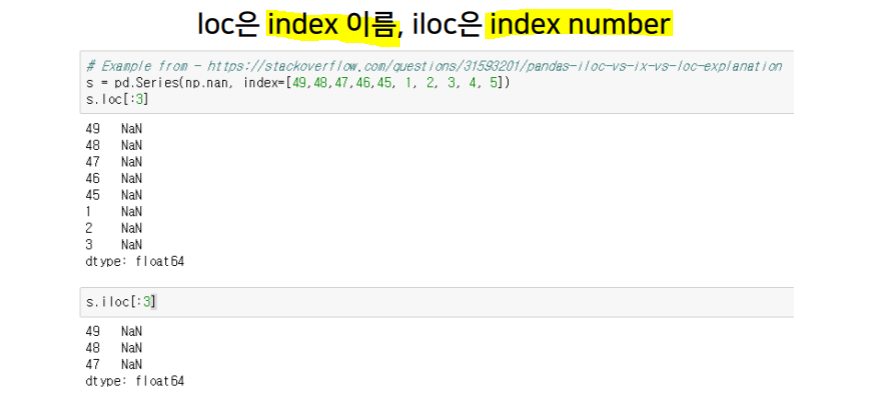
dataframe indexing
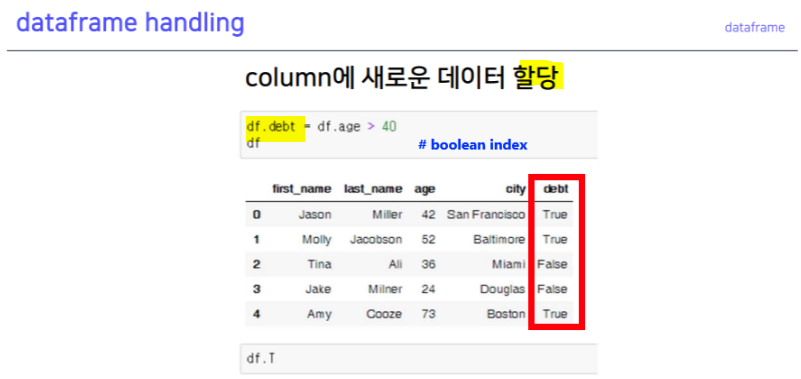
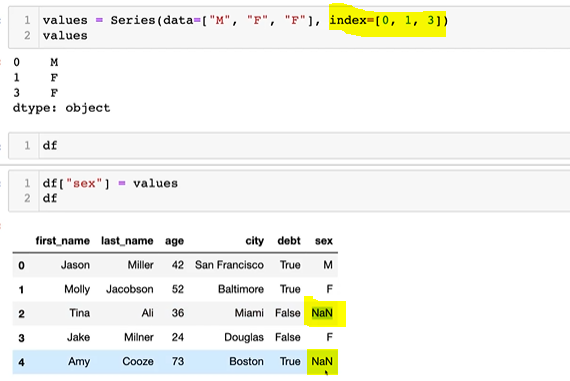
dataframe handling

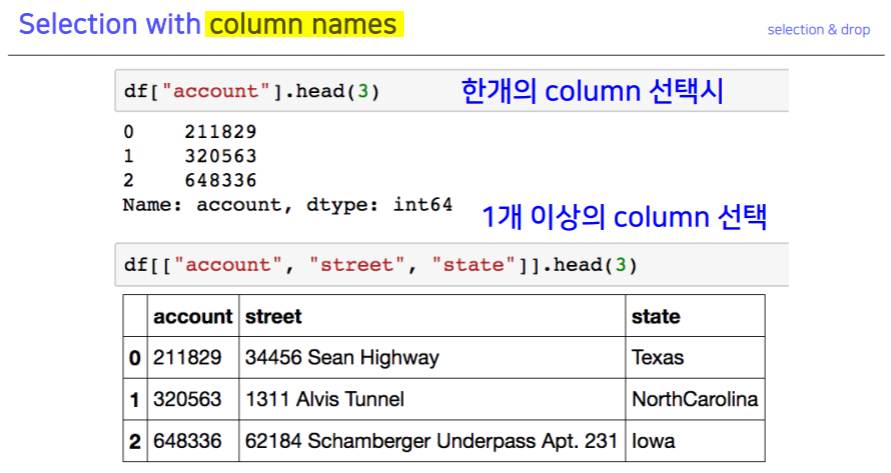
Selection & Drop
selection

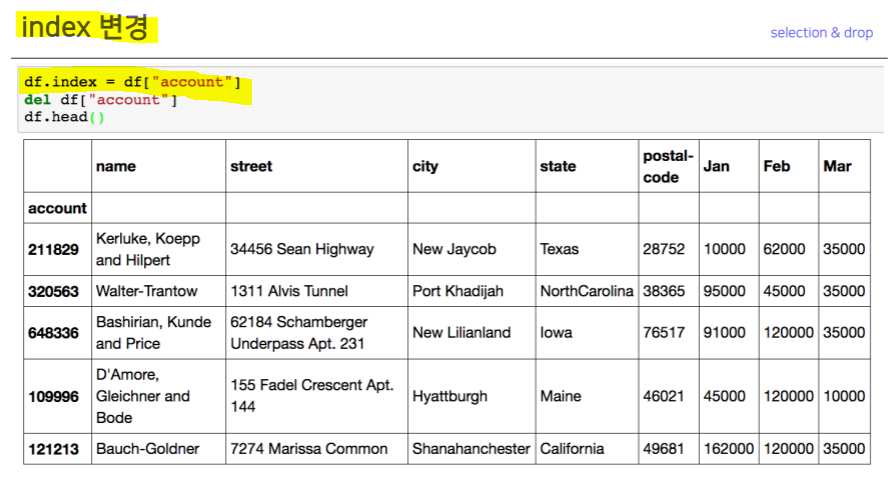

