학습 목표
- 트랜잭션에 대해서 설명할 수 있어야 합니다.
- ACID에 대해서 설명할 수 있어야 합니다.
- SQL 다중 테이블 쿼리를 날릴 수 있어야 합니다.
- GROUP BY를 사용할 수 있어야 합니다.
트랜잭션
COMMIT & ROLLBACK
ACID
SQL 내장함수_집합연산
SQL에서 자체적으로 사용할 수 있는 함수로 레코드들을 조회하고 분류한 뒤에 특정 작업을 합니다.
GROUP BY
데이터를 조회하게 될 때 묶어서 조회하게 해주는 기능
# 각 주(state)를 기반으로 그룹화
SELECT State, COUNT(*)
FROM customers
GROUP BY State;HAVING
GROUP BY로 조회된 결과에 대한 필터 적용
# 각 주(state)를 기반으로 그룹화
SELECT State, COUNT(*)
FROM customers
GROUP BY State;WHERE와는 무엇이 다른가?
- WHERE : 그룹화하기 전에 조회되는 레코드 필터
=> GROUP BY 전에 데이터를 필터하고 싶다면 WHERE- HAVING : 그룹화한 결과에 대한 필터
=> GROUP BY 결과에 대한 필터는 HAVING
그룹화를 했으니 이제 묶여진 그룹에 대해서 어떤 작업들을 할 수 있는지 알아보겠습니다.
COUNT()
몇 개인지 값을 리턴
# 각 그룹의 첫번째 레코드와 각 그룹에 대한 집계를 리턴
SELECT *, COUNT(*) FROM customers
GROUP BY State;
# 필요한 정보만 조회
SELECT State, COUNT(*) FROM customers
GROUP BY State;SUM()
합을 구해주는 함수로 조회된 값들에 대한 합을 구해 리턴
# 'InvoiceId' 필드를 기준으로 그룹화 후 'UnitPrice' 필드에 대한 값들에 대한 합을 구함
SELECT InvoiceId, SUM(UnitPrice)
FROM invoice_items
GROUP BY InvoiceId;AVG()
평균값을 구해주는 함수
# 각 TrackId 의 평균 'UnitPrice' 를 구함
SELECT TrackId, AVG(UnitPrice)
FROM invoice_items
GROUP BY TrackId;MAX(), MIN()
최대값과 최소값을 구할 수 있는 함수
# CustomerId로 그룹화한 뒤에 각 고객의 최소값들을 보여줌
SELECT CustomerId, MIN(Total) # MAX일 경우, 각 고객이 지불한 최대 금액을 명시
FROM invoices
GROUP BY CustomerIdSQL More
SELECT 실행 순서
SELECT 문은 데이터를 조회하는 쿼리문에 사용이 됩니다. 그런데 쿼리문이 적힌 순서가 아닌 정해진 순서대로 작동을 하게 됩니다.
실행 순서는 다음과 같습니다.
