
IN-IT 프로젝트 DB 조회 횟수 줄이고, DB 레이어의 부하 분산과 빠른 응답을 위한 캐싱 레이어로 쓰려고 구현했다.
우리가 정한 방식은 Read Through + Write Through 방식이다.
Read Through
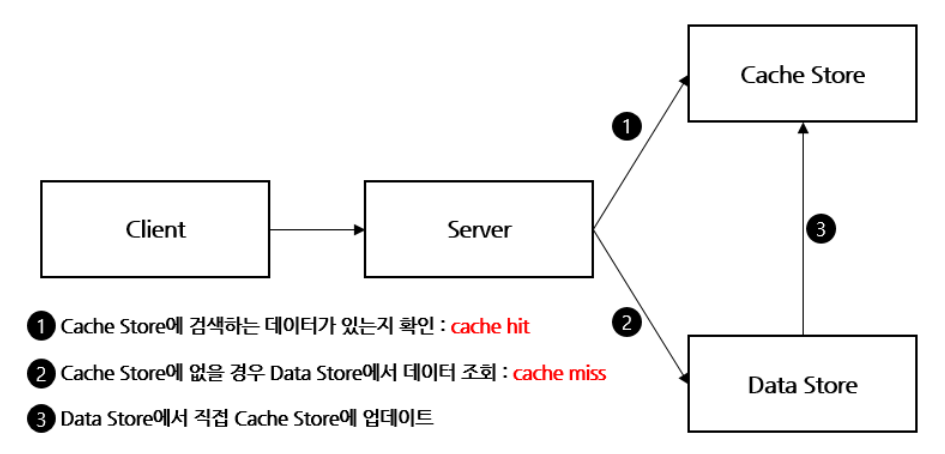
Write Through
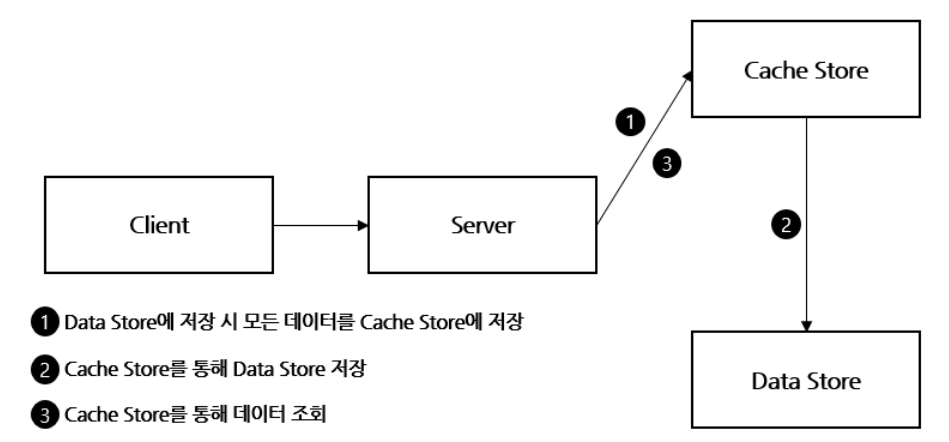
방식을 정한 이유는 다음과 같다.
- 데이터를 쓸 때, 항상 캐시에 먼저 쓰므로, 읽어올 때 최신 캐시 데이터를 보장할 수 있다.
- 데이터를 쓸때는 항상 캐시에서 DB로 보내므로, 데이터 정합성이 보장된다.
→ 다만, 캐시에 저장할 필요가 없는 데이터까지 cache에 저장되어 리소스 낭비 및 write 작업에 부하가 발생할 수 있다.
따라서, TTL을 통해 사용되지 않는 데이터를 반드시 삭제해야한다.
캐싱 방식을 정한 후에는, 캐시 속 데이터 조회/데이터 제거/데이터 공유(이 부분은 MSA와 같은 여러 인스턴스인 프로젝트일 때 확인 해야하는 정보)/가용성 및 성능 확보에 대해 생각해봤다.
🧐 캐시 조회
참고 블로그 : https://waspro.tistory.com/697
캐시 솔루션은 자주 사용되면서 자주 변경되지 않는 데이터의 경우 캐시 서버에 적용하여 반영할 경우 높은 성능 향상을 이뤄낼 수 있다.
→ 이 부분을 읽으며, 좋아요 기능은 자주 사용되는 데이터에 해당한다고 생각했다.
일반적으로 캐시는 메모리에 저장되는 형태를 선호한다. 디스크에 저장되는 방식은 기존 비휘발성 메모리와 크게 다르지 않기 때문에 메모리에 저장하여 성능 향상을 극단적으로 뽑아내는 환경을 구성하기를 원한다. 결국 자주 사용되는 데이터를 어떻게 뽑아 캐시에 저장하고 자주 사용하지 않는 데이터를 어떻게 제거해 나갈 것이냐를 지속적으로 고민해야 한다.
→ 제거에 관해서는 캐시 만료시간을 둬서 제거를 하면 된다고 생각했다. 그러나, 조회에 관해서는 "좋아요"는 사용자들의 중요 정보가 아니고,
한 사용자에 대해 [한 번의 좋아요 클릭] 혹은 [한 번의 좋아요 취소] 외에 반복되는 요청이 들어오지 않는 기능이라 생각해 추가적인 고민은 하지 않았다.
