#리스트 #딕셔너리 #반복문 #조건문
학습 목표
- 파이썬의 기본 문법을 활용할 수 있어야 합니다.
- 소스코드를 통해 파이썬에서 사용되는 데이터 타입을 활용할 수 있어야 합니다.
- 컬렉션 자료형(리스트, 딕셔너리) 활용할 수 있어야 합니다.
- 간단한 파이썬 코드를 작성할 수 있어야 합니다.
파이썬
연산자
+: 덧셈-: 뺄셈*: 곱셈/: 몫 구하기//: 정수형 몫 구하기**: 거듭제곱%: 나머지 구하기
### 기본 연산
print(30 + 6)
print(40 - 4)
print(6 * 6)
print(72 / 5)
print(72 // 5)
print(6**2)
print(36 % 34)Values and Types(값과 타입)
# 파이썬의 모든 자료형은 클래스로 구현되었기 때문에, 클래스 이름이 자료형이다.
type(6)
>>>> <class 'int'>
type(36.0)
>>>> <class 'float'>
type('Hello, World!')
>>>> <class 'str'>
type([cat, dog])
>>>> <class 'list'>Error
- IndentationError : 들여쓰기 오류
- SyntaxError : 문법 오류
- KeyboardInterrupt : python 코드 실행시 Ctrl + C를 누를 때 발생
- TypeError : 연산이나 함수가 부적절한 형의 객체에 적용될 때
- ZeroDivisionError : 나누기 또는 모듈로 연산의 두 번째 인자가 0일 때 발생
주석(Comments)
주요 클래스, 함수의 기능과 변수에 대한 명명규칙, 소스코드 작성날짜 및 수정날짜를 위주로 작성하는 것을 권장한다.
- 공식적인 주석(외부제출용)인 경우, 구어체가 아닌 형태로 핵심적인 부분만 주석을 작성한다.
- 내부공유용이거나 설명을 위한 소스코드인 경우, 재사용과 내용공유를 목적으로 하여 용어에 대한 풀이 및 이해 내용을 상세히 적는다.
# 실제 예시(외부에서 사용된 소스코드)
import matplotlib.pyplot as plt # pyplot : interactive plots and simple cases
# Look at index 4 and 6, which demonstrate overlapping cases.
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
# Colors: https://matplotlib.org/api/colors_api.html, 외부 url 참조시
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot() # 시각화 1단계
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend() # 시각화 2단계 - 범례 추가
plt.show() # 시각화 3단계 - 그림형태로 표시반복문(for, while)
for + 생성되는 신규변수 또는 입력변수 + in range() 또는 컬렉션변수 + :
### 입력변수
y = int(input())
for i in range(y,5):
print(i)
### 리스트변수
y = [1,3,3]
for i in y:
print(i)
### set변수
y = {1,3,3}
for i in y:
print(i)
### 튜플변수
y = (1,3,3)
for i in y:
print(i)
### 딕셔너리변수
y = {'a':1,'b':3,'c':3}
for i in y:
print(i)
### 신규변수 x
for x in range(5):
print(x)
for x in range(2, 7):
print(x)
for x in range(1, 8, 2):
print(x)
### while
count = 0
while count < 5:
print(count)
count += 1
### break
count = 0
while True:
print(count)
count += 1
if count >= 5:
break # 조건에 맞는 경우 break을 통해 조건문과 반복문에서 탈출.
### continue
for x in range(8):
