Pipelines
여러 모델을 같은 전처리 프로세스에 연결시킬 수 있는 방법
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
StandardScaler(),
LogisticRegression(n_jobs=-1)
)
pipe.fit(X_train, y_train) # 한번에 모델을 학습시킬 수 있음
pipe.score(X_val, y_val) # 검증세트의 정확도 점수
y_pred = pipe.predict(X_test) # 테스트세트를 통한 예측결정트리모델
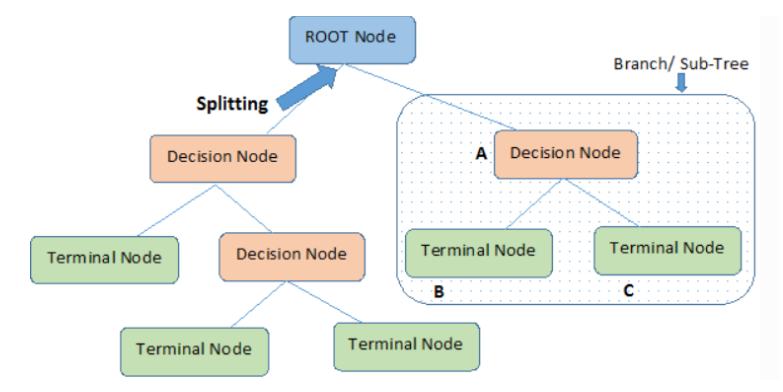
특성들을 기준으로 샘플을 분류
질문이나 말단의 정답을 노드 node
노드를 연결하는 선을 엣지 edge
- 결정트리의 각 노드는 뿌리(root)노드 / 중간(internal)노드 / 말단(external, leaf, terminal)노드로 나뉜다
- 결정트리는 분류 / 회귀 문제 모두 적용 가능하다
- 결정트리는 데이터를 분할해 가는 알고리즘
- 분류과정은 새로운 데이터가 특정 말단 노드에 속한다는 정보를 확인한 뒤 말단 노드의 빈도가 가장 높은 범주로 데이터를 분류
⚠️ 결정트리모델은 한 개의 트리만 사용하기 때문에 한 노드에서 생긴 에러가 하부 노드에서도 계속 영향을 주는 특성이 있다
트리모델 학습 알고리즘
- 결정트리를 학습할 때 노드를 어떻게 분할하는가가 중요
- 노드 분할 방법에 따라 다른 모양의 트리구조가 만들어진다
- 결정트리의 비용함수를 정의하고 그것을 최소화하도록 분할하는것이 트리모델 학습 알고리즘이다
-
지니불순도(Gini Impurity / Gini Index)
※ 불순도 : 여러 범주가 섞여 있는 정도
노드가 중요할 수록 불순도가 크게 감소
ex) A:B가 45:55인 샘플보다 80:20인 샘플이 불순도가 낮다 -
엔트로피(Entropy)
하이퍼파라미터
- min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터수
⚠️ 작게 설정할수록 분할노드가 많아져 과적합↑ - min_samples_leaf : 말단 노드에 최소한 존재해야하는 샘플들의 수
- max_depth : 트리의 최대 깊이
⚠️ 깊이가 깊어지면 과적합↑
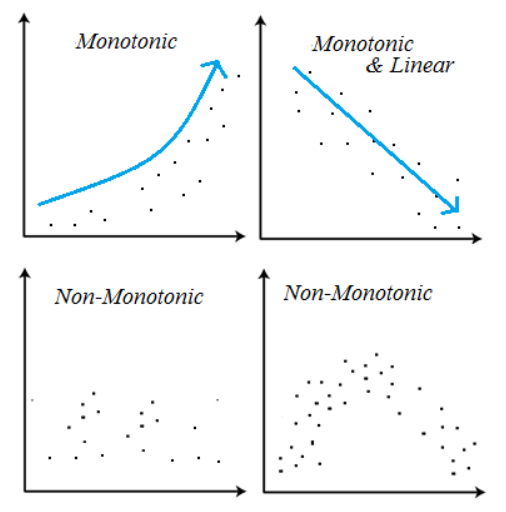
※ 결정트리모델은 선형모델과 달리 비선형, 비단조(Non-Monotonic), 특성상호작용(Feature Interactions) 특징을 가지고 있는 데이터 분석에 용이하다
from sklearn.tree import DecisionTreeClassifier
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
DecisionTreeClassifier(max_depth=5, min_samples_leaf=10, random_state=1)
)
⚠️ 과적합을 방지하기 위해 파라미터 조정을 잘해야한다
AI/Data Science