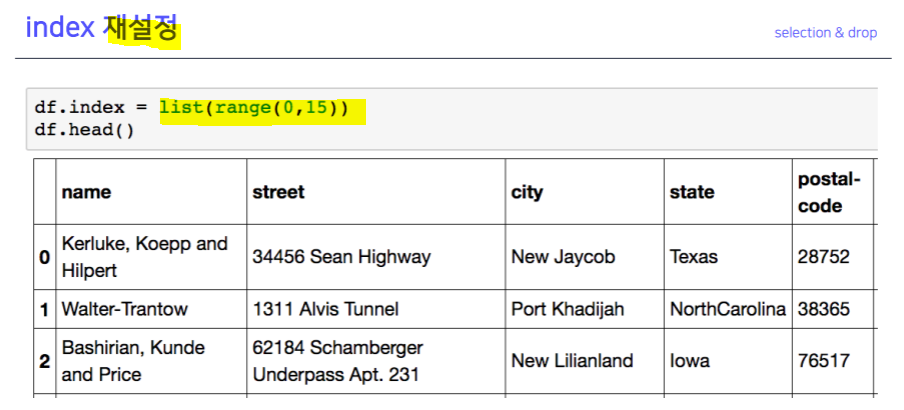
index 설정

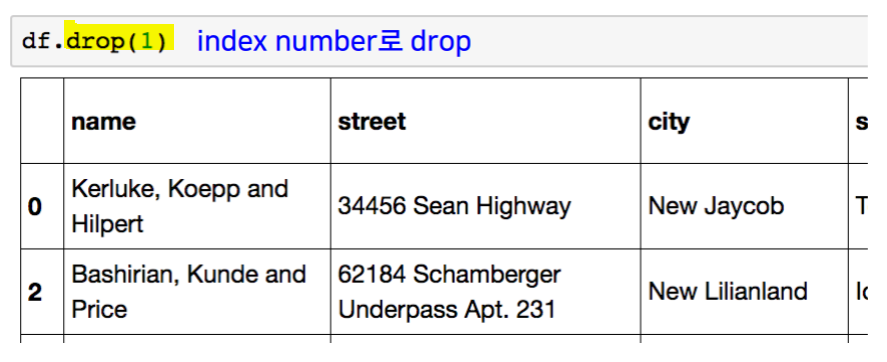
drop


Dataframe operations
lambda

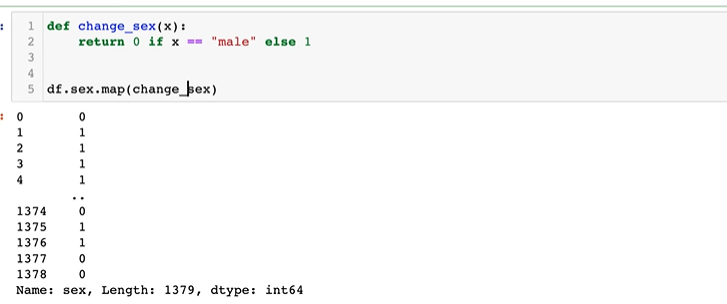
map

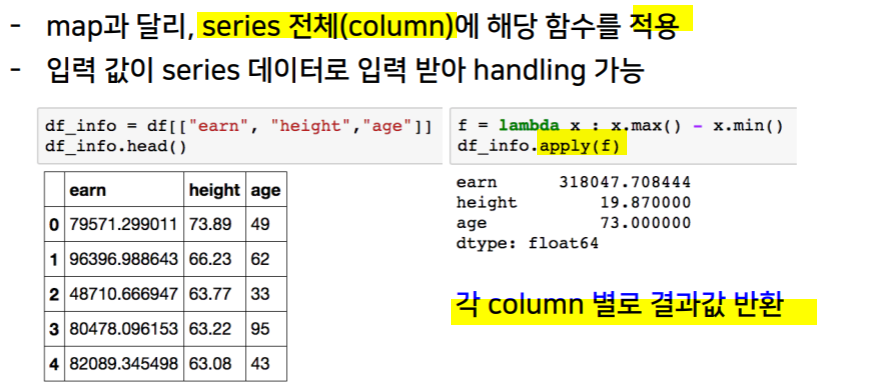
apply & applymap

