학습목표
- 사이킷런 파이프라인(pipelines) 을 이해하고 활용 할 수 있습니다.
- 사이킷런 결정트리(decision tree) 를 사용할 수 있습니다.
- 결정트리의 특성 중요도(feature importances) 를 활용할 수 있습니다.
- 결정트리 모델의 장점을 이해하고 선형회귀모델과 비교할 수 있습니다.
파이프라인(Pipelines)
모델을 만들때 진행했던 결측치 처리, 스케일링, 모델학습 등의 코드를 최소화하여 여러 ML 모델을 같은 전처리 프로세스에 연결시킬 뿐만 아니라 그리드서치(grid search)를 통해 여러 하이퍼파라미터를 쉽게 연결할 수 있다.
파이프라인(Pipelines)
https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.htmlpipe = make_pipeline( OneHotEncoder(), SimpleImputer(), StandardScaler(), LogisticRegression(n_jobs=-1) #n_jobs=-1 : 모든 cpu core 사용 ) pipe.fit(X_train, y_train) print('검증세트 정확도', pipe.score(X_val, y_val)) y_pred = pipe.predict(X_test)
Accessing steps(파이프라인의 각 스텝에 접근)
pipe.named_stepsimport matplotlib.pyplot as plt model_lr = pipe.named_steps['logisticregression'] enc = pipe.named_steps['onehotencoder'] encoded_columns = enc.transform(X_val).columns coefficients = pd.Series(model_lr.coef_[0], encoded_columns) plt.figure(figsize=(10,30)) coefficients.sort_values().plot.barh();
결정 트리(Decision Trees)
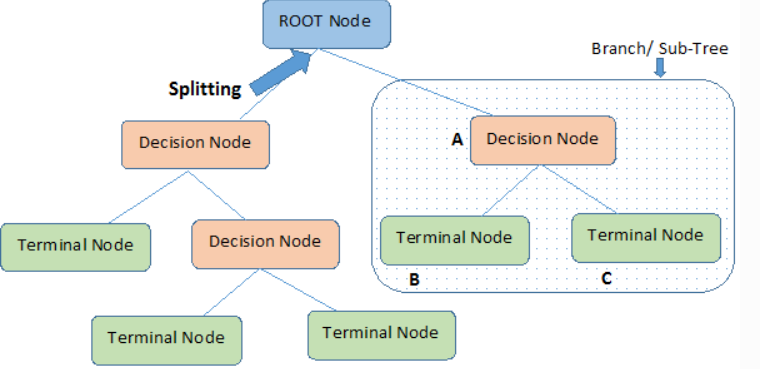
정보 이득(부모와 자식 노드 사이의 불순도 차이)이 최대가 되도록 데이터 분류 및 회귀에 사용되는 지도학습 알고리즘으로
데이터의 특징 속에서 영향력이 큰 특징(의미 있는 질문)을 상위 노드로, 영향력이 작은 특징은 하위 노드로 선택하는 것이 핵심이다.
#결정 트리는 표준화 전처리 과정(StandardScaler)이 필요없다.
#노드(node) / 엣지(edge) / 뿌리 노드(root Node) / 중간노드(internal Node) / 말단 노드(external, leaf, terminal)
#부모 노드의 Gini Impurity 보다 자식노드들의 Gini Impurity(가중평균합)가 커지면(정보획득량 감소) 더이상 트리를 나누지 않고, 부모 노드가 마지막 말단 노드가 된다.즉, 결정 트리는 가중평균합이 감소할 때까지 분기한다.
| 장점 | 단점 | |
|---|---|---|
| 의사결정트리 | - 모델의 추론 과정을 시각화하기 쉽다 -> 결과값이 왜, 어떻게 나왔는가? - 데이터에서 중요한 특성이 무엇인지 쉽게 알아낼 수 있다 - 학습 및 예측 속도가 빠르다 | - 과대적합되기 쉽다 - 조정해야 할 하이퍼파라미터가 많다. |
학습 알고리즘
결정트리를 학습하는 것은 노드를 어떻게 분할하는가에 대한 문제로, 노드 분할 방법에 따라 다른 모양의 트리구조가 만들어지게 된다. 노드 분할 시 결정트리는 비용함수를 정의하고 그것을 최소화하는 방식을 선택한다.
비용 함수
- 지니 불순도 =
-> 0일 경우 모든 샘플이 하나의 레이블을 가지며, 1에 가까울수록 여러 레이블이 한 노드에 존재함
- 엔트로피 =
*한 노드에서 모든 값이 하나의 범주(class)에 속할 때, 엔트로피(entropy)는 0이다.
즉, 분할에 사용할 특성이나 분할지점(값)은 타겟변수를 가장 잘 구별해 주는(불순도의 감소 최대, 정보획득 최대)것을 선택합니다.

