학습 목표
- 랜덤포레스트 모델을 이해하고 문제에 적용할 수 있습니다.
- 순서형인코딩(Ordinal encoding) 과 원핫인코딩을 구분하여 사용할 수 있습니다.
- 범주형 변수의 인코딩 방법이 트리모델과 선형회귀 모델에 주는 영향을 이해합니다.
앙상블(ensemble)
한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner, 기본모델)만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법을 말하며 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이다.
배깅(bagging)
과대적합이 쉬운 모델에 상당히 적합한 앙상블. 한 가지 분류 모델을 여러 개 만들어 서로 다른 학습 데이터로 학습시킨 후(부트스트랩), 동일한 테스트 데이터에 대한 서로 다른 예측값들을 투표를 통해(어그리게이팅) 가장 높은 예측값으로 최종 결론을 내리는 앙상블 기법이다.
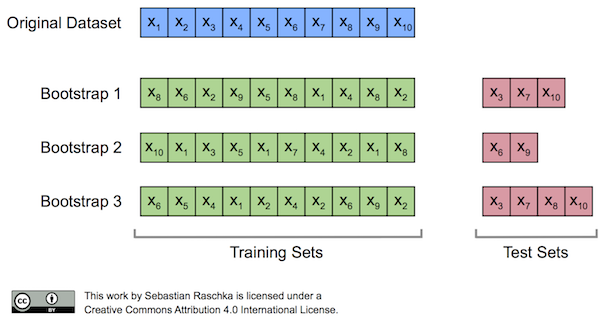
부트스트랩(Bootstrap)
데이터 샘플링 시 편향을 높임(중복 허용)으로써 분산이 높은 모델의 과대적합 위험을 줄이는 효과를 주는 기법으로 복원추출(중복 허용)을 통해 원본 데이터를 샘플링하여 부트스트랩세트를 얻어낸 후 앙상블에 사용하는 작은 모델들을 학습시키는 방식
어그리게이팅(Aggregating)
여러 분류 모델이 예측한 값들을 조합해서 하나의 결론을 도출하는 과정을 말하며 결론은 투표를 통해 결정한다.
- 회귀 : 평균
- 분류 : 다수결