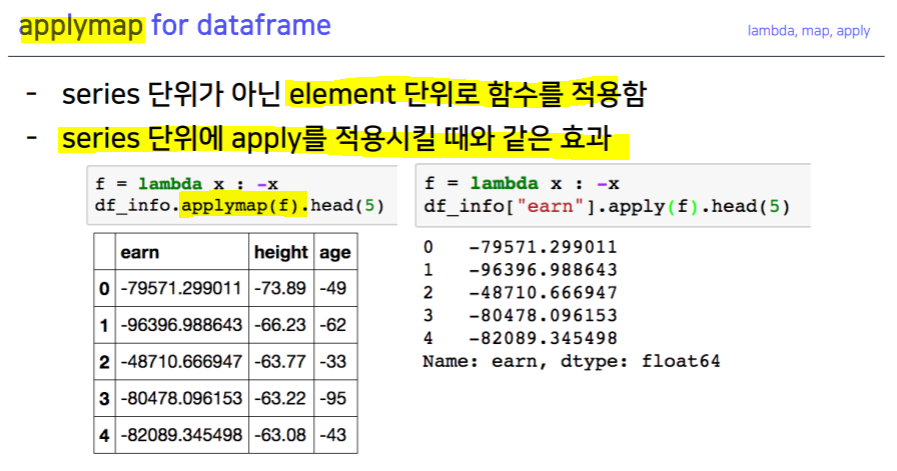
Pandas built-in functions


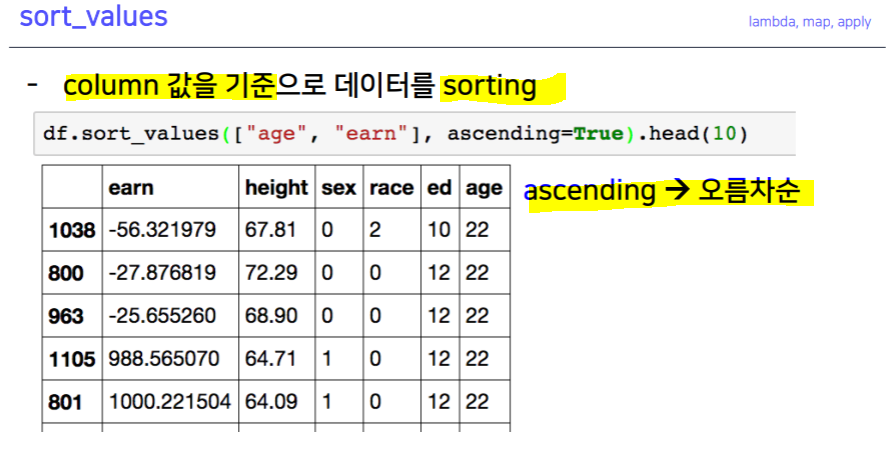
- 원하는 row의 개수만큼 볼 수 있는 기능


Review
- 데이터 로딩
import pandas as pdpd.read_csv(), pd.read_excel (conda install xlrd)df.head() df.columns = [~]
- Series
- index
