데이터 타입 : csv, 웹(html), XML, JSON
CSV(Comma separate Values)





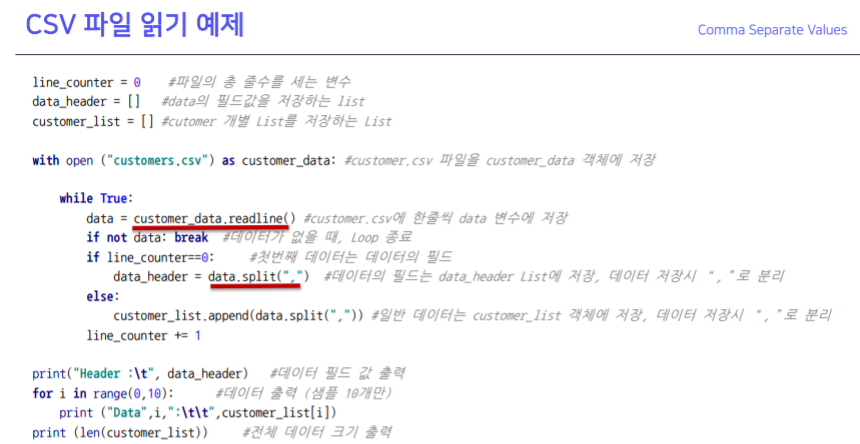

csv 객체


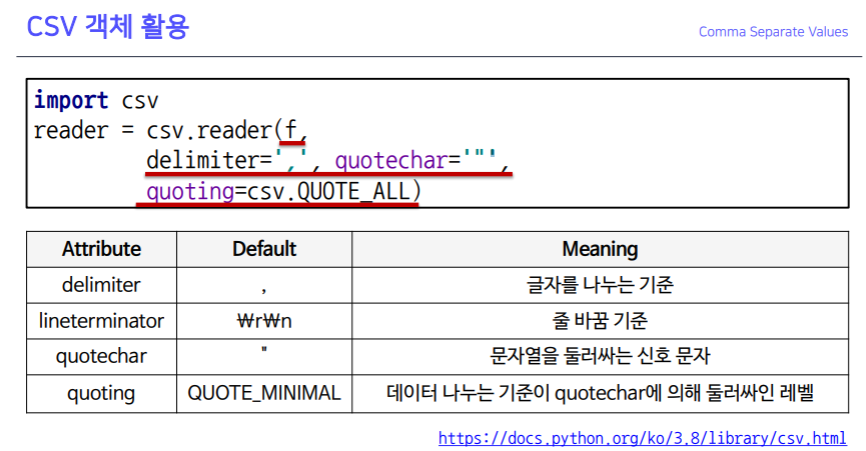

cp949: window에서 저장 및 관리되는 데이터는 모두cp949로 되어있다.u"성남시": unicode, 한글 처리 시 앞에 붙여줌u"성남시" != -1: 성남시가 존재하는 경우 (-1 : 해당 값이 없다는 뜻)encoding:cp949-> 안될 경우utf8(왠만한 파일은 거의 이것으로 저장하는 것이 좋음)delimeter: 데이터를 자르는 기준quoting: 데이터를 싸매는 기준- 새로 생긴 성남 데이터
Web

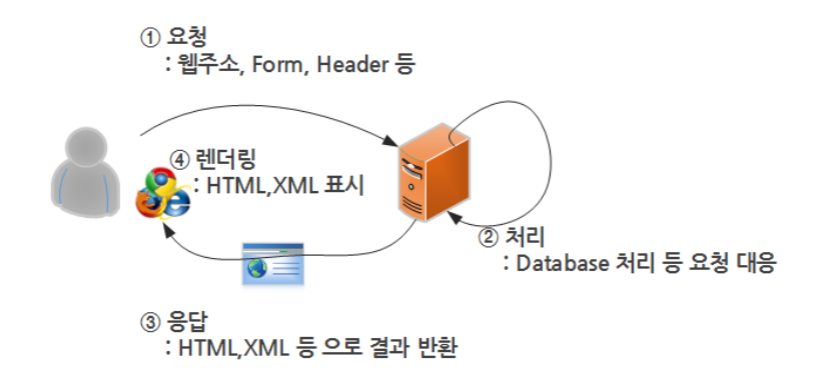
web의 동작
HTML(Hyper Text Markup Language)

