학습목표
- 모델선택을 위한 교차검증 방법을 이해하고 활용할 수 있다.
- 하이퍼파라미터를 최적화하여 모델의 성능을 향상시킬 수 있다.
교차검증(Cross-Validation)

데이터가 충분하지 않을 경우의 문제를 극복하고자 고안된 검증 방법으로 훈련 세트에서 검증 세트를 떼어 내어 평가하는 과정을 여러번 반복하고 이 점수를 평균하여 최종 검증 점수를 얻어내는 방법
장점
모든 데이터셋을 훈련에 활용할 수 있다.
- 정확도를 향상시킬 수 있다.
- 데이터 부족으로 인한 underfitting을 방지할 수 있다.
모든 데이터셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수 있다.(검증 데이터가 한쪽 데이터에 편향돼 있지 않아 따로 검증 데이터를 분리하지 않고도 학습 데이터에 대한 전반적인 검증 정확도를 구할 수 있다.)
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다.
단점
- Iteration 횟수가 많기 때문에, 모델 훈련/평가 시간이 오래 걸린다.
- 교차검증은 시계열(time series) 데이터에는 적합하지 않다.
*hold-out 교차검증
충분한 데이터가 있을때 사용하는 것으로 원시(Raw)데이터를 학습, 검증, 테스트 이렇게 세가지의 데이터 셋으로 나누어 train데이터로 학습하는 방식이다. 그러나 만약 데이터셋 전체가 개수가 크지 않다면, 모델 예측 성능에 대한 추정이 부정확해진다. 즉 홀드아웃 셋을 만들어 내는 것 자체에 대단한 신경을 써야한다
k-fold cross-validation(CV)

k개의 집합에서 k-1 개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증하는 것으로 학습 데이터의 일정 부분을 검증 데이터로 쓰되, k번의 검증 과정을 통해 학습 데이터의 모든 데이터를 한 번씩 검증 데이터로 사용해서 k개의 검증 결과를 평균낸 값을 검증 성능 평가 지표로 사용하는 방식
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0)
)
# 3-fold 교차검증을 수행합니다.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
#일반적으로 scoring을 값이 클 수록 모델 성능이 좋은 것으로 사이킷런에서 인식하는데, mae는 값이 클 수록 모델 성능이 저하되는 것이므로 Negative 키워드를 붙여서 사용
print(f'MAE ({k} folds):', -scores)
#평균&정규화
-scores.mean()
scores.std()from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
# TargetEncoder: 범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2)
)
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
#일반적으로 scoring을 값이 클 수록 모델 성능이 좋은 것으로 사이킷런에서 인식하는데, mae는 값이 클 수록 모델 성능이 저하되는 것이므로 Negative 키워드를 붙여서 사용합니다.
print(f'MAE for {k} folds:', -scores)
-scores.mean()
scores.std()(mean)TargetEncoder
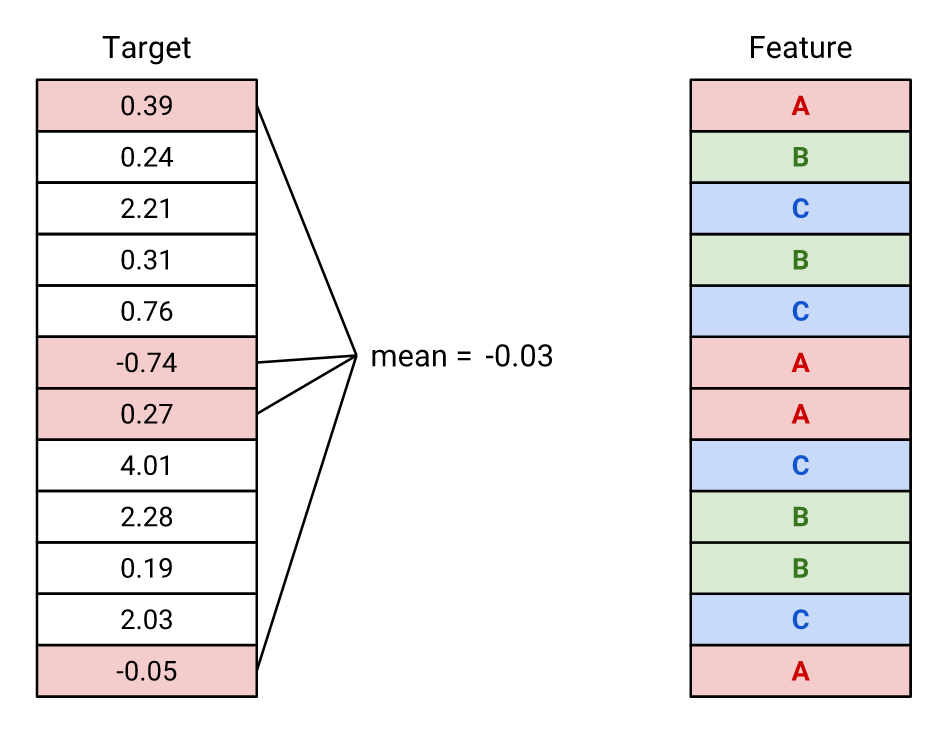