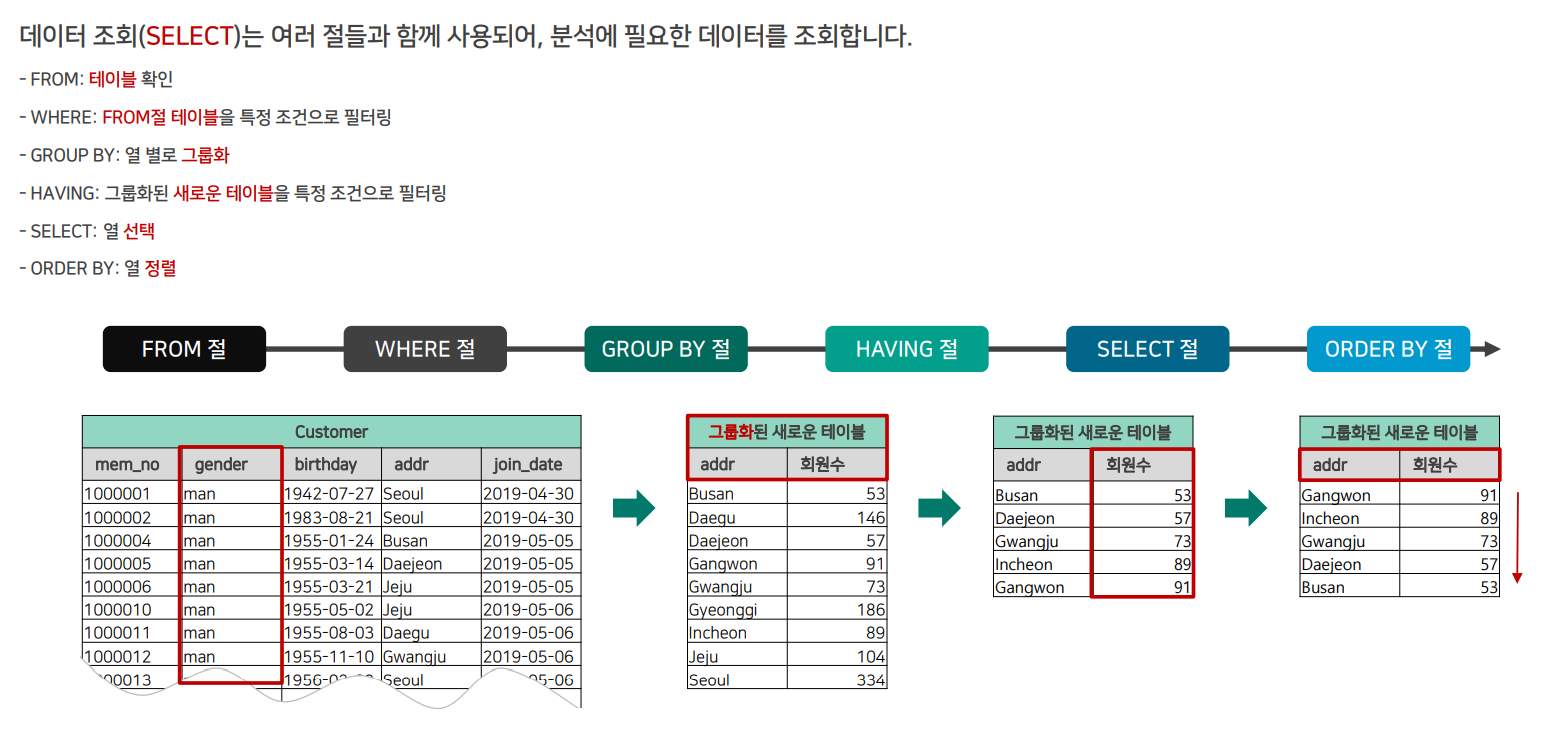

SELECT CustomerId, AVG(Total)
FROM invoices
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2FROM invoices: 먼저 invoices 테이블에 접근을 합니다.WHERE CustomerId >= 10: 'CustomerId' 필드가 10 이상인 레코드들을 조회합니다.GROUP BY CustomerId: 'CustomerId' 를 기준으로 그룹화합니다.HAVING SUM(Total) >= 30: 'Total' 필드의 값들의 합이 30 이상인 결과들만 필터합니다.SELECT CustomerId, AVG(Total): 조회된 결과에서 'CustomerId' 필드와 'Total' 필드의 평균값을 가져옵니다.ORDER BY 2:AVG(Total)필드를 기준으로 오름차순 정렬을 합니다.
