#크롤링 #웹 스크레이핑 #HTML #CSS #DOM #beautifulsoup 라이브러리 #parser #requests 라이브러리
학습 목표
- 크롤링을 이해하고 설명할 수 있다.
- 파이썬을 통해서 크롤링을 할 수 있다.
- HTML 혹은 CSS 를 읽을 수 있다.
- DOM 에 대해서 설명할 수 있다.
- requests 라이브러리를 사용할 수 있다.
- beautifulsoup 라이브러리를 사용할 수 있다.
HTML
- HyperText Markup Language 의 약자로 웹 페이지가 어떻게 구성되는지 알려주는 마크업 언어
head,body,div,li등 다양한 요소(element)로 이루어짐- 각 엘레멘트들은 열어주는 태그(opening tag)와 닫아주는 태그(closing tag)를 통해 표현이 되는데, 요소에 따라 열어주는 태그만 사용할 때도 있다.
ex)<head></head>,<br>,<hr> - HTML Children : 하나의 HTMI 요소 안에 다른 요소를 추가할 수 있다.
<ul>
<li>Hello</li>
<li>World</li>
<li>!</li>
</ul>CSS
- Cascading Style Sheets 의 약자로 웹 페이지 문서가 어떻게 표현되는지 알려주는 스타일시트 언어
- 특정 요소를 선택할 수 있는 셀렉터(Selector)들로 이루어짐
- Type selector: CSS 타입에 따라서 선택 (예를 들어 'p', 'div' 등)
- Class selector: 클래스에 따라 선택
- Id selector: id 에 따라 선택
이러한 셀렉터들을 활용하게 되면 더 쉽게 원하는 요소들을 선택해 접근할 수 있다. - CSS 는 요소의 위치에 따라 상위 요소의 스타일을 상속받도록 되어 있다.
<div style="color:red">
<p>I have no style</p>
</div>
# p 태그는 아무런 스타일이 적용이 되어 있지 않지만 상위 요소인 div 의 영향을 받게 된다.- 클래스는 어떤 특정 요소들의 스타일을 정하고 싶을 때에 사용이 되며 동시에 여러 개의 요소들에 대한 스타일을 정할 때에는 보통 클래스를 지정해서 상속을 받도록 정한다.
# 클래스 정의1
<p class="banana">I have a banana class</p>
# 클래스 정의2_스타일 적용(.)
.banana {
color:"yellow";
}위처럼 한번에 여러 클래스를 동시에 부여할 수 있으며 CSS에서는 따로따로 클래스를 정의해 스타일을 지정할 수 있다.
- CSS ID
# ID 지정1
<p id="pink">My id is pink</p>
# ID 지정2_스타일 적용(#)
#pink {
color:"pink";
}ID 도 클래스와 동일하게 정해진 스타일을 HTML 요소에 적용할 수 있고 여러 개의 HTML 요소에도 동일한 ID 를 부여할 수 있다. 다만 ID는 여러 개의 요소에 사용 되는 클래스와 달리 보통 특정 HTML 요소를 가리킬 때에만 사용이 된다.
DOM(Documt Object Model)
HTML, XML 등 문서의 프로그래밍 인터페이스로 프로그래밍 언어를 통해 HTML 문서 등에 접근할 수 있도록 해주는 문서 객체 모델이다. DOM은 문서를 하나의 구조화된 형식으로 표현을 하기 때문에 이러한 구조를 통해 웹 페이지의 요소나 스타일 등을 추가하거나 수정하는 등의 다양한 작업 및 기능을 구현해낼 수 있다.
DOM은 자바스크립트의 데이터 구조 중 하나인 객체(object)로 표현을 하는데 파이썬에서는 이와 비슷한 dictionary가 존재한다. 즉, DOM을 통해 프로그래밍 언어에서 사용할 수 있는 데이터 구조 형태로 작업을 수행할 수 있는 것이다.
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1>h1 태그입니다.</h1>
<p>p 태그입니다.</p>
</body>
</html>DOM은 위의 HTML 구조에서 메소드를 사용해 내부의 정보에 대한 작업을 보다 원활하게 진행할 수 있다.