.astype().values.index.name.index.name
- Dataframe
- index, columns
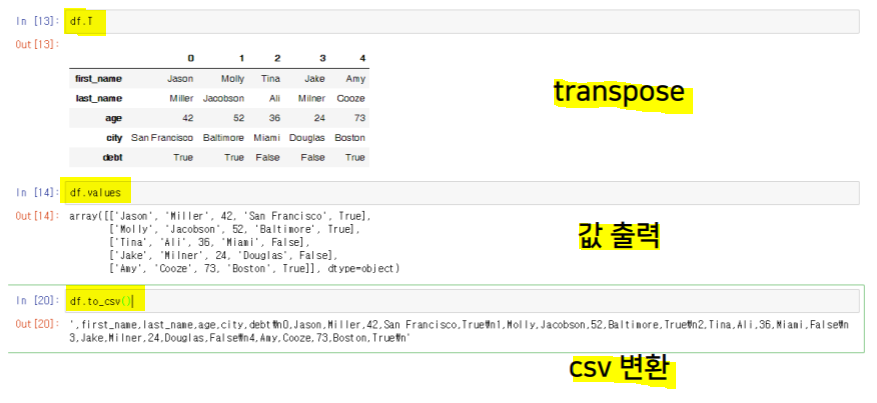
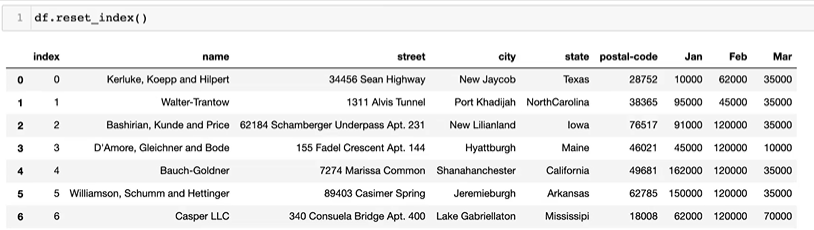
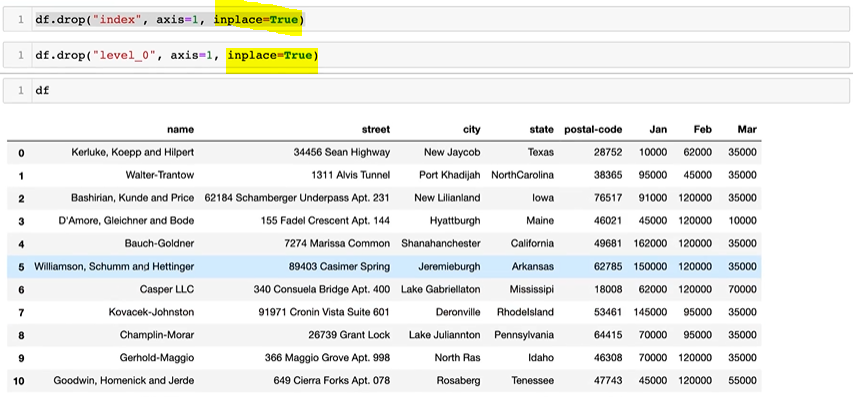
.loc, .iloc.T.values.to_csv()del df['column']df['col1'], df[['col1', 