- Tag :
<>

웹을 알아야 하는 이유

정규식(Regular Expression)

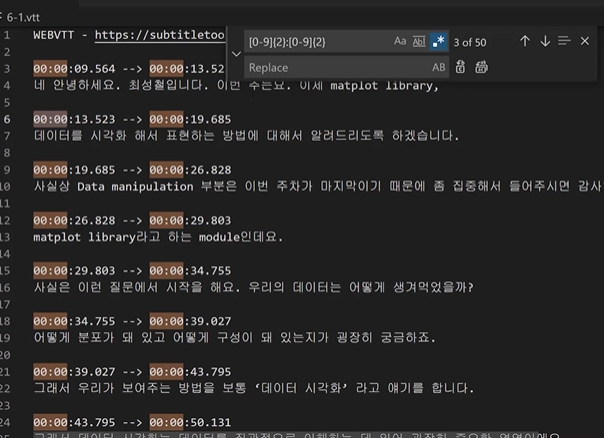



기본 문법



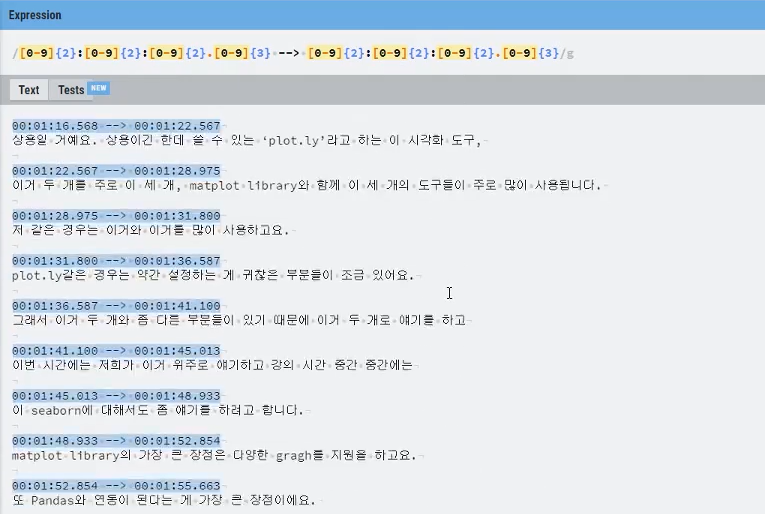

정규식 in 파이썬

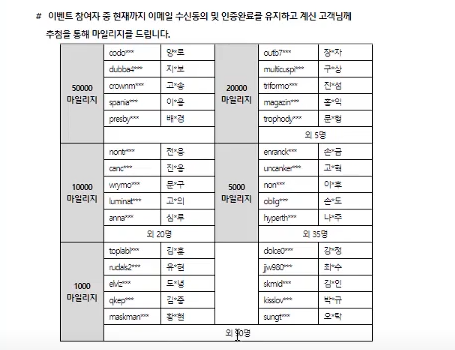
예제1 : 이벤트 당첨 아이디


urllib: url링크에 접속해서 content를 가져오는 코드findall: 해당 정규식 패턴을 가진 모든 데이터 찾아줌url_list: 찾고자 하는 데이터의 리스트 형태
예제 2 : googlebooks

예제 3 : 네이버 금융 데이터




XML(eXtensible Markup Language)