if / CASE
SELECT CASE
WHEN CustomerId <= 25 THEN 'GROUP 1'
WHEN CustomerId <= 50 THEN 'GROUP 2'
ELSE 'GROUP 3'
END
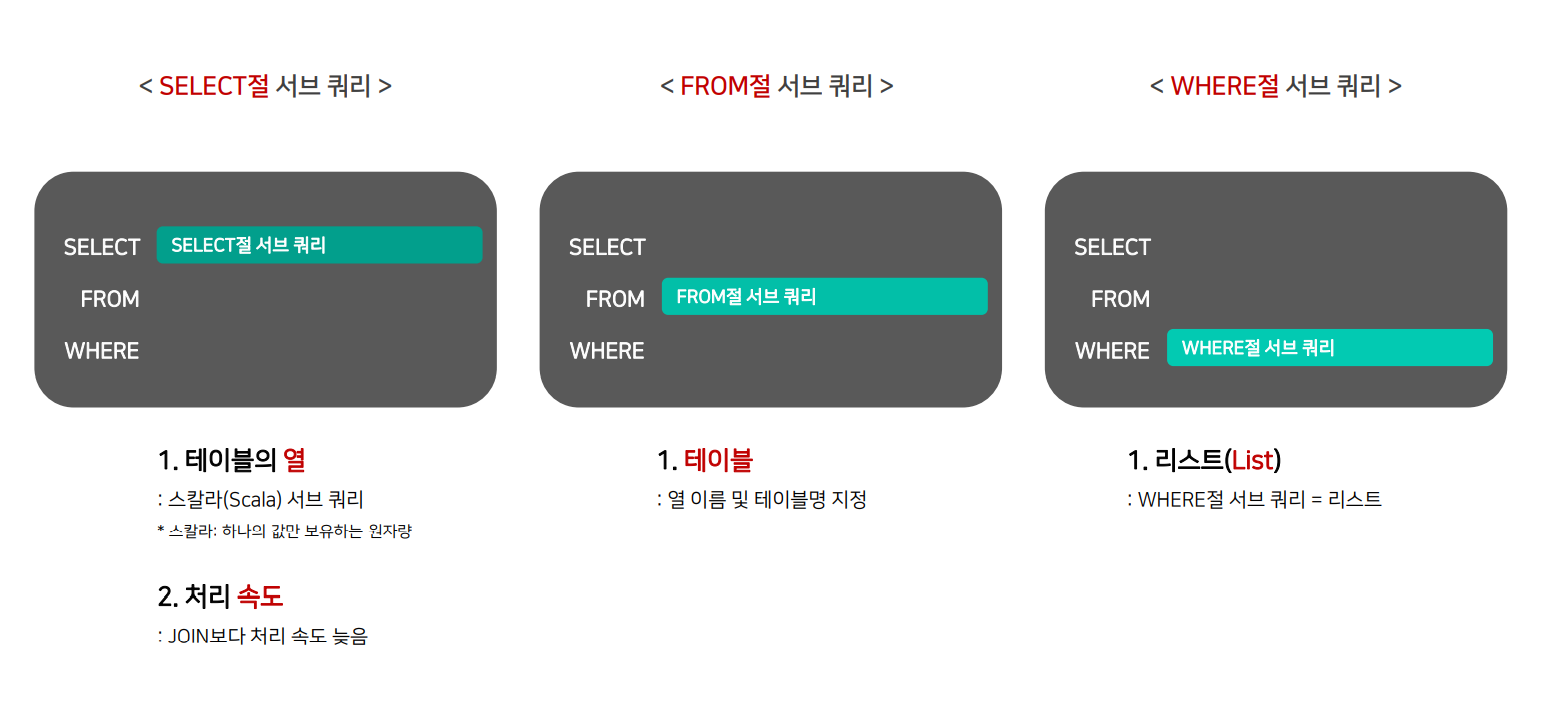
FROM customersSUBQUERY
쿼리문을 작성할 때 다른 쿼리문을 포함하는 것. 즉, 실행되는 쿼리에 중첩으로 위치해 정보를 전달합니다. 서브쿼리는 소괄호로 감싸져 있습니다.서브쿼리의 결과는 개별값들이나 레코드 리스트를 돌려줄 수 있고 그 결과를 하나의 칼럼으로 활용할 수 있습니다.