'col2', 'col3']]df[row:column]df.index = list(range(0, 15))df.reset_index(inplace=True, drop=True)df.drop(axis=1, inplace=True)- Operation types :
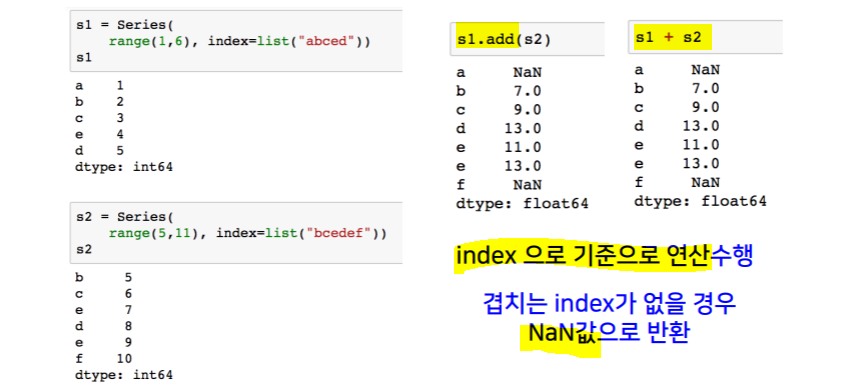
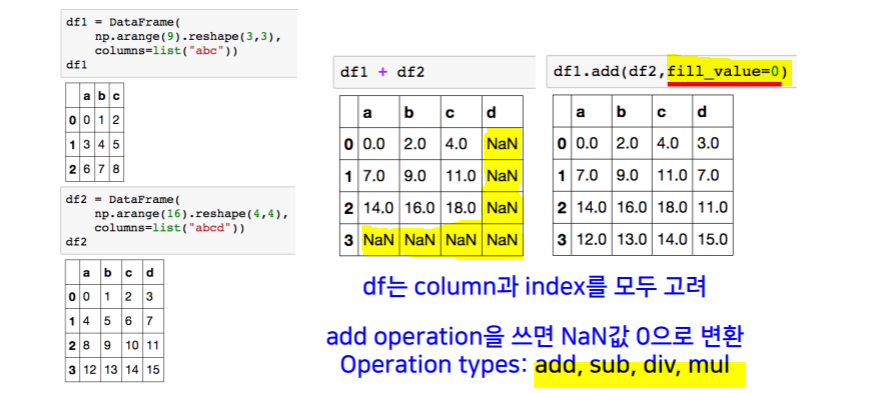