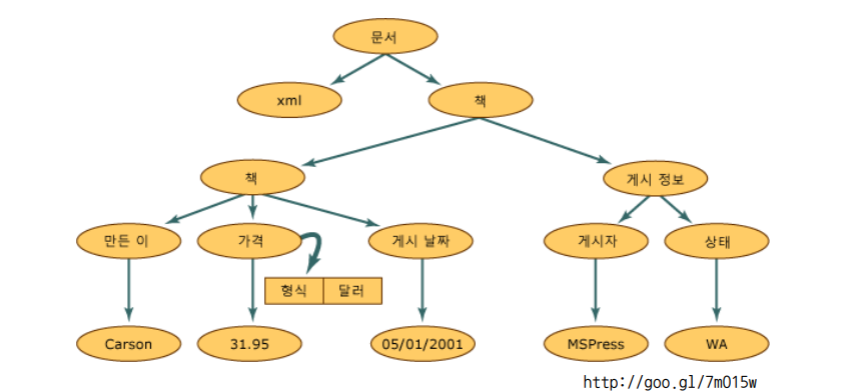
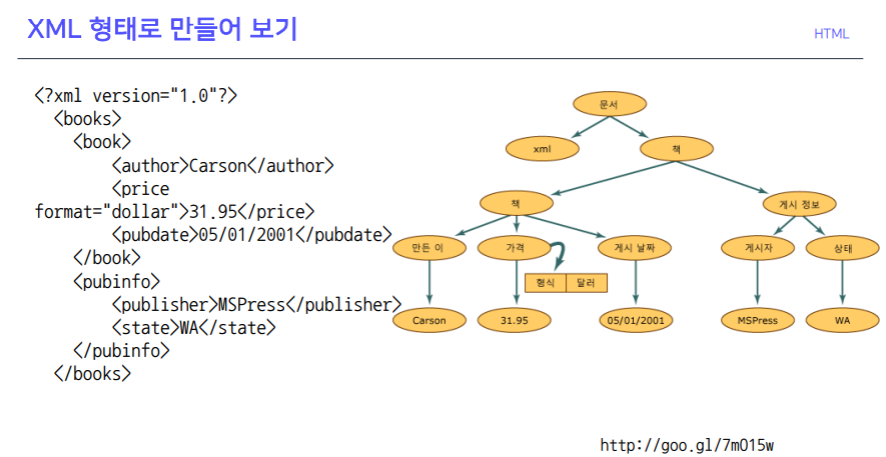

Beautifulsoup

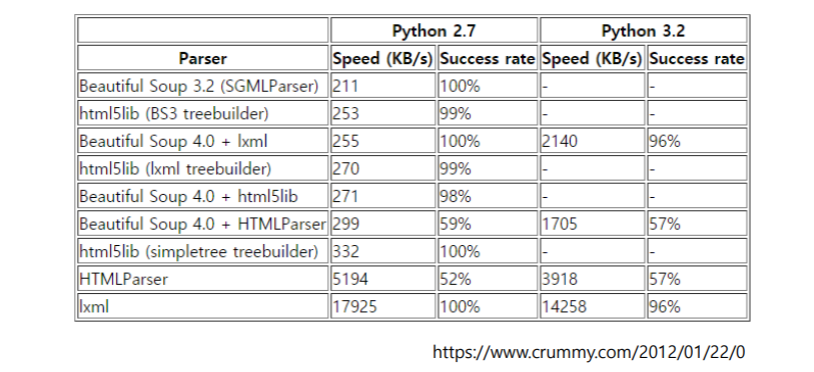
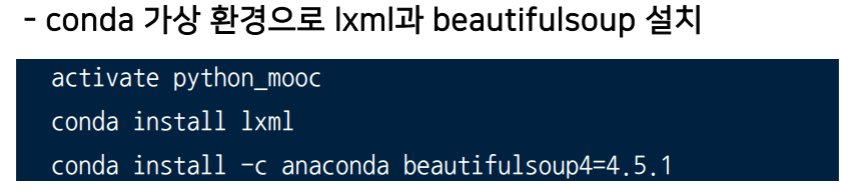
설치 및 사용