SELECT customers.LastName ,
(SELECT COUNT(*) FROM invoices WHERE customers.CustomerId = invoices.CustomerId) AS InvoiceCount
FROM customers;# JOIN으로 변경
SELECT c.LastName , COUNT(*) AS invoceCount
FROM customers c
JOIN invoices i
ON c.CustomerId == i.CustomerId
GROUP BY c.CustomerId;이제부터는 서브쿼리를 어떻게 사용할 수 있는지 더 자세히 알아보겠습니다.
IN, NOT IN
SELECT *
FROM customers
WHERE CustomerId IN (SELECT invoices.CustomerId FROM invoices WHERE invoices.Total < 1 );FROM
SELECT *
FROM (
SELECT CustomerId
FROM customers
WHERE CustomerId < 10
)
SQL vs Pandas
- Pandas = 데이터 분석 및 조작을 위한 Python 라이브러리
- SQL = 데이터베이스와 통신하는 데 사용되는 프로그래밍 언어
-> 데이터 조회가 주 목적 (데이터 계산 등은 SQL이 Pandas보다 속도가 빠름)
대부분의 관계형 데이터베이스 관리 시스템 (RDBMS)은 SQL을 사용하여 데이터베이스에 저장된 테이블에서 작동합니다. 공통점은 Pandas와 SQL이 모두 테이블 형식 데이터(행과 열로 구성)에서 작동한다는 것입니다.
SELECT_데이터 선택
# pandas
tips[["total_bill", "tip", "smoker", "time"]]# SQL
SELECT total_bill, tip, smoker, time
FROM tips;LIMIT_rows 제한
# pandas
tips.head(10)# SQL
SELECT *
FROM tips
LIMIT 10;LIMIT OFFSET_rows, columns 제한
# pandas
tips.iloc[3:8, :]# SQL
SELECT *
FROM tips
LIMIT 5 OFFSET 3;UNIQUE_고유값
# pandas
tips.day.unique()# SQL
SELECT DISTINCT day
FROM tips;NUNIQUE_고유값 개수
# pandas
tips.day.nunique()# SQL