*참고
무한히 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률은 위와 같으므로 데이터가 충분히 크다고 가정했을 때 한 부트스트랩세트는 표본의 63.2% 에 해당하는 샘플을 가지게 된다.
Out-Of-Bag 샘플(OOB)
추출되지 않는 36.8%의 샘플로 이를 통해 자체적으로 모델의 성능을 평가하는 점수. 이를 얻기 위해서는 RandomForestClassifier 클래스의 oob_score 매개변수를 True로 지정해야 한다. 이렇게 하면 랜덤 포레스트는 각 결정 트리의 OOB 점수를 평균하여 출력한다.
#RandomForestClassifier : oob_score=True로 지정
RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
# oob_score_
pipe.named_steps['randomforestclassifier'].oob_score_랜덤포레스트(Random Forest)
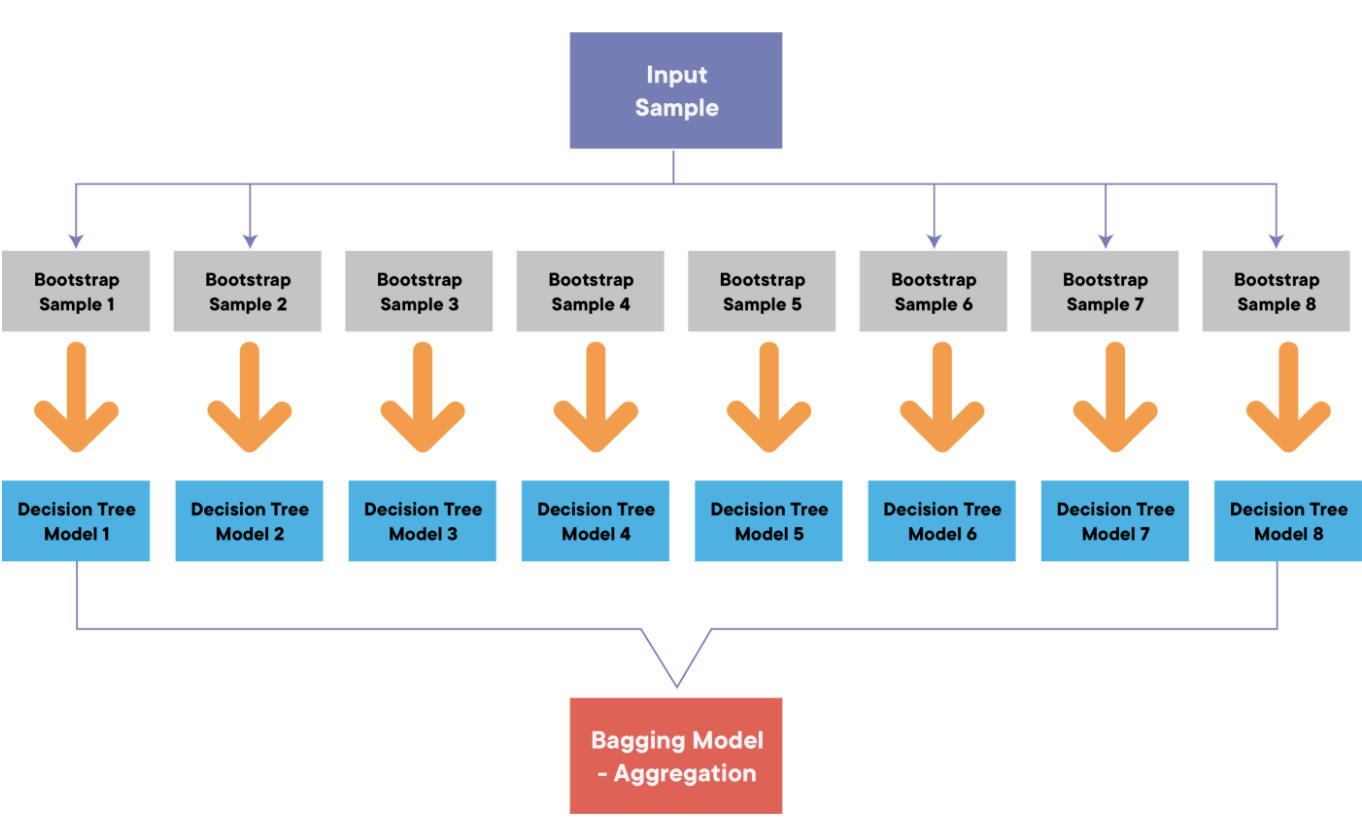


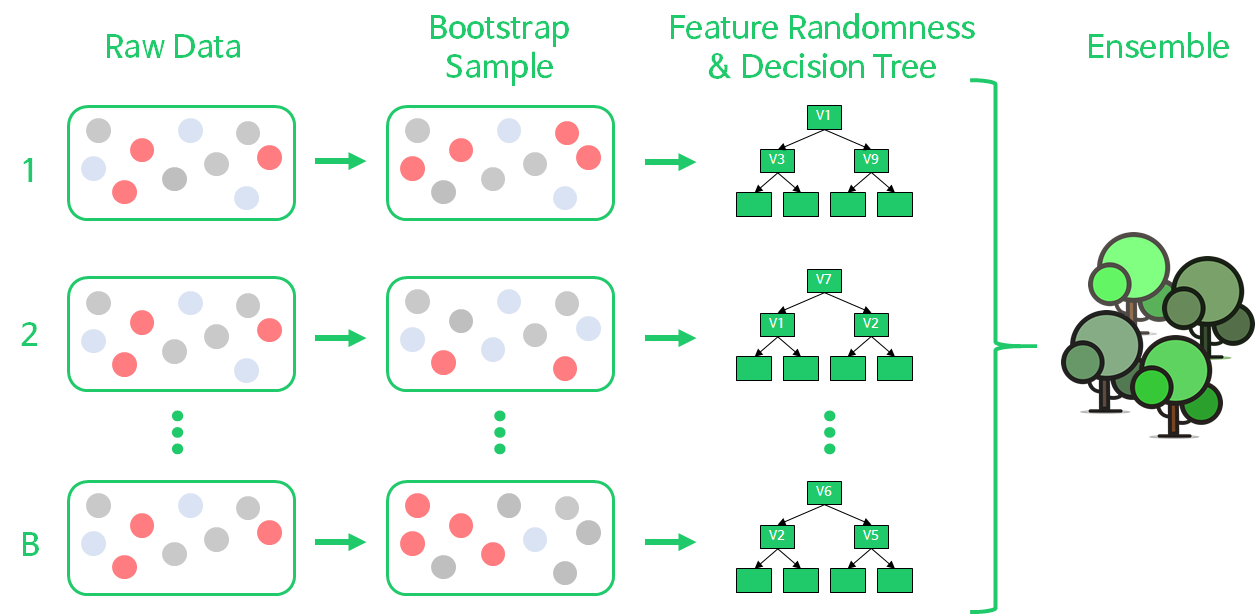
랜덤포레스트는 의사결정 트리의 과적합(Over Fitting)을 해결하기 위해 여러 의사결정 트리를 배깅해서 예측을 실행하는 모델로, 한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner, 기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 "앙상블 머신러닝 모델"이다.
