랜덤포레스트_변수 중요도(Variable Importance)
랜덤 포레스트가 많은 강점이 있음에도 불구하고, 블랙박스모형이기 때문에 설명변수와 반응변수의 설명력을 확보하기 어렵다는 단점도 있다. 이를 어느 정도 해결하기 위해, 변수 중요도(Variable Importance)라는 척도를 통해 어느 변수가 예측 성능에 중요한 역할을 하는지를 추정하곤 한다. 변수 중요도는 "해당 변수가 상대적으로 얼마만큼 종속변수에 영향을 주는가?"에 대한 척도이기 때문에, "어떻게 영향을 주는가?"에 대한 답변으로는 적절하지 않다.
Feature Importances(Mean decrease impurity, MDI)
가장 대표적인 변수 중요도로서, scikit-learn의 default로 내장되어 있는 방법론이다.
각 변수가 split될 때 impurity 감소분의 평균, 즉 평균불순도감소(mean decrease impurity)를 중요도로 정의하는 값이다.
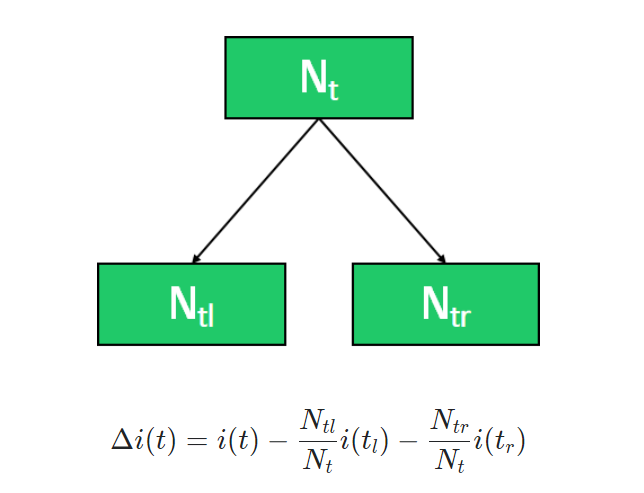
- : t노드의 impurity (entropy, gini index, variance, ...)
- : t노드의 관측치 개수
각 노드의 관측치 개수를 고려하여 impurity 감소분이 계산되며, 값이 클수록 중요도가 높습니다.
- 장점 : 빠르고, 직관적임
- 단점 : 연속형 변수와 high-cardinality 범주형 변수에 대해서는 편향됨.
Warning: impurity-based feature importances can be misleading for high cardinality features (many unique values). See sklearn.inspection.permutation_importance as an alternative.
=> 범주가 많은 특성을 분기에 사용하게 되면 트리 구성 중 분기에 이용될 확률이 높아 전체적인 일반화보다는 범주의 종류가 많은 특성들의 그룹에 편향되어 과적합을 일으키면서 불순도 감소값이 높게 나오는 오류현상을 보일 수 있어 잘못된 해석 가능성 있음
# 특성 중요도
rf = pipe.named_steps['randomforestclassifier']
importances = pd.Series(rf.feature_importances_, X_train.columns)
%matplotlib inline
import matplotlib.pyplot as plt
n = 20
plt.figure(figsize=(10,n/2))
plt.title(f'Top {n} features')
importances.sort_values()[-n:].plot.barh();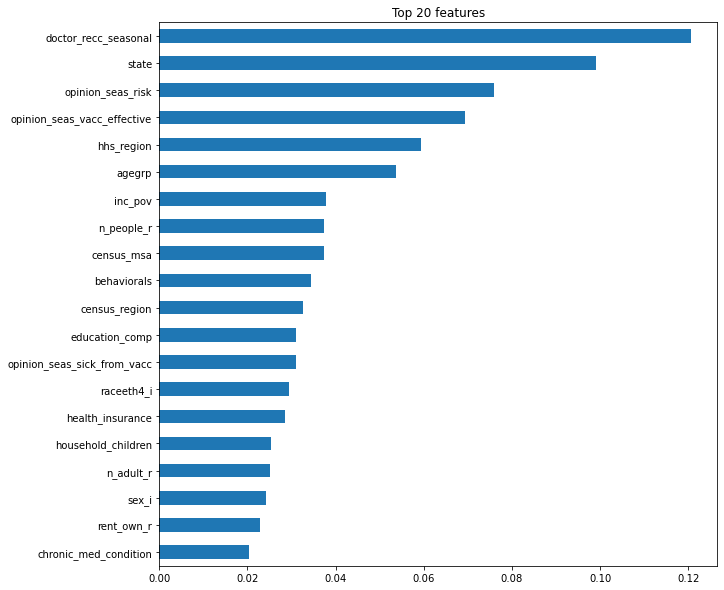