SELECT COUNT(DISTINCT day)
FROM tips;WHERE_rows 조건부 필터링
== / =
# pandas
tips[tips.sex == "Female"][["tip", "smoker"]][:5]# SQL
SELECT tip, smoker
FROM tips
WHERE sex = 'Female'
LIMIT 5; & / AND
# pandas
tips[(tips["time"] == "Diner") & (tips["tip"] > 5.00)]# SQL
SELECT *
FROM tips
WHERE time = 'Dinner' AND tip > 5.00;| / OR
# pandas
tips[(tips["size"] >= 5) | (tips["total_bill"] > 45)]# SQL
SELECT *
FROM tips
WHERE size >= 5 OR total_bill > 45;DIVISION_Column 연산 및 생성
# pandas
tips["tip_rate"] = tips["tip"] / tips["total_bill"]# SQL
SELECT tip/total_bill AS tip_rate
FROM tips;VALUE COUNTS_고유값과 개수
# pandas
tips.day.value_counts()# SQL
SELECT day, COUNT(day) AS 'count'
FROM tips
GROUP BY day;GROUP BY_Column별 그룹화
groupby
# pandas
tips.groupby('sex').count()# SQL
SELECT sex, COUNT(*)
FROM tips
GROUP BY sex;groupby.agg
# pandas
tips.groupby("day").agg({"tip": np.mean, "day": np.size})# SQL
SELECT day, AVG(tip), COUNT(*)
FROM tips
GROUP BY day;# pandas
tips.groupby(["smoker", "day"].agg({"tips" : [np.size, np.mean]}))# SQL
SELECT smoker, day, COUNT(*), AVG(tip)
FROM tips
GROUP BY smoker, day;Null Value_결측치
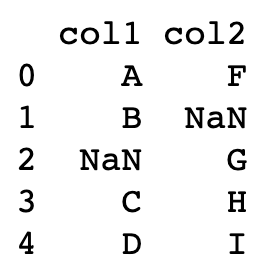
isna / IS NULL