# x를 2로 나눴을때 나머지가 0이면(조건문 == 참), x값은 그대로 (+)하면서 반복문부터 재시작.
if x % 2 == 0:
continue
print(x)연산자 / 조건문 / 중첩조건
### Boolean Expressions(부울식)
print(2 == 2) # True
print(4 == 8) # False
print(type(True)) # <class 'bool'>
print(type(False)) # <class 'bool'>
### Logical Operators(논리 연산자)
print(True and True) # True
print(True and False) # False
print(False and False) # False
print(True or False) # True
print(True or True) # True
print(False or False) # False
print(not True) # False
print(not False) # True
### Conditional Execution(조건 연산자)
x = -4
if x < 0:
print('x is negative')
### Chained Conditionals(다중 조건문)
x = 2
y = -3
if x < y:
print('x is less than y')
elif x > y:
print('x is greater than y')
else:
print('x and y are equal')
### Nested Conditionals(중첩조건)
x, y = 3, 5
if x == y:
print('x and y are equal')
else:
if x < y:
print('x is less than y')
else:
print('x is greater than y')파이썬 기본 자료구조
컬렉션 자료형
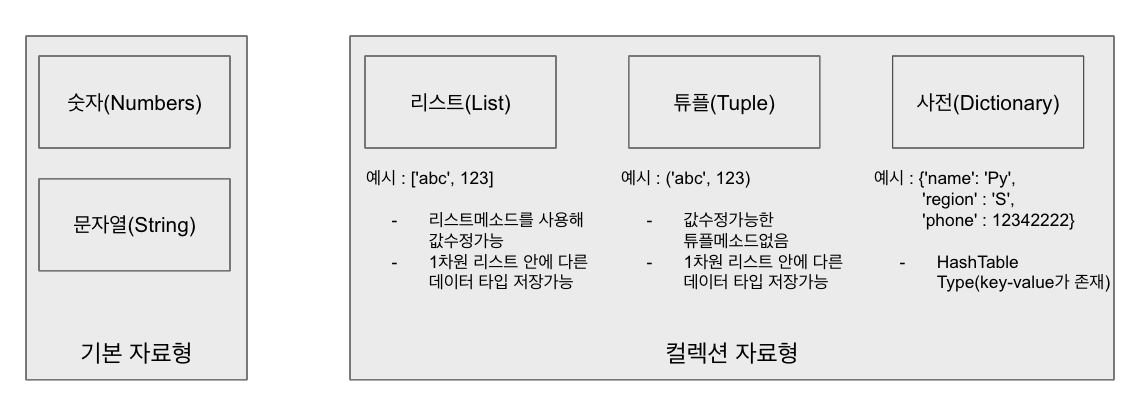
컬렉션 자료형의 특징에 따라 리스트, 튜플, 셋, 딕셔너리로 구분된다. 기본 자료형(문자열, 숫자, bool)이 특정 하나의 값을 사용하는 반면 컬렉션은 여러 개의 값을 저장할 수 있다.
- 데이터 순서를 동적으로 조절하려면, 리스트 사용을 권장.
- 키와 값에 따른 데이터를 효율적으로 보려면, 딕셔너리 사용을 권장.
리스트(list)
- 인덱스와 메소드를 활용하기때문에 동적으로 값의 수정 및 정렬이 쉽다.
( 동적=메소드를 사용해 값을 추가하거나 제거 가능한 것 ) - 대괄호를 통해 생성한다. ex)
[ and ] - 연산에 대한 메소드(탐색, 삽입, 삭제)를 갖고 있으므로 단순 자료형이 아닌 자료구조의 형태를 취한다.
- 값을 여러개 저장할 수 있는 기능인 배열의 기능 또한 갖고 있다.
- 다양한 타입의 요소들을 한번에 포함할 수 있으며 심지어는 함수, 클래스, 모듈 같은 복잡한 객체도 포함할 수 있다.
- 다차원 리스트 : 리스트안에 리스트를 넣을 수 있다.(게임개발, 대규모 머신러닝 알고리즘에서 사용)
- 배열과 같이 배열의 특징인 핵심 연산(생성, 인덱스를 통한 접근, 인덱스를 통한 할당, 반복)을 지원하므로 중요하다.
string[ : ]vslist[ : ]### string : returns a reference to the same object s = 'foobar' s[:] >>>'foobar' s[:] is s >>>True### list : copy of list a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] a[:] >>>['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] a[:] is a >>>False
리스트 메소드
append(<obj>)리스트 마지막에 새로운 값 추가
arr = ['math', 'biology', 1989, 2019] arr.append(2021) arr >>> ['math', 'biology', 1989, 2019, 2021]* append() + math 모듈
import math center = 10 height = 20 value = [] # 문자열값을 입력받음 items=[string for string in input().split(',')] # element = 1부터 시작함 for element in items: value.append( str( int( round( math.sqrt( 2 * center * float(element) / height ) ) ) ) ) print(items,element) print(','.join(value))* append와 정규표현식을 활용한 비밀번호 구성하기
# 정규표현식 -> module: re import re # Support for regular expressions (RE). value = [] items = [index for index in input().split(',')]# 비밀번호 구성로직 for pw in items: if len(pw) < 6 or len(pw) > 12: continue else: pass if not re.search("[a-z]",pw): continue elif not re.search("[0-9]",pw): continue elif not re.search("[A-Z]",pw): continue elif not re.search("[$#@]",pw): continue elif re.search("\s",pw): continue else: pass value.append(pw) print(",".join(value))
extend(<iterable>)리스트끼리 이어붙이기
arr_one = [1, 2, 3, 4, 5] arr_two = [1, 2, 3] arr_one.extend(arr_two) arr_one* concatentaion operator :
+or+=
a list must be concatenated with an object that is iterable.