add, sub, div, mul (fill_value=n) -> index 기준 연산
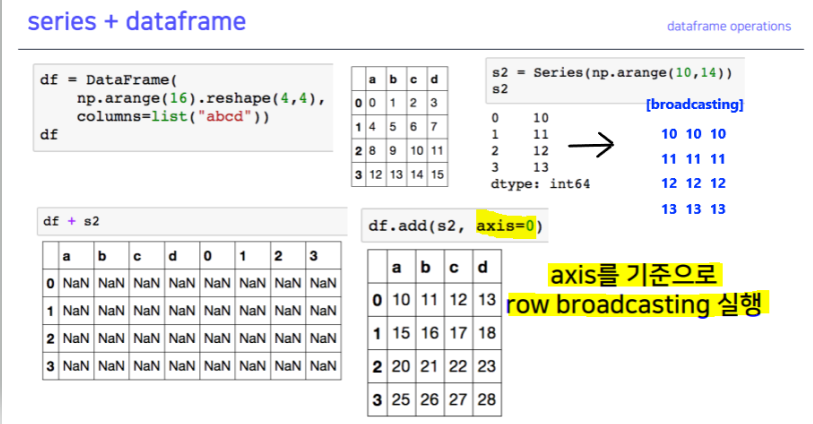
- series + dataframe : row broadcasting
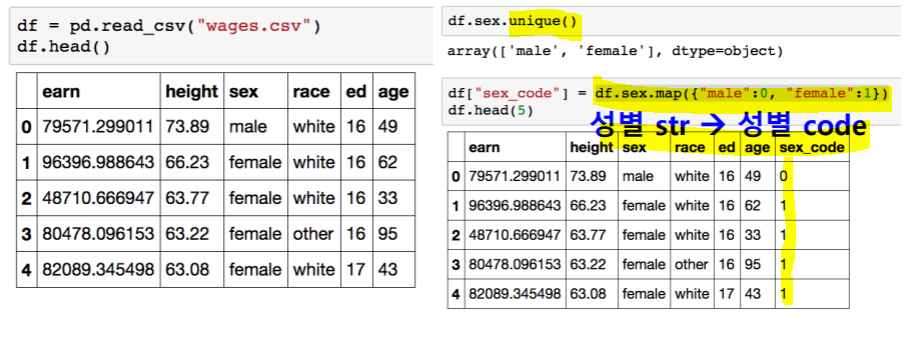
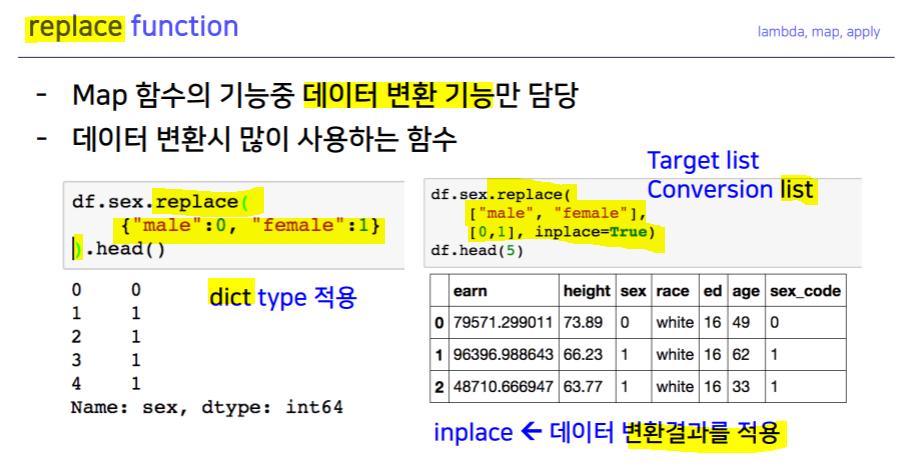
lambda.map().unique().replace().apply(), .applymap
