교차검증
k-fold cross-validation(CV) : 교차검증을 하기 위해서 데이터를 k개로 등분 후 k개의 집합에서 k-1 개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증
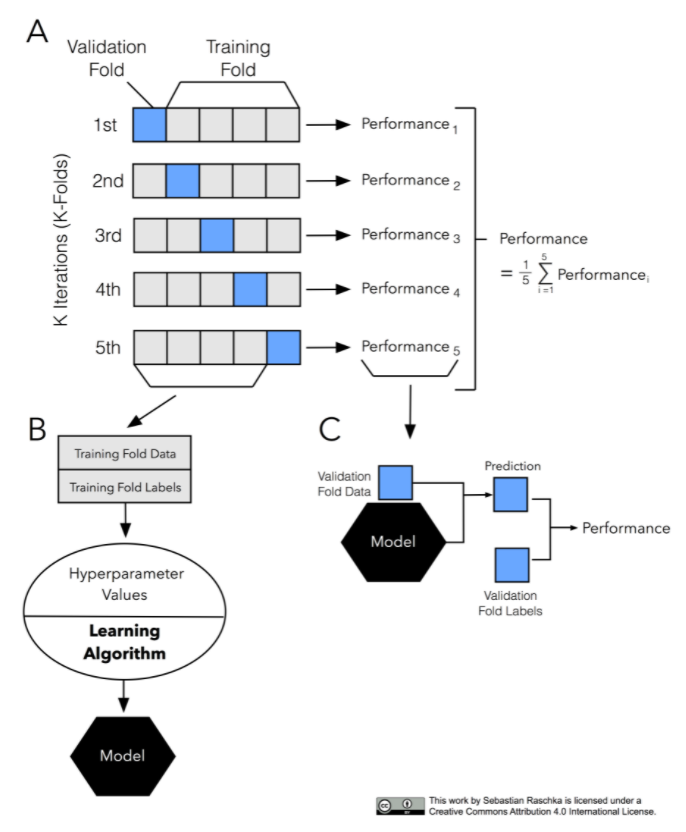
ex) 데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 3번 바꾸어가며 검증하는 것은 3-fold CV / 10-fold CV의 경우 검증을 총 10번 검증
※ 훈련/검증/테스트 세트로 나누는 방법 : Hold-out 교차검증
- 단점 2가지
- 학습에 사용가능한 데이터가 충분하지 않다면 문제가 생긴다
- 검증세트 크기가 충분히 크지 않으면 예측 성능에 대한 추정이 부정확해진다
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
Ridge(alpha=1.0)
)
# 3-fold 교차검증
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(-scores)
# 일반적으로 scoring을 값이 클 수록 모델 성능이 좋은 것으로 사이킷런에서 인식하는데,
mae는 값이 클 수록 모델 성능이 저하되는 것이므로 Negative 키워드를 붙여서 사용한다
# 출력
[19912.3716215 23214.74205495 18656.29713167]하이퍼파라미터 튜닝
머신러닝 모델을 만들때 중요한 점이
최적화(optimization)와 일반화(generalization)
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 뜻한다
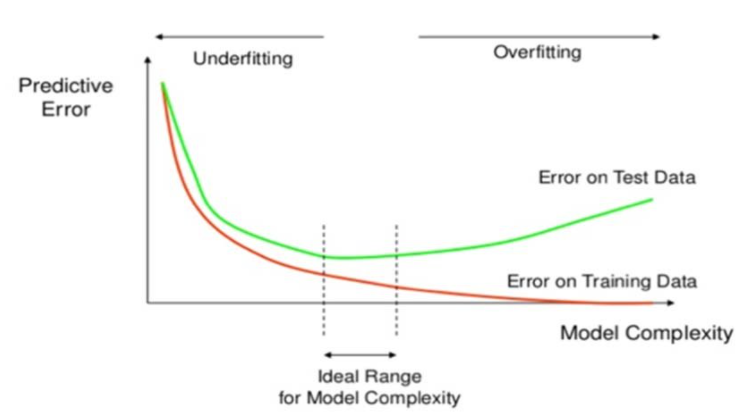
모델의 복잡도를 높이는 과정에서 훈련/검증 세트의 손실이 함께 감소하는 시점이 과소적합(underfitting)
어느 시점부터 훈련데이터의 손실은 계속 감소하는데 검증데이터의 손실은 증가하는 때가 과적합(overfitting)
이상적인 모델은 과소적합과 과적합 사이에 존재한다
Randomized Search CV
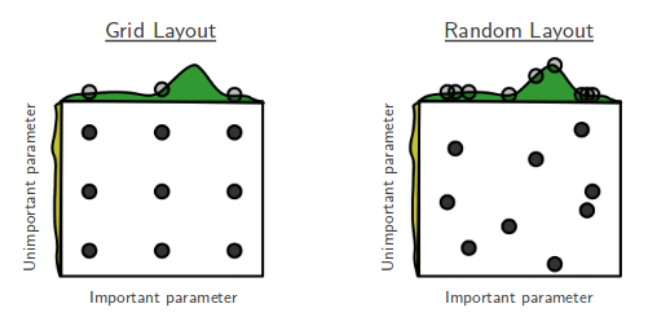
1. GridSearchCV: 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증
2. RandomizedSearchCV: 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'], # __를 해줘야 함
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe, # 모델
param_distributions=dists, # 파라미터 조정부분
n_iter=50, # n_iter(=50) * 3 교차검증 = 150 tasks
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print(clf.best_params_) # 최적의 파라미터
print(-clf.best_score_) # 최적의 점수
# 파라미터 조정 후 가장 성능이 좋은 모델
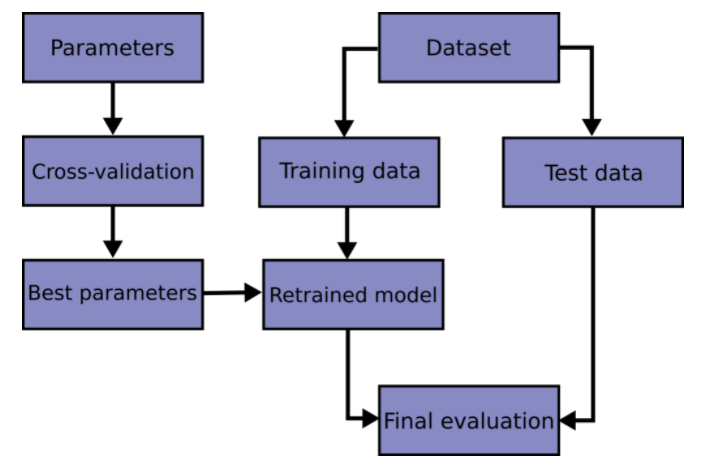
best = clf.best_estimator_⚠️ hold-out 교차검증(훈련/검증/테스트 세트로 한 번만 나누어 실험)을 수행한 경우에는 (훈련 + 검증) 데이터셋에서 최적화된 하이퍼파라미터로 최종 모델을 재학습(refit) 해야 한다

AI/Data Science