*iterable : 반복 가능한 것을 의미한다. 대표적인 iterable한 타입은 list, tuple, set, dict, str, bytes, range가 있다. 즉, 반복 연산이 가능하며 요소를 하나씩 리턴할 수 있는 객체를 의미한다.### concatenate noniterable a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] a += 20 >>> Traceback (most recent call last): File "<pyshell#58>", line 1, in <module> a += 20 TypeError : 'int' object is not iterable### concatenate strings(iterable) a = ['foo', 'bar', 'baz', 'qux', 'quux'] a += 'corge' a >>> ['foo', 'bar', 'baz', 'qux', 'quux', 'c', 'o', 'r', 'g', 'e']### concatentae list(iterable) a = ['foo', 'bar', 'baz', 'qux', 'quux'] a += ['corge'] a >>> ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
insert(<index>, <obj>)리스트 중간에 인덱스와 값을 지정하여 값을 추가삽입
arr_in = ['math', 'biology', 1989, 2019] arr_in.insert(1,2021) arr_in >>> ['math', 2021, 'biology', 1989, 2019]
del list[<index>]제거할 항목의 인덱스에 따라 삭제
arr_del = [1, 2, 3, 4, 5] del arr_del[0] arr_del >>> [2, 3, 4, 5]arr_del = [1, 2, 3, 4, 5] arr_del[1:3] = [] arr_del >>> [3, 4, 5]
remove(<obj>)
- (인덱스가 아니라) 삭제할 항목의 값을 알고 있어야 함
- 중복 값이 있을 경우, 인덱스 순서에 따라 앞 순서에 있는 값만 삭제
arr = [1, 2, 3, 4, 5] arr.remove(2) arr >>> [1, 3, 4, 5]arr_1 = [1, 2, 3, 4, 5,1,1,1] arr_1.remove(1) arr_1 >>> [2, 3, 4, 5,1,1,1]
pop(<index(default-1)>)리스트에서 특정 위치의 값을 빼내는 기능
pop()- 맨 뒤부터 하나씩 빼냄pop(<index>)- 해당 인덱스 값 빼냄arr_pop = [1, 2, 3, 4, 5, 8, 9, 10] p_1 = arr_pop.pop() # pop 이후 리스트 print(arr_pop) >>> [1, 2, 3, 4, 5, 8, 9] # pop한 값 print(p_1) >>> 10p_2 = arr_pop.pop() # 두번째 pop 이후 리스트 print(arr_pop) >>> [1, 2, 3, 4, 5, 8] # 두번째 pop한 값 print(p_2) >>> 9p_3 = arr_pop.pop(1) # index=1에서 pop한 이후 리스트 print(arr_pop) >>> [1, 3, 4, 5, 8] # index=1에서 pop한 값 print(p_3) >>> 2
sum(<list>)리스트 내부 값의 총합
arr = [1, 2, 3, 4, 5] sum(arr) >>> 15
count(<obj>)리스트안에 특정 값의 갯수
arr = [1, 1, 1, 2, 3] print(arr.count(1)) print(arr.count(2)) print(arr.count(3))
len(<list>)리스트 길이
arr = [1, 2, 3, 4, 5] len(arr)
index(<index>, <start>, <end>)리스트 범위에서 특정 값의 인덱스 반환
arr_two = ['a', 'b', 'c', 'd', 'e', 'a', 'b'] # arr_two[1:]에서 'a'의 index print(arr_two.index('a', 1)) >>> 5 # arr_two[1:3]에서 'b'의 index print(arr_two.index('b', 1, 3)) >>> 1
min(<list>)리스트 최소값
# 숫자 arr = [4, 3, 2.5, 7, 0.7, 9] min(arr) >>> 0.7 # 글자 : 순서와 대소문자 확인 arr = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] min(arr) >>> 'bar' arr = ['jimin', 'Jimin'] min(arr) >>> 'Jimin'
sort(<reverse(default=False)>)리스트의 값 자체의 순서를 정렬
# 오름차순 arr = [4, 3, 2.5, 7, 0.7, 9] arr.sort() print(arr) >>> [0.7, 2.5, 3, 4, 7, 9]# 내림차순 arr.sort(reverse=True) print(arr) >>> [9, 7, 4, 3, 2.5, 0.7]=> arr의 순서자체가 바뀜
sorted(<list>, <reverse>)리스트 자체의 순서는 유지하고, 정렬된 순서로 출력만 함
arr = [4, 3, 2.5, 7, 0.7, 9] print(sorted(arr, reverse=True)) >>> [9, 7, 4, 3, 2.5, 0.7] print(arr) # 주어진 arr은 그대로 유지되어 있음 >>> [4, 3, 2.5, 7, 0.7, 9]
튜플(tuple)
튜플은 리스트와 기능은 비슷하게 값을 저장하지만 특정 값과 인덱스에 대한 값 변경은 불가능하다.