또한 한 가지 고민해야 할 사항은캐시 솔루션은 언제든지 데이터가 날라갈 수 있는 휘발성을 기본으로 한다는 점이다. 이는 데이터를 주기적으로 디스크에 저장할 수는 있지만, 실시간으로 모든 데이터를 디스크에 저장할 경우 성능 저하를 일으킬 수 있어 어느 정도 데이터 수집과 저장 주기를 갖게 된다. 즉 데이터의 유실 또는 정합성이 일정 부분 깨질 수 있다는 점을 항상 고려해야 한다.
→ 좋아요 기능은 일차적으로 사용자와 글의 정보 중 중요한 내용이 아니다.
따라서 캐시에 저장되는 데이터는 중요한 정보, 민감 정보 등은 저장하지 않는 것이 좋으며,
→ 좋아요 기능은 일단 사용자와 글의 정보 중 중요한 내용이 아니므로, 해당 사항에 대해 괜찮다.
캐시 솔루션이 장애가 발생했을 경우 적절한 대응방안을 모색해 두는 것이 바람직하다. (TimeOut, 데이터베이스 조회 병행 등)
→ Read Through + Write Through 방식은 데이터를 쓸때는 항상 캐시에서 DB로 보내므로, 캐시에서 장애가 발생해 데이터가 날라갈 때도, DB에 저장되어 있기 때문에 데이터 정합성이 보장된다.
🫥 캐시 제거
캐시 데이터의 경우 캐시 서버에만 단독으로 저장되는 경우도 있지만, 대부분 영구 저장소에 저장된 데이터의 복사본으로 동작하는 경우가 많다. 이는 2차 저장소(영구 저장소)에 저장되어 있는 데이터와 캐시 솔루션의 데이터를 동기화 하는 작업이 반드시 필요함을 의미하며, 개발 과정에 고려사항이 늘어난다는 점을 반드시 기억해야 한다.
→ 동기화를 고려한 캐싱 방식을 정했다.
예를 들어 캐시 서버와 데이터베이스에 저장되는 데이터의 커밋 시점에 대한 고려 등이 예가 될 수 있다. 캐시의 만료 정책이 제대로 구현되지 않은 경우 클라이언트는 데이터가 변경되었음에도 캐시된 오래된 정보를 사용할 수 있다.
→ write through는 캐시를 거쳐 DB로 저장이 되므로, 항상 최신 정보를 가지고 있다.
캐시를 구성할 때 기본 만료 정책을 설정할 수 있다. 캐시된 데이터가 만료 되면 캐시에서 제거 되고 응용 프로그램은 원래 데이터 저장소에서 데이터를 검색 해야 한다. 캐시 만료 주기가 너무 짧으면 데이터는 너무 빨리 제거되고 캐시를 사용하는 이점은 줄어든다. 반대로 너무 기간이 길면 데이터가 변경될 가능성과 메모리 부족 현상이 발생하거나, 자주 사용되어야 하는 데이터가 제거되는 등의 역효과를 나타낼 수도 있다.
→ 만료 주기에 대한 고찰은 좀 더 해봐야한다는 생각이 들었다. 만료주기를 적게 하니, Redis를 쓰는 의미가 없었고, 길게 하면 쉽게 메모리가 부족한 현상을 확인할 수 있었기 때문이다.
😜 가용성 및 성능 확보
캐시를 구성하는 목적은 빠른 성능 확보와 데이터 전달에 있으며, 데이터의 영속성을 보장하기 위함이 아니라는 점을 기억하고 설계해야 한다.
데이터의 영속성은 기존 데이터 스토어에 위임하고, 캐시는 데이터 읽기에 집중하는 것이 성능 확보 측면에서 핵심 고려사항이 될 수 있다.
→ 우리가 Redis를 사용하려는 Main Point!!
또한, 캐시 서버가 장애 또는 특별한 사유로 인해 다운되었을 경우나 서비스가 불가능할 경우에도 지속적인 서비스가 가능해야 한다. 이는 캐시에 저장되는 데이터는 결국 기존 영구 데이터 스토어에 동일하게 저장되고 유지된다는 점을 뒷바침하는 설계방식이다. 캐시 서버가 장애로 부터 복구되는 동안 성능상의 지연은 발생할 수 있지만, 서비스가 불가능한 상태가 되지 않도록 고려해야 한다.
→ DB와의 데이터 정합성을 이용해, 캐시에 장애가 생겨도 느리지만, DB에서 불러올 수 있도록 해야겠다.

좋은 글 잘 보았습니다.
1. 다만 기술사용의 정당성이 조금은 부실하지 않나 생각되네요.
github 코드를 보니 like domain자체가 Question이라는 domain에 종속적인 관계로 보이고, 결론적으로 Question에 관련된 data를 db를 통해서 가져온 후에 관련된 like data를 보여주게 되는 듯 합니다. 제가 본게 맞을까요?
이게 맞다면, 결국 db를 1번은 거쳐야지만 like를 반환할 수 있다는 것인데, 이 과정에 캐싱이 필요한지에 대한 정당성에 의문이 갑니다. 어차피 db를 조회한다면 join table을 통해 가져오는 것과 캐싱해서 가져오는 것과의 redis의 자원소모 대비 효율이 나올지 궁금하기도 합니다. 유의미한 성능차이가 있다면, 그 비교를 해주시면 좀 더 정당성이 부여되지 않을까 하네요.