DOM 메소드
DOM을 사용해볼 수 있는 방법은 웹 브라우저에서 개발자 도구를 열어 콘솔 창으로 들어가 자바스크립트를 통해 사용하는 것이다.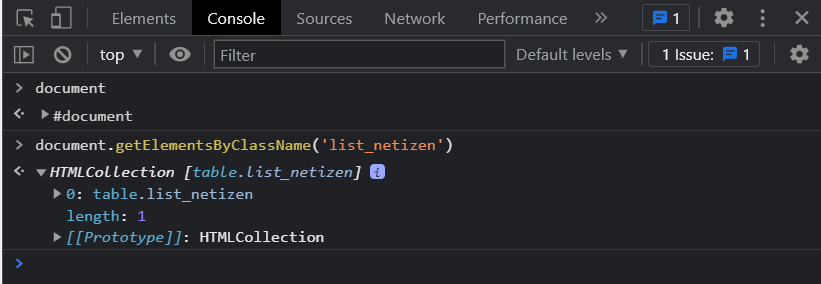
getElementsbyTagName: 태그 이름으로 문서의 요소들을 리턴합니다.getElementById: 'id' 가 일치하는 요소들을 리턴합니다.getElementsByClassName: '클래스' 가 일치하는 요소들을 리턴합니다.querySelector: 셀렉터(들)과 일치하는 요소를 리턴합니다.querySelectorAll: 셀렉터(들)과 일치하는 모든 요소들을 리턴합니다.
[javascript.info] getElement, querySelector로 요소 검색하기
Web Scraping
웹 스크레이핑/크롤링
- 웹 크롤링 : 웹에서 사이트들을 방문하며 필요한 정보를 수집하는 행위로 자동화에 초점이 맞춰져 있고 주로 인터넷에 있는 사이트들을 인덱싱하는 것이 목적
- 웹 스크레이핑 : 크롤링과 비슷하지만 특정 정보를 가져오는 것이 목적
request_요청
파이썬에서 HTTP 요청을 보낼 때 거의 표준으로 사용되는 라이브러리
# 라이브러리 설치
pip install requests
# 라이브러리 불러오기
import requests
# 웹에 HTTP 요청 보내기
requests.get('https://google.com')response_응답
.status_code.raise_for_status.text
# 응답 성공여부1
resp.status_code
# 정상적으로 연결되었을 경우 해당 HTTP 응답 객체 리턴 : <Response [200]>
# requests 라이브러리의 Response 타입 : <class 'requests.models.Response'>
# 응답 성공여부2
import requests
from requests.exceptions import HTTPError
url = 'https://google.com'
try:
resp = requests.get(url)
resp.raise_for_status()
except HTTPError as Err:
print('HTTP 에러가 발생했습니다.')
except Exception as Err:
print('다른 에러가 발생했습니다.')
else:
print('성공')
# 응답 내용 : HTML 파일
resp.textparsing_파싱
파싱 (parsing) 이란 문자열로 구성된 특정 문서들 (HTML, XML) 등을 파이썬에서도 쉽게 사용할 수 있도록 변환해주는 작업
page.contenthtml.parserXMLorHTML parser(ex.html5lib)-> install 필요
# BeauitifulSoup 라이브러리 설치
pip install beautifulsoup4
import requests
from bs4 import BeautifulSoup
url = 'https://google.com'
page = requests.get(url) # 파싱할 페이지 받아오기
soup = BeautifulSoup(page.content, 'html.parser') # 문자열 변환find_element 찾기
find: 한 개의 요소를 찾을 때, 조건에 일치하는 첫번째 결과 리턴find_all: 여러 개의 요소들을 찾을 때, 조건에 일치하는 모든 결과 리턴
*class를 이용해 찾을 때에는 class가 아닌 뒤에 밑줄_을 추가해야 합니다. 추가하지 않게 되는 경우에는 파이썬의 class로 인식하게 되기 때문에 구별해줘야 합니다.
# class에 cat이 들어있는 모든 요소
cat_elements = soup.find_all(class_='cat')
# 더 세부적인 검색
cat_elements = soup.find_all(class_='cat')
for cat_el in cat_elements:
cat_el.find(class_='fish')
# 태그 활용
cat_div_elements = soup.find_all('div', class_='cat')
# string 활용
soup.find_all(string='raining') # 정확히 해당 문자열 포함해야함
# 문자열이 대소문자 구분없이 들어가 있는 것 찾기
soup.find_all(string=lambda text: 'raining' in text.lower())
# 하나의 요소로 받기 위해 태그 추가
soup.find_all('h3', string='raining')text_정보 얻기
text: 태그 내부 글을 얻기 위한 속성
<p class='cat'>This is a p-cat</p>cat_el = soup.find('p', class_='cat')
cat_el.text # 'This is a p-cat'
# 불필요한 띄어쓰기 정리
cat_el.text.strip()