*immmutable : 변경 불가능, mutable : 변경 가능
튜플 메소드
count(<obj>)튜플 내 해당 객체가 몇 개인지 세는 기능
# 4가 몇개인지 my_tuple = (1, 3, 4, 5, 2, 3, 4, 6, 7, 2) my_tuple.count(4) >>> 2
index(<obj>)특정 값의 인덱스를 알려주는 기능
my_tuple = (1, 3, 7, 2, 7, 5, 3, 2, 9, 3) my_tuple.index(7) >>> 2
딕셔너리(dictionary)
- 키를 기반으로 값을 저장한다.(내부적으로 해시테이블로 구현되어 있음)
- 주의사항 : 파이썬 3.6 이하에서는 딕셔너리가 해시테이블로 구현된 자료형이기 때문에, 입력 순서를 고려하지 않는다.
- 그래서 파이썬 3.6 이하에서는 OrderedDict라는 별도의 object를 제공한다.
- 개발환경을 고려하면서 딕셔너리를 활용해야 한다.
### 파이썬 버전 확인
>>> import sys
>>> print(sys.version)
3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)]
### OrderedDict
from collections import OrderedDict
dict_test = {'test':1, 'test2':5, 'gui':4, 'black':2}
# dict_test : OrderedDict 활용하지 않는 경우, 키를 기준으로 정렬됨
# OrderedDict(dict_test) : OrderedDict 활용하는 경우, 입력 그대로 순서 유지### 딕셔너리 선언 형식
eng_sp = dict() # 방법1
eng_sp = {} # 방법2
eng_sp['one'] = 'uno'
eng_sp
>>>{'one': 'uno'}
eng_sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}딕셔너리 메소드
clear()car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.clear() print(car) >>> {}
copy()car = { "brand": "Honda", "model": "CR-V", "year": 2002 } carbon_copy = car.copy() print(carbon_copy) >>> {'brand': 'Honda', 'model': 'CR-V', 'year': 2002}
fromkeys(<list of key>, <list of value>)딕셔너리 생성 메소드
# key값만 생성 x = ('name', 'age', 'sex') dict_without_values = dict.fromkeys(x) print(dict_without_values) >>> {'age':None, 'name':None, 'sex':None}# key값과 value값 모두 생성 dict_with_values = dict.fromkeys(x, 10) print(dict_with_values) >>> {'age':10, 'name':10, 'sex':10}
get(<key>)key값으로 value값 찾기
car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.get("model") >>> "CR-V"
items()key와 value를 한꺼번에 for문을 반복하려면 items() 사용
for key, val in a.items(): print("key = {key}, value={value}".format(key=key,value=val)) >>> key = alice, value=[1, 2, 3] key = bob, value=20 key = tony, value=15 key = suzy, value=30
keys()key값만 가져오기
car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.keys() >>> dict_keys(['brand', 'model', 'year'])
values()value값 출력
car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.values() >>> dict_values(['Honda', 'CR-V', 2002]) # value값 변경 car["color"] = "black" car >>> {'brand': 'Honda', 'model': 'CR-V', 'year': 2002, 'color': 'black'}
pop()car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.pop("model") >>> "CR-V"
popitem()(key, value) 쌍을 제거하고 돌려줍니다.
car = { "brand": "Honda", "model": "CR-V", "year": 2002 } car.popitem() >>> ('year', 2002)car["price"] = 4000 print(car) >>> {'brand': 'Honda', 'model': 'CR-V', 'price': 4000}
setdefault(<key>, <default>)key 가 딕셔너리에 있으면 해당 값을 돌려줍니다. 그렇지 않으면, default 값을 갖는 key 를 삽입한 후 default 를 돌려줍니다.
car = { "brand": "Honda", "model": "CR-V", "year": 2002 } # key가 기존에 존재하는 경우 : 해당 value 출력 car.setdefault("model", "Odyssey") >>> CR-V # 새로운 key일 경우 : 해당 (<key>, <default>) 추가 후 default 출력 car.setdefault("color", "black") >> black
update(<dict>)딕셔너리 여러 값 수정
a = { 'alice': [1, 2, 3], 'bob': 20, 'tony': 15, 'suzy': 30 } a.update({'bob':99, 'tony':99, 'kim': 30}) a >>> {'alice': [1, 2, 3], 'bob': 99, 'tony': 99, 'suzy': 30, 'kim': 30}
디버깅 (debugging)
프로그램 상에서 어떤 오류가 있다던지 문법적 실수가 있어 우리가 원하는 대로 프로그램이 실행하지 않을 때 '버그(bug)가 있다'고 표현하고 그 버그를 하나씩 잡아 나가는 과정을 디버깅(debugging)이라고 합니다.
import pdb
# 아래 함수 실행
pdb.set_trace()
# 파이썬 3.7 이상
breakpoint()=> 다음 set_trace 함수로 넘어가기 위해서는 즉, 다음 디버깅 줄까지 넘어가는 것은 n을 입력하여 할 수 있습니다.