Drop-Column Importance
모든 변수를 사용했을 때의 Reference척도에서 특정 변수를 빼고 랜덤포레스트를 다시 학습했을 때의 척도의 차이로 변수 중요도를 정의하는 방법으로 변수를 뺏을 때의 성능이 많이 떨어지면 해당 변수를 중요한 변수라고 할 수 있다.
- 장점 : 개념이 매우 직관적임
- 단점 : 매 특성을 drop한 후 fit을 다시 해야 하기 때문에 매우 느리다
*특성이 n개 존재할 때 n + 1 번 학습이 필요하다.
column = 'opinion_seas_risk'
# opinion_h1n1_risk 없이 fit
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1)
)
pipe.fit(X_train.drop(columns=column), y_train)
score_without = pipe.score(X_val.drop(columns=column), y_val)
print(f'검증 정확도 ({column} 제외): {score_without}')
# opinion_h1n1_risk 포함 후 다시 학습
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1)
)
pipe.fit(X_train, y_train)
score_with = pipe.score(X_val, y_val)
print(f'검증 정확도 ({column} 포함): {score_with}')
# opinion_h1n1_risk 포함 전 후 정확도 차이를 계산합니다
print(f'{column}의 Drop-Column 중요도: {score_with - score_without}')📌순열중요도, (Permutation Importance, Mean Decrease Accuracy,MDA)
이 특성이 '얼마나'영향을 미치는가?
중요도 측정은 관심있는 특성에만 무작위로 노이즈를 주고 예측을 하였을 때 성능 평가지표(정확도, F1, R2 등)가 얼마나 감소하는지를 측정하는 방식이다. Drop-column는 중요도를 계산하기 위해 재학습을 해야 했다면, 순열중요도는 검증데이터에서 각 특성 값을 무작위로 섞어 특성과 실제 결과 사이의 관계를 없애고 모델의 예측 오차 증가를 측정하여 특성의 중요도를 판단하는 방식이다. 이때 노이즈를 주는 방법은 그 특성값들을 샘플들 내에서 섞는 것(shuffle, permutation) 이다.
*노이즈 : 특성이 기능을 하지 못하게 방해요소를 주는 것
순열중요도는 랜덤포레스트의 각 나무의 OOB(Out of Bag) sample에서 다음과 같이 구현된다.