범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩한다.
#범주형 데이터만 출력
X_train.describe(exclude='number')from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
# TargetEncoder: 범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2)
)하이퍼파라미터 튜닝
머신러닝 모델을 만들 때 중요한 이슈는 다음 2가지이며,
- 최적화(optimization): 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정
- 일반화(generalization): 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 하는 것
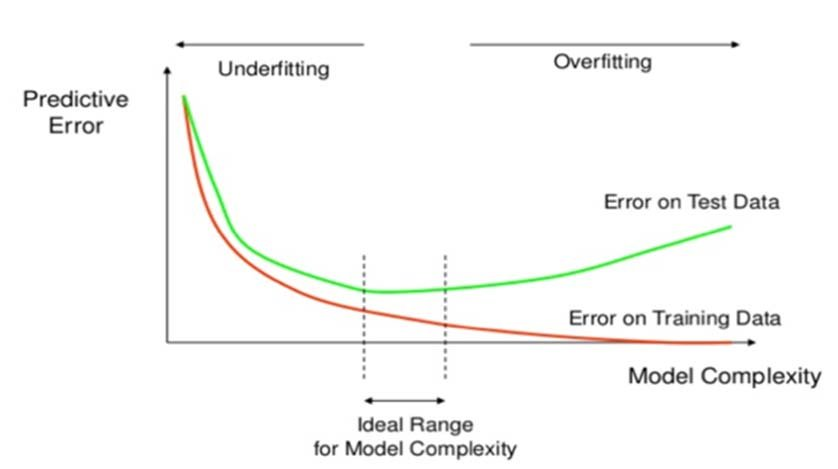
이상적인 모델은 과소적합과 과적합 사이에 존재한다.
- 과소적합(underfitting) : 훈련/검증 세트의 손실이 함께 감소하는 시점
- 과적합(overfitting) : 훈련데이터의 손실은 계속 감소하는데 검증데이터의 손실은 증가하는 때
검증곡선(validation curve) 그리기
import matplotlib.pyplot as plt
from category_encoders import OrdinalEncoder
from sklearn.model_selection import validation_curve
from sklearn.tree import DecisionTreeRegressor
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
DecisionTreeRegressor()
)
depth = range(1, 30, 2)
ts, vs = validation_curve(
pipe, X_train, y_train
, param_name='decisiontreeregressor__max_depth'
, param_range=depth, scoring='neg_mean_absolute_error'
, cv=3
, n_jobs=-1
)
train_scores_mean = np.mean(-ts, axis=1)
validation_scores_mean = np.mean(-vs, axis=1)
fig, ax = plt.subplots()
# 훈련세트 검증곡선
ax.plot(depth, train_scores_mean, label='training error')
# 검증세트 검증곡선
ax.plot(depth, validation_scores_mean, label='validation error')
# 이상적인 max_depth
ax.vlines(5,0, train_scores_mean.max(), color='blue')
# 그래프 셋팅
ax.set(title='Validation Curve'
, xlabel='Model Complexity(max_depth)', ylabel='MAE')
ax.legend()
fig.dpi = 100
이대로 트리의 깊이를 정해야 한다면 max_depth = 5 부근에서 설정해 주어야 과적합을 막고 일반화 성능을 지킬 수 있다.
Randomized Search CV

현실적으로 사용자가 직접 정해줘야 하는 하이퍼파라미터는 수작업으로 정해주는 것이 어려우므로 사이킷런에 최적의 하이퍼파라미터 조합을 찾아주는 도구를 사용한다.
- GridSearchCV: 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증
- RandomizedSearchCV: 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
pipe = make_pipeline(
TargetEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=2)
)
dists = {
'targetencoder__smoothing': [2.,20.,50.,60.,100.,500.,1000.], # int로 넣으면 error(bug)
'targetencoder__min_samples_leaf': randint(1, 10),
'simpleimputer__strategy': ['mean', 'median'],
'randomforestregressor__n_estimators': randint(50, 500),
'randomforestregressor__max_depth': [5, 10, 15, 20, None],
'randomforestregressor__max_features': uniform(0, 1) # max_features
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
#일반적으로 scoring을 값이 클 수록 모델 성능이 좋은 것으로 사이킷런에서 인식하는데, mae는 값이 클 수록 모델 성능이 저하되는 것이므로 Negative 키워드를 붙여서 사용합니다.
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)
#각 하이퍼파라미터 조합으로 만들어진 모델들을 순위별로 나열
pd.DataFrame(clf.cv_results_).sort_values(by='rank_test_score').T
#테스트 데이터에 대한 예측 결과
# 만들어진 모델에서 가장 성능이 좋은 모델을 불러옵니다.
pipe = clf.best_estimator_
from sklearn.metrics import mean_absolute_error
y_pred = pipe.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
print(f'테스트세트 MAE: ${mae:,.0f}')Parameter

best_estimator : estimator
Estimator that was chosen by the search, i.e. estimator which gave highest score (or smallest loss if specified) on the left out data. Not available if refit=False. ... See refit parameter for more information ...
=> best_estimator 는 CV가 끝난 후 찾은 best parameter를 사용해 모든 학습데이터(all the training data)를 가지고 자동으로 다시 학습(refit)한 상태
refit : boolean, string, or callable, default=True
Refit an estimator using the best found parameters on the whole dataset.
=> 만약 hold-out 교차검증(훈련/검증/테스트 세트로 한 번만 나누어 실험)을 수행한 경우에는, 반드시 (훈련 + 검증) 데이터셋에서 최적화된 하이퍼파라미터로 최종 모델을 재학습(refit) 해야 합니다.
선형회귀, 랜덤포레스트 모델들의 튜닝 추천 하이퍼파라미터
Random Forest
- class_weight (불균형(imbalanced) 클래스인 경우)
- max_depth (너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성)
Logistic Regression
- C (Inverse of regularization strength)
- class_weight (불균형 클래스인 경우)
- penalty
Ridge / Lasso Regression
- alpha