랜덤 포레스트는 아래와 같이 구현된다.
- Bootstrap Sampling : 전체 데이터 N개에서 N개의 sample을 복원추출
- Feature Random Selection : 의사결정나무를 분개할 때마다 변수 중 p개를 선택하여, 최적의 변수와 split-point를 선정
- 1~2번 단계를 B번 반복하여, 결과를 취합
랜덤 포레스트는 각 나무에서 샘플과 특성 모두 랜덤하게 선택하기 때문에, 각 나무가 uncorrelated model(≓독립적)일 뿐만 아니라 훈련 세트에 과대적합되는 것을 막아주며 검증 세트와 테스트 세트에서 안정적인 성능을 얻을 수 있게 해준다.
📌 결정 트리에서는 분할을 위한 특성을 선택할 때, 모든 특성(n개)을 고려하여 최적의 특성을 고르고 분할하는 반면, 랜덤포레스트에서는 특성 n개 중 일부분 k개(=)의 특성을 선택(sampling) 하고 이 k개에서 최적의 특성을 찾아내어 분할합니다.
랜덤포레스트가 결정 트리보다 상대적으로 과적합을 피할 수 있는 이유
랜덤포레스트의 랜덤성=편향 증가=과적합 위험 감소
1. 랜덤포레스트에서 학습되는 트리들은 배깅을 통해 만들어집니다.(bootstrap = true) 이때 각 기본트리에 사용되는 데이터가 랜덤으로 선택됩니다.
2. 각각 트리는 무작위로 선택된 특성들을 가지고 분기를 수행합니다.(max_features = auto.)
%%time
from category_encoders import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(missing_values=np.nan, strategy='most_frequent'),
RandomForestClassifier(n_jobs = -1,
random_state = 10,
n_estimators = 200,
max_features = 'sqrt', #RandomForestClassifier:기본적으로 전체 특성 개수의 제곱근만큼의 특성 선택
oob_score = True) #RandomForestRegressor : 전체 특성 사용
)
pipe.fit(X_train, y_train)
print('Training accuracy : ', pipe.score(X_train, y_train))
print('Validation accuracy : ', pipe.score(X_val,y_val))
y_pred = pipe.predict(X_val)
print('Validation F1 score : ', f1_score(y_val, y_pred))순서형인코딩(Ordinal encoding)
변수의 순서를 유지하는 인코딩 방식이다. 정확한 범주의 순위를 알고 있다면 mapping 파라미터를 사용해 지정해줄 수 있다.
https://contrib.scikit-learn.org/category_encoders/ordinal.html
ex) ['a', 'b', 'c'] -> [1, 2, 3]
onehot vs ordinal
- 실행 속도의 차이 : ordinal이 더 빠르다.
- 특성의 수 : onehot이 cardinality에 비례해 shape이 커지는 반면, ordinal은 shape이 그대로이다.(*highcardinality특성도 drop하지 않아 중요한 특성이 상위 노드에서 선택될 기회가 줄어들어 성능이 낮아지는 일을 방지할 수 있다.)
- 특성 중요도 비교 : 랜덤포레스트에서는 학습 후 특성들의 중요도 정보를 기본으로 제공하는데 이는 노드들의 지니불순도 즉, 노드가 중요할수록 불순도가 감소한다는 사실을 이용한 것이다. 노드는 한 특성의 값을 기준으로 분리가 되므로 불순도를 크게 감소하는 데 많이 사용된 특성이 중요도가 올라갈 것이다.
랜덤포레스트에서 순서형인코딩을 할 경우 특성이 가지고 있는 의미를 무시하고 모두 동등하게 보게 된다.
tree based model 마인드맵 정리