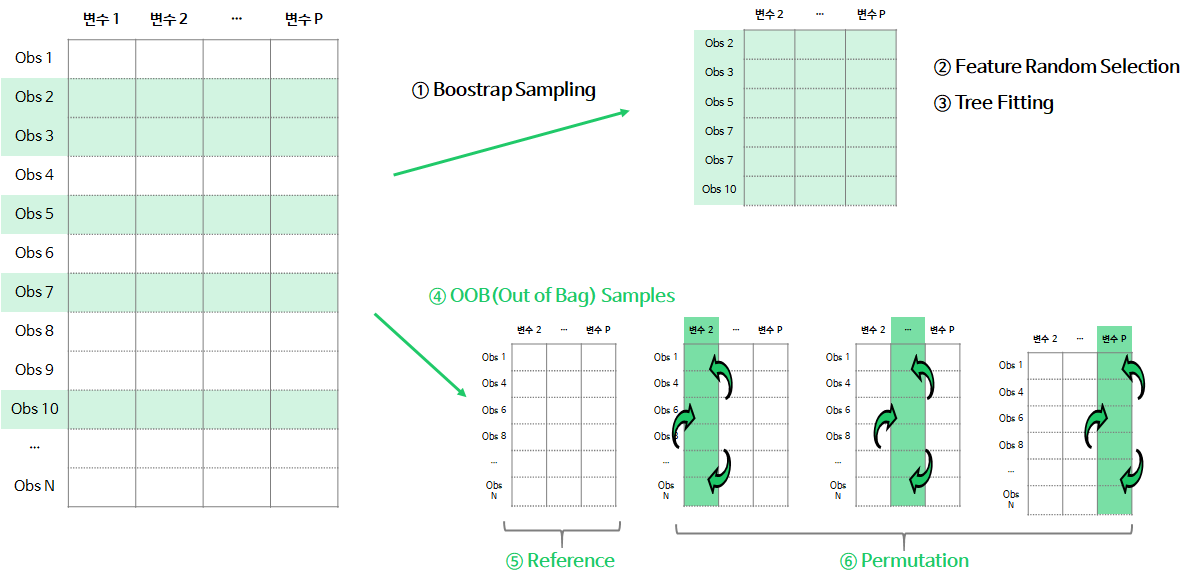
1. (①~③) n번째 tree를 생성할 때, bootstrap sample로 나무를 학습+fit
2. (④) OOB Samples : 학습할 때 사용되지 않은 데이터 셋으로 Validation 데이터를 생성
3. (⑤) Reference Measure : OOB Sample로 나무의 예측력(accuracy, R-square, MSE 등)을 계산 및 저장
4. (⑥) Permutation Measure : OOB Sample에서 j번째 변수의 데이터를 무작위로 섞은 뒤, 학습된 나무의 예측력을 계산 및 저장
5. ⑤, ⑥단계에서 저장된 예측력 척도의 차이(Reference Measure - j번째 변수의 Permutation Measure)를 계산
위의 과정을 나무의 개수 n만큼 시행하여, 각 변수에서 계산된 중요도의 평균을 Permutation Importance로 정의한다.
위의 과정 중 특정 변수를 무작위로 섞었을 때 기존 Reference 척도보다 낮아지게되면, 해당 변수는 중요하다고 판단되며 척도가 유사하거나 오히려 좋아지면 불필요하다고 판단내릴 수 있다.
- 장점 : 재학습이 필요없으므로 계산이 빠름. 직관적임.
- 단점 : Permutation importance overestimates the importance of correlated predictors — Strobl et al (2008)
#eli5
from sklearn.pipeline import Pipeline
# encoder, imputer를 preprocessing으로 묶었습니다. 후에 eli5 permutation 계산에 사용합니다
pipe = Pipeline([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
])
# pipeline 생성 확인
pipe.named_steps
pipe.fit(X_train, y_train)
print('검증 정확도: ', pipe.score(X_val, y_val))
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2
)
# permuter 계산은 preprocessing 된 X_val을 사용합니다.
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val_transformed, y_val);
#확인1
feature_names = X_val.columns.tolist()
pd.Series(permuter.feature_importances_, feature_names).sort_values()
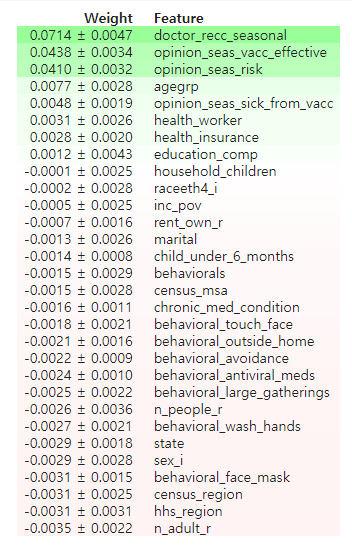
#확인2 : 특성별 score 확인
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로 넣어야 합니다
)
중요도를 이용한 특성 선택(Feature selection)
중요도가 (-)인 특성을 제외해도 성능은 거의 영향이 없지만 모델학습 속도는 개선될 수 있다.