정보획득(Information Gain)
: 특정한 특성을 사용해 분할했을 때 엔트로피의 감소량
IG(T,a)=H(T)−H(T|a) = 분할전 노드 불순도 - 분할 후 자식노드 들의 불순도 평균
DesicionTreeClassifier_결정트리 구현
DecisionTreeClassifier
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html?highlight=decisiontreeclassifier#sklearn.tree.DecisionTreeClassifier
| 파라미터명 | 설명 |
|---|---|
| min_samples_split | - 노드를 나누기 위한 최소 샘플 개수 → 과적합 제어하는데 사용 - int or float, default=2 → 작게 설정할 수록 분할 노드가 많아져 과적합 가능성 증가 |
| min_samples_leaf | - 리프노드가 되기 위해 필요한 최소한의 샘플 데이터수 - 과적합 제어 용도 - 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 feature 개수 - Default = None → 데이터 세트의 모든 피처를 사용 - int형으로 지정 →피처 갯수 / float형으로 지정 →비중 - sqrt 또는 auto : 전체 피처 중 만큼 선정 - log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정 |
| max_depth | - 트리의 최대 깊이 - default = None→ 완벽하게 클래스 값이 결정될 때 까지 분할 또는 데이터 개수가 min_samples_split보다 작아질 때까지 분할 - 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요 |
| max_leaf_nodes | 리프노드의 최대 개수 |
| min_impurity_decrease | 불순물 감소를 유도하는 기준 지정, float, 기본값=0.0 |
| criterion | 불순도 지정,{“gini”, “entropy”}, default=”gini” |
| splitter | 노드 분할 전략 선택, {“best”, “random”}, default=”best” |
과적합
from sklearn.tree import DecisionTreeClassifier
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True), #use_cat_names: 이전에 있는 컬럼 names를 살리면서 인코딩
SimpleImputer(),
DecisionTreeClassifier(random_state=1, criterion='entropy')
)
pipe.fit(X_train, y_train)
print('훈련 정확도: ', pipe.score(X_train, y_train)) #훈련 정확도: 0.9908667674880646
print('검증 정확도: ', pipe.score(X_val, y_val)) #검증 정확도: 0.7572055509429486시각화
# graphviz 설치방법: conda install -c conda-forge python-graphviz
import graphviz
from sklearn.tree import export_graphviz
model_dt = pipe.named_steps['decisiontreeclassifier']
enc = pipe.named_steps['onehotencoder']
encoded_columns = enc.transform(X_val).columns
dot_data = export_graphviz(model_dt
, max_depth=3
, feature_names=encoded_columns
, class_names=['no', 'yes']
, filled=True
, proportion=True)
display(graphviz.Source(dot_data))가지치기_하이퍼파라미터
과대적합의 위험이 높은 결정 트리는 학습 시 적절한 리프 노드의 샘플 개수와 트리의 깊이에 제한을 둬서 학습 데이터에 너무 모델이 치우치지 않게 주의해야 한다.
- min_samples_split : 엣지 수
- min_samples_leaf : 말단 노드(external node)에 최소한 존재해야 하는 샘플들의 수(커질 수록 분기가 적어짐/과적합 방지)
- max_depth : 트리 레벨 수 제한
특성중요도(feature importance)
선형모델에서는 특성과 타겟의 관계를 확인하기 위해 회귀 계수(coefficients)를 살펴보았지만 결정트리에서는 대신 결정 트리에 사용된 특성이 불순도를 감소하는데 기여한 정도를 나타내는 특성중요도를 확인한다. 회귀계수와 달리 특성중요도는 항상 0에서 1사이의 양수값을 가진다.(전체 합=1) 결정 트리가 계산한 특성 중요도는 모델 객체의 feature_importances_속성에 저장되어있다.
model_dt = pipe.named_steps['decisiontreeclassifier']
enc = pipe.named_steps['onehotencoder']
encoded_columns = enc.transform(X_val).columns
importances = pd.Series(model_dt.feature_importances_, encoded_columns)
plt.figure(figsize=(10,30))
importances.sort_values().plot.barh();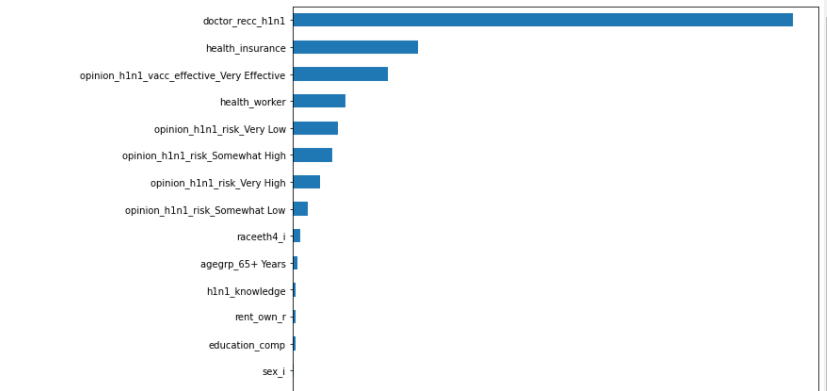
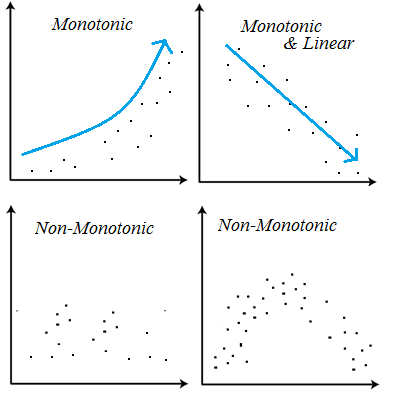
비선형, 비단조, 특성상호작용
결정트리모델은 선형모델과 달리 비선형, 비단조(non-monotonic), 특성상호작용(feature interactions) 특징을 가지고 있는 데이터 분석에 용의하다.
비선형_트리회귀모델(DecisionTreeRegressor)
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(criterion="mae")특성상호작용(feature interactions)
특성상호작용은 특성들끼리 서로 상호작용을 하는 경우를 말한다. 회귀분석에서는 서로 상호작용이 높은 특성들이 있으면 개별 계수를 해석하는데 어려움이 있고 학습이 올바르게 되지 않을 수 있다. 하지만 트리모델은 선형회귀모델과 달리 이런 상호작용을 자동으로 걸러내 특성상호작용에도 문제없이 예측이 가능하다.
+
#특정 형태 데이터 추출
train.select_dtypes(include=['number', 'object'])
#행을 기준으로 중복 검사
df.duplicated()