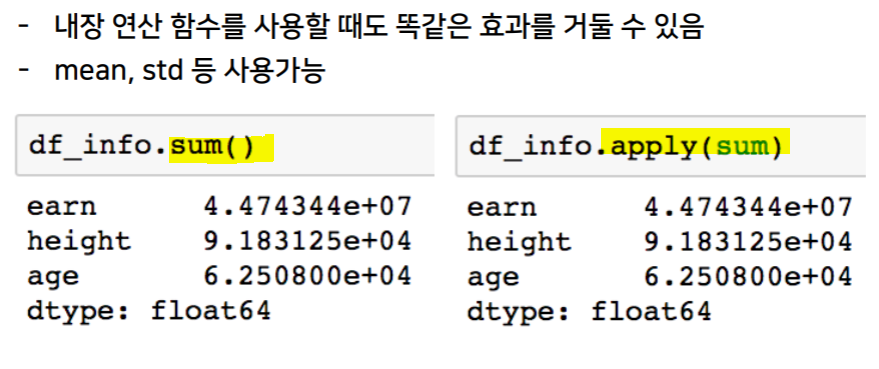
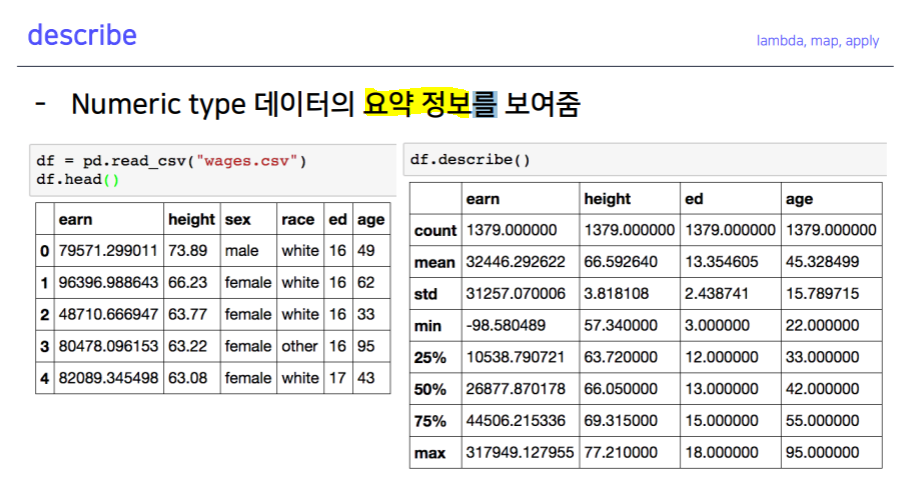
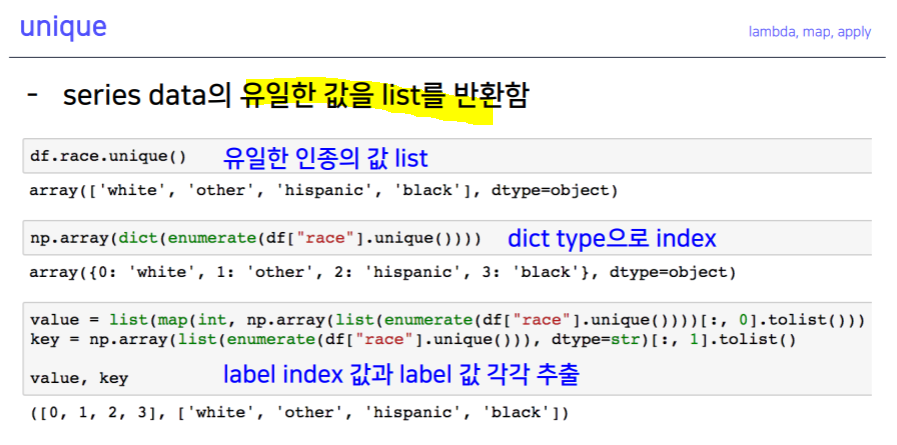
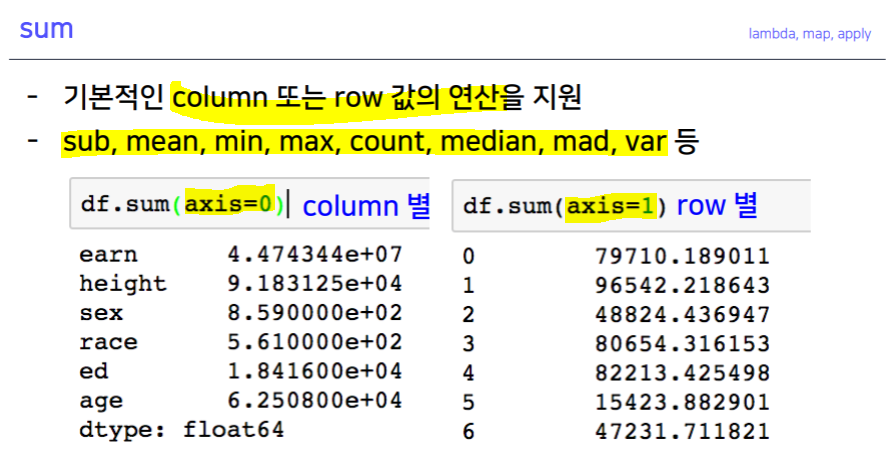
- Pandas built-in functions
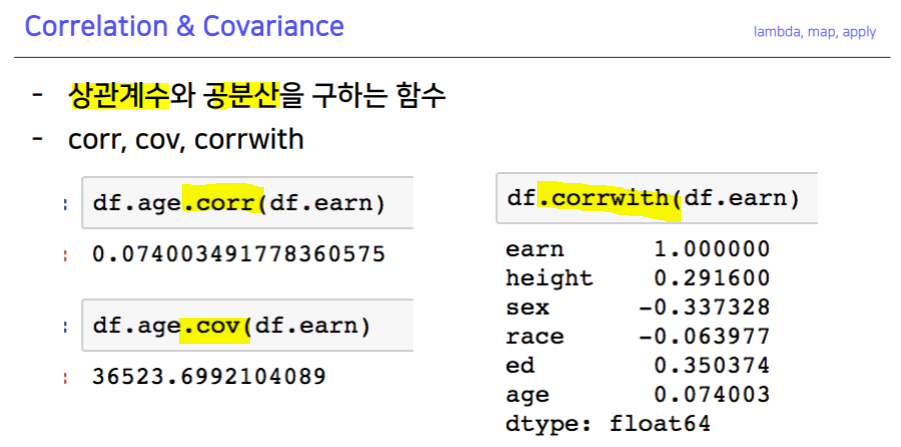
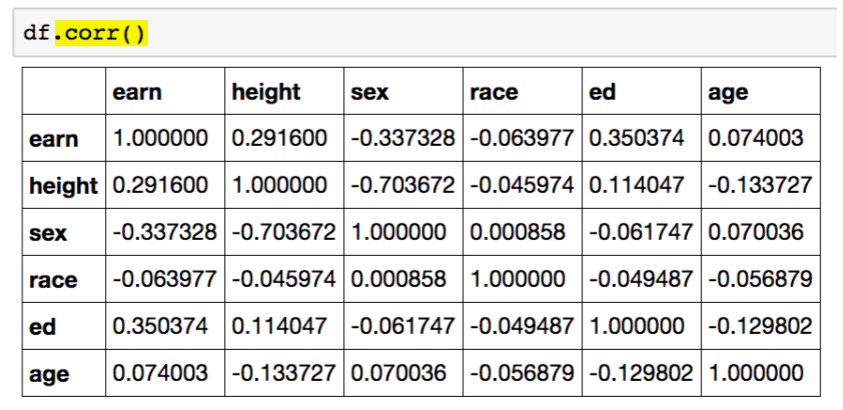
.describe().unique().sum(), .sub(), .mean(), .min(), .max() .count(), .median(), .median(), .var() -> axis 지정.isnull(), .isnull().sum().sort_values(ascending=True).corr().cov().corrwith().corr()pd.options.display.max_rows = ndf.sex.value_counts(sort=True)