BeautifulSoup(어떤 파일을 열 것인지, 어떤 파서(parser)로 열 것인지)parser: xml을 분석하는 도구


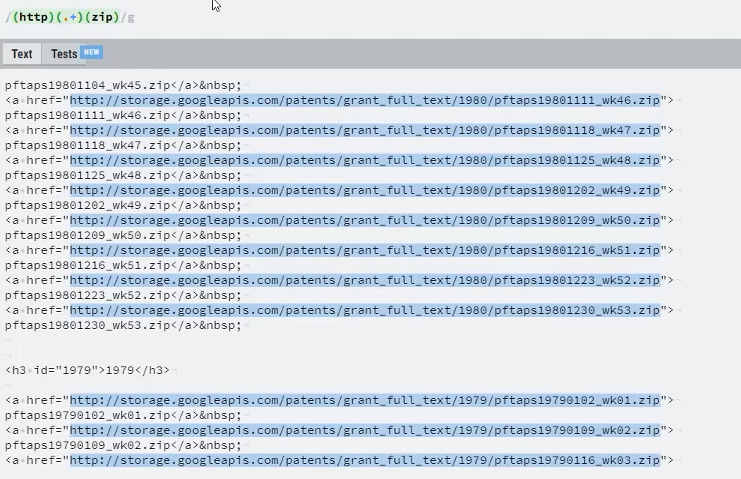
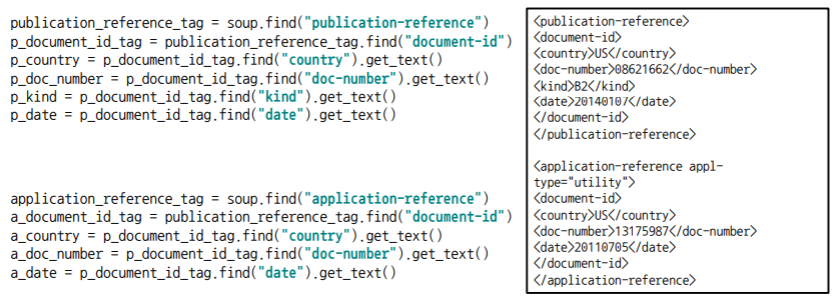
예제 : 미국 특허청(USPTO) 특허 데이터



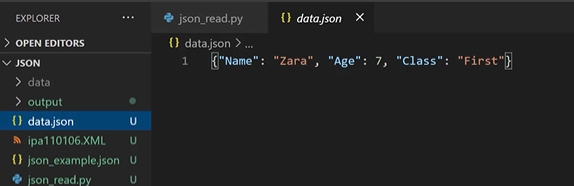
JSON (JavaScript Object Notation)



JSON in python

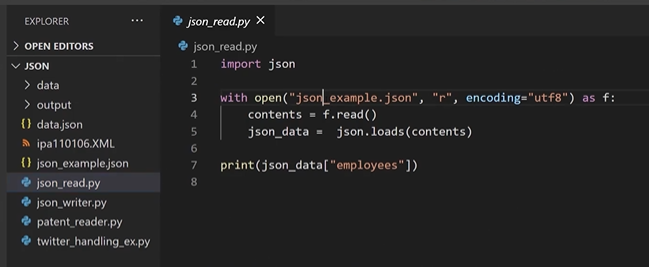
Read
json.loads()

print(json_data["employees"])

print(json_data): dict 타입으로 출력


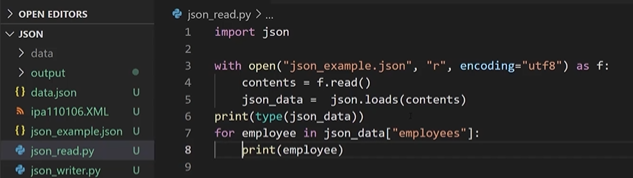
print(type(json_data))


- for문을 통해 하나씩 출력

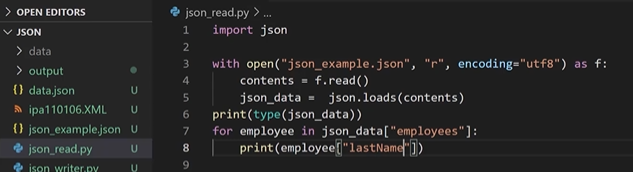
- for문 +
print(employee["lastName"])