print('특성 삭제 전:', X_train.shape, X_val.shape)
minimum_importance = 0.001
mask = permuter.feature_importances_ > minimum_importance
features = X_train.columns[mask]
X_train_selected = X_train[features]
X_val_selected = X_val[features]
print('특성 삭제 후:', X_train_selected.shape, X_val_selected.shape)
# pipeline 다시 정의
pipe = Pipeline([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
], verbose=1)
#재학습
pipe.fit(X_train_selected, y_train);
print('검증 정확도: ', pipe.score(X_val_selected, y_val))
# 순열 중요도의 평균 감소값과 그 표준편차의 차가 양수인 특징들을 확인할 수 있습니다.
permuter.feature_importances_ - permuter.feature_importances_std_ > 0트리 앙상블 모델
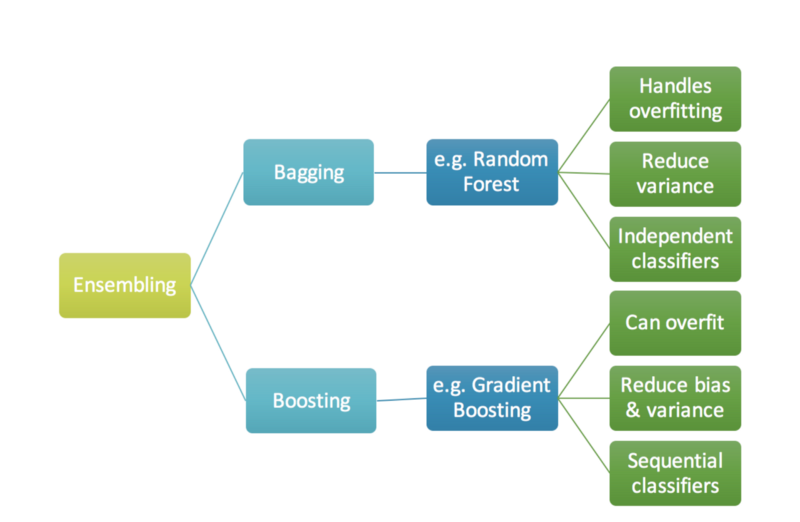
예측 성능이 조금 낮은 약 분류기(weak classifier)들의 조합으로 좀 더 좋은 성능을 발휘하는 강 분류기(strong classifier)를 만드는 앙상블 학습은 학습방법에 따라 배깅(Bagging)과 부스팅(Boosting)으로 나뉜다.
부스팅(Boosting)

부트스트랩(복원랜덤샘플링)한 데이터로 독립적으로 학습된 여러 모델의 결과를 집계(평균, 다수결)하여 최종 결과값을 구하는 배깅과는 달리
부스팅은 가중치를 활용하여 모델 간 팀워크로 약 분류기를 강 분류기로 만드는 방식이다. 처음 모델의 예측 결과에 따라 데이터의 가중치가 부여되고 이것이 또 다음 모델에게 영향을 주는 방식이다. 잘못 분류된 데이터는 다음 모델에서 더 집중해 분류하기 위해 가중치를 부여하여 새로운 분류 규칙을 만들어내고 이것이 계속 반복된다.(분류가 다시 잘 될 경우 가중치를 낮춘다.)