# pandas
frame[frame["col2"].isna()] # SQL
SELECT *
FROM frame
WHERE col2 IS NULL;notna() / IS NOT NULL
# pandas
frame[frame["col1"].notna()]# SQL
SELECT *
FROM frame
WHERE col1 IS NOT NULL;merge/JOIN_데이터 합치기
df1)

df2)

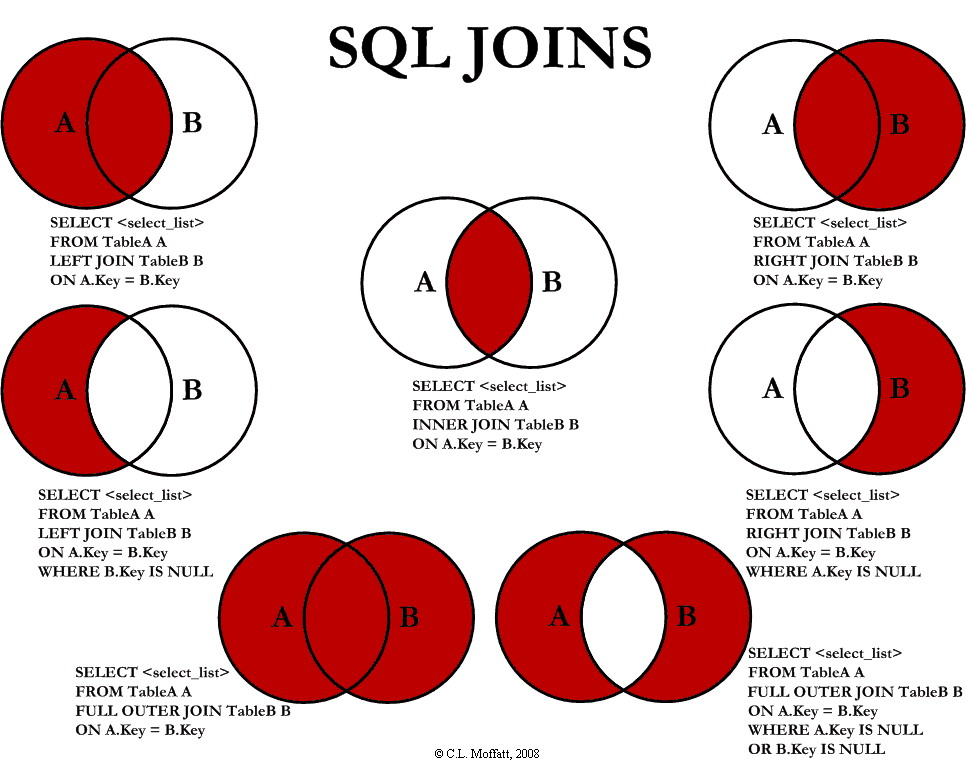
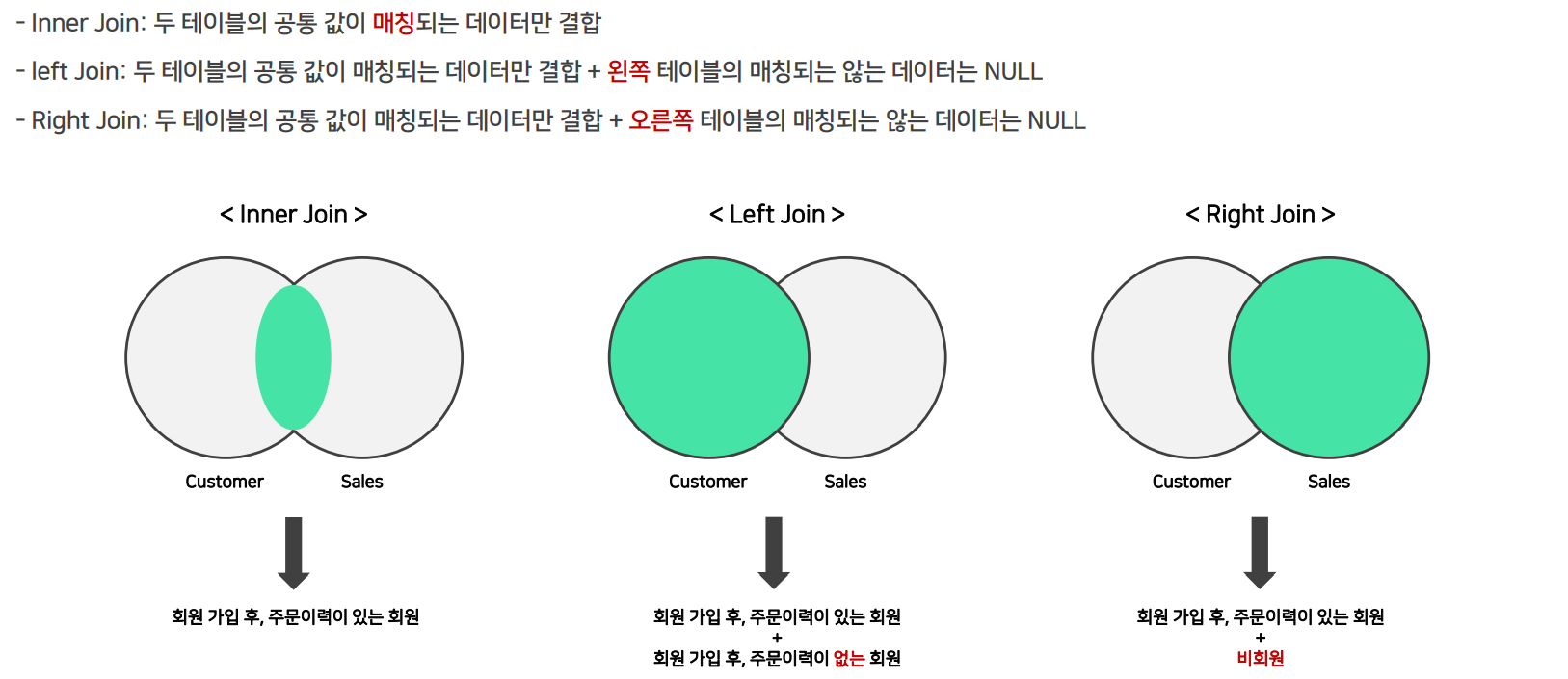
merge_on / INNER JOIN
# pandas
pd.merge(df1, df2, on="key")# SQL
SELECT *
FROM df1
INNER JOIN df12
ON df1.key = df2.key;merge_how="left" / LEFT JOIN
# pandas
pd.merge(df1, df2, on="key", how="left")# SQL
SELECT *
FROM df1
LEFT OUTER JOIN df2
ON df1.key= df2.key;merge_how="outer" / OUTER JOIN
# pandas
pd.merge(df1, df2, on="key", how="outer")# SQL
SELECT *
FROM df1
FULL OUTER JOIN df2
ON df1.key = df2.key;concat/UNION_데이터 세로 합치기
SQL에서는 합치는 두 데이터프레임의 열이 반드시 같아야 합니다. 만약 다를 경우 error가 발생합니다. 반면 pandas에서는 자동적으로 null을 생성하여 열이 동일하지 않더라도 합쳐줍니다.
df1)

df2)

# pandas
pd.concat([df1, df2])# SQL
SELECT city, rank
FROM df1
UNION ALL
SELECT city, rank
FROM df2만약 두 데이터 프레임을 세로로 합친 다음 중복되는 값들을 제거 하고자 한다면 pandas는 dop_duplicates() 함수를, SQL은 UNION ALL이 아닌 UNION을 이용하면 됩니다.
# pandas
pd.concat([df1, df2]).drop_duplicates()# SQL
SELECT city, rank
FROM df1
UNION ALL
SELECT city, rank
FROM df2