
Stream이란?
다양한 데이터 소스(컬렉션/배열)을 표준화된 방법으로 다루기 위한 것.

원래 Collection Framework가 여러 데이터들을 같은 방법으로 다루기 위해서 만들어졌는데, List&Set/Map의 사용방법이 달라 아쉬웠다. 그래서 JDK 1.8부터는 Stream을 사용했다.
Stream 사용
데이터소스에 stream만들고 n번의 중간연산과 1번의 최종연산을 거쳐 결과를 낸다.
(stream이 나옴으로써, 연산 처리 방식이 같아졌다!)
1. 스트림 만들기
2. 중간 연산 - 연산결과가 스트림인 연산. 반복적으로 적용가능
3. 최종 연산 - 연산결과가 스트림이 아닌 연산. 단 한번만 적용가능(스트림의 요소를 소모)


Stream 특징
-
스트림은 데이터 소스로부터 데이터를 읽기만 할 뿐 변경하지 않는다. (ReadOnly)
-
스트림은 Iterator처럼 일회용이다. (필요하면 스트림을 다시 생성해야함)

-
최종 연산 전까지 중간연산이 수행되지 않는다 - 지연된 연산
( 최종 연산 전까지 어떤 연산이 수행될 지 체크해뒀다가 필요할 때 모두 연산함)

그림처럼 무한스트림이라면 distinct가 불가능하다고 생각할 것 같은데, 바로 처리하는 것이 아니라 모든 연산을 체크한 후 수행하기 때문에 가능하다 -
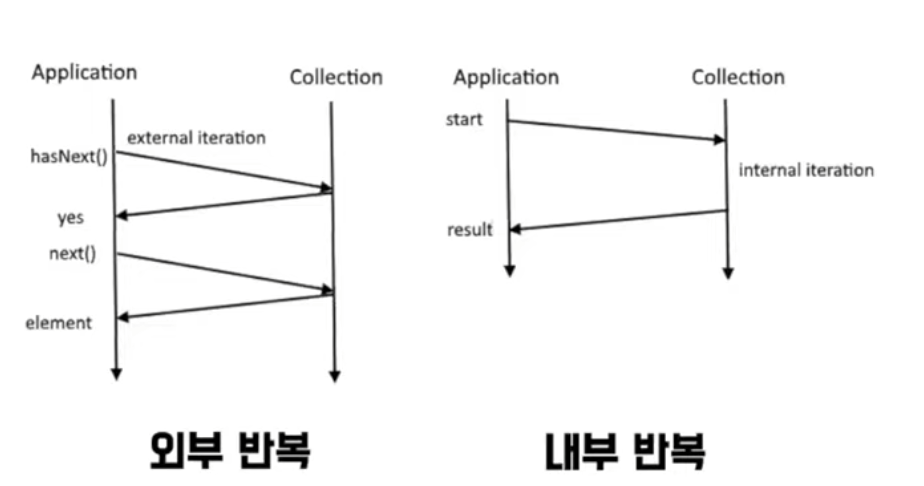
스트림은 작업을 내부 반복으로 처리한다.
-
스트림의 작업을 병렬로 처리한다. → 병렬 스트림(멀티스레드)