배깅 vs 부스팅
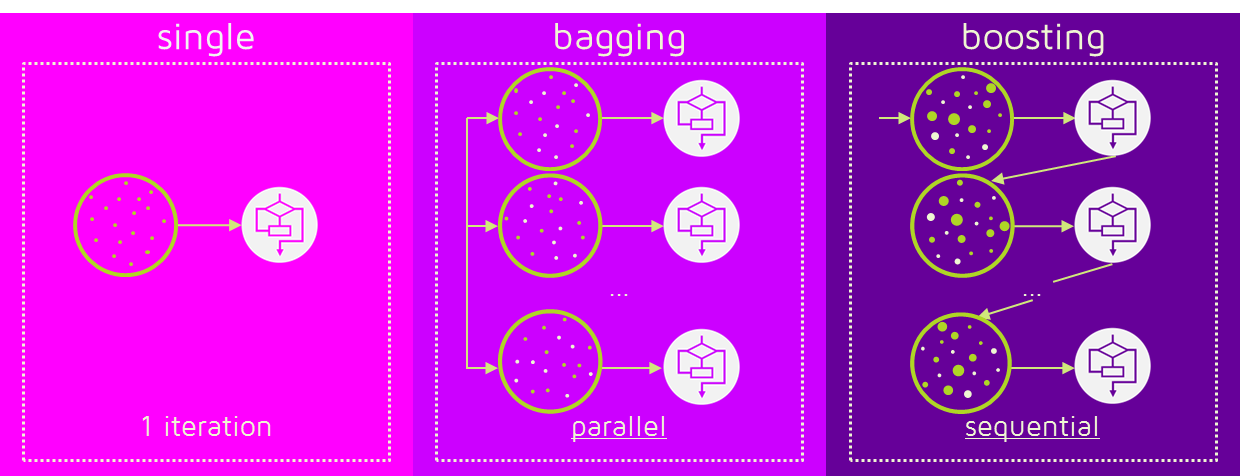
배깅은 위 그림과 같이 독립적인 각 트리들을 병렬(parallel)로 학습하여 그 결과값을 aggregate하는 반면, 부스팅은 약분류기를 하나 만든 후 이 트리의 잘못된 값에 대해 가중치를 두어 다음 트리에서는 좀 더 잘 분류할 수 있도록 순차적(sequential)으로 학습(업데이트?)하는 방식으로 오답에 더욱 집중하여 배깅에 비해 error가 적다. 즉, 성능이 좋다. 하지만 속도가 느리고 오버 피팅이 될 가능성이 있어 만약 둘 중 하나를 골라 모델을 학습해야 한다면 현재 처한 문제 상황에 따라 결정해야 한다. (낮은 성능 문제→부스팅, 오버 피팅→배깅)
*분류문제를 풀기 위해서는 트리 앙상블 모델을 많이 사용한다.
- 트리모델은 non-linear, non-monotonic 관계, 특성간 상호작용이 존재하는 데이터 학습에 적용하기 좋다.
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에. 배깅(Bagging, 랜덤포레스트)이나 부스팅(Boosting) 앙상블 모델을 사용해 과적합을 피한다.
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것인데, 그래디언트 부스팅의 경우 하이퍼파라미터 셋팅에 따라 랜덤포레스트 보다 더 좋은 예측 성능을 보여줄 수도 있다.