Write
json.dump

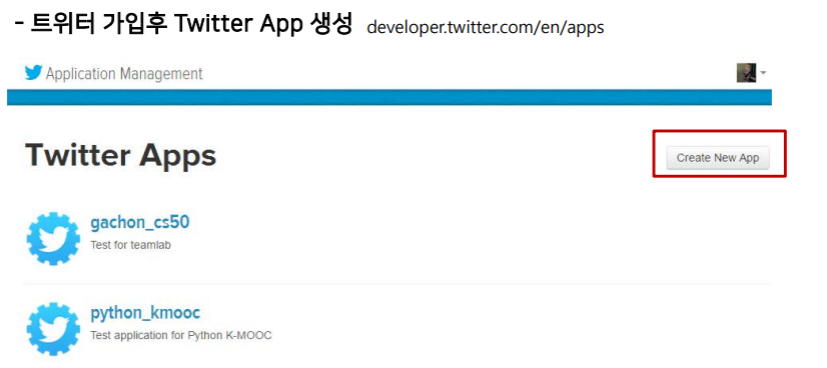
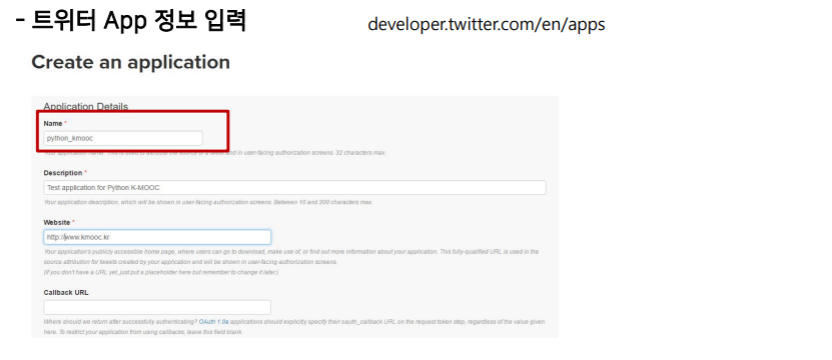
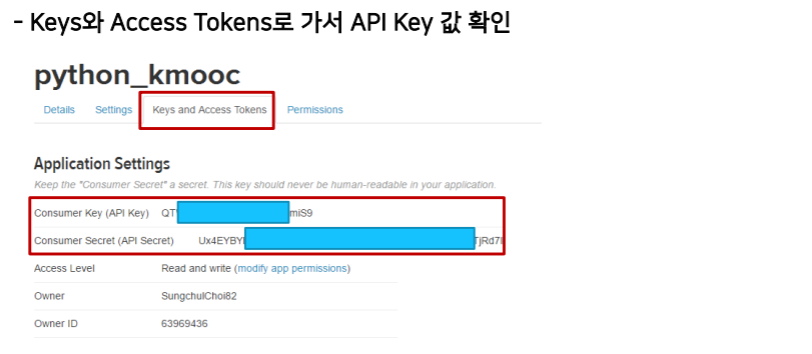
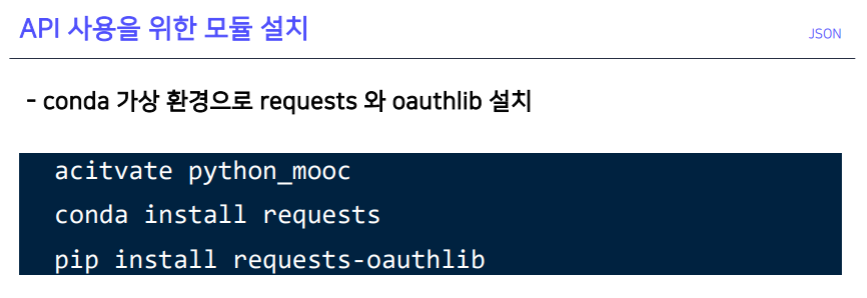
Twitter 데이터 가져오기