IntStream, LongStream, DoubleStream
- 오토박싱&언박싱의 비효율이 제거된다.
기본형 변수들도 스트림 변환을 거치게 되면 참조형으로 바껴서 연산된다. - 숫자와 관련된 유용한 메서드를 Stream< T>보다 더 많이 제공한다.
Stream의 장점
-
가독성이 좋다.
-
코드 변경이 쉽다.
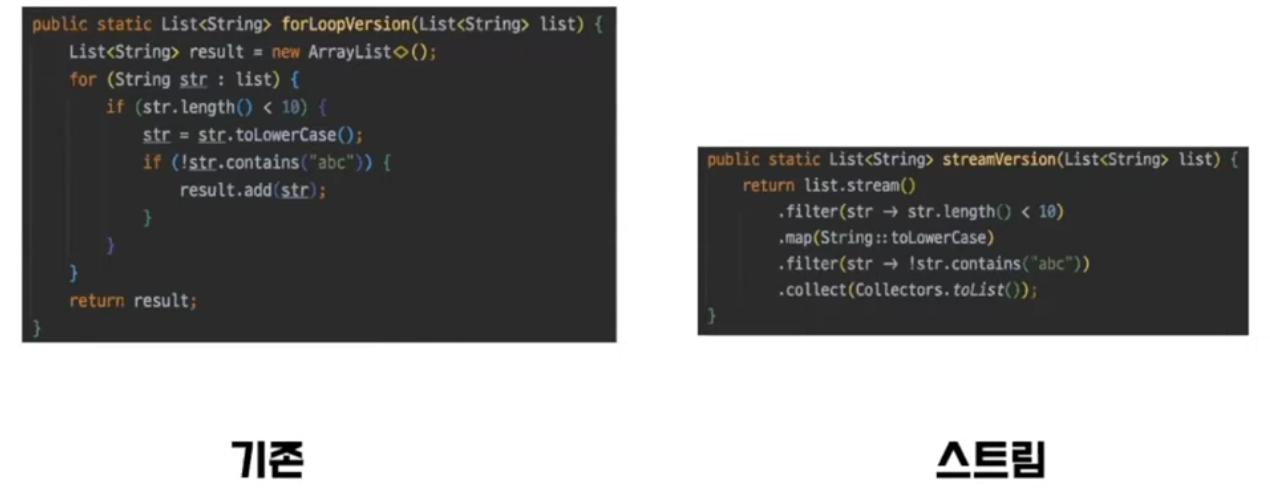
-
병렬처리를 간단하게 처리할 수 있다.
-
stream은 fork join framework를 사용한다.
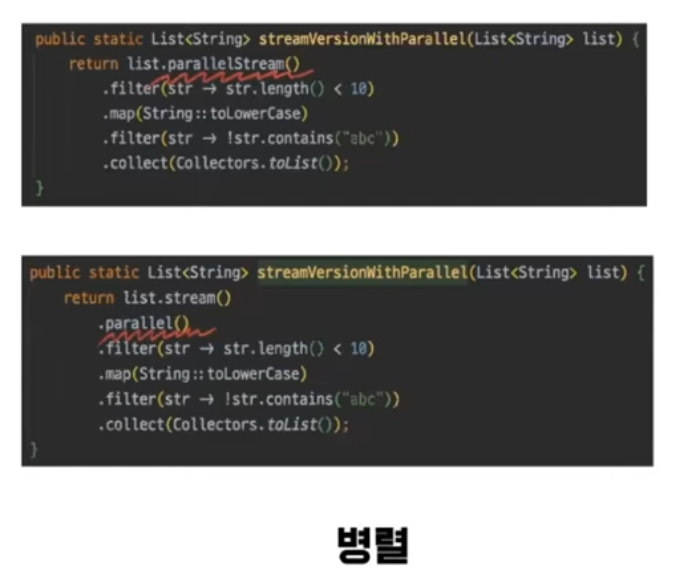
Stream의 단점
- for loop보다 상대적으로 시간이 많이 걸린다.
- 인지에 대한 비용도 많이 발생한다. 외부반복과 내부반복으로 나뉘는데, 내부 반복에서 문제가 발생할 시 정확한 문제를 알지 못한다는 단점이 있다.
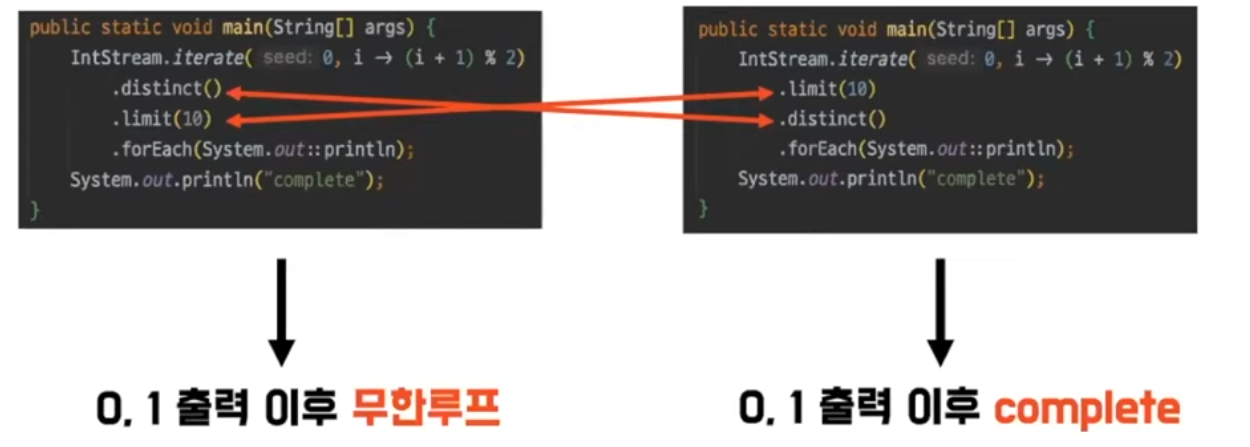
얼핏보면 비슷해보이지만, 왼쪽은 0과 1이 들어오고 나서는 다시 0과 1이 들어오면 발견한 적이 있으므로 limit으로 넘겨지지 않는다. 그러나 오른쪽은 limit을 10개로 걸어놓았기 때문에 해당 자료를 가지고 distinct로 넘어가 complete을 할 수 있다는 차이점이 있다.
이와 같이 순서만 바뀌어도 동작이 다르고 그것을 찾는 과정이 for-loop보다는 힘들기 때문에 단점이 될 수 있다.
Reference
https://www.youtube.com/watch?v=7Kyf4mMjbTQ
https://www.youtube.com/watch?v=rbm87IFpwvQ

stream 을 어떻게 구성하냐에 따라 for loop와 성능 우월이 가능할 것 같습니다.
박싱언박싱을 거쳐서 도출하는 형태가 아닌 구조로 stream 로직을 짜고, stream의 가장 문제인 중간연산을 멈추는것이 어렵다 인데, 이점을 고려하면 parallel로 로직 구성을 할 수 있는 stream이 더 빠를거라고 생각이 드네요