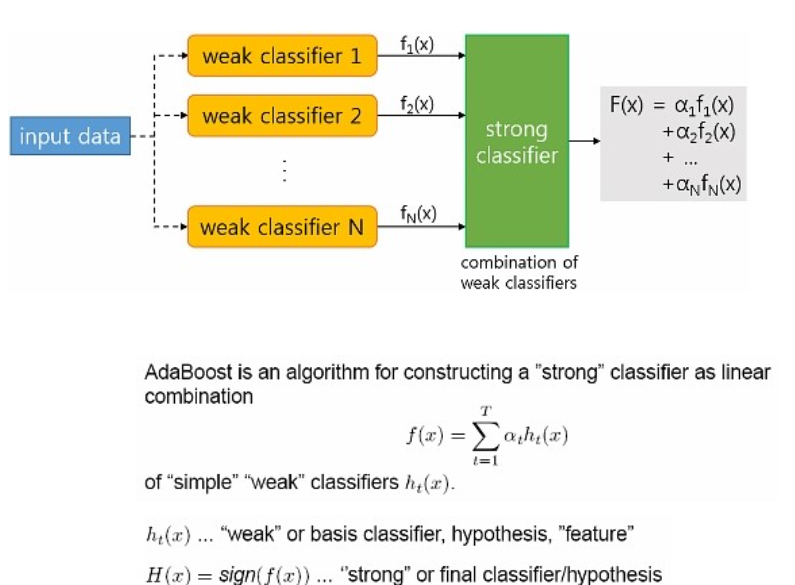
에이다 부스트(AdaBoost)
adaptive + boosting의 축약어로 각 트리((분류력이) 약한 약학습기들, weak learners)가 만들어질 때 잘못 분류되는 관측치에 가중치를 주어 다음 트리가 만들어질 때 이전에 잘못 분류된 관측치가 더 많이 샘플링되게 하여 그 관측치를 분류하는데 더 초점을 맞추는 부스팅 알고리즘이다.
아래는 AdaBoost의 알고리즘 예시 입니다.
Step 0. 모든 관측치에 대해 가중치를 동일하게 설정 합니다.
Step 1. 관측치를 복원추출 하여 약한 학습기 Dn을 학습하고 +, - 분류 합니다.
Step 2.잘못 분류된 관측치에 가중치를 부여해 다음 과정에서 샘플링이 잘되도록 합니다.
Step 3. Step 1~2 과정을 n회 반복(n = 3) 합니다.
Step 4. 분류기들(D1, D2, D3)을 결합하여 최종 예측을 수행합니다.


- : 약분류기
- : 가중치(신뢰도)
- : 분류기의 개수
- : 최종 강분류기
최종 학습기 는 약한 학습기들()의 가중()합으로 만들어진다. 여기서 가 크면 가 작다는 것으로 분류기 성능이 좋다는 것이고 여기서 가 작으면 가 크다는 것으로 분류기 성능이 안좋다는 뜻이다.
이렇게 AdaBoost 알고리즘은 T개의 약한 분류기를 weight linear combination하여 최종 강분류기를 만든다.
그래디언트 부스팅(Gradien Boost)

그래디언트 부스팅은 회귀와 분류문제에 모두 사용할 수 있다.
그래디언트 부스팅은 AdaBoost와 유사하지만 비용함수(Loss function)을 최적화하는 방법에 있어서 차이가 있습니다. 그래디언트 부스팅에서는 샘플의 가중치를 조정하는 대신 잔차(residual)을 학습하도록 합니다. 이것은 잔차가 더 큰 데이터를 더 학습하도록 만드는 효과가 있습니다.
- 분류 문제는 랜덤 포레스트, 회귀는 그래디언트 부스팅으로 사용하는 것이 최적
Python libraries for Gradient Boosting
- scikit-learn Gradient Tree Boosting — 상대적으로 속도가 느릴 수 있다.
- Anaconda: already installed
- Google Colab: already installed- xgboost — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
- Anaconda, Mac/Linux: conda install -c conda-forge xgboost
- Windows: conda install -c anaconda py-xgboost
- Google Colab: already installed- LightGBM — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
- Anaconda: conda install -c conda-forge lightgbm
- Google Colab: already installed- CatBoost — 결측값을 수용하며, categorical features를 전처리 없이 사용할 수 있습니다.
- Anaconda: conda install -c conda-forge catboost
- Google Colab: pip install catboost
XGBoost
Gradient boosting 알고리즘의 단점(느림, 과적합 이슈)을 보완하기 위해 나온 앙상블 부스팅 모델
- 랜덤포레스트보다 하이퍼파라미터 셋팅에 민감함
- gbm'보다'는 빠르다
- 과적합(overfitting)방지가 가능한 규제 포함
- CART(Classification And Regression Tree) 기반(분류와 회귀 모두 가능)
- 조기 종료(early stopping) 사용하여 과적합 피함
- Gradient Boost 기반으로 앙상블 부스팅의 특징인 가중치 부여를 경상하강법(gradient descent)으로 한다.
encoder = OrdinalEncoder()
X_train_encoded = encoder.fit_transform(X_train) # 학습데이터
X_val_encoded = encoder.transform(X_val) # 검증데이터
# XGBClassifier
model = XGBClassifier(
n_estimators=1000, # <= 1000 트리로 설정했지만, early stopping 에 따라 조절됩니다.
#아무리 수치를 높게 주어도 모델이 50rounds 동안 개선이 없을 경우 weak tree 만드는 것을 그만두고 종료
max_depth=7, # default=3, high cardinality 특성을 위해 기본보다 높여 보았습니다.
learning_rate=0.2,
# scale_pos_weight=ratio, # 타겟이 imbalance 데이터 일 경우 비율을 적용합니다.
# vc = y_train.value_counts().tolist()
# ratio = float(vc[0]/vc[1])
n_jobs=-1
)
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric='error', # #(wrong cases)/#(all cases)
early_stopping_rounds=50 # 50 rounds 동안 스코어의 개선이 없으면 멈춤
)
>>> 검증 정확도 상승!results = model.evals_result()
train_error = results['validation_0']['error']
val_error = results['validation_1']['error']
epoch = range(1, len(train_error)+1)
plt.plot(epoch, train_error, label='Train')
plt.plot(epoch, val_error, label='Validation')
plt.ylabel('Classification Error')
plt.xlabel('Model Complexity (n_estimators)')
plt.ylim((0.15, 0.25)) # Zoom in
plt.legend();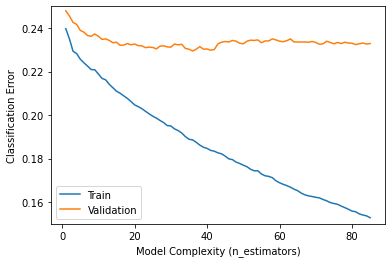
*monotonic constraints
# monotonic constraints 효과, 단조증가해야 하는 특성이 오류로 비단조 증가할때 변수마다 적용 가능합니다.
# 단조증가해야 하는 특성을 명확하게 알고있을 경우 옵션을 줄 수 있다.
from IPython.display import HTML, display
display(HTML('<table><tr><td><img src="https://xiaoxiaowang87.github.io/images/2016-11-20-monotonicity_constraint/no_constraint_one_feature.png" width="300" /></td><td><img src="https://xiaoxiaowang87.github.io/images/2016-11-20-monotonicity_constraint/w_constraint_one_feature.png" width="300" /></td></tr></table>'))
하이퍼파라미터 튜닝
Random Forest
- max_depth (높은값에서 감소시키며 튜닝, 너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성, 높이면 같은 특성을 사용하는 트리가 많아져 다양성이 감소)
- class_weight (imbalanced 클래스인 경우 시도)
XGBoost
- learning_rate (높을경우 과적합 위험이 있습니다)
- max_depth (낮은값에서 증가시키며 튜닝, 너무 깊어지면 과적합위험, -1 설정시 제한 없이 분기, 특성이 많을 수록 깊게 설정)
- n_estimators (너무 크게 주면 긴 학습시간, early_stopping_rounds와 같이 사용)
- scale_pos_weight (imbalanced 문제인 경우 적용시도)
보다 자세한 내용 아래 참고
[reference]
Adaboost, Machine learning, Boosting
데이터마이닝_앙상블 학습 알고리즘
앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
에이다 부스트(AdaBoost)
랜덤 포레스트에서의 변수 중요도(Variable Importance) 3가지
머신러닝 앙상블